Flink v1.11
より翻訳.機械翻訳を利用しながらのため間違いがある可能性があります.
チュートリアルではJavaのコードを取り上げます.
適宜,Scalaと読み替えてください.
Flinkを試す
ローカルインストール
以下のステップに従って,最新の安定版をダウンロードしてください.
Step1:ダウンロード
Flinkの実行には,__Java8__または__Java11__がインストールされている必要があります.
java -version
ver1.11.2をDownloadして,圧縮を解凍してください.
Step2:クラスターの起動
Flinkには,ローカルクラスタを起動するための単一のbashスクリプトが作成されています.
$ ./bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host.
Starting taskexecutor daemon on host.
Step3:Jobの開始
Flinkのリリースには多くのサンプルが含まれています.
これらのアプリケーションの1つを実行中のクラスタに素早くデプロイできます.
$ ./bin/flink run examples/streaming/WordCount.jar
$ tail log/flink-*-taskexecutor-*.out
(to,1)
(be,1)
(or,1)
(not,1)
(to,2)
(be,2)
FlinkのWeb UIでクラスタの状態や実行中のジョブの状態を確認できます.
Step4:クラスターの停止
ジョブが終了したら,クラスタと実行中のコンポーネントをすぐに停止させることができます.
$ ./bin/stop-cluster.sh
Data StreamAPIによる不正検知
何を構築するのか?
クレジットカード詐欺は、デジタル時代に懸念が高まっています。
犯罪者は、詐欺を実行したり、安全でないシステムにハッキングしたりすることで、クレジットカード番号を盗みます。
盗まれた番号は、多くの場合、1ドル以下の少額の買い物をすることでテストされます。
それが成功した場合、彼らは、販売したり、自分のために保管したりできるアイテムを手に入れるために、より重要な買い物をします。
このチュートリアルでは、不審なクレジットカード取引を警告するための不正検知システムを構築します。
シンプルなルールのセットを使用して、Flinkを使用して高度なビジネスロジックを実装し、リアルタイムで行動する方法を見ることができます。
前提条件
このチュートリアルでは、JavaやScalaにある程度慣れていることを前提としていますが、他のプログラミング言語から来ている場合でも、それに沿って進むことができるはずです。
ヘルプ,行き詰まってしまいました.
行き詰ったら、コミュニティのサポートリソースをチェックしてください。
特に、Apache Flink のユーザメーリングリストは、どの Apache プロジェクトの中でも最も活発なものの一つとして常にランク付けされており、素早く助けを得るための素晴らしい方法となっています。
フォローアップの仕方
チュートリアルを進めていくには以下をインストールしたコンピュータが必要になります.
- Java 8 or 11
- Maven
NOTE: チュートリアルで紹介するコードは簡易的なものになっています.完璧なコードは一番下に記載
$ mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-walkthrough-datastream-java \
-DarchetypeVersion=1.11.2 \
-DgroupId=frauddetection \
-DartifactId=frauddetection \
-Dversion=0.1 \
-Dpackage=spendreport \
-DinteractiveMode=false
必要に応じて,groupId, artifactId, packageを編集できます.
上記のパラメータを使用して,Mavenはチュートリアルを完了するための全ての依存関係を持つプロジェクトを含む__fraudDetection__という名前のフォルダを作成します.
プロジェクトをエディタにインポートした後、以下のコードを含むファイル FraudDetectionJob.java (またはFraudDetectionJob.scala) を見つけることができ、IDE内で直接実行できます.
データストリームを通してブレークポイントを設定してみて、どのように動作するかを理解するためにDEBUGモードでコードを実行してください。
FraudDetectionJob.java
package spendreport;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.walkthrough.common.sink.AlertSink;
import org.apache.flink.walkthrough.common.entity.Alert;
import org.apache.flink.walkthrough.common.entity.Transaction;
import org.apache.flink.walkthrough.common.source.TransactionSource;
public class FraudDetectionJob {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Transaction> transactions = env
.addSource(new TransactionSource())
.name("transactions");
DataStream<Alert> alerts = transactions
.keyBy(Transaction::getAccountId)
.process(new FraudDetector())
.name("fraud-detector");
alerts
.addSink(new AlertSink())
.name("send-alerts");
env.execute("Fraud Detection");
}
}
FraudDetector.java
package spendreport;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.walkthrough.common.entity.Alert;
import org.apache.flink.walkthrough.common.entity.Transaction;
public class FraudDetector extends KeyedProcessFunction<Long, Transaction, Alert> {
private static final long serialVersionUID = 1L;
private static final double SMALL_AMOUNT = 1.00;
private static final double LARGE_AMOUNT = 500.00;
private static final long ONE_MINUTE = 60 * 1000;
@Override
public void processElement(
Transaction transaction,
Context context,
Collector<Alert> collector) throws Exception {
Alert alert = new Alert();
alert.setId(transaction.getAccountId());
collector.collect(alert);
}
}
コードの分解
この2つのファイルのコードを順を追って見ていきましょう.
FraudDetectionJobクラスはアプリケーションのデータフローを定義し、FraudDetectorクラスは不正トランザクションを検出する機能のビジネスロジックを定義しています。
ここでは、FraudDetectionJobクラスのメインメソッドでジョブがどのように組み立てられているかを説明します.
The Execution Environment(実行環境)
最初の行は StreamExecutionEnvironment を設定します.
The ExecutionEvironmentは、ジョブのプロパティを設定し、ソースを作成し、最終的にジョブの実行をトリガーする方法です。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Creating a Source(ソースの作成)
ソースは、Apache Kafka、Rabbit MQ、Apache Pulsarなどの外部システムからFlink Jobsにデータをインジェストします。
このチュートリアルでは、あなたが処理するためのクレジットカードトランザクションの無限のストリームを生成するソースを使用します。
各トランザクションには、アカウントID(accountId)、トランザクションが発生した時刻のタイムスタンプ(timestamp)、米ドルの金額(金額)が含まれています。
ソースに付けられた名前はあくまでもデバッグのためのものなので、何か問題が発生した場合、どこでエラーが発生したのかを知ることができます。
DataStream<Transaction> transactions = env
.addSource(new TransactionSource())
.name("transactions");
Partitioning Events & Detecting Fraud(イベントの分割と不正の検出)
トランザクションストリームには、多数のユーザーからの大量のトランザクションが含まれているため、複数の不正検出タスクで並行して処理する必要があります。不正行為はアカウントごとに発生するため、同じアカウントのすべてのトランザクションが、不正検知オペレータの同じ並列タスクによって処理されるようにする必要があります。
特定のキーのすべてのレコードを同じ物理タスクが処理するようにするには、DataStream#keyBy を使用してストリームを分割します。
process()呼び出しは、ストリーム内の各パーティショニングされた要素に関数を適用する演算子を追加します。
演算子は、"keyBy"(この場合はFraudDetector)がキー付きコンテキスト内で実行された直後に行うのが一般的です.
DataStream<Alert> alerts = transactions
.keyBy(Transaction::getAccountId)
.process(new FraudDetector())
.name("fraud-detector");
Outputting Results(結果を出力)
シンクは、Apache Kafka、Cassandra、AWS Kinesisなどの外部システムにDataStreamを書き込みます。
AlertSinkは、各Alertレコードを永続的なストレージに書き込むのではなく、ログレベルのinfoでログを記録するので、結果を簡単に確認することができます。
alerts.addSink(new AlertSink());
Executing the Job(ジョブの実行)
Flink アプリケーションはlazyにビルドされ、完全に形成されてから実行のためにクラスタに送られます。
ジョブの実行を開始するために StreamExecutionEnvironment#execute を呼び出し、名前を付けます。
env.execute("Fraud Detection");
The Fraud Detector(詐欺発見機)
不正検出器は、___KeyedProcessFunction___として実装されています。
そのメソッド KeyedProcessFunction#processElement は、すべてのトランザクションイベントに対して呼び出されます。
この最初のバージョンでは、すべてのトランザクションでアラートを生成しますが、これは保守的すぎると言う人もいるかもしれません。
このチュートリアルの次のステップでは、より意味のあるビジネスロジックで不正検知器を拡張していきます。
public class FraudDetector extends KeyedProcessFunction<Long, Transaction, Alert> {
private static final double SMALL_AMOUNT = 1.00;
private static final double LARGE_AMOUNT = 500.00;
private static final long ONE_MINUTE = 60 * 1000;
@Override
public void processElement(
Transaction transaction,
Context context,
Collector<Alert> collector) throws Exception {
Alert alert = new Alert();
alert.setId(transaction.getAccountId());
collector.collect(alert);
}
}
実際のアプリケーション(v1)を書く
最初のバージョンでは、詐欺検出器は、すぐに大規模なものが続く小さなトランザクションを行うすべてのアカウントのアラートを出力する必要があります。
小規模なものは1.00ドル未満のものであり、大規模なものは500ドル以上です。
あなたの詐欺検出器は、特定のアカウントのトランザクションの次のストリームを処理することを想像してみてください。

取引3と4は、0.09ドルという少額の取引の後に510ドルという多額の取引が続いているため、不正行為としてマークされるべきです。
あるいは、取引7、8、9は、0.02ドルの小額取引がすぐに大額取引の後に続くわけではないので、不正行為ではありませんが、その代わりに、パターンを崩す中間取引があります。
これを実現するには、不正検出器はイベントにまたがって情報を記憶していなければなりません。
イベントにまたがって情報を記憶するには状態/Stateが必要で、これがKeyedProcessFunctionを使用することにした理由です。
これにより、状態と時間の両方を細かく制御することができ、このウォークスルーを通して、より複雑な要件でアルゴリズムを進化させることができるようになります。
最も簡単な実装は、小さなトランザクションが処理されるたびに設定されるブーリアンフラグです。
大規模なトランザクションが発生した場合、そのアカウントにフラグが設定されているかどうかをチェックするだけです。
しかし、単にフラグをFraudDetectorクラスのメンバ変数として実装するだけではうまくいきません。
Flink は FraudDetector の同じオブジェクトインスタンスで複数のアカウントのトランザクションを処理します。
つまり、アカウント A と B が FraudDetector の同じインスタンスを介してルーティングされている場合、アカウント A のトランザクションでフラグが true に設定され、アカウント B のトランザクションで false アラートが発生する可能性があります。
もちろん、個々のキーのフラグを追跡するためにMapのようなデータ構造を使用することもできますが、単純なメンバ変数はフォールトトレラントではなく、障害が発生した場合にはすべての情報が失われます。
そのため、アプリケーションが障害から回復するために再起動しなければならない場合、不正検出器は警告を見逃す可能性があります。
これらの課題に対処するために、Flink は、通常のメンバ変数とほぼ同じくらい簡単に使用できるフォールトトレラント状態のプリミティブを提供しています。
ValueStateはキー付きステートの一形態であり、キー付きコンテキストで適用される演算子(DataStream#keyByの直後の演算子)でのみ利用可能です。
演算子のキー付き状態は、現在処理されているレコードのキーに自動的にスコープされます。
この例では、キーは現在のトランザクションのアカウント ID (keyBy() で宣言されたもの) であり、FraudDetector はアカウントごとに独立した状態を維持しています。
ValueStateは、Flinkがどのように変数を管理すべきかについてのメタデータを含むValueStateDescriptorを使用して作成されます。
状態は、関数がデータの処理を開始する前に登録しておく必要があります。
そのための正しいフックが open() メソッドです。
public class FraudDetector extends KeyedProcessFunction<Long, Transaction, Alert> {
private static final long serialVersionUID = 1L;
private transient ValueState<Boolean> flagState;
@Override
public void open(Configuration parameters) {
ValueStateDescriptor<Boolean> flagDescriptor = new ValueStateDescriptor<>(
"flag",
Types.BOOLEAN);
flagState = getRuntimeContext().getState(flagDescriptor);
}
ValueStateは、Java標準ライブラリのAtomicReferenceやAtomicLongに似たラッパークラスです。
update は状態を設定し、value は現在の値を取得し、clear はその内容を削除します。アプリケーションの開始時や ValueState#clear を呼び出した後など、特定のキーの状態が空の場合、ValueState#value は null を返します。
ValueState#valueによって返されたオブジェクトへの変更は、システムによって認識されることが保証されていないため、すべての変更はValueState#updateによって実行されなければなりません。
それ以外の場合は、フォールト トレランスは Flink が自動的に管理しているので、他の標準変数と同じように操作することができます。
以下に、フラグステートを使用して潜在的な不正トランザクションを追跡する方法の例を示します。
@Override
public void processElement(
Transaction transaction,
Context context,
Collector<Alert> collector) throws Exception {
// Get the current state for the current key
Boolean lastTransactionWasSmall = flagState.value();
// Check if the flag is set
if (lastTransactionWasSmall != null) {
if (transaction.getAmount() > LARGE_AMOUNT) {
// Output an alert downstream
Alert alert = new Alert();
alert.setId(transaction.getAccountId());
collector.collect(alert);
}
// Clean up our state
flagState.clear();
}
if (transaction.getAmount() < SMALL_AMOUNT) {
// Set the flag to true
flagState.update(true);
}
}
すべてのトランザクションについて、不正検出器はそのアカウントのフラグの状態をチェックします。
ValueStateは常に現在のキー、つまりアカウントにスコープされていることを覚えておいてください。
フラグが NULL でない場合は、そのアカウントの最後の取引が少額であったことを意味し、この取引の金額が大きい場合は、不正検知器は不正警告を出力する。
そのチェックの後、フラグ状態は無条件にクリアされる。
現在の取引が不正警告を引き起こし、パターンが終了したか、現在の取引が警告を引き起こしておらず、パターンが壊れているので再開する必要があるかのいずれかである。
最後に、トランザクションの金額が小さいかどうかをチェックします。もしそうであれば、次のイベントでチェックできるようにフラグが設定されます。
ValueStateには、実際にはunset ( null)、true、falseの3つの状態があることに注意してください。
このジョブでは、フラグがセットされているかどうかをチェックするために、unset ( null) と true のみを使用します。
不正検知器 v2.状態+時間=❤️
詐欺師は、テスト取引が気づかれる可能性を減らすために、大きな買い物をするのに時間をかけません。
例えば、詐欺検出器に1分間のタイムアウトを設定したいとします。
FlinkのKeyedProcessFunctionでは、将来のある時点でコールバックメソッドを呼び出すタイマーを設定することができます。
それでは、新しい要件を満たすようにジョブを修正する方法を見てみましょう。
- フラグがtrueに設定されているときはいつでも、未来の1分間のタイマーを設定してください。
- タイマーが作動したら、フラグの状態をクリアしてリセットします。
- フラグがクリアされた場合、タイマーはキャンセルされるべきです。
タイマーをキャンセルするには、それが何時までに設定されているかを覚えておく必要があり、覚えておくことは状態を意味します。
private transient ValueState<Boolean> flagState;
private transient ValueState<Long> timerState;
@Override
public void open(Configuration parameters) {
ValueStateDescriptor<Boolean> flagDescriptor = new ValueStateDescriptor<>(
"flag",
Types.BOOLEAN);
flagState = getRuntimeContext().getState(flagDescriptor);
ValueStateDescriptor<Long> timerDescriptor = new ValueStateDescriptor<>(
"timer-state",
Types.LONG);
timerState = getRuntimeContext().getState(timerDescriptor);
}
KeyedProcessFunction#processElementは、タイマーサービスを含むコンテキストで呼び出されます。
タイマーサービスは、現在時刻の問い合わせ、タイマーの登録、タイマーの削除などを行うことができます。
これを使えば、フラグが設定されるたびに1分先のタイマーを設定し、そのタイムスタンプをtimerStateに格納することができます。
if (transaction.getAmount() < SMALL_AMOUNT) {
// set the flag to true
flagState.update(true);
// set the timer and timer state
long timer = context.timerService().currentProcessingTime() + ONE_MINUTE;
context.timerService().registerProcessingTimeTimer(timer);
timerState.update(timer);
}
処理時間はwall clock timeであり、オペレータを動かしている機械のシステムクロックによって決定されます。
タイマーが発生すると、KeyedProcessFunction#onTimerを呼び出します。
このメソッドをオーバーライドすることで、フラグをリセットするコールバックを実装することができます。
public void onTimer(long timestamp, OnTimerContext ctx, Collector<Alert> out) {
// remove flag after 1 minute
timerState.clear();
flagState.clear();
}
最後に、タイマーをキャンセルするには、登録されているタイマーを削除して、タイマーの状態を削除する必要があります.
これをヘルパーメソッドでラップして、flagState.clear()の代わりにこのメソッドを呼び出すことができます。
private void cleanUp(Context ctx) throws Exception {
// delete timer
Long timer = timerState.value();
ctx.timerService().deleteProcessingTimeTimer(timer);
// clean up all state
timerState.clear();
flagState.clear();
}
完全に機能的で、ステートフルな分散型ストリーミングアプリケーションです!
完成したアプリケーション
package spendreport;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.walkthrough.common.entity.Alert;
import org.apache.flink.walkthrough.common.entity.Transaction;
public class FraudDetector extends KeyedProcessFunction<Long, Transaction, Alert> {
private static final long serialVersionUID = 1L;
private static final double SMALL_AMOUNT = 1.00;
private static final double LARGE_AMOUNT = 500.00;
private static final long ONE_MINUTE = 60 * 1000;
private transient ValueState<Boolean> flagState;
private transient ValueState<Long> timerState;
@Override
public void open(Configuration parameters) {
ValueStateDescriptor<Boolean> flagDescriptor = new ValueStateDescriptor<>(
"flag",
Types.BOOLEAN);
flagState = getRuntimeContext().getState(flagDescriptor);
ValueStateDescriptor<Long> timerDescriptor = new ValueStateDescriptor<>(
"timer-state",
Types.LONG);
timerState = getRuntimeContext().getState(timerDescriptor);
}
@Override
public void processElement(
Transaction transaction,
Context context,
Collector<Alert> collector) throws Exception {
// Get the current state for the current key
Boolean lastTransactionWasSmall = flagState.value();
// Check if the flag is set
if (lastTransactionWasSmall != null) {
if (transaction.getAmount() > LARGE_AMOUNT) {
//Output an alert downstream
Alert alert = new Alert();
alert.setId(transaction.getAccountId());
collector.collect(alert);
}
// Clean up our state
cleanUp(context);
}
if (transaction.getAmount() < SMALL_AMOUNT) {
// set the flag to true
flagState.update(true);
long timer = context.timerService().currentProcessingTime() + ONE_MINUTE;
context.timerService().registerProcessingTimeTimer(timer);
timerState.update(timer);
}
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<Alert> out) {
// remove flag after 1 minute
timerState.clear();
flagState.clear();
}
private void cleanUp(Context ctx) throws Exception {
// delete timer
Long timer = timerState.value();
ctx.timerService().deleteProcessingTimeTimer(timer);
// clean up all state
timerState.clear();
flagState.clear();
}
}
期待される出力
提供されたTransactionSourceを使用してこのコードを実行すると、アカウント3の不正行為の警告が表示されます。
タスクマネージャーのログに以下のような出力が表示されるはずです。
2019-08-19 14:22:06,220 INFO org.apache.flink.walkthrough.common.sink.AlertSink - Alert{id=3}
2019-08-19 14:22:11,383 INFO org.apache.flink.walkthrough.common.sink.AlertSink - Alert{id=3}
2019-08-19 14:22:16,551 INFO org.apache.flink.walkthrough.common.sink.AlertSink - Alert{id=3}
2019-08-19 14:22:21,723 INFO org.apache.flink.walkthrough.common.sink.AlertSink - Alert{id=3}
2019-08-19 14:22:26,896 INFO org.apache.flink.walkthrough.common.sink.AlertSink - Alert{id=3}
Table APIによるリアルタイムレポート
Apache Flink は、バッチ処理とストリーム処理のための統一されたリレーショナル API として Table API を提供しています。
FlinkのTable APIは、データ分析、データパイプライン、ETLアプリケーションの定義を容易にするために一般的に使用されています。
何を構築するのか
このチュートリアルでは、口座別に金融取引を追跡するリアルタイムダッシュボードの構築方法を学びます。
パイプラインでは、Kafkaからデータを読み込み、結果をGrafana経由で可視化されたMySQLに書き込みます。
前提条件
このチュートリアルでは、Java や Scala にある程度慣れていることを前提としていますが、他のプログラミング言語を使用している場合でも十分に理解できるはずです。
また、SELECT句やGROUP BY句などの基本的なリレーショナル概念に精通していることも前提としています。
ヘルプ!行き詰まっています.
行き詰ったら、コミュニティのサポートリソースをチェックしてください。
特に、Apache Flink のユーザメーリングリストは、どの Apache プロジェクトの中でも最も活発なものの一つであり、すぐに助けを得るための素晴らしい方法の一つとなっています。
チュートリアルをフォローするには
あなたがチュートリアルを行う場合,以下をインストールしたコンピュータが必要になります.
- Java 8または11
- Maven
- Docker
必要な設定ファイルは、flink-playgrounds リポジトリで入手できます。
ダウンロードしたら、IDE でプロジェクト flink-playground/table-walkthrough を開き、SpendReport というファイルに移動します。
EnvironmentSettings settings = EnvironmentSettings.newInstance().build();
TableEnvironment tEnv = TableEnvironment.create(settings);
tEnv.executeSql("CREATE TABLE transactions (\n" +
" account_id BIGINT,\n" +
" amount BIGINT,\n" +
" transaction_time TIMESTAMP(3),\n" +
" WATERMARK FOR transaction_time AS transaction_time - INTERVAL '5' SECOND\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'transactions',\n" +
" 'properties.bootstrap.servers' = 'kafka:9092',\n" +
" 'format' = 'csv'\n" +
")");
tEnv.executeSql("CREATE TABLE spend_report (\n" +
" account_id BIGINT,\n" +
" log_ts TIMESTAMP(3),\n" +
" amount BIGINT\n," +
" PRIMARY KEY (account_id, log_ts) NOT ENFORCED" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://mysql:3306/sql-demo',\n" +
" 'table-name' = 'spend_report',\n" +
" 'driver' = 'com.mysql.jdbc.Driver',\n" +
" 'username' = 'sql-demo',\n" +
" 'password' = 'demo-sql'\n" +
")");
Table transactions = tEnv.from("transactions");
report(transactions).executeInsert("spend_report");
コードの分解
実行環境
最初の2行はTableEnvironmentを設定します。テーブル環境は、ジョブのプロパティを設定したり、バッチかストリーミング・アプリケーションかを指定したり、ソースを作成したりする方法です。
このチュートリアルでは、ストリーミング実行を使用する標準のテーブル環境を作成します。
EnvironmentSettings settings = EnvironmentSettings.newInstance().build();
TableEnvironment tEnv = TableEnvironment.create(settings);
テーブルの登録
次に、テーブルが現在のカタログに登録されており、これを使用して外部システムに接続して、バッチデータとストリーミングデータの両方を読み書きすることができます。
テーブル ソースは、データベース、キー値ストア、メッセージ キュー、ファイル システムなどの外部システムに保存されているデータへのアクセスを提供します。
テーブル シンクは、テーブルを外部ストレージ システムに送信します。ソースとシンクのタイプに応じて、CSV、JSON、Avro、またはParquetなどの異なるフォーマットをサポートしています。
tEnv.executeSql("CREATE TABLE transactions (\n" +
" account_id BIGINT,\n" +
" amount BIGINT,\n" +
" transaction_time TIMESTAMP(3),\n" +
" WATERMARK FOR transaction_time AS transaction_time - INTERVAL '5' SECOND\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'transactions',\n" +
" 'properties.bootstrap.servers' = 'kafka:9092',\n" +
" 'format' = 'csv'\n" +
")");
トランザクション入力テーブルと支出レポート出力テーブルの2つのテーブルが登録されています。
transaction (transactions) テーブルでは、クレジットカードのトランザクションを読み取ることができ、アカウント ID (account_id)、タイムスタンプ (transaction_time)、米ドルの金額 (amount) が含まれています。
このテーブルは、CSV データを含むトランザクションと呼ばれる Kafka トピックの論理ビューです。
tEnv.executeSql("CREATE TABLE spend_report (\n" +
" account_id BIGINT,\n" +
" log_ts TIMESTAMP(3),\n" +
" amount BIGINT\n," +
" PRIMARY KEY (account_id, log_ts) NOT ENFORCED" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://mysql:3306/sql-demo',\n" +
" 'table-name' = 'spend_report',\n" +
" 'driver' = 'com.mysql.jdbc.Driver',\n" +
" 'username' = 'sql-demo',\n" +
" 'password' = 'demo-sql'\n" +
")");
2 番目のテーブル spend_report には、集計の最終結果が格納されています。
その基礎となるストレージは MySql データベースのテーブルです。
クエリ
環境を設定し、テーブルを登録したら、最初のアプリケーションを構築する準備ができました。
TableEnvironmentから入力テーブルから行を読み込み、その結果をexecuteInsertを使用して出力テーブルに書き込むことができます。
レポート関数はビジネスロジックを実装する場所です。
現在は未実装です。
Table transactions = tEnv.from("transactions");
report(transactions).executeInsert("spend_report");
テスト
このプロジェクトには、レポートのロジックを検証するセカンダリ・テスト・クラス SpendReportTest が含まれています。
これは、バッチ・モードでテーブル環境を作成します。
EnvironmentSettings settings = EnvironmentSettings.newInstance().inBatchMode().build();
TableEnvironment tEnv = TableEnvironment.create(settings);
___Flinkのユニークな特性の1つ___は、バッチとストリーミングの間で一貫したセマンティクスを提供していることです。
つまり、静的なデータセット上でバッチモードでアプリケーションを開発・テストし、ストリーミングアプリケーションとして本番環境にデプロイすることができます。
こちらも参照
これでジョブセットアップの骨格ができたので、ビジネスロジックを追加する準備ができました。
目標は、1日の各時間帯の各アカウントの総支出を表示するレポートを作成することです。
これは、タイムスタンプの列をミリ秒単位から時間単位に切り下げる必要があることを意味します。
Flinkは、純粋なSQLまたはTable APIを使用したリレーショナルアプリケーションの開発をサポートしています。
Table APIはSQLにインスパイアされた流暢なDSLで、Python、Java、Scalaで記述でき、IDEとの強力な統合をサポートしています。
SQLクエリのように、テーブルプログラムは必要なフィールドを選択し、キーでグループ化することができます。
これらの機能は、フロアや和のようなbuilt-in functionとallong、あなたはこのレポートを書くことができます。
public static Table report(Table transactions) {
return transactions.select(
$("account_id"),
$("transaction_time").floor(TimeIntervalUnit.HOUR).as("log_ts"),
$("amount"))
.groupBy($("account_id"), $("log_ts"))
.select(
$("account_id"),
$("log_ts"),
$("amount").sum().as("amount"));
}
ユーザ定義機能
Flinkには限られた数の組み込み関数が含まれており、時にはユーザー定義の関数で拡張する必要があります。
floorが事前に定義されていない場合は、自分で実装することができます。
import java.time.LocalDateTime;
import java.time.temporal.ChronoUnit;
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.functions.ScalarFunction;
public class MyFloor extends ScalarFunction {
public @DataTypeHint("TIMESTAMP(3)") LocalDateTime eval(
@DataTypeHint("TIMESTAMP(3)") LocalDateTime timestamp) {
return timestamp.truncatedTo(ChronoUnit.HOURS);
}
}
そして、それをアプリケーションに素早く統合します。
public static Table report(Table transactions) {
return transactions.select(
$("account_id"),
call(MyFloor.class, $("transaction_time")).as("log_ts"),
$("amount"))
.groupBy($("account_id"), $("log_ts"))
.select(
$("account_id"),
$("log_ts"),
$("amount").sum().as("amount"));
}
このクエリは、トランザクションテーブルからすべてのレコードを消費し、レポートを計算し、効率的でスケーラブルな方法で結果を出力します。
この実装でテストを実行すると合格となります。
ウィンドウの追加
時間に基づいてデータをグループ化することは、データ処理における典型的な操作であり、特に無限ストリームを扱う場合にはよく行われます。時間に基づくグルーピングはウィンドウと呼ばれ、Flinkは柔軟なウィンドウのセマンティクスを提供しています。
最も基本的なタイプのウィンドウはタンブルウィンドウと呼ばれ、サイズが固定されていてバケットが重ならないものです。
public static Table report(Table transactions) {
return transactions
.window(Tumble.over(lit(1).hour()).on($("transaction_time")).as("log_ts"))
.groupBy($("account_id"), $("log_ts"))
.select(
$("account_id"),
$("log_ts").start().as("log_ts"),
$("amount").sum().as("amount"));
}
これは、アプリケーションがタイムスタンプ列に基づいて1時間のタンブリングウィンドウを使用するように定義します。
つまり、タイムスタンプが2019-06-01 01:23:47の行は、2019-06-01 01:00:00のウィンドウに置かれます。
時間に基づく集計は、他の属性とは対照的に、一般的に連続的なストリーミングアプリケーションでは時間が進むため、ユニークなものです。
フロアやあなたのUDFとは異なり、ウィンドウ関数は本質的なものであり、ランタイムが追加の最適化を適用することができます。
バッチコンテキストでは、ウィンドウはタイムスタンプ属性によってレコードをグループ化するための便利なAPIを提供します。
この実装でテストを実行しても合格します。
ストリーミングでもう一度!
これが、完全に機能的で、ステートフルな分散型ストリーミングアプリケーションです。
クエリはKafkaからのトランザクションのストリームを継続的に消費し、1時間ごとの消費量を計算し、準備が整うとすぐに結果を出力します。
入力には制限がないので、クエリは手動で停止するまで実行し続けます。
また、ジョブは時間ウィンドウベースの集約を使用するので、Flinkは特定のウィンドウにレコードが到着しないことをフレームワークが知っているときに状態をクリーンアップするなど、特定の最適化を実行することができます。
テーブルの遊び場(play ground)は完全にドッカー化されており、ストリーミングアプリケーションとしてローカルで実行可能です。
環境には、Kafka トピック、継続的データ生成器、MySql、Grafana が含まれています。
table-walkthrough フォルダ内から docker-compose スクリプトを起動します。
$ docker-compose build
$ docker-compose up -d
実行中のジョブの情報は、Flink コンソールから確認できます。
MySQLの内部から結果を探ります。
$ docker-compose exec mysql mysql -Dsql-demo -usql-demo -pdemo-sql
mysql> use sql-demo;
Database changed
mysql> select count(*) from spend_report;
+----------+
| count(*) |
+----------+
| 110 |
+----------+
最後にGrafanaに行って、完全に可視化された結果を見てみましょう
Python API
Python Table APIチュートリアル
資料を参照することで,詳細を知ることができる.
Python Table API Tutorial
*個人的に興味があるため,この部分も翻訳します.
Flink Operations Playground
Apache Flink を様々な環境に展開して運用する方法はたくさんあります。
このような多様性に関わらず、Flink クラスタの基本的な構成要素は変わりませんし、同様の運用原則が適用されます。
この遊び場では、Flink ジョブの管理と実行方法を学びます。
アプリケーションをデプロイして監視する方法、Flink がジョブの障害からどのように回復するかを体験し、アップグレードや再スケーリングなどの日常的な運用タスクを実行する方法を見ることができます。
遊び場(play ground)の解剖学
この遊び場は、長く生きている Flink セッションクラスタと Kafka クラスタで構成されています。
Flink クラスタは常にジョブマネージャと 1 つ以上の Flink タスクマネージャで構成されています。ジョブマネージャはジョブの投入、ジョブの監視、リソース管理を担当します。
Flink タスクマネージャはワーカープロセスであり、Flink ジョブを構成する実際のタスクの実行を担当します。
このプレイグラウンドでは、最初は 1 つのタスクマネージャーでスタートしますが、後から複数のタスクマネージャーにスケールアップしていきます。
さらに、このプレイグラウンドには専用のクライアントコンテナが付属しており、これを使用して Flink ジョブを最初に投入し、後から様々な運用タスクを実行します。
クライアントコンテナは Flink Cluster 自体には必要ありませんが、使いやすさのためだけに含まれています。
Kafka ClusterはZookeeperサーバーとKafka Brokerで構成されています。

プレイグラウンドが開始されると、Flink Event CountというFlinkジョブがJobManagerに投入されます。
さらに、2つのKafkaトピックの入力と出力が作成されます。

ジョブは、入力トピックからタイムスタンプとページを持つClickEventsを消費します。
イベントは、ページごとにキーが設定され、15 秒のウィンドウでカウントされます。結果は出力トピックに書き込まれます。
6 つの異なるページがあり、ページごとに 1000 クリック イベントを生成し、15 秒のウィンドウでカウントしています。
したがって、Flinkジョブの出力は、ページとウィンドウごとに1000ビューを表示する必要があります。
プレイグラウンドの開始
プレイグラウンドの環境は、ほんの数ステップで設定できます。
必要なコマンドを順を追って説明し、すべてが正しく動作していることを検証する方法を紹介します。
マシンに Docker (1.12+) と docker-compose (2.1+) がインストールされていることを想定しています。
必要な設定ファイルはflink-playgroundsリポジトリにあります。それを確認して、環境を構築してください。
git clone --branch release-1.11 https://github.com/apache/flink-playgrounds.git
cd flink-playgrounds/operations-playground
docker-compose build
docker-compose up -d
その後、以下のコマンドで実行中のDockerコンテナを検査することができます。
docker-compose ps
Name Command State Ports
-----------------------------------------------------------------------------------------------------------------------------
operations-playground_clickevent-generator_1 /docker-entrypoint.sh java ... Up 6123/tcp, 8081/tcp
operations-playground_client_1 /docker-entrypoint.sh flin ... Exit 0
operations-playground_jobmanager_1 /docker-entrypoint.sh jobm ... Up 6123/tcp, 0.0.0.0:8081->8081/tcp
operations-playground_kafka_1 start-kafka.sh Up 0.0.0.0:9094->9094/tcp
operations-playground_taskmanager_1 /docker-entrypoint.sh task ... Up 6123/tcp, 8081/tcp
operations-playground_zookeeper_1 /bin/sh -c /usr/sbin/sshd ... Up 2181/tcp, 22/tcp, 2888/tcp, 3888/tcp
これは、クライアントコンテナが正常に Flink ジョブを送信し(Exit 0)、すべてのクラスタコンポーネントとデータジェネレータが実行されていることを示しています(Up)。
呼び出すことで、プレイグラウンド環境を停止することができます。
docker-compose down -v
プレイグラウンドに入る
プレイグラウンドには、試してみたり、チェックしてみたりできるものがたくさんあります。
次の2つのセクションでは、Flink Clusterとの対話方法とFlinkの主要な機能のいくつかを紹介します。
Flink WebUI
Flink クラスタを観察するための最も自然な出発点は、http://localhost:8081 で公開されている WebUI です。
すべてがうまくいった場合、クラスタは最初は1つのTaskManagerで構成され、Click Event Countと呼ばれるジョブを実行していることがわかります。
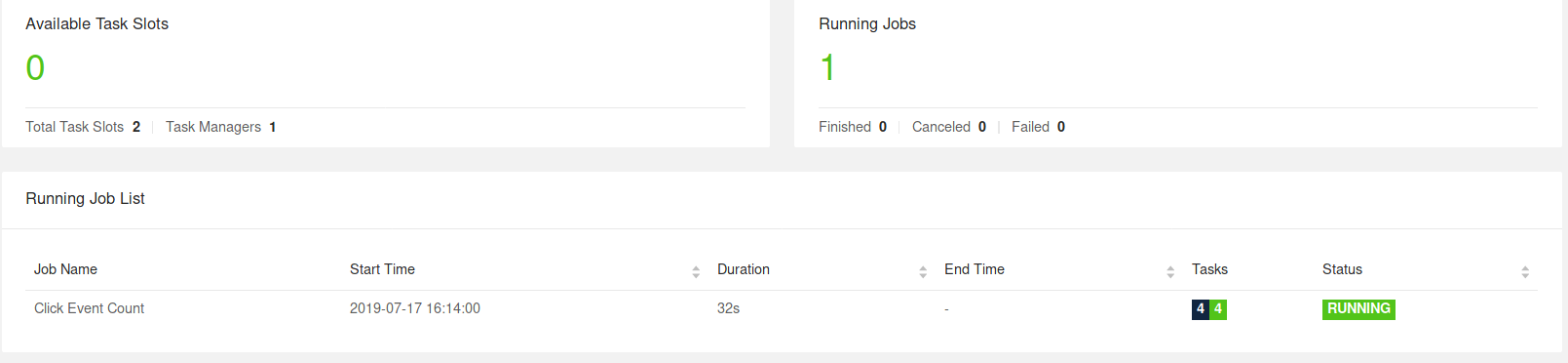
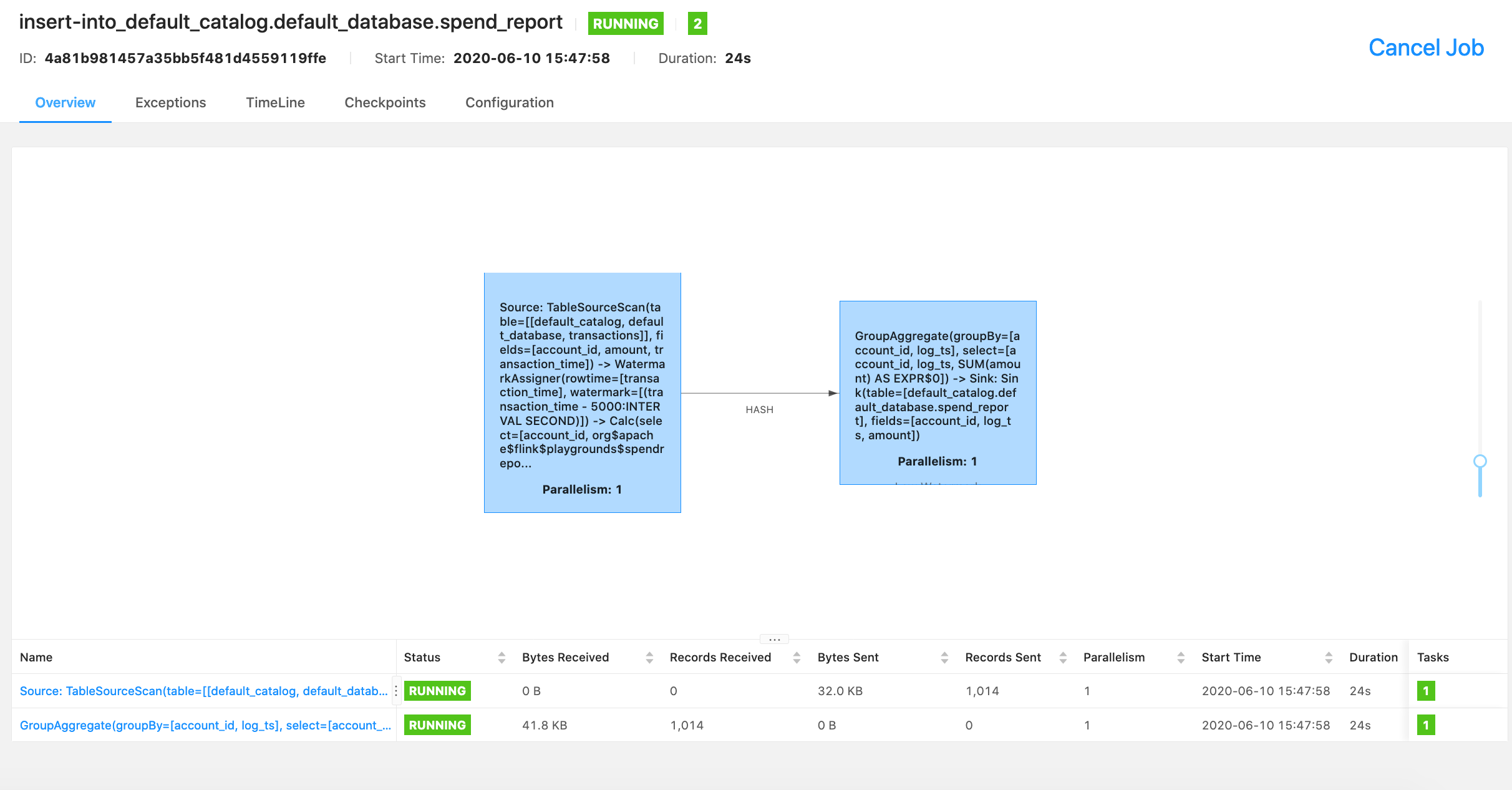
Flink WebUIには、Flinkクラスタとそのジョブに関する多くの有用で興味深い情報(ジョブグラフ、メトリクス、チェックポイント統計、タスクマネージャのステータスなど)が含まれています。
ログ
JobManager
JobManagerのログはdocker-compose経由で調査することができます。
docker-compose logs -f jobmanager
最初の起動後、主にチェックポイントが完了するたびにログメッセージが表示されるはずです。
TaskManager
askManagerのログも同様に調査することができます。
docker-compose logs -f taskmanager
最初の起動後、主にチェックポイントが完了するたびにログメッセージが表示されるはずです。
Flink CLI
Flink CLIはクライアントコンテナ内から使用することができます。
例えば、Flink CLIのヘルプメッセージを表示するには、次のように実行します。
docker-compose run --no-deps client flink --help
Flink REST API
Flink REST API はホスト上の localhost:8081 を介して、またはクライアントコンテナから jobmanager:8081 を介して公開されます。
curl localhost:8081/jobs
Kafka Topics
Kafka Topicsに書き込まれたレコードを見ることができます.
//input topic (1000 records/s)
docker-compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic input
//output topic (24 records/min)
docker-compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic output
遊ぶ時間が来た!
FlinkとDockerコンテナの操作方法を学んだところで、私たちのプレイグラウンドで試すことができる一般的な運用タスクをいくつか見てみましょう。
これらのタスクはすべて互いに独立しています。
ほとんどのタスクはCLIとREST API経由で実行できます。
*CLIの翻訳を進めます.REST APIに適宜読み替えてください.
ランニングジョブの一覧
Command
docker-compose run --no-deps client flink list
期待される出力
Waiting for response...
------------------ Running/Restarting Jobs -------------------
16.07.2019 16:37:55 : <job-id> : Click Event Count (RUNNING)
--------------------------------------------------------------
No scheduled jobs.
JobIDは、ジョブの送信時にジョブに割り当てられ、CLIまたはREST APIを介してジョブ上でアクションを実行するために必要となります。
障害と復旧を観察する
Flink は、(部分的な)故障の下で正確な一度きりの処理を保証します。このプレイグラウンドでは、この動作を観察し、(ある程度は)検証することができます。
Step1: 出力の観察
上述したように、このプレイグラウンドのイベントは、各ウィンドウに正確に 1,000 レコードが含まれるように生成されます。
したがって、Flink がデータの損失や重複なしに TaskManager の障害から正常に復旧したことを確認するには、出力トピックを追跡して、復旧後にすべてのウィンドウが存在し、カウントが正しいことを確認することができます。
そのためには、出力トピックからの読み取りを開始し、回復後までこのコマンドを実行したままにします (ステップ 3)。
docker-compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic output
Step2: 障害の導入
部分的な障害をシミュレートするために、TaskManager を終了させることができます。
本番環境では、これは TaskManager プロセス、TaskManager マシンの損失、または単にフレームワークやユーザーコードから投げられる一時的な例外 (外部リソースが一時的に使用できなくなるなど) に対応します。
docker-compose kill taskmanager
数秒後、ジョブマネージャはタスクマネージャの損失に気付き、影響を受けたジョブをキャンセルし、すぐにリカバリーのためにジョブを再投入します。
ジョブが再起動されると、そのタスクは SCHEDULED 状態のままで、紫色の四角で示されています(以下のスクリーンショットを参照)。
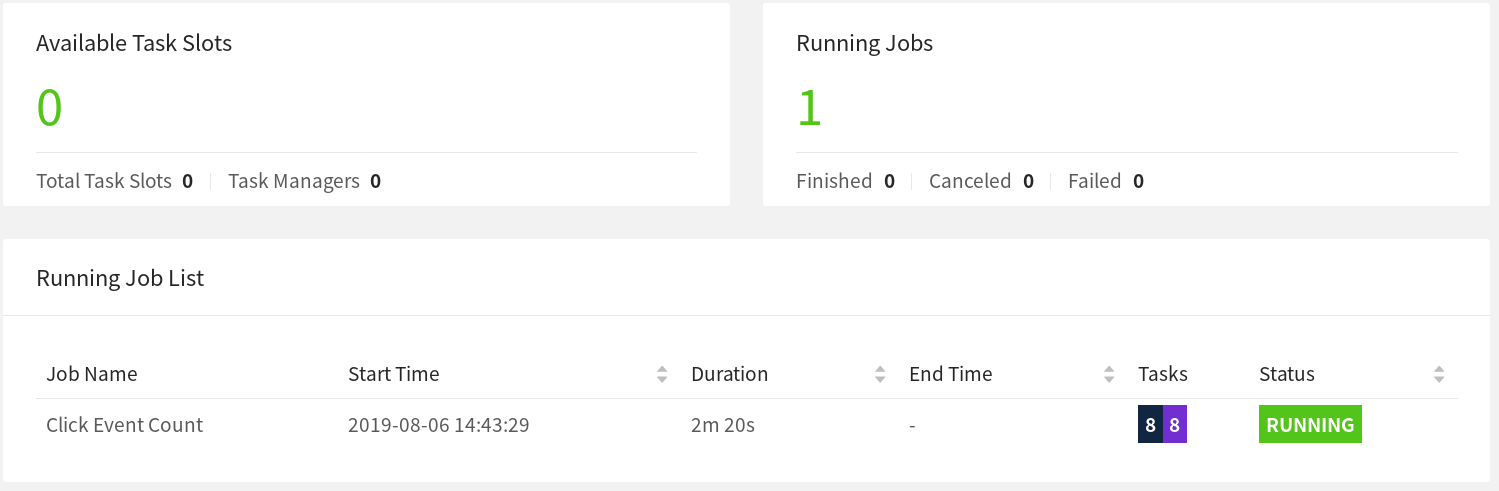
注意:ジョブのタスクがSCHEDULED状態にあり、まだRUNNING状態ではないにもかかわらず、ジョブの全体的な状態はRUNNINGと表示されます。
この時点では、タスクを実行するためのリソース(タスクマネージャによって提供されるタスクスロット)がないため、ジョブのタスクは SCHEDULED 状態から RUNNING 状態に移動することができません。
新しいTaskManagerが利用可能になるまで、ジョブはキャンセルと再提出のサイクルを繰り返します。
その間、データジェネレーターはクリックイベントを入力トピックにプッシュし続けます。
これは、処理するジョブがダウンしている間にデータが生成される実際のプロダクションの設定に似ています。
Step3: 復旧
タスクマネージャーを再起動すると、ジョブマネージャーに再接続します。
docker-compose up -d taskmanager
新しいタスクマネージャが通知されると、ジョブマネージャは回復中のジョブのタスクを新たに利用可能なタスクスロットにスケジューリングします。
再起動時に、タスクは障害の前に行われた最後の成功したチェックポイントから状態を回復し、RUNNING 状態に切り替わります。
(知りたかった部分)
ジョブは、Kafkaからの入力イベント(停止中に蓄積された)の完全なバックログを迅速に処理し、ストリームの先頭に到達するまで、はるかに高い速度(24レコード/分以上)で出力を生成します。
~~~
出力では、すべてのキー(ページ)がすべての時間窓に存在し、すべてのカウントが正確に1000個であることがわかります。
[FlinkKafkaProducer](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/connectors/kafka.html#kafka-producers-and-fault-tolerance) を "at-least-once" モードで使用しているので、出力レコードが重複して表示される可能性があります。
`注意: ほとんどのプロダクションセットアップは、失敗したプロセスを自動的に再起動するために、リソースマネージャ(Kubernetes、Yarn、Mesos)に依存しています。`
#### ジョブのアップグレードと再スケーリング
Flinkジョブのアップグレードには、常に2つのステップがあります。
最初に、FlinkジョブはSavepointで優雅に停止されます。
[Savepoint](https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/state/savepoints.html)は、明確に定義されたグローバルに一貫した時点での完全なアプリケーション状態の一貫したスナップショットです(チェックポイントに似ています)。
次に、アップグレードされたFlinkジョブは、Savepointから開始されます。
この文脈では、「アップグレード」は以下のような異なる意味を持ちます。
- 設定(ジョブの並列性を含む)のアップグレード
- ジョブのトポロジーのアップグレード(オペレーターの追加・削除
- ジョブのユーザー定義機能のアップグレード
アップグレードを開始する前に、アップグレードの過程でデータが失われたり破損したりしないことを観察するために、出力トピックの尾行を開始したい場合があります。
~~~sh
docker-compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic output
~~~
CLIで翻訳します.適宜REST APIに読み替えてください.
##### Step1: Jobの停止
ジョブを優雅に停止させるには、CLIまたはREST APIの "stop "コマンドを使用する必要があります。
これにはジョブのJobIDが必要で、[実行中の全てのジョブ](https://ci.apache.org/projects/flink/flink-docs-release-1.11/try-flink/flink-operations-playground.html#listing-running-jobs)をリストアップするか、WebUIから取得できます。
JobIDがあれば、ジョブの停止に進むことができます。
___Command___
~~~bash
docker-compose run --no-deps client flink stop <job-id>
~~~
___期待される出力___
~~~bash
Suspending job "<job-id>" with a savepoint.
Savepoint completed. Path: file:<savepoint-path>
~~~
Savepointは、ローカルマシンの/tmp/flink-savepoints-directory/の下にマウントされているflink-conf.yamlで設定されたstate.savepoint.dirに保存されています。
次のステップでは、この Savepoint へのパスが必要になります。
##### Step2a:変更なしでJobを再起動する
これで、このSavepointからアップグレードしたJobを再起動することができます。
簡単にするために、何も変更せずに再起動することから始めることができます。
___Command___
~~~bash
docker-compose run --no-deps client flink run -s <savepoint-path> \
-d /opt/ClickCountJob.jar \
--bootstrap.servers kafka:9092 --checkpointing --event-time
~~~
___期待される出力___
~~~bash
Job has been submitted with JobID <job-id>
~~~
ジョブが再び実行されると、ジョブが停止中に蓄積されたバックログを処理している間、レコードがより高いレートで生成されていることが出力トピックでわかります。
さらに、アップグレード中にデータが失われていないことがわかります。
##### Step2b:並列度の異なるJobの再起動(再スケーリング
また、再起動時に別の並列性を渡すことで、このSavepointからジョブを再スケールすることもできます。
___Command___
~~~bash
docker-compose run --no-deps client flink run -p 3 -s <savepoint-path> \
-d /opt/ClickCountJob.jar \
--bootstrap.servers kafka:9092 --checkpointing --event-time
~~~
___期待される出力___
~~~bash
Starting execution of program
Job has been submitted with JobID <job-id>
~~~
現在、ジョブは再投入されていますが、並列性を高めた状態で実行するためのタスクスロットが不足しているため、開始されません(2つ利用可能、3つ必要)。このような場合には
~~~bash
docker-compose scale taskmanager=2
~~~
2つのタスクスロットを持つ2つ目のTaskManagerをFlinkクラスタに追加することができ、これは自動的にJobManagerに登録されます。
TaskManager を追加した直後に、ジョブは再び実行を開始します。
ジョブが再び「実行中」になると、出力トピックに、再スケーリング中にデータが失われていないことが表示されます。
#### ジョブのメトリクスを取得する
ジョブマネージャは、その REST API を介してシステムとユーザの[メトリクス](https://ci.apache.org/projects/flink/flink-docs-release-1.11/monitoring/metrics.html)を公開します。
エンドポイントは、これらのメトリクスのスコープに依存します。
ジョブにスコープされたメトリクスは jobs/<job-id>/metrics で一覧表示できます。
この機能を使用するには、以下の手順に従います。
___Request___
~~~bash
curl "localhost:8081/jobs/<jod-id>/metrics?get=lastCheckpointSize"
~~~
___期待される出力___
~~~json
[
{
"id": "lastCheckpointSize",
"value": "9378"
}
]
~~~
REST APIはメトリクスのクエリだけでなく、実行中のジョブのステータスに関する詳細な情報を取得することもできます。
___Request___
~~~bash
# find the vertex-id of the vertex of interest
curl localhost:8081/jobs/<jod-id>
~~~
___期待される出力___
~~~json
{
"jid": "<job-id>",
"name": "Click Event Count",
"isStoppable": false,
"state": "RUNNING",
"start-time": 1564467066026,
"end-time": -1,
"duration": 374793,
"now": 1564467440819,
"timestamps": {
"CREATED": 1564467066026,
"FINISHED": 0,
"SUSPENDED": 0,
"FAILING": 0,
"CANCELLING": 0,
"CANCELED": 0,
"RECONCILING": 0,
"RUNNING": 1564467066126,
"FAILED": 0,
"RESTARTING": 0
},
"vertices": [
{
"id": "<vertex-id>",
"name": "ClickEvent Source",
"parallelism": 2,
"status": "RUNNING",
"start-time": 1564467066423,
"end-time": -1,
"duration": 374396,
"tasks": {
"CREATED": 0,
"FINISHED": 0,
"DEPLOYING": 0,
"RUNNING": 2,
"CANCELING": 0,
"FAILED": 0,
"CANCELED": 0,
"RECONCILING": 0,
"SCHEDULED": 0
},
"metrics": {
"read-bytes": 0,
"read-bytes-complete": true,
"write-bytes": 5033461,
"write-bytes-complete": true,
"read-records": 0,
"read-records-complete": true,
"write-records": 166351,
"write-records-complete": true
}
},
{
"id": "<vertex-id>",
"name": "Timestamps/Watermarks",
"parallelism": 2,
"status": "RUNNING",
"start-time": 1564467066441,
"end-time": -1,
"duration": 374378,
"tasks": {
"CREATED": 0,
"FINISHED": 0,
"DEPLOYING": 0,
"RUNNING": 2,
"CANCELING": 0,
"FAILED": 0,
"CANCELED": 0,
"RECONCILING": 0,
"SCHEDULED": 0
},
"metrics": {
"read-bytes": 5066280,
"read-bytes-complete": true,
"write-bytes": 5033496,
"write-bytes-complete": true,
"read-records": 166349,
"read-records-complete": true,
"write-records": 166349,
"write-records-complete": true
}
},
{
"id": "<vertex-id>",
"name": "ClickEvent Counter",
"parallelism": 2,
"status": "RUNNING",
"start-time": 1564467066469,
"end-time": -1,
"duration": 374350,
"tasks": {
"CREATED": 0,
"FINISHED": 0,
"DEPLOYING": 0,
"RUNNING": 2,
"CANCELING": 0,
"FAILED": 0,
"CANCELED": 0,
"RECONCILING": 0,
"SCHEDULED": 0
},
"metrics": {
"read-bytes": 5085332,
"read-bytes-complete": true,
"write-bytes": 316,
"write-bytes-complete": true,
"read-records": 166305,
"read-records-complete": true,
"write-records": 6,
"write-records-complete": true
}
},
{
"id": "<vertex-id>",
"name": "ClickEventStatistics Sink",
"parallelism": 2,
"status": "RUNNING",
"start-time": 1564467066476,
"end-time": -1,
"duration": 374343,
"tasks": {
"CREATED": 0,
"FINISHED": 0,
"DEPLOYING": 0,
"RUNNING": 2,
"CANCELING": 0,
"FAILED": 0,
"CANCELED": 0,
"RECONCILING": 0,
"SCHEDULED": 0
},
"metrics": {
"read-bytes": 20668,
"read-bytes-complete": true,
"write-bytes": 0,
"write-bytes-complete": true,
"read-records": 6,
"read-records-complete": true,
"write-records": 0,
"write-records-complete": true
}
}
],
"status-counts": {
"CREATED": 0,
"FINISHED": 0,
"DEPLOYING": 0,
"RUNNING": 4,
"CANCELING": 0,
"FAILED": 0,
"CANCELED": 0,
"RECONCILING": 0,
"SCHEDULED": 0
},
"plan": {
"jid": "<job-id>",
"name": "Click Event Count",
"nodes": [
{
"id": "<vertex-id>",
"parallelism": 2,
"operator": "",
"operator_strategy": "",
"description": "ClickEventStatistics Sink",
"inputs": [
{
"num": 0,
"id": "<vertex-id>",
"ship_strategy": "FORWARD",
"exchange": "pipelined_bounded"
}
],
"optimizer_properties": {}
},
{
"id": "<vertex-id>",
"parallelism": 2,
"operator": "",
"operator_strategy": "",
"description": "ClickEvent Counter",
"inputs": [
{
"num": 0,
"id": "<vertex-id>",
"ship_strategy": "HASH",
"exchange": "pipelined_bounded"
}
],
"optimizer_properties": {}
},
{
"id": "<vertex-id>",
"parallelism": 2,
"operator": "",
"operator_strategy": "",
"description": "Timestamps/Watermarks",
"inputs": [
{
"num": 0,
"id": "<vertex-id>",
"ship_strategy": "FORWARD",
"exchange": "pipelined_bounded"
}
],
"optimizer_properties": {}
},
{
"id": "<vertex-id>",
"parallelism": 2,
"operator": "",
"operator_strategy": "",
"description": "ClickEvent Source",
"optimizer_properties": {}
}
]
}
}
~~~
異なるスコープのメトリクス(TaskManager メトリクスなど)のクエリ方法を含む、可能なクエリの完全なリストについては、[REST API リファレンス](https://ci.apache.org/projects/flink/flink-docs-release-1.11/monitoring/rest_api.html#api)を参照してください。
### バリエーション
クリックイベントカウントのアプリケーションは、常に--checkpointingと--event-timeプログラムの引数で起動されていたことに気がついたかもしれません。
docker-compose.yamlのクライアントコンテナのコマンドでこれらを省略することで、ジョブの動作を変更することができます。
- --checkpointingはFlinkのフォールトトレランス機構である[チェックポイント](https://ci.apache.org/projects/flink/flink-docs-release-1.11/learn-flink/fault_tolerance.html)を有効にします。これを使わずに実行して[障害とリカバリー](https://ci.apache.org/projects/flink/flink-docs-release-1.11/try-flink/flink-operations-playground.html#observing-failure--recovery)を行うと、実際にデータが失われていることがわかるはずです。
- --event-timeはジョブの[イベントタイムセマンティクス](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/event_time.html)を有効にします。無効にすると、ジョブはClickEventのタイムスタンプではなく、壁時計の時間に基づいてウィンドウにイベントを割り当てます。その結果、ウィンドウごとのイベント数は正確には1000個にはなりません。
クリックイベントカウントアプリケーションには、デフォルトではオフになっている別のオプションもあります。
このオプションは、docker-compose.yamlのクライアントコンテナのコマンドで追加することができます。
- --backpressure は、ジョブの途中に追加の演算子を追加して、偶数分の間(例えば、10:12 の間には深刻な背圧を発生させますが、10:13 の間には発生しません)には、ジョブの途中に追加の演算子を追加します。これは、outputQueueLength や outPoolUsage などのさまざまな[ネットワークメトリクス](https://ci.apache.org/projects/flink/flink-docs-release-1.11/monitoring/metrics.html#default-shuffle-service)を検査したり、WebUI で利用可能な[バックプレッシャー監視](https://ci.apache.org/projects/flink/flink-docs-release-1.11/monitoring/back_pressure.html#monitoring-back-pressure)を使用して観察することができます。
# Flinkを学ぶ
## 概要
### トレーニングの目標と範囲
このトレーニングでは、スケーラブルなストリーミングETL、アナリティクス、イベントドリブンなアプリケーションを書き始めるのに十分な内容を含んだApache Flinkの入門書を紹介しますが、多くの(最終的に重要な)詳細は省いています。
焦点は、状態と時間を管理するためのFlinkのAPIを簡単に紹介することで、これらの基本をマスターすることで、より詳細なリファレンスドキュメントから知る必要のある残りの部分をピックアップするためのより良い装備を提供することを期待しています。
各セクションの最後にあるリンクから、より詳細な情報を得ることができます。
具体的には、以下のことを学びます。
- ストリーミングデータ処理パイプラインの実装方法
- Flinkがどのようにして状態を管理しているのか、その理由
- イベント時間を使って正確な分析を一貫して計算する方法
- 継続的なストリームでイベント駆動型アプリケーションを構築する方法
- Flinkがどのようにしてフォールトトレラントでステートフルなストリーム処理を実現しているかを、正確に一度だけのセマンティクスで表現します。
このトレーニングでは、___ストリーミングデータの連続処理、イベントタイム、ステートフルストリーム処理、状態スナップショット___という4つの重要な概念に焦点を当てています。
このページでは、これらの概念を紹介します。
`注 このトレーニングには、説明されている概念の操作方法を学ぶための実践的な演習が付属しています。各セクションの最後には、関連する練習問題へのリンクがあります。`
### ストリーム処理
ストリームはデータの自然な生息地です。
それがウェブサーバからのイベントであれ、証券取引所からの取引であれ、工場の床にある機械からのセンサーの読み取りであれ、データはストリームの一部として作成されます。
しかし、データを分析するときには、制限されたストリームと制限されていないストリームのどちらかで処理を整理することができ、これらのパラダイムのどちらを選択するかによって、重大な結果がもたらされます。
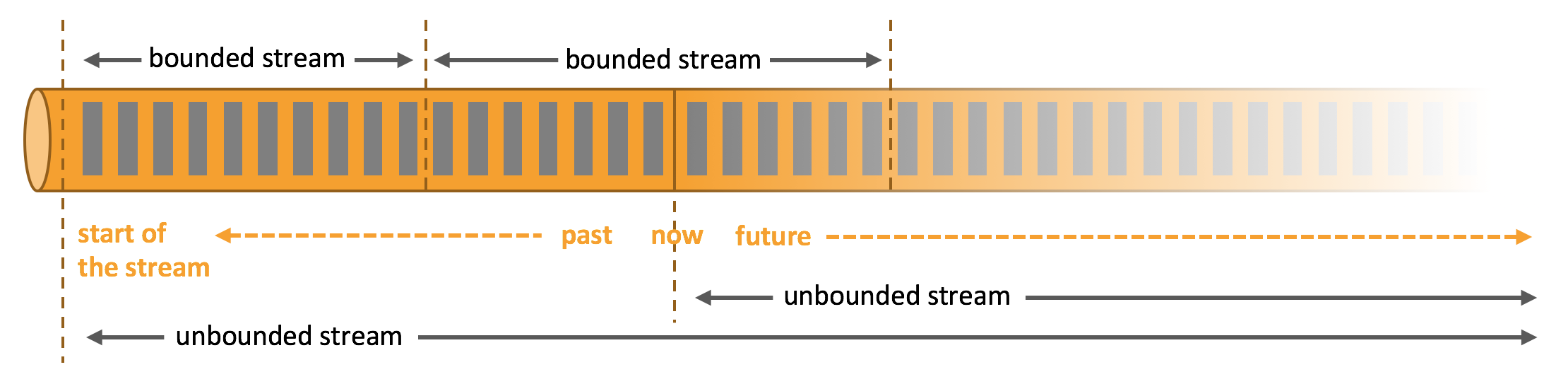
___バッチ処理___とは、制限されたデータストリームを処理する際のパラダイムです。
この操作モードでは、結果を出す前にデータセット全体をインジェストすることができます。
つまり、例えば、データをソートしたり、グローバル統計を計算したり、入力をすべて要約した最終レポートを作成したりすることができます。
___ストリーム処理___では、データのストリームには制限がありません。
概念的には、少なくとも入力が終わることはないので、データが到着したときには継続的に処理しなければなりません。
Flinkでは、アプリケーションはストリーミングデータフローで構成され、ユーザー定義の演算子によって変換されます。
これらのデータフローは、1つ以上のソースで始まり、1つ以上のシンクで終わる有向グラフを形成します。

多くの場合、プログラム内の変換とデータフロー内の演算子の間には一対一の対応関係があります。
しかし、一つの変換が複数の演算子で構成されていることもあります。
アプリケーションは、メッセージキューやApache KafkaやKinesisのような分散ログのようなストリーミングソースからリアルタイムデータを消費することがあります。
しかし、flinkは、様々なデータソースからの制限付きのヒストリカルデータを消費することもできます。
同様に、Flinkアプリケーションによって生成される結果のストリームは、シンクとして接続可能な多種多様なシステムに送ることができます。
### 並列DataFlow
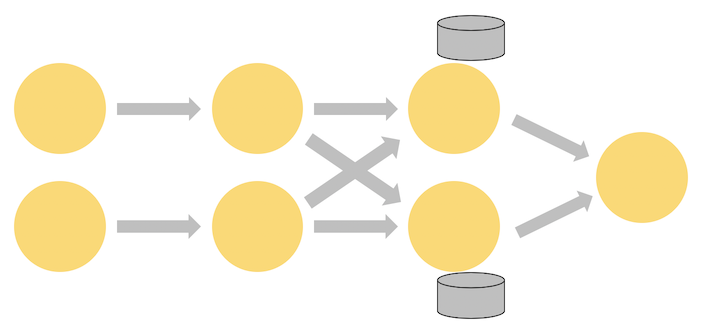
Flink のプログラムは本質的に並列分散しています。
実行中、ストリームは1つまたは複数のストリームパーティションを持ち、各演算子は1つまたは複数の演算子サブタスクを持ちます。
演算子サブタスクは互いに独立しており、異なるスレッドで実行され、場合によっては異なるマシンやコンテナ上で実行されます。
演算子サブタスクの数は、その演算子の並列性を表します。
同じプログラムの異なる演算子は、異なるレベルの並列性を持つことがあります。

ストリームは、2 つの演算子間で 1 対 1 (または転送) パターン、または再配布パターンでデータを転送することができます。
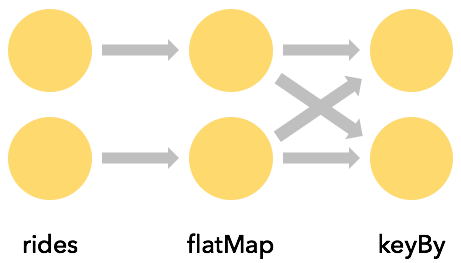
- ___一対一のストリーム(One-to-one)___(例えば、上図のソースと map()演算子の間)は、要素の分割と順序を保持します。つまり、map()演算子のサブタスク[1]は、ソース演算子のサブタスク[1]が生成したのと同じ順番で同じ要素を見ることになります。
- ___ストリームの再分配(Redistributing)___(上記の map() と keyBy/window の間や keyBy/window と Sink の間のように)は、ストリームの分割を変更します。各演算子サブタスクは、選択された変換に応じて、異なるターゲットサブタスクにデータを送信します。例としては、keyBy() (キーをハッシュ化して再分割する)、broadcast()、rebalance() (ランダムに再分割する) などがあります。再分配交換では、要素間の順序は、送信サブタスクと受信サブタスクの各ペア内でのみ保持されます(例えば、map()のサブタスク[1]とkeyBy/windowのサブタスク[2])。そのため、例えば、上に示した keyBy/window と Sink 演算子の間の再分配では、異なるキーの集約結果が Sink に到達する順序に関して非決定性が導入されています。
### タイムリーなストリーム処理
ほとんどのストリーミング・アプリケーションでは、ライブ・データの処理に使用されるのと同じコードで履歴データを再処理できることが非常に重要です。
また、イベントが処理のために配信される順番ではなく、イベントが発生した順番に注意を払い、イベントのセットがいつ完了するか(または完了すべきか)を推論できるようにすることも重要です。
例えば、電子商取引や金融取引に関わる一連のイベントを考えてみましょう。
タイムリーなストリーム処理に対するこれらの要件は、データを処理する機械の時計を使用するのではなく、データストリームに記録されたイベントタイムスタンプを使用することで満たすことができます。
### ステートフルストリーム処理
Flinkの操作はステートフルにすることができます。
つまり、あるイベントがどのように処理されるかは、それ以前に発生したすべてのイベントの累積効果に依存します。
ステートは、ダッシュボードに表示する1分間のイベント数をカウントするなどの単純なものから、不正検知モデルのための機能を計算するなどの複雑なものまで、さまざまな用途に使用できます。
Flinkアプリケーションは、分散クラスタ上で並列に実行されます。
与えられた演算子の様々な並列インスタンスは独立して、別々のスレッドで実行され、一般的には異なるマシン上で実行されます。
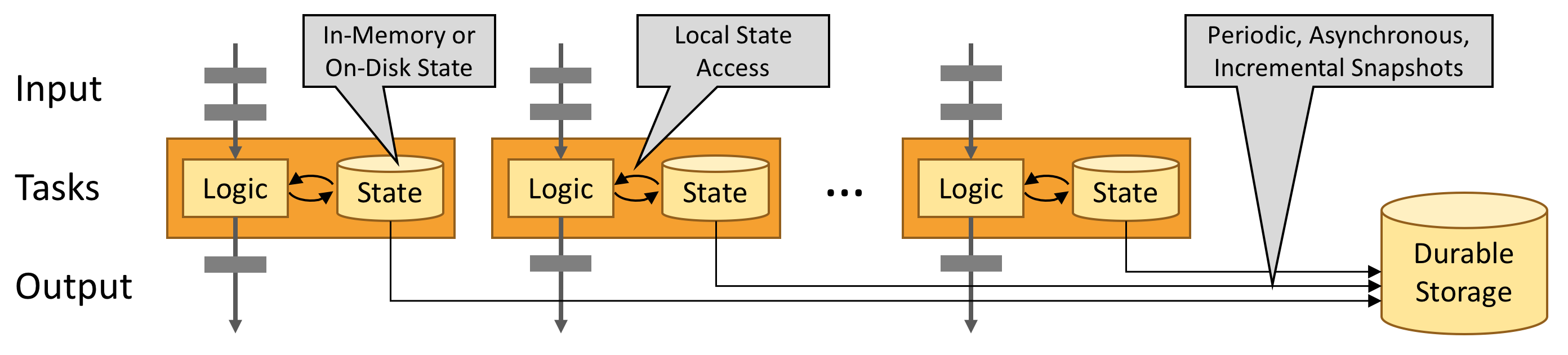
ステートフルな演算子の並列インスタンスのセットは、実質的にシャードされたキーと値のストアです。
各並列インスタンスは、特定のキーのグループに対するイベントの処理を担当し、それらのキーの状態はローカルに保持されます。
下図は、ジョブ・グラフの最初の3つの演算子の並列度が2で実行され、並列度が1のシンクで終了するジョブを示しています。
3番目の演算子はステートフルで、2番目と3番目の演算子の間で完全に接続されたネットワーク・シャッフルが発生していることがわかります。これは、ストリームを何らかのキーで分割するために行われており、一緒に処理する必要のあるすべてのイベントがそうなるようにしています。
ステートは常にローカルでアクセスされるため、Flinkアプリケーションが高いスループットと低レイテンシを実現するのに役立ちます。
ステートをJVMヒープ上に保持するか、または大きすぎる場合は、効率的に整理されたディスク上のデータ構造に保持するかを選択することができます。
### ステートスナップショットによるフォールトトレランス
Flinkは、状態スナップショットとストリーム再生の組み合わせにより、フォールトトレラントで正確な一度きりのセマンティクスを提供することができます。
これらのスナップショットは、分散パイプラインの全体の状態をキャプチャし、入力キューへのオフセットや、その時点までのデータをインジェストした結果のジョブグラフ全体の状態を記録します。
障害が発生すると、ソースが巻き戻され、状態が復元され、処理が再開されます。
上図のように、これらの状態スナップショットは、進行中の処理を妨げることなく、非同期的にキャプチャされます。
## DataFlow APIの紹介
このトレーニングの焦点は、ストリーミングアプリケーションを書き始めることができるように、DataStream APIを幅広くカバーすることです。
### 何がストリームできるのか
FlinkのJavaとScala用のDataStream APIは、それらがシリアライズできるものなら何でもストリーミングできるようにしてくれます。
Flink独自のシリアライザは
- 基本型(String、Long、Integer、Boolean、Arrayなど)
- 複合型(タプル、POJO、Scalaのケースクラス)
上記を使用し、Flink は他のタイプでは Kryo にフォールバックします。
また、Flinkで他のシリアライザを使用することも可能です。
特に Avro はよくサポートされています。
#### JavaのタプルとPOJOs
Flinkのネイティブシリアライザは、タプルやPOJOを効率的に操作することができます。
##### Tuples
Javaの場合、Flinkは独自のTuple0からTuple25までの型を定義しています。
~~~java
Tuple2<String, Integer> person = Tuple2.of("Fred", 35);
// zero based index!
String name = person.f0;
Integer age = person.f1;
~~~
##### POJOs
Flinkは、以下の条件を満たす場合、データ型をPOJO型として認識します(そして"by-name"フィールド参照を許可します)。
- クラスがパブリックでスタンドアロンである(非静的な内部クラスがない)
- このクラスには、引数なしのパブリックなコンストラクタがあります
- クラス(およびすべてのスーパークラス)内のすべての非静的で非一過性のフィールドは、パブリック(および非最終)であるか、Java beansのゲッターとセッターの命名規則に従ったパブリックなゲッターとセッターのメソッドを持っています。
例:
~~~java
public class Person {
public String name;
public Integer age;
public Person() {};
public Person(String name, Integer age) {
. . .
};
}
Person person = new Person("Fred Flintstone", 35);
~~~
Flinkのシリアライザは[POJO型のスキーマ進化をサポートしています。](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/stream/state/schema_evolution.html#pojo-types)
#### Scalaのタプルとケースクラス
期待通りの働きをしてくれます。
### 完全な例
この例では、人々に関する記録のストリームを入力として受け取り、成人のみを含むようにフィルタリングします。
~~~java
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.api.common.functions.FilterFunction;
public class Example {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Person> flintstones = env.fromElements(
new Person("Fred", 35),
new Person("Wilma", 35),
new Person("Pebbles", 2));
DataStream<Person> adults = flintstones.filter(new FilterFunction<Person>() {
@Override
public boolean filter(Person person) throws Exception {
return person.age >= 18;
}
});
adults.print();
env.execute();
}
public static class Person {
public String name;
public Integer age;
public Person() {};
public Person(String name, Integer age) {
this.name = name;
this.age = age;
};
public String toString() {
return this.name.toString() + ": age " + this.age.toString();
};
}
}
~~~
#### ストリーム実行環境
すべての Flink アプリケーションには実行環境が必要で、この例では env を使用します。
ストリーミングアプリケーションはStreamExecutionEnvironmentを使用する必要があります。
アプリケーション内で行われる DataStream API の呼び出しは、StreamExecutionEnvironment にアタッチされたジョブグラフを作成します。
env.execute() が呼び出されると、このグラフはパッケージ化されて JobManager に送られ、ジョブを並列化してタスクマネージャにスライスを配布して実行します。
ジョブの各並列スライスはタスクスロットで実行されます。
execute() を呼び出さないと、アプリケーションは実行されないことに注意してください。

この分散ランタイムは、アプリケーションがシリアライズ可能であることに依存します。
また、すべての依存関係がクラスタ内の各ノードで利用可能である必要があります。
#### 基本的なStream sources
上の例では、env.fromElements(....)を使ってDataStream<Person>を構築しています。
これは、プロトタイプやテストで使用するためのシンプルなストリームをまとめるのに便利な方法です。
また、StreamExecutionEnvironmentにはfromCollection(Collection)メソッドもあります。その代わりに、次のようにすることができます。
~~~java
List<Person> people = new ArrayList<Person>();
people.add(new Person("Fred", 35));
people.add(new Person("Wilma", 35));
people.add(new Person("Pebbles", 2));
DataStream<Person> flintstones = env.fromCollection(people);
~~~
プロトタイプを作成している間にデータをストリームに取り込むもう一つの便利な方法は、ソケットを使うことです。
~~~java
DataStream<String> lines = env.socketTextStream("localhost", 9999)
~~~
または
~~~java
DataStream<String> lines = env.readTextFile("file:///path");
~~~
実際のアプリケーションで最も一般的に使用されるデータソースは、Apache Kafka、Kinesis、様々なファイルシステムなど、高性能と耐障害性の前提条件である巻き戻しと再生を組み合わせた低レイテンシ、高スループットの並列読み取りをサポートするものです。
また、REST APIやデータベースは、ストリームエンリッチメントのために頻繁に使用されています。
#### 基本的なStream sinks
上の例では、その結果をタスクマネージャのログに出力するために Adults.print() を使用しています (IDE で実行している場合は、IDE のコンソールに表示されます)
これは、ストリームの各要素に対して toString() を呼び出します。
出力は以下のようになります。
1> フレッド:35歳
2>ウィルマ:35歳
ここで、1> と 2> は出力を生成したサブタスク(つまりスレッド)を示します。
プロダクションでは、一般的に使用されているシンクには、StreamingFileSink、様々なデータベース、そしていくつかのパブサブシステムがあります。
#### デバッグ
本番環境では、アプリケーションはリモートのクラスタまたはコンテナのセットで実行されます。
そして、障害が発生した場合、リモートで障害が発生します。
JobManager や TaskManager のログはそのような障害のデバッグに非常に役立ちますが、Flink がサポートしている IDE 内でローカルデバッグを行う方がはるかに簡単です。
ブレークポイントを設定したり、ローカル変数を調べたり、コードをステップスルーしたりすることができます。
また、Flinkのコードを覗き込むこともでき、Flinkがどのように動作するかに興味がある場合には、Flinkの内部をより詳しく知ることができます。
### ハンズオン
この時点で、シンプルなDataStreamアプリケーションのコーディングと実行を始めるのに十分な知識があります。
[flink-trainingレポ](https://github.com/apache/flink-training/tree/release-1.11)をクローンし、READMEの指示に従った後、最初のエクササイズを行います。
[ストリームのフィルタリング(ライドクレンジング)](https://github.com/apache/flink-training/tree/release-1.11/ride-cleansing)を行います。
### 続きをさらに読む
- [Flink Serialization Tuning Vol. 1: Choosing your Serializer — if you can](https://flink.apache.org/news/2020/04/15/flink-serialization-tuning-vol-1.html)
- [Anatomy of a Flink Program](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/datastream_api.html#anatomy-of-a-flink-program)
- [Data Sources](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/datastream_api.html#data-sources)
- [Data Sinks](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/datastream_api.html#data-sinks)
- [DataStream Connectors](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/connectors/)
## データパイプラインとETL
Apache Flink の非常に一般的なユースケースとしては、1つ以上のソースからデータを取得し、変換や濃縮を行い、その結果をどこかに保存する ETL (extract, transform, load) パイプラインを実装することがあります。
このセクションでは、この種のアプリケーションを実装するためにFlinkのDataStream APIを使用する方法を見ていきます。
Flinkの[TableとSQL API](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/table/)は、多くのETLユースケースに適していることに注意してください。
しかし、最終的にDataStream APIを直接使用するかどうかに関わらず、ここで紹介した基本をしっかりと理解しておくことは貴重なものになるでしょう。
### ステートレス変換
このセクションでは、ステートレス変換を実装するために使用される基本的な操作である map() と flatmap() について説明します。
このセクションの例では、[flink-trainingレポ](https://github.com/apache/flink-training/tree/release-1.11)のハンズオン演習で使用されているTaxi Rideデータに精通していることを前提としています。
#### map()
最初の演習では、タクシー乗車イベントのストリームをフィルタリングしました。
その同じコードベースには、静的メソッドGeoUtils.mapToGridCell(float lon, float lat)を提供するGeoUtilsクラスがあり、サイズが約100x100メートルの領域を参照するグリッドセルに位置(経度、緯度)をマップします。
それでは、各イベントにstartCellとendCellフィールドを追加することで、タクシー乗車オブジェクトのストリームを豊かにしてみましょう。
これらのフィールドを追加して、TaxiRideを拡張したEnrichedRideオブジェクトを作成することができます。
~~~java
public static class EnrichedRide extends TaxiRide {
public int startCell;
public int endCell;
public EnrichedRide() {}
public EnrichedRide(TaxiRide ride) {
this.rideId = ride.rideId;
this.isStart = ride.isStart;
...
this.startCell = GeoUtils.mapToGridCell(ride.startLon, ride.startLat);
this.endCell = GeoUtils.mapToGridCell(ride.endLon, ride.endLat);
}
public String toString() {
return super.toString() + "," +
Integer.toString(this.startCell) + "," +
Integer.toString(this.endCell);
}
}
~~~
そして、ストリームを変換するアプリケーションを作成することができます。
~~~java
DataStream<TaxiRide> rides = env.addSource(new TaxiRideSource(...));
DataStream<EnrichedRide> enrichedNYCRides = rides
.filter(new RideCleansingSolution.NYCFilter())
.map(new Enrichment());
enrichedNYCRides.print();
~~~
MapFunctionの利用:
~~~java
public static class Enrichment implements MapFunction<TaxiRide, EnrichedRide> {
@Override
public EnrichedRide map(TaxiRide taxiRide) throws Exception {
return new EnrichedRide(taxiRide);
}
}
~~~
#### flatmap()
MapFunction は、一対一の変換を行う場合にのみ適しています: 入ってくる各ストリーム要素に対して、 map() は変換された要素を一つずつ出力します。
それ以外の場合は flatmap() を使用します。
~~~java
DataStream<TaxiRide> rides = env.addSource(new TaxiRideSource(...));
DataStream<EnrichedRide> enrichedNYCRides = rides
.flatMap(new NYCEnrichment());
enrichedNYCRides.print();
~~~
FlatMapFunctionとの処理:
~~~java
public static class NYCEnrichment implements FlatMapFunction<TaxiRide, EnrichedRide> {
@Override
public void flatMap(TaxiRide taxiRide, Collector<EnrichedRide> out) throws Exception {
FilterFunction<TaxiRide> valid = new RideCleansing.NYCFilter();
if (valid.filter(taxiRide)) {
out.collect(new EnrichedRide(taxiRide));
}
}
}
~~~
このインターフェイスで提供されている Collector を使用すると、flatmap() メソッドはストリーム要素を好きなだけ出力することができます。
### キー付きストリーム
#### KeyBy()
ストリームを属性の一つを中心に分割できると、その属性の同じ値を持つすべてのイベントをグループ化することができ、非常に便利なことがよくあります。
例えば、グリッドの各セルから始まる最長のタクシー乗車時間を見つけたいとします。
SQLクエリの観点から考えると、これはstartCellでGROUP BYを行うことを意味しますが、FlinkではこれはkeyBy(KeySelector)で行われます。
~~~java
rides
.flatMap(new NYCEnrichment())
.keyBy(value -> value.startCell)
~~~
keyBy のたびにネットワークシャッフルが発生し、ストリームを再分割します。
一般的に、これはシリアライズとデシリアライズに加えてネットワーク通信を伴うため、かなり高価なものになります。
上の例では、キーは "startCell "というフィールド名で指定されています。
このスタイルのキー選択には、コンパイラがキー入力に使用されるフィールドの型を推測できないという欠点があり、Flinkはキーの値をタプルとして渡してしまいます。
適切にタイプされた KeySelector を使用する方が良いでしょう。
~~~java
rides
.flatMap(new NYCEnrichment())
.keyBy(
new KeySelector<EnrichedRide, int>() {
@Override
public int getKey(EnrichedRide enrichedRide) throws Exception {
return enrichedRide.startCell;
}
})
~~~
これはラムダでより簡潔に表現することができます。
~~~java
rides
.flatMap(new NYCEnrichment())
.keyBy(enrichedRide -> enrichedRide.startCell)
~~~
#### Keysの計算
KeySelectors は、イベントからキーを抽出するだけではありません。
結果として得られるキーが決定論的であり、hashCode() や equals() の有効な実装を持っている限りは、好きなようにキーを計算することができます。
この制限により、乱数を生成したり、配列や列挙型を返す KeySelectors は除外されますが、例えばタプルや POJO を用いた複合鍵を作成することは可能です。
キーは決定論的な方法で生成されなければなりません。
なぜなら、キーはストリームレコードに添付されるのではなく、必要なときにいつでも再計算されるからです。
例えば、startCellフィールドを持つ新しいEnrichedRideクラスを作成し、それを
~~~java
keyBy(enrichedRide -> enrichedRide.startCell)
~~~
私たちは以下のようにすることができます.
~~~java
keyBy(ride -> GeoUtils.mapToGridCell(ride.startLon, ride.startLat))
~~~
#### Keys付きストリームの集約
このビットコードは、各エンドオブライドイベントの開始セルと持続時間(分単位)を含むタプルの新しいストリームを作成します。
~~~java
import org.joda.time.Interval;
DataStream<Tuple2<Integer, Minutes>> minutesByStartCell = enrichedNYCRides
.flatMap(new FlatMapFunction<EnrichedRide, Tuple2<Integer, Minutes>>() {
@Override
public void flatMap(EnrichedRide ride,
Collector<Tuple2<Integer, Minutes>> out) throws Exception {
if (!ride.isStart) {
Interval rideInterval = new Interval(ride.startTime, ride.endTime);
Minutes duration = rideInterval.toDuration().toStandardMinutes();
out.collect(new Tuple2<>(ride.startCell, duration));
}
}
});
~~~
これで、各startCellに対して、これまでに見た中で最も長いライド(その時点までのライド)だけを含むストリームを生成することが可能になりました。
キーとして使用するフィールドを表現する方法は様々です。
先ほど、EnrichedRide POJOの例を見ましたが、ここではキーとして使用するフィールドがその名前で指定されていました。
この例では、Tuple2オブジェクトを使用しており、タプル内のインデックス(0から始まる)がキーを指定するために使用されています。
~~~java
minutesByStartCell
.keyBy(value -> value.f0) // .keyBy(value -> value.startCell)
.maxBy(1) // duration
.print();
~~~
出力ストリームには、持続時間が新しい最大値に達するたびに、各キーのレコードが含まれるようになりました。
~~~
...
4> (64549,5M)
4> (46298,18M)
1> (51549,14M)
1> (53043,13M)
1> (56031,22M)
1> (50797,6M)
...
1> (50797,8M)
...
1> (50797,11M)
...
1> (50797,12M)
~~~
#### (暗黙の)状態
これは、ステートフル・ストリーミングを含むこのトレーニングの最初の例です。
ステートは透過的に処理されていますが、Flinkは各キーの最大持続時間を追跡しなければなりません。
アプリケーションにステートが関与するときはいつでも、ステートがどれだけ大きくなるかを考える必要があります。
キー空間に制限がないときはいつでも、Flinkが必要とするステートの量も同じです。
ストリームを扱う場合、一般的には、ストリーム全体ではなく、有限のウィンドウの集約という観点から考える方が理にかなっています。
#### reduce()などのアグリゲータ
上記で使用した maxBy() は、Flink の KeyedStream で利用可能なアグリゲータ関数の一例です。
また、より汎用的な reduce() 関数もあり、独自のアグリゲーションを実装することができます。
### ステートフル変換
#### なぜFlinkがステート管理に関与するか
アプリケーションはFlinkが管理に関与しなくてもステートを使用することができますが、Flinkはステートを管理するためにいくつかの魅力的な機能を提供しています.
- それはローカルです。ローカル: Flinkのステートは処理するマシンのローカルに保持され、メモリ速度でアクセスできます。
- 耐久性があります。フリンク状態は耐障害性があり、定期的に自動的にチェックポイントされ、故障時に復元されます。
- 垂直方向にスケーラブルです。ローカルディスクを追加することでスケールする埋め込み型のRocksDBインスタンスにFlinkの状態を保持することができます。
- 水平方向にスケーラブルです。クラスタの成長や縮小に応じて、フリンクの状態が再分配されます。
- クエリー可能です。Flink のステートは、[Queryable State API](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/stream/state/queryable_state.html) を使用して外部から問い合わせることができます。
このセクションでは、キー付きステートを管理する Flink の API を使用した作業方法について説明します。
#### 豊富な機能
この時点で、FilterFunction、MapFunction、FlatMapFunction など、Flink の関数インタフェースのいくつかをすでに見てきました。
これらはすべて Single Abstract Method パターンの例です。
これらのインターフェイスのそれぞれについて、Flink はいわゆる「リッチ」バリアント、例えば RichFlatMapFunction も提供しており、以下のような追加メソッドを持っています。
- open(Configuration c)
- close()
- getRuntimeContext()
open() は、オペレータの初期化中に一度だけ呼び出されます。
これは、静的データをロードしたり、外部サービスへの接続を開いたりする機会です。
getRuntimeContext() は、潜在的に興味深いもののスイート全体へのアクセスを提供しますが、最も注目すべきは、Flink によって管理されている状態を作成してアクセスする方法です。
#### キー付き状態の例
この例では、重複排除したいイベントのストリームがあるとします。Deduplicator と呼ばれる RichFlatMapFunction を使って、それを行うアプリケーションを紹介します。
~~~java
private static class Event {
public final String key;
public final long timestamp;
...
}
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.addSource(new EventSource())
.keyBy(e -> e.key)
.flatMap(new Deduplicator())
.print();
env.execute();
}
~~~
これを達成するためには、Deduplicatorは各キーについて、そのキーのイベントが既に発生しているかどうかを何らかの方法で記憶する必要がある。
これはFlinkのキー付きステート・インターフェースを使って行う。
このようなキー付きストリームを扱う場合、Flinkは管理されている状態の各アイテムのキー/値のストアを保持します。
Flink はいくつかの異なるタイプのキー付きステートをサポートしていますが、この例では最もシンプルなもの、すなわち ValueState を使用しています。
つまり、各キーに対して、Flinkは1つのオブジェクト(この場合はBoolean型のオブジェクト)を保存することになります。
Deduplicator クラスには open() と flatMap() の 2 つのメソッドがあります。
openメソッドは、ValueStateDescriptor<Boolean>を定義することで、管理された状態の使用を確立します。
コンストラクタへの引数は、キー付き状態のこの項目の名前("keyHasBeenSeen")を指定し、これらのオブジェクトをシリアライズするために使用できる情報を提供します(この場合、Types.BOOLEAN)
~~~java
public static class Deduplicator extends RichFlatMapFunction<Event, Event> {
ValueState<Boolean> keyHasBeenSeen;
@Override
public void open(Configuration conf) {
ValueStateDescriptor<Boolean> desc = new ValueStateDescriptor<>("keyHasBeenSeen", Types.BOOLEAN);
keyHasBeenSeen = getRuntimeContext().getState(desc);
}
@Override
public void flatMap(Event event, Collector<Event> out) throws Exception {
if (keyHasBeenSeen.value() == null) {
out.collect(event);
keyHasBeenSeen.update(true);
}
}
}
~~~
flatMap メソッドが keyHasBeenSeen.value() を呼び出すと、Flink のランタイムは、コンテキスト内のキーの状態のこの部分の値を調べ、それが null である場合にのみ、イベントを出力に収集します。
また、この場合はkeyHasBeenSeenをtrueに更新します。
キーがDeduplicatorの実装では明示的に表示されていないため、このようにキー分割された状態にアクセスしたり更新したりするメカニズムは不思議に思えるかもしれません。
Flink のランタイムが RichFlatMapFunction の open メソッドを呼び出すとき、イベントは発生せず、その時点ではコンテキスト内にキーは存在しません。
しかし、flatMap メソッドを呼び出すと、処理されているイベントのキーがランタイムに提供され、Flink のステートバックエンドのどのエントリが操作されているかを判断するために舞台裏で使用されます。
分散クラスタにデプロイされた場合、この Deduplicator のインスタンスが多数存在し、それぞれが鍵空間全体の不連続なサブセットを担当することになります。
したがって、以下のような ValueState の単一の項目を見たときには
~~~java
ValueState<Boolean> keyHasBeenSeen;
~~~
これは単一のブール値ではなく、分散されたシャードされたキー/値のストアを表していることを理解してください。
#### クリアリング状態
上の例には潜在的な問題があります。
キー空間が束縛されていない場合はどうなるのでしょうか?
Flinkは、使用される個別のキーごとにBooleanのインスタンスをどこかに保存しています。
鍵のセットが制限されている場合は問題ありませんが、鍵のセットが制限されていない方法で増加しているアプリケーションでは、不要になった鍵の状態をクリアする必要があります。
これは、以下のように state オブジェクトに対して clear() を呼び出すことで行います。
~~~java
keyHasBeenSeen.clear()
~~~
例えば、指定したキーが一定期間使用されていない場合などにこれを行いたいと思うかもしれません。
これを行うためにタイマーを使用する方法については、イベント駆動型アプリケーションのセクションでProcessFunctionsについて学ぶときに説明します。
[ステートタイムトゥライブ(TTL)オプション](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/stream/state/state.html#state-time-to-live-ttl)もあり、 ステートディスクリプタで設定することができ、 ステートが古くなった鍵の状態を自動的にクリアするタイミングを指定することができます。
#### ノンキー状態
また、キーを持たないコンテキストで管理された状態で作業することも可能です。
これは[演算子状態](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/stream/state/state.html#operator-state)と呼ばれることもあります。
関係するインターフェースは多少異なり、ユーザー定義関数が非キー状態を必要とすることは珍しいので、ここでは取り上げません。
この機能は、ソースとシンクの実装で最もよく使われます。
### 接続されたストリーム
このようにあらかじめ定義された変換を適用するのではなく、時々、このような変換を適用します。

しきい値やルール、その他のパラメータをストリーミングすることで、変換のいくつかの側面を動的に変更できるようにしたい場合があります。
これをサポートするFlinkのパターンは、コネクテッドストリームと呼ばれるもので、1つの演算子が2つの入力ストリームを持っています。

接続されたストリームは、ストリーミング結合を実装するために使用することもできます。
#### 例
この例では、streamOfWordsからフィルタリングする必要のある単語を指定するためにコントロールストリームを使用しています。
ControlFunction と呼ばれる RichCoFlatMapFunction を接続されたストリームに適用して、これを実現しています。
~~~java
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> control = env.fromElements("DROP", "IGNORE").keyBy(x -> x);
DataStream<String> streamOfWords = env.fromElements("Apache", "DROP", "Flink", "IGNORE").keyBy(x -> x);
control
.connect(datastreamOfWords)
.flatMap(new ControlFunction())
.print();
env.execute();
}
~~~
接続される 2 つのストリームは、互換性のある方法でキーが設定されている必要があることに注意してください。
keyBy の役割はストリームのデータを分割することであり、キーが設定されたストリームが接続されている場合は、同じ方法で分割されている必要があります。
これにより、同じキーを持つ両方のストリームからのすべてのイベントが同じインスタンスに送信されるようになります。
さらに、例えば、そのキーで2つのストリームを結合することが可能になります。
この場合、ストリームは両方とも DataStream<String> 型で、両方のストリームのキーは文字列です。以下に示すように、この RichCoFlatMapFunction は Boolean 値をキー付きの状態で格納しており、この Boolean は 2 つのストリームで共有されています。
~~~java
public static class ControlFunction extends RichCoFlatMapFunction<String, String, String> {
private ValueState<Boolean> blocked;
@Override
public void open(Configuration config) {
blocked = getRuntimeContext().getState(new ValueStateDescriptor<>("blocked", Boolean.class));
}
@Override
public void flatMap1(String control_value, Collector<String> out) throws Exception {
blocked.update(Boolean.TRUE);
}
@Override
public void flatMap2(String data_value, Collector<String> out) throws Exception {
if (blocked.value() == null) {
out.collect(data_value);
}
}
}
~~~
RichCoFlatMapFunctionは、接続されたストリームのペアに適用できるFlatMapFunctionの一種であり、リッチ関数インタフェースへのアクセス権を持っています。
つまり、ステートフルにすることができます。
ブロックされたBooleanは、制御ストリーム上で言及されたキー(ここでは単語)を記憶するために使用されており、それらの単語はstreamOfWordsストリームからフィルタリングされています。
これがキー付きの状態であり、2つのストリーム間で共有されているため、2つのストリームは同じキー空間を共有しなければならない。
flatMap1とflatMap2は、接続された2つのストリームのそれぞれからの要素を持ってFlinkランタイムによって呼び出されます.
私たちの場合、制御ストリームからの要素はflatMap1に渡され、streamOfWordsからの要素はflatMap2に渡されます。
これは、control.connect(datastreamOfWords) で 2 つのストリームが接続される順序によって決定されました。
重要なのは、flatMap1 と flatMap2 のコールバックが呼び出される順序を制御できないということです。
これらの 2 つの入力ストリームは互いに競合しており、Flink ランタイムはどちらか一方のストリームからイベントを消費するか、または他方のストリームからイベントを消費するかについて、好きなように実行します。
タイミングや順序が重要な場合、アプリケーションが処理できるようになるまで、管理された Flink の状態でイベントをバッファリングする必要があるかもしれません。
``(注意: もし本当に必要ならば、[InputSelectable](https://ci.apache.org/projects/flink/flink-docs-release-1.11/api/java/org/apache/flink/streaming/api/operators/InputSelectable.html)インターフェイスを実装したカスタムオペレータを使用して、2入力オペレータが入力を消費する順序を限定的に制御することができます)``
### ハンズオン
このセクションに付随するハンズオンエクササイズが[「乗り物と運賃のエクササイズ」](https://github.com/apache/flink-training/tree/release-1.11/rides-and-fares)です。
### 続きを読む
- [DataStream Transformations](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/stream/operators/#datastream-transformations)
- [Stateful Stream Processing](https://ci.apache.org/projects/flink/flink-docs-release-1.11/concepts/stateful-stream-processing.html)
## ストリーミング分析
### イベント時間とWatermarks
#### 導入
Flinkは3つの異なる___時間の概念___を明示的にサポートしています。
- イベント時間: イベントを生成(または保存)するデバイスによって記録された、イベントが発生した時間
- インジェスト時間:イベントをインジェストした瞬間にFlinkが記録したタイムスタンプ
- 処理時間:パイプライン内の特定のオペレータがイベントを処理している時間
再現性のある結果を得るためには、例えば、ある日の取引の最初の時間に到達した株価の最高値を計算する場合、イベントタイムを使用する必要があります。
この方法では、結果は計算が実行された時間に依存しません。
このようなリアルタイムアプリケーションは処理時間を使用して実行されることもありますが、その場合、結果はその時に発生したイベントではなく、その時間にたまたま処理されたイベントによって決定されます。
処理時間に基づいてアナリティクスを計算すると矛盾が生じ、履歴データの再分析や新しい実装のテストが困難になります。
#### イベント時間を使った作業
デフォルトでは、Flink は処理時間を使用します。これを変更するには、Time Characteristicを設定します。
~~~java
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
~~~
イベントタイムを使用したい場合は、Flinkがイベントタイムの進行状況を追跡するために使用するTimestamp ExtractorとWatermark Generatorも必要になります。これについては、以下の[「Watermarksを使った作業」](https://ci.apache.org/projects/flink/flink-docs-release-1.11/learn-flink/streaming_analytics.html#working-with-watermarks)のセクションで説明しますが
まず、Watermarksとは何かを説明します。
#### Watermarks
なぜWatermarksが必要なのか、また、Watermarksがどのように機能するのか、簡単な例を見てみましょう。
この例では、以下に示すように、タイムスタンプ付きのイベントのストリームがあります。表示されている数字は、これらのイベントが実際にいつ発生したかを示すタイムスタンプです。最初に到着したイベントは時刻 4 に発生し、それより前に発生したイベント、時刻 2 に発生したイベントがそれに続いています。
··· 23 19 22 24 21 14 17 13 12 15 9 11 7 2 4 →
ストリームソーターを作ろうとしていると想像してください。
これは、到着したストリームから各イベントを処理し、同じイベントをタイムスタンプ順に並べた新しいストリームを生成するアプリケーションを意味しています。
いくつかの注意点があります。
(1) ストリームソーターが最初に見る要素は 4 ですが、ソートされたストリームの最初の要素としてすぐにリリースすることはできません。
それは順番通りに到着していないかもしれませんし、それ以前のイベントがまだ到着しているかもしれません。
実際、あなたはこのストリームの未来についての神のような知識の恩恵を受けており、あなたのストリームソーターは結果を出す前に少なくとも2が到着するまで待つべきであることがわかります。
ある程度のバッファリングと、ある程度の遅延が必要である。
(2) これを間違えると、永遠に待つことになるかもしれません。
ソーターは最初に時刻4からのイベントを見て、次に時刻2からのイベントを見ました。
タイムスタンプが2よりも小さいイベントは到着するでしょうか?あるかもしれない。
そうではないかもしれません。永遠に待っても1を見ないかもしれない。
最終的には勇気を持って、ソートされたストリームの開始点として2を放出しなければなりません。
(3) そこで必要なのは、任意のタイムスタンプ付きイベントについて、いつまでにそれより前のイベントの到着を待つのをやめるかを定義するポリシーのようなものです。
これはまさにウォーターマークが行うことであり、以前のイベントの到着を待つのをやめるタイミングを定義します。
Flinkでのイベントの時間処理は、ウォーターマークと呼ばれる特別なタイムスタンプ要素をストリームに挿入するウォーターマークジェネレータに依存しています。時刻 t の透かしは、ストリームが(おそらく)時刻 t までに完了したことを表明しています。
このストリームソーターはいつ待機を停止し、ソートされたストリームを開始するために2を押し出すべきでしょうか? 2以上のタイムスタンプを持つウォーターマークが到着したときです。
(4) ウォーターマークを生成する方法を決定するための異なるポリシーを想像するかもしれません。
各イベントは何らかの遅延を経て到着しますが、この遅延は様々なので、いくつかのイベントは他のイベントよりも遅延が大きくなります。
1つの簡単なアプローチは、これらの遅延がある最大遅延によって制限されていると仮定することです。
Flinkはこの戦略を bounded-out-of-ordererness watermarkingと呼んでいます。
ウォーターマークに対するより複雑なアプローチを想像するのは簡単ですが、ほとんどのアプリケーションでは固定遅延で十分に機能します。
#### 遅延と完全性
ウォーターマークについて考えるもう一つの方法は、ストリーミングアプリケーションの開発者であるあなたに、待ち時間と完全性の間のトレードオフをコントロールできるようにするということです。
バッチ処理とは異なり、結果を出す前に入力を完全に把握することができるという贅沢がありますが、ストリーミングでは、最終的には入力の詳細を見るのを待つのをやめて、ある種の結果を出さなければなりません。
短く制限された遅延を使って積極的にウォーターマークを設定することができ、それによって、入力についての不完全な知識を持ったまま結果を出すリスクを冒すことができます。
あるいは、より長く待って、入力ストリームのより完全な知識を持っていることを利用した結果を生成することもできます。
また、初期結果を迅速に生成し、追加の(遅い)データが処理されたときにその結果の更新を提供するハイブリッドソリューションを実装することも可能です。
これは、いくつかのアプリケーションに適したアプローチです。
#### 遅延
遅延はウォーターマークとの相対的な関係で定義されます。
ウォーターマーク(t)は、時刻tまでのストリームが完全であることを保証します。
このウォーターマークに続くイベントでタイムスタンプが≦tのものはすべて遅刻です。
#### Watermarkを使った作業
イベント時間ベースのイベント処理を実行するためには、Flink は各イベントに関連付けられた時間を知る必要があり、また、ストリームにウォーターマークを含める必要があります。
実習で使用したTaxiデータソースがこれらの詳細を処理してくれます。
これは通常、イベントからタイムスタンプを抽出し、要求に応じてウォーターマークを生成するクラスを実装することで行われます。
これを行う最も簡単な方法は、WatermarkStrategy を使用することです。
~~~java
DataStream<Event> stream = ...
WatermarkStrategy<Event> strategy = WatermarkStrategy
.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(20))
.withTimestampAssigner((event, timestamp) -> event.timestamp);
DataStream<Event> withTimestampsAndWatermarks =
stream.assignTimestampsAndWatermarks(strategy);
~~~
### ウィンドウ
Flink は非常に表現力豊かなウィンドウセマンティクスを特徴としています。
このセクションでは、以下のことを学びます。
- 束縛されていないストリームの集約を計算するためにウィンドウがどのように使われているか。
- Flink がサポートしているウィンドウの種類
- ウィンドウアグリゲーションを使用したDataStreamプログラムの実装方法
#### 導入
ストリーム処理を行う際に、以下のような質問に答えるために、ストリームの限られたサブセットに集約されたアナリティクスを計算したいと考えるのは自然なことです。
- 1分間のページビュー数
- 一週間のユーザーあたりのセッション数
- センサー毎分最高温度
Flinkでウィンドウ分析を計算するには、2つの主要な抽象化に依存します。
ウィンドウにイベントを割り当てる(必要に応じて新しいウィンドウオブジェクトを作成する)ウィンドウアシグナと、ウィンドウに割り当てられたイベントに適用されるウィンドウ関数です。
FlinkのウィンドウAPIには、ウィンドウ関数を呼び出すタイミングを決定するTriggersと、ウィンドウに集められた要素を削除するEvictorの概念もあります。
基本的な形では、以下のようなキー付きストリームにウィンドウ処理を適用します。
~~~java
stream.
.keyBy(<key selector>)
.window(<window assigner>)
.reduce|aggregate|process(<window function>)
~~~
キーを持たないストリームでウィンドウ処理を使うこともできますが、この場合は並列処理にならないことに注意してください。
~~~java
stream.
.windowAll(<window assigner>)
.reduce|aggregate|process(<window function>)
~~~
#### ウィンドウアサイン
Flinkにはいくつかのウィンドウアサイザーが組み込まれており、以下のように説明されています。

これらのウィンドウアサイザーが何のために使われるかの例と、それらを指定する方法をいくつか紹介します。
- タンブリング時間ウィンドウ
- 毎分ページビュー
- TumblingEventTimeWindows.of(Time.minutes(1))
- スライディングタイムウィンドウ
- 10秒ごとに計算された毎分ページビュー
- SlidingEventTimeWindows.of(Time.minutes(1), Time.seconds(10))
- セッションウィンドウ
- セッションはセッション間のギャップが30分以上あることで定義されます
- EventTimeSessionWindows.withGap(Time.minutes(30))
時間は、Time.ミリ秒(n)、Time.秒(n)、Time.分(n)、Time.時(n)、Time.日(n)のいずれかを使用して指定することができます。
時間ベースのウィンドウアサイザ(セッションウィンドウを含む)には、イベント時間と処理時間の両方の種類があります。
これら2種類の時間ウィンドウの間には大きなトレードオフがあります。
処理時間ウィンドウでは、これらの制限を受け入れなければなりません。
- 履歴データを正しく処理できない。
- 順序外のデータを正しく扱うことができません。
- 結果は非決定論的なものになります。
- レイテンシーが低いという利点があります。
カウントベースのウィンドウを使用する場合、バッチが完了するまでウィンドウは起動しないことに注意してください。
タイムアウトして部分的なウィンドウを処理するオプションはありませんが、カスタムトリガーでそのような動作を実装することは可能です。
グローバルウィンドウアサイン機能は、すべてのイベント(同じキーで)を同じグローバルウィンドウに割り当てます。
これは、カスタムトリガーを使って独自のウィンドウ処理を行う場合にのみ有用です。
多くの場合、これが便利そうに見えるかもしれませんが、[別のセクション](https://ci.apache.org/projects/flink/flink-docs-release-1.11/learn-flink/event_driven.html#process-functions)で説明するように ProcessFunction を使用した方が良いでしょう。
#### ウィンドウ機能
ウィンドウの内容を処理する方法には、3 つの基本的なオプションがあります。
バッチとして、ウィンドウの内容を含むイテレータブルを渡す ProcessWindowFunction を使用します。
ReduceFunction や AggregateFunction を使用して、各イベントがウィンドウに割り当てられるたびに呼び出されます。
または、この2つの組み合わせで、ReduceFunctionやAggregateFunctionの事前に集約された結果は、ウィンドウがトリガされたときにProcessWindowFunctionに供給されます。
ここでは、アプローチ1と3の例を示します。それぞれの実装では、1 分間のイベントタイムウィンドウ内の各センサからピーク値を検出し、(key, end-of-window-timestamp, max_value)を含むタプルのストリームを生成します。
##### ProcessWindowFunction Example
~~~java
DataStream<SensorReading> input = ...
input
.keyBy(x -> x.key)
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
.process(new MyWastefulMax());
public static class MyWastefulMax extends ProcessWindowFunction<
SensorReading, // input type
Tuple3<String, Long, Integer>, // output type
String, // key type
TimeWindow> { // window type
@Override
public void process(
String key,
Context context,
Iterable<SensorReading> events,
Collector<Tuple3<String, Long, Integer>> out) {
int max = 0;
for (SensorReading event : events) {
max = Math.max(event.value, max);
}
out.collect(Tuple3.of(key, context.window().getEnd(), max));
}
}
~~~
この実装で注意すべき点がいくつかあります。
- ウィンドウに割り当てられたすべてのイベントは、ウィンドウがトリガーされるまで、キー付きのフリンク状態でバッファリングされなければなりません。これは非常にコストがかかる可能性があります。
- ProcessWindowFunction には、ウィンドウに関する情報を含む Context オブジェクトが渡されます。そのインターフェイスは次のようになっています。
~~~java
public abstract class Context implements java.io.Serializable {
public abstract W window();
public abstract long currentProcessingTime();
public abstract long currentWatermark();
public abstract KeyedStateStore windowState();
public abstract KeyedStateStore globalState();
}
~~~
windowState および globalState は、そのキーのすべてのウィンドウについて、キーごと、ウィンドウごと、またはグローバルなキーごとの情報を保存できる場所です。
これは、例えば、現在のウィンドウに関する情報を記録しておき、後続のウィンドウを処理する際にそれを使用したい場合に便利です。
##### Incremental Aggregation Example
~~~java
DataStream<SensorReading> input = ...
input
.keyBy(x -> x.key)
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
.reduce(new MyReducingMax(), new MyWindowFunction());
private static class MyReducingMax implements ReduceFunction<SensorReading> {
public SensorReading reduce(SensorReading r1, SensorReading r2) {
return r1.value() > r2.value() ? r1 : r2;
}
}
private static class MyWindowFunction extends ProcessWindowFunction<
SensorReading, Tuple3<String, Long, SensorReading>, String, TimeWindow> {
@Override
public void process(
String key,
Context context,
Iterable<SensorReading> maxReading,
Collector<Tuple3<String, Long, SensorReading>> out) {
SensorReading max = maxReading.iterator().next();
out.collect(Tuple3.of(key, context.window().getEnd(), max));
}
}
~~~
Iterable<SensorReading>は、MyReducingMaxによって計算された事前に集計された最大値である1つの読み取り値を正確に含むことに注意してください。
#### 後期のイベント
デフォルトでは、イベントタイムウィンドウを使用すると、遅いイベントは削除されます。
ウインドウ API には、これを制御するためのオプションの部分が 2 つあります。
[サイド出力](https://ci.apache.org/projects/flink/flink-docs-release-1.11/learn-flink/event_driven.html#side-outputs)と呼ばれるメカニズムを使用して、ドロップされるイベントを別の出力ストリームに収集するようにアレンジすることができます。以下にその例を示します。
~~~java
OutputTag<Event> lateTag = new OutputTag<Event>("late"){};
SingleOutputStreamOperator<Event> result = stream.
.keyBy(...)
.window(...)
.sideOutputLateData(lateTag)
.process(...);
DataStream<Event> lateStream = result.getSideOutput(lateTag);
~~~
また、許容される遅延時間の間隔を指定して、遅延イベントが適切なウィンドウに割り当てられ続けます(その状態が保持されます)。
デフォルトでは、各遅延イベントはウィンドウ関数を再度呼び出すことになります(レイトファージングと呼ばれることもあります)。
デフォルトでは、許容される遅延は0です。
言い換えれば、ウォーターマークの後ろにある要素は削除されます(またはサイド出力に送られます)。
例えば、以下のようになります。
~~~java
stream.
.keyBy(...)
.window(...)
.allowedLateness(Time.seconds(10))
.process(...);
~~~
許容される遅延がゼロよりも大きい場合、ドロップされるほど遅れているイベントのみがサイド出力に送信されます(設定されている場合)。
#### サプライズ
Flink のウィンドウズ API のいくつかの側面は、あなたが期待するような動作をしないかもしれません。
[flink-user メーリングリスト](https://flink.apache.org/community.html#mailing-list)やその他の場所でよく聞かれる質問に基づいて、あなたを驚かせるようなウィンドウに関する事実をいくつか紹介します。
##### スライドウィンドウでコピーを作成
スライディングウィンドウのアサイン機能は、たくさんのウィンドウオブジェクトを作成することができ、各イベントを関連するすべてのウィンドウにコピーします。
例えば、15分ごとに24時間の長さのスライドウィンドウがある場合、各イベントは4 * 24 = 96個のウィンドウにコピーされます。
##### タイムウィンドウはエポックに合わせて配置される
1時間の処理時間のウィンドウを使用していて、12時5分にアプリケーションを起動したからといって、最初のウィンドウが1時5分に閉じるわけではありません。
最初のウィンドウは55分間の長さで、1:00に終了します。
しかし、タンブリングウィンドウとスライディングウィンドウのアサインでは、ウィンドウの配置を変更するために使用できるオプションのオフセットパラメータが使用されていることに注意してください。
詳細は[タンブリングウィンドウ](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/stream/operators/windows.html#tumbling-windows)と[スライディングウィンドウ](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/stream/operators/windows.html#sliding-windows)を参照してください。
##### ウィンドウはウィンドウをフォローできます
例えば、これを行うために動作します。
~~~java
stream
.keyBy(t -> t.key)
.timeWindow(<time specification>)
.reduce(<reduce function>)
.timeWindowAll(<same time specification>)
.reduce(<same reduce function>)
~~~
Flinkのランタイムは、(ReduceFunctionやAggregateFunctionを使用していれば)この並列事前集計をしてくれると期待するかもしれませんが、そうではありません。
なぜこれが機能するかというと、タイムウィンドウによって生成されたイベントには、ウィンドウの終了時の時刻に基づいてタイムスタンプが割り当てられているからです。
ですから、例えば、1時間のウィンドウによって生成されるすべてのイベントは、1時間の終わりを示すタイムスタンプを持つことになります。
これらのイベントを消費する後続のウィンドウは、前のウィンドウと同じか、その倍数の持続時間を持つべきです。
##### Empty TimeWindowsの検索結果はありませんでした
ウィンドウは、イベントが割り当てられたときにのみ作成されます。そのため、指定された時間枠内にイベントがない場合、結果は報告されません。
##### 遅いイベントは遅いマージを引き起こす可能性があります
セッションウィンドウは、マージ可能なウィンドウの抽象化に基づいています。
各要素は最初に新しいウィンドウに割り当てられ、その後、ウィンドウ間のギャップが十分に小さくなるとウィンドウがマージされます。
このようにして、遅いイベントによって、以前に別々になった2つのセッション間のギャップを埋めることができ、遅いマージを行うことができます。
### ハンズオン
この項目に付随するハンズオンエクササイズが[「時報ヒントエクササイズ」](https://github.com/apache/flink-training/tree/release-1.11/hourly-tips)です。
### 続きを読む
- [Timely Stream Processing](https://ci.apache.org/projects/flink/flink-docs-release-1.11/concepts/timely-stream-processing.html)
- [Windows](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/stream/operators/windows.html)
## イベント駆動型アプリケーション
### プロセス機能
#### 導入
ProcessFunctionは、イベント処理とタイマーやステートを組み合わせたもので、ストリーム処理アプリケーションの強力なビルディングブロックとなっています。
これは、Flinkでイベントドリブンなアプリケーションを作成するための基礎となります。
これは RichFlatMapFunction に非常に似ていますが、タイマーが追加されています。
#### 例
[Streaming Analyticsのトレーニング](https://ci.apache.org/projects/flink/flink-docs-release-1.11/learn-flink/streaming_analytics.html)で[ハンズオン演習](https://ci.apache.org/projects/flink/flink-docs-release-1.11/learn-flink/streaming_analytics.html#hands-on)を行ったことがある方は、次のようにTumblingEventTimeWindowを使用して、各時間帯の各ドライバーのチップの合計を計算していることを覚えていると思います。
~~~java
// compute the sum of the tips per hour for each driver
DataStream<Tuple3<Long, Long, Float>> hourlyTips = fares
.keyBy((TaxiFare fare) -> fare.driverId)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.process(new AddTips());
~~~
同じことをKeyedProcessFunctionで行うのは、合理的に簡単で、教育的です。
上のコードをこれに置き換えることから始めてみましょう。
~~~java
// compute the sum of the tips per hour for each driver
DataStream<Tuple3<Long, Long, Float>> hourlyTips = fares
.keyBy((TaxiFare fare) -> fare.driverId)
.process(new PseudoWindow(Time.hours(1)));
~~~
このコードスニペットでは、PseudoWindow と呼ばれる KeyedProcessFunction がキー付きストリームに適用されており、その結果は DataStream<Tuple3<Long, Long, Float>> (Flink の組み込みタイムウィンドウを使用する実装で生成されたストリームと同じ種類のもの) になります。
PseudoWindowの全体的なアウトラインはこのような形をしています。
~~~java
// Compute the sum of the tips for each driver in hour-long windows.
// The keys are driverIds.
public static class PseudoWindow extends
KeyedProcessFunction<Long, TaxiFare, Tuple3<Long, Long, Float>> {
private final long durationMsec;
public PseudoWindow(Time duration) {
this.durationMsec = duration.toMilliseconds();
}
@Override
// Called once during initialization.
public void open(Configuration conf) {
. . .
}
@Override
// Called as each fare arrives to be processed.
public void processElement(
TaxiFare fare,
Context ctx,
Collector<Tuple3<Long, Long, Float>> out) throws Exception {
. . .
}
@Override
// Called when the current watermark indicates that a window is now complete.
public void onTimer(long timestamp,
OnTimerContext context,
Collector<Tuple3<Long, Long, Float>> out) throws Exception {
. . .
}
}
~~~
注意すべきこと
プロセス関数にはいくつかの種類があり、これはKeyedProcessFunctionですが、CoProcessFunction、BroadcastProcessFunctionなどもあります。
キー付きプロセス関数は、リッチ関数の一種です。RichFunctionとして、管理されたキー付き状態で作業するために必要なopenメソッドとgetRuntimeContextメソッドへのアクセスを持っています。
実装するコールバックは、processElementとonTimerの2つです。processElementは着信イベントごとに呼び出され、onTimerはタイマーが発生したときに呼び出されます。これらは、イベントタイムまたは処理時間タイマーのいずれかになります。processElement と onTimer の両方にはコンテキストオブジェクトが用意されており、これを使用して TimerService とやり取りすることができます (他のものとのやり取りも可能です)。また、両方のコールバックには結果を出力するために使用できる Collector が渡されます。
注意すべきこと
- プロセス関数にはいくつかの種類があり、これはKeyedProcessFunctionですが、CoProcessFunction、BroadcastProcessFunctionなどもあります。
- キー付きプロセス関数は、リッチ関数の一種です。RichFunctionとして、管理されたキー付き状態で作業するために必要なopenメソッドとgetRuntimeContextメソッドへのアクセスを持っています。
- 実装するコールバックは、processElementとonTimerの2つです。processElementは着信イベントごとに呼び出され、onTimerはタイマーが発生したときに呼び出されます。これらは、イベントタイムまたは処理時間タイマーのいずれかになります。processElement と onTimer の両方にはコンテキストオブジェクトが用意されており、これを使用して TimerService とやり取りすることができます (他のものとのやり取りも可能です)。また、両方のコールバックには結果を出力するために使用できる Collector が渡されます。
##### The open() method
~~~java
// Keyed, managed state, with an entry for each window, keyed by the window's end time.
// There is a separate MapState object for each driver.
private transient MapState<Long, Float> sumOfTips;
@Override
public void open(Configuration conf) {
MapStateDescriptor<Long, Float> sumDesc =
new MapStateDescriptor<>("sumOfTips", Long.class, Float.class);
sumOfTips = getRuntimeContext().getMapState(sumDesc);
}
~~~
運賃イベントが順番に到着しないことがあるため、前の1時間の結果の計算が終わるまでに1時間イベントを処理する必要があることがあります。
実際、透かしの遅延がウィンドウの長さよりもはるかに長い場合、2つのウィンドウだけではなく、多くのウィンドウが同時に開かれている可能性があります。
この実装では、各ウィンドウの終了時のタイムスタンプをそのウィンドウのチップの合計にマップする MapState を使用してこれをサポートしています。
##### The processElement() method
~~~java
public void processElement(
TaxiFare fare,
Context ctx,
Collector<Tuple3<Long, Long, Float>> out) throws Exception {
long eventTime = fare.getEventTime();
TimerService timerService = ctx.timerService();
if (eventTime <= timerService.currentWatermark()) {
// This event is late; its window has already been triggered.
} else {
// Round up eventTime to the end of the window containing this event.
long endOfWindow = (eventTime - (eventTime % durationMsec) + durationMsec - 1);
// Schedule a callback for when the window has been completed.
timerService.registerEventTimeTimer(endOfWindow);
// Add this fare's tip to the running total for that window.
Float sum = sumOfTips.get(endOfWindow);
if (sum == null) {
sum = 0.0F;
}
sum += fare.tip;
sumOfTips.put(endOfWindow, sum);
}
}
~~~
考えるべきこと。
遅れているイベントはどうなる?ウォーターマークの後ろにあるイベント(つまり遅いイベント)は落とされています。
これよりも良いことをしたい場合は、[次のセクション](https://ci.apache.org/projects/flink/flink-docs-release-1.11/learn-flink/event_driven.html#side-outputs)で説明するサイド出力の使用を検討してください。
この例では、キーがタイムスタンプである MapState を使用し、同じタイムスタンプに Timer を設定しています。
これは一般的なパターンで、タイマーが作動したときに関連する情報を簡単かつ効率的に検索することができます。
##### The onTimer() method
~~~java
public void onTimer(
long timestamp,
OnTimerContext context,
Collector<Tuple3<Long, Long, Float>> out) throws Exception {
long driverId = context.getCurrentKey();
// Look up the result for the hour that just ended.
Float sumOfTips = this.sumOfTips.get(timestamp);
Tuple3<Long, Long, Float> result = Tuple3.of(driverId, timestamp, sumOfTips);
out.collect(result);
this.sumOfTips.remove(timestamp);
}
~~~
観察事項です。
- onTimerに渡されたOnTimerContextコンテキストは、現在のキーを決定するために使用することができます。
- 私たちの疑似ウィンドウは、現在の透かしが各時間の終わりに達したときにトリガされており、その時点で onTimer が呼び出されます。この onTimer メソッドは sumOfTips から関連するエントリを削除します。これは、Flinkのタイムウィンドウで作業する際に、allowedLatenessをゼロに設定することに相当します。
#### パフォーマンスに関する考察
Flinkは、RocksDB用に最適化されたMapStateとListStateの型を提供しています。
可能であれば、これらは何らかのコレクションを保持するValueStateオブジェクトの代わりに使用されるべきです。
RocksDBのステートバックエンドは、(de)シリアライズを経ることなくListStateに追加することができ、また、MapStateの場合は、キーと値のペアがそれぞれ別のRocksDBオブジェクトとなるため、MapStateに効率的にアクセスして更新することができます。
### サイド出力
#### 導入
Flink オペレータからの出力ストリームを複数持ちたい理由はいくつかあります。
- 例外 exceptions
- 不良事象 malformed events
- 後日談 late events
- 外部サービスへのタイムアウト接続などの運用上の警告
サイド出力はこれを行うのに便利な方法です。エラー報告を超えて、サイド出力はストリームのn方向の分割を実装するのにも良い方法です。
#### 例
前のセクションで無視されていた後期イベントをどうにかしたいと思っています。
サイド出力チャンネルはOutputTag<T>に関連付けられています。
これらのタグは、サイドアウトプットのDataStreamの型に対応する一般的な型を持ち、名前を持っています。
~~~java
private static final OutputTag<TaxiFare> lateFares = new OutputTag<TaxiFare>("lateFares") {};
~~~
上に示したのは、PseudoWindowのprocessElementメソッドでレイトイベントを発行する際に、両方とも参照できる静的なOutputTag<TaxiFare>です。
~~~java
if (eventTime <= timerService.currentWatermark()) {
// This event is late; its window has already been triggered.
ctx.output(lateFares, fare);
} else {
. . .
}
~~~
上記と,ジョブのメインメソッドでこの側の出力からストリームにアクセスするときに
~~~java
// compute the sum of the tips per hour for each driver
SingleOutputStreamOperator hourlyTips = fares
.keyBy((TaxiFare fare) -> fare.driverId)
.process(new PseudoWindow(Time.hours(1)));
hourlyTips.getSideOutput(lateFares).print();
~~~
あるいは、同じ名前の2つのOutputTagsを使って、同じ側の出力を参照することもできますが、その場合は、同じ型を持っている必要があります。
### 閉会の挨拶
この例では、ProcessFunctionを使って簡単なタイムウィンドウを再実装する方法を見てきました。
もちろん、もしFlinkのビルトインウィンドウAPIがあなたのニーズを満たしているのであれば、ぜひ使ってみてください。
しかし、もしあなたがFlinkのウィンドウを使って何か歪んだことをしようと考えていることに気付いたら、あなた自身のウィンドウを作成することを恐れないでください。
また、ProcessFunctionsは、コンピューティング分析以外の多くのユースケースにも役立ちます。
以下のハンズオンエクササイズでは、全く異なるものの例を示しています。
ProcessFunctionsのもう一つの一般的なユースケースは、期限切れの陳腐な状態のためのものです。RichCoFlatMapFunctionを使用して単純な結合を計算している[Rides and Fares Exercise](https://github.com/apache/flink-training/tree/release-1.11/rides-and-fares)に戻って考えてみると、サンプルのソリューションでは、TaxiRidesとTaxiFaresが各rideIdに対して1対1で完全に一致していると仮定しています。
イベントが失われた場合、同じrideIdの他のイベントは永遠に状態で保持されます。
これは、代わりにKeyedCoProcessFunctionとして実装することができ、タイマーを使用してスタール状態を検出してクリアすることができます。
### ハンズオン
この項に付随するハンズオンエクササイズは、[ロングライドアラートエクササイズ](https://github.com/apache/flink-training/tree/release-1.11/long-ride-alerts)です。
### 続きを読む
- [ProcessFunction](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/stream/operators/process_function.html)
- [Side Outputs](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/stream/side_output.html)
## フォールトトレランス
### ステートバックエンド
Flinkによって管理される鍵付きステートは一種のシャード化された鍵/値のストアであり、鍵付きステートの各項目の作業コピーは、その鍵を担当するタスクマネージャのローカルのどこかに保管されます。
オペレータの状態もまた、それを必要とするマシンのローカルにあります。Flink は定期的にすべてのステートの永続的なスナップショットを取得し、これらのスナップショットを分散ファイルシステムなどのより耐久性のある場所にコピーします。
障害が発生した場合、Flink はアプリケーションの完全な状態を復元し、何も問題がなかったかのように処理を再開することができます。
Flinkが管理するこの状態は、ステートバックエンドに保存されます。ステートバックエンドには2つの実装があります。
1つはRocksDBをベースにしたもので、ディスク上に作業状態を保持する組み込みのキー/値ストア、もう1つはJavaヒープ上のメモリ上に作業状態を保持するヒープベースのステートバックエンドです。
このヒープベースのステートバックエンドには、分散ファイルシステムにステートスナップショットを永続化するFsStateBackendと、ジョブマネージャのヒープを使用するMemoryStateBackendの2種類があります。

ヒープベースのステートバックエンドに保持されているステートを扱う場合、アクセスと更新にはヒープ上のオブジェクトを読み書きする必要があります。
しかし、RocksDBStateBackendに保持されているオブジェクトの場合、アクセスと更新にはシリアライズとデシリアライズが必要になるため、コストが高くなります。
しかし、RocksDB で保持できるステートの量は、ローカルディスクのサイズによってのみ制限されます。
また、RocksDBStateBackendだけがインクリメンタルスナップショットを行うことができることにも注意してください。
これらのステートバックエンドはすべて非同期スナップショットを行うことができ、進行中のストリーム処理を妨げることなくスナップショットを取得することができます。
### 状態のスナップショット
#### 定義
- スナップショット - Flinkジョブの状態のグローバルで一貫性のあるイメージの総称。スナップショットには、各データソースへのポインタ(ファイルやKafkaパーティションへのオフセットなど)と、ジョブのステートフル演算子からの状態のコピーが含まれます。
- チェックポイント - 障害から回復するために Flink が自動的に取得するスナップショット。チェックポイントはインクリメンタルで、迅速に復元できるように最適化されています。
Externalized Checkpoint (外部化チェックポイント) - 通常、チェックポイントはユーザーが操作することを意図していません。Flink は、ジョブの実行中は n 番目に新しいチェックポイント(n は設定可能)のみを保持し、ジョブがキャンセルされたときに削除します。しかし、代わりに保持するように設定することもでき、その場合は手動で再開することができます。
Savepoint - ステートフルな再配置/アップグレード/再スケーリング操作などの運用目的で、ユーザー(またはAPIコール)が手動でトリガーしたスナップショット。サベポイントは常に完全なものであり、運用の柔軟性のために最適化されています。
#### ステートスナップショットはどのように機能しますか?
Flinkは、非同期バリアスナップショットとして知られる[Chandy-Lamportアルゴリズム](https://en.wikipedia.org/wiki/Chandy-Lamport_algorithm)の変形を使用します。
タスクマネージャがチェックポイントコーディネータ(ジョブマネージャの一部)からチェックポイントを開始するように指示されると、すべてのソースにオフセットを記録させ、番号付きのチェックポイントバリアをストリームに挿入します。
これらのバリアはジョブグラフを流れ、各チェックポイントの前後のストリームの部分を示します。

チェックポイント n は、チェックポイント障壁 n の前のすべてのイベントを消費した結果、チェックポイント障壁 n の後のイベントを消費しなかった結果、各オペレータの状態を記録します。
ジョブグラフ内の各オペレータがこれらのバリアの1つを受け取ると、その状態が記録される。
2 つの入力ストリーム(CoProcessFunction のような)を持つオペレータは、両方の入力ストリームからのイベントを消費した結果の状態を両方のバリアまで(過去ではなく)反映するように、スナップショットがバリアの整列を実行します。

Flink のステートバックエンドはコピーオンライトメカニズムを使用しており、古いバージョンのステートが非同期的にスナップショットされている間、ストリーム処理が妨げられることなく継続されるようになっています。
スナップショットが永続的に持続した場合にのみ、これらの古いバージョンのステートがガベージコレクションされます。
#### 一度だけの保証 Exactly Once Gurarantees
ストリーム処理アプリケーションで問題が発生すると、結果が失われたり、重複したりする可能性があります。
Flinkでは、アプリケーションの選択と実行するクラスタによって、これらの結果のいずれかが発生する可能性があります。
- フリンクは失敗から回復する努力をしない(最大でも1回 at most once)
- 何も失われていませんが、重複した結果を経験するかもしれません(少なくとも一度は at least once)
- 何も失われたり、複製されたりしない(一度だけexactly once)
Flinkがソースデータストリームを巻き戻したり再生したりすることで障害から回復することを考えると、理想的な状況を「一度だけ」と表現した場合、これはすべてのイベントが一度だけ正確に処理されるという意味ではありません。
むしろ、すべてのイベントがFlinkによって管理されている状態に正確に一度だけ影響を与えることを意味しています。
バリアライメントは、正確に一度だけの保証を提供するためにのみ必要です。
これを必要としない場合は、FlinkにCheckpointingMode.AT_LEAST_ONCEを使用するように設定することで、バリアアライメントを無効にする効果があり、ある程度のパフォーマンスを得ることができます。
#### 一度だけのエンド・ツー・エンド Exactly Once End-to-end
ソースからのすべてのイベントがシンクに正確に一度だけ影響を与えるように、エンドツーエンドで正確に一度だけを実現するには、次のことを実行しなければなりません。
- ソースはリプレイ可能でなければなりません
- あなたのシンクはトランザクション型でなければなりません
-
### ハンズオン
[Flink Operations Playground](https://ci.apache.org/projects/flink/flink-docs-release-1.11/try-flink/flink-operations-playground.html)には、[失敗と回復の観察](https://ci.apache.org/projects/flink/flink-docs-release-1.11/try-flink/flink-operations-playground.html#observing-failure--recovery)に関するセクションがあります。
### 続きを読む
- [Stateful Stream Processing](https://ci.apache.org/projects/flink/flink-docs-release-1.11/concepts/stateful-stream-processing.html)
- [State Backends](https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/state/state_backends.html)
- [Fault Tolerance Guarantees of Data Sources and Sinks](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/connectors/guarantees.html)
- [Enabling and Configuring Checkpointing](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/stream/state/checkpointing.html)
- [Checkpoints](https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/state/checkpoints.html)
- [Savepoints](https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/state/savepoints.html)
- [Tuning Checkpoints and Large State](https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/state/large_state_tuning.html)
- [Monitoring Checkpointing](https://ci.apache.org/projects/flink/flink-docs-release-1.11/monitoring/checkpoint_monitoring.html)
- [Task Failure Recovery](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/task_failure_recovery.html)
# コンセプト
[ハンズオントレーニング](https://ci.apache.org/projects/flink/flink-docs-release-1.11/learn-flink/)では、FlinkのAPIの根底にあるステートフルおよびタイムリーなストリーム処理の基本的な概念を説明し、これらのメカニズムがアプリケーションでどのように使用されているかを例示しています。ステートフルなストリーム処理は、[データパイプラインとETL](https://ci.apache.org/projects/flink/flink-docs-release-1.11/learn-flink/etl.html#stateful-transformations)のコンテキストで紹介され、[フォールトトレランス](https://ci.apache.org/projects/flink/flink-docs-release-1.11/learn-flink/fault_tolerance.html)のセクションでさらに発展します。タイムリーなストリーム処理は、[「ストリーミング分析」](https://ci.apache.org/projects/flink/flink-docs-release-1.11/learn-flink/streaming_analytics.html)のセクションで紹介されています。
このConcepts in Depthのセクションでは、Flinkのアーキテクチャとランタイムがこれらの概念をどのように実装しているかをより深く理解することができます。
## 概要
### Flink's APIs
Flinkは、ストリーミング/バッチアプリケーションを開発するためのさまざまなレベルの抽象化を提供します。

- 最下層の抽象化は、単にステートフルでタイムリーなストリーム処理を提供します。これは、[Process Function](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/stream/operators/process_function.html)を介して[DataStream API](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/datastream_api.html)に組み込まれています。これにより、ユーザーは1つ以上のストリームからのイベントを自由に処理することができ、一貫性のあるフォールトトレラントな状態を提供します。さらに、ユーザーはイベント時間と処理時間のコールバックを登録することができ、プログラムは高度な計算を実現することができます。
- 実際には、多くのアプリケーションでは上記のような低レベルの抽象化を必要とせず、代わりにコアAPIである[DataStream API](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/datastream_api.html) (束縛/非束縛ストリーム)と[DataSet API](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/batch/) (束縛データセット)を使用してプログラムすることができます。これらの流暢なAPIは、ユーザーが指定した様々な形式の変換、結合、集約、ウィンドウ、ステートなどのデータ処理のための共通のビルディングブロックを提供します。これらのAPIで処理されるデータ型は、それぞれのプログラミング言語でクラスとして表現されます。低レベルのProcess FunctionはDataStream APIと統合されており、必要に応じて低レベルの抽象化を使用することができます。データセットAPIは、ループや反復のような、制限されたデータセットに関する追加のプリミティブを提供します。
- [Table API](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/table/)は、テーブルを中心とした宣言的DSLであり、動的に変化するテーブル(ストリームを表現する場合)である可能性があります。Table API は (拡張された) リレーショナルモデルに従います。テーブルにはスキーマがアタッチされており (リレーショナルデータベースのテーブルに似ています)、API は select, project, join, group-by, aggregate などの同等の操作を提供します。テーブルAPIプログラムは、操作のためのコードがどのように見えるかを正確に指定するのではなく、どのような論理操作を行うべきかを宣言的に定義します。Table APIは様々なタイプのユーザー定義関数で拡張可能ですが、Core APIに比べて表現力が低く、より簡潔に使用することができます(書くコードが少ない)。さらに、Table API プログラムは、実行前に最適化ルールを適用するオプティマイザを通過します。テーブルとDataStream/DataSetの間でシームレスに変換することができ、プログラムはテーブルAPIとDataStreamとDataSetのAPIを混在させることができます。
- Flinkが提供する最高レベルの抽象化は[SQL](https://ci.apache.org/projects/flink/flink-docs-release-1.11//ci.apache.org/projects/flink/flink-docs-release-1.11/dev/table/#sql)です。この抽象化は、セマンティクスと表現力の両面でTable APIに似ていますが、プログラムをSQLクエリ式として表現します。SQLの抽象化はTable APIと密接に相互作用し、SQLクエリはTable APIで定義されたテーブル上で実行することができます。
## ステートフルなストリーム処理
### ステートとは?
データフローの多くの操作は、単に一度に1つの個別のイベントを見るだけですが(イベント・パーサなど)、一部の操作は複数のイベントにまたがって情報を記憶しています(ウィンドウ・オペレータなど)。これらの操作はステートフルと呼ばれます。
ステートフル操作の例をいくつか挙げます。
- アプリケーションが特定のイベントパターンを検索すると、状態はこれまでに遭遇したイベントのシーケンスを格納します。
- 分/時間/日ごとにイベントを集約する場合、状態は保留中の集約を保持します。
- データポイントの流れの上で機械学習モデルを学習するとき、状態はモデルパラメータの現在のバージョンを保持します。
- 歴史的なデータを管理する必要がある場合、状態は、過去に発生したイベントへの効率的なアクセスを可能にします。
Flinkは、[チェックポイント](https://ci.apache.org/projects/flink/flink-docs-release-1.11//ci.apache.org/projects/flink/flink-docs-release-1.11/dev/stream/state/checkpointing.html)と[セーブポイント](https://ci.apache.org/projects/flink/flink-docs-release-1.11//ci.apache.org/projects/flink/flink-docs-release-1.11/ops/state/savepoints.html)を使用してフォールトトレラントにするために、状態を認識しておく必要があります。
また、ステートに関する知識は、Flinkアプリケーションの再スケーリングを可能にし、並列インスタンス間でステートの再分配をFlinkが行うことを意味します。
[クエリー可能な状態](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/stream/state/queryable_state.html)は、実行時にFlinkの外部から状態にアクセスすることを可能にします。
ステートを扱う際には、[Flink のステートバックエンド](https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/state/state_backends.html)についても読んでおくと便利かもしれません。Flink は、ステートがどこにどのように保存されるかを指定するさまざまなステートバックエンドを提供しています。
### キー付きステート
鍵の状態は、埋め込まれた鍵/値のストアと考えられるもので維持されます。
ステートは、ステートフルな演算子によって読み込まれるストリームと一緒に、厳密に分割されて分散される。
したがって、キー/値の状態へのアクセスは、キー付きストリーム、すなわち、キー付き/分割されたデータ交換の後にのみ可能であり、現在のイベントのキーに関連付けられた値に制限される。
ストリームとステートのキーを整列させることで、すべてのステート更新がローカル操作であることを確認し、トランザクションのオーバーヘッドなしに一貫性を保証します。
また、このアラインメントにより、Flinkはステートを再分配し、ストリームのパーティショニングを透過的に調整することができます。

鍵付き状態はさらに、いわゆる鍵グループに整理されます。
鍵グループは、Flinkが鍵付き状態を再分配するための原子単位であり、定義された最大並列度と同じ数の鍵グループが存在します。
実行中、鍵付き演算子の各並列インスタンスは、1つまたは複数の鍵グループの鍵を使用して動作します。
### 状態の持続性
Flink は、ストリーム再生とチェックポイントを組み合わせてフォールトトレランスを実装します。
チェックポイントは、入力ストリームのそれぞれの特定のポイントを、演算子のそれぞれに対応する状態とともにマークします。
ストリーミングデータフローは、演算子の状態を復元し、チェックポイントのポイントからレコードを再生することで、一貫性(正確に一度だけの処理セマンティクス)を維持しながら、チェックポイントから再開することができます。
チェックポイント間隔は、実行中のフォールトトレランスのオーバーヘッドを回復時間(再生する必要があるレコードの数)とトレードオフするための手段です。
フォールトトレランス機構は、分散ストリーミングデータフローのスナップショットを連続的に描画します。
状態が小さいストリーミングアプリケーションの場合、これらのスナップショットは非常に軽量であり、パフォーマンスにあまり影響を与えることなく頻繁に描画することができます。
ストリーミングアプリケーションの状態は、設定可能な場所、通常は分散ファイルシステムに保存されます。
プログラムに障害が発生した場合(マシン、ネットワーク、またはソフトウェアの障害による)、Flinkは分散ストリーミング・データフローを停止します。その後、システムは演算子を再起動し、最新の成功したチェックポイントにリセットします。
入力ストリームは、状態スナップショットのポイントにリセットされます。
再起動された並列データフローの一部として処理されるレコードは、以前にチェックポイントされた状態に影響を与えていないことが保証されます。
`注意 デフォルトでは、チェックポイント機能は無効になっています。チェックポイントを有効にして構成する方法の詳細は、[「チェックポイント」](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/stream/state/checkpointing.html)を参照してください。`
`注意 このメカニズムが完全に保証されるためには、データストリームのソース (メッセージキューやブローカなど) が、ストリームを定義された最近のポイントに巻き戻すことができる必要があります。[Apache Kafka](http://kafka.apache.org/) にはこの機能があり、Flink の Kafka へのコネクタはこれを利用しています。Flink のコネクタが提供する保証の詳細については、[「データソースとシンクの耐障害性保証」](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/connectors/guarantees.html)を参照してください。`
`注意 Flink のチェックポイントは分散されたスナップショットによって実現されるため、スナップショットとチェックポイントという言葉を入れ替えて使用します。また、スナップショットという用語は、チェックポイントまたはセーブポイントのいずれかを意味する場合に使用されることがよくあります.`
#### チェックポイント
Flinkのフォールト・トレランス・メカニズムの中心的な部分は、分散データ・ストリームとオペレータの状態の一貫したスナップショットを描くことです。
これらのスナップショットは、障害が発生した場合にシステムがフォールバックできる一貫したチェックポイントとして機能します。これらのスナップショットを描画するFlinkのメカニズムは、["Lightweight Asynchronous Snapshots for Distributed Dataflows "](http://arxiv.org/abs/1506.08603)で説明されています。これは、分散スナップショットの標準的な[Chandy-Lamportアルゴリズム](http://research.microsoft.com/en-us/um/people/lamport/pubs/chandy.pdf)に触発されており、Flinkの実行モデルに合わせて特別に調整されています。
チェックポイントに関連するすべてのことが非同期的に行われることを覚えておいてください。
チェックポイント障壁はロックステップで移動することはなく、操作は非同期にその状態をスナップショットすることができます。
Flink 1.11以降、チェックポイントはアラインメントの有無に関わらず取ることができます。
このセクションでは、まずアラインメントされたチェックポイントについて説明します。
##### Barriers(障壁
Flinkの分散スナップショットの核となる要素は、ストリームバリアです。
これらのバリアはデータストリームに注入され、データストリームの一部としてレコードと一緒に流れます。
バリアがレコードを追い越すことはなく、厳密に一直線に流れます。
バリアは、データストリーム内のレコードを、現在のスナップショットに入るレコードのセットと、次のスナップショットに入るレコードのセットに分離します。
各バリアは、その前にレコードを押し込んだスナップショットのIDを持っています。
バリアはストリームの流れを中断しないため、非常に軽量です。
異なるスナップショットからの複数のバリアを同時にストリームに入れることができ、様々なスナップショットが同時に発生する可能性があることを意味します。

ストリームバリアは、ストリームソースで並列データフローに注入されます。スナップショット n のバリアが注入される点 (これを Sn と呼びましょう) は、スナップショットがデータをカバーするまでのソースストリーム内の位置です。
例えば、Apache Kafka では、この位置はパーティション内の最後のレコードのオフセットになります。
この位置 Sn はチェックポイントコーディネータ (Flink のジョブマネージャ) に報告されます。
その後、バリアは下流に流れます。
中間演算子がその入力ストリームのすべてからスナップショットnのバリアを受信すると、その中間演算子はスナップショットnのバリアをその発信ストリームのすべてに放出します。
シンク演算子(ストリーミングDAGの終端)が、その入力ストリームのすべてからバリアnを受信すると、そのスナップショットnをチェックポイントコーディネータに確認する。
すべてのシンクがスナップショットを確認した後、それは完了したとみなされます。
スナップショットnが完了すると、ジョブは、Sn以前のレコードをソースに再び尋ねることはありません。

複数の入力ストリームを受信するオペレータは、スナップショットバリア上で入力ストリームを整列させる必要があります。
上の図はこれを示しています。
- オペレータは、着信ストリームからスナップショットバリアnを受信するとすぐに、他の入力からもバリアnを受信するまで、そのストリームからそれ以上のレコードを処理することはできません。そうでなければ、スナップショットnに属するレコードとスナップショットn+1に属するレコードとが混在することになる。
- 最後のストリームがバリアnを受信すると、オペレータは保留中のすべての発信レコードを放出し、スナップショットnのバリア自体を放出します。
- 状態をスナップショットし、すべての入力ストリームからレコードの処理を再開し、ストリームからのレコードを処理する前に入力バッファからのレコードを処理します。
- 最後に、演算子は非同期的にステートバックエンドにステートを書き込みます。
アライメントは、複数の入力を持つすべての演算子と、複数のアップストリームサブタスクの出力ストリームを消費するシャッフル後の演算子に必要であることに注意してください。
##### スナップショット演算子の状態
演算子が何らかの形の状態を含む場合、この状態もスナップショットの一部でなければなりません。
オペレータは、入力ストリームからすべてのスナップショットバリアを受け取った時点で、バリアを出力ストリームに放出する前の時点で状態をスナップショットする。
その時点では、バリアが適用される前のレコードからの状態へのすべての更新が行われ、バリアが適用された後のレコードに依存する更新は行われない。スナップショットの状態は大きいかもしれないので、設定可能な[状態バックエンド](https://ci.apache.org/projects/flink/flink-docs-release-1.11//ci.apache.org/projects/flink/flink-docs-release-1.11/ops/state/state_backends.html)に保存されます。
デフォルトでは、これはジョブマネージャのメモリですが、本番用には分散型の信頼性の高いストレージ(HDFSなど)を設定する必要があります。
状態が保存された後、オペレータはチェックポイントを確認し、出力ストリームにスナップショットバリアを放出し、処理を進めます。
結果として得られるスナップショットには、現在、次のようなものが含まれています。
- 各パラレルストリームデータソースについて、スナップショットが開始されたときのストリーム内のオフセット/位置
- 各演算子について、スナップショットの一部として保存された状態へのポインタ

##### 復旧
このメカニズムによるリカバリは簡単です。障害が発生すると、Flink は最新のチェックポイント k を選択します。
その後、システムは分散データフロー全体を再配置し、各オペレータにチェックポイント k の一部としてスナップショットされた状態を与えます。
例えば、Apache Kafka の場合、これはコンシューマにオフセット Sk からフェッチを開始するように指示することを意味します。
状態がインクリメンタルにスナップショットされていた場合、オペレータは最新の完全なスナップショットの状態から開始し、その状態に一連のインクリメンタルなスナップショット更新を適用します。
詳細については、[「再起動戦略」](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/task_failure_recovery.html#restart-strategies)を参照してください。
#### アンアラインドチェックポイント
Flink 1.11からは、チェックポイントもアラインメントなしで実行できるようになりました。基本的な考え方は、飛行中のデータがオペレータの状態の一部になる限り、チェックポイントはすべての飛行中のデータを追い越すことができるということです。
このアプローチは実際には[Chandy-Lamportアルゴリズム](http://research.microsoft.com/en-us/um/people/lamport/pubs/chandy.pdf)に近いですが、Flinkではチェックポイント・コーディネーターのオーバーロードを避けるためにソースにバリアを挿入します。

図は、演算子が非整列チェックポイントバリアをどのように処理するかを示しています。
- オペレータは、その入力バッファに格納されている第1のバリアに反応する。
- 出力バッファの末尾に追加することで、バリアを直ちに下流のオペレータに転送します。
- 演算子は、すべての追い越したレコードを非同期的に保存するためにマークし、それ自身の状態のスナップショットを作成します。
その結果、オペレータは入力の処理を一時的に停止してバッファにマークを付け、バリアを転送し、他の状態のスナップショットを作成するだけです。
アラインメントされていないチェックポインティングにより、バリアが可能な限り速くシンクに到着することが保証されます。
アラインメント時間が数時間に達する可能性がある低速なデータパスが少なくとも1つあるアプリケーションに特に適しています。
しかし、I/O圧力が追加されるため、ステートバックエンドへのI/Oがボトルネックになっている場合には役に立ちません。
その他の制限事項については、[OPS](https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/state/checkpoints.html#unaligned-checkpoints)の詳細な議論を参照してください。
セーブポイントは常にアラインメントされることに注意してください。
##### アンアラインドリカバリー
オペレータは、非整列チェックポイントで上流のオペレータからの任意のデータの処理を開始する前に、まず飛行中のデータを回復する。それはさておき、[整列チェックポイントの回復中](https://ci.apache.org/projects/flink/flink-docs-release-1.11/concepts/stateful-stream-processing.html#recovery)と同じステップを実行する。
#### ステートバックエンド
キー/値インデックスが格納される正確なデータ構造は、選択した[ステートバックエンド](https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/state/state_backends.html)によって異なります。
あるステートバックエンドはインメモリのハッシュマップにデータを格納し、別のステートバックエンドはキー/値の格納場所として[RocksDB](http://rocksdb.org/)を使用します。
ステートバックエンドは、ステートを保持するデータ構造を定義するだけでなく、キー/値の状態のスナップショットをポイントインタイムで取得し、そのスナップショットをチェックポイントの一部として保存するロジックも実装しています。
ステートバックエンドは、アプリケーションロジックを変更することなく設定することができます。

#### 保存ポイント
チェックポイントを使用するすべてのプログラムは、セーブポイントから実行を再開することができます。
セーブポイントを使用すると、状態を失うことなく、プログラムとFlinkクラスタの両方を更新することができます。
[セーブポイント](https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/state/savepoints.html)は、手動でトリガーされたチェックポイントで、プログラムのスナップショットを取得してステートバックエンドに書き出します。これは通常のチェックポイント機構に依存しています。
Savepoints はチェックポイントに似ていますが、ユーザーによってトリガされ、新しいチェックポイントが完了しても自動的に期限切れにならない点が異なります。
#### 正確に一度ではなく,少なくとも一度は(Exactly Once vs. At Least Once)
アライメント・ステップは、ストリーミング・プログラムにレイテンシを追加することがあります。
通常、この余分なレイテンシは数ミリ秒のオーダーですが、いくつかのアウトライアのレイテンシが顕著に増加するケースを見てきました。
すべてのレコードに対して一貫して超低レイテンシ(数ミリ秒)を必要とするアプリケーションのために、Flinkにはチェックポイント中にストリームのアラインメントをスキップするスイッチがあります。
チェックポイントのスナップショットは、オペレータが各入力からチェックポイントバリアを見るとすぐに描画されます。
アライメントがスキップされると、オペレータは、チェックポイントnのチェックポイントバリアがいくつか到着した後でも、すべての入力を処理し続ける。
そうすると、オペレータは、チェックポイントnの状態スナップショットが取られる前にチェックポイントn+1に属する要素も処理します。
リストア時には、これらのレコードは重複として発生しますが、これは両方ともチェックポイント n の状態スナップショットに含まれており、チェックポイント n の後にデータの一部として再生されるからです。
`注意 アライメントは、複数の前任者(結合)を持つ演算子と、複数の送信者を持つ演算子(ストリームの再分割/シャッフルの後)に対してのみ発生します。このため、恥ずかしいほど並列なストリーミング操作(map(), flatMap(), filter(), ...)しかできないデータフローでは、少なくとも一度のモードであっても、実際には正確な一度の保証が得られます。`
#### バッチプログラムの状態とフォールトトレランス
Flinkはストリーミングプログラムの特殊なケースとして[バッチプログラム](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/batch/index.html)を実行します。データセットは内部的にはデータのストリームとして扱われます。このように、上記の概念はバッチプログラムにもストリーミングプログラムと同様に適用されますが、わずかな例外を除いては、バッチプログラムにも適用されます。
- [バッチプログラムのフォールトトレランス](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/batch/fault_tolerance.html)はチェックポイントを使用しません。リカバリはストリームを完全に再生することで起こります。これは、入力が制限されているために可能です。これはコストをリカバリーに押し上げますが、チェックポイントを回避するため、通常の処理をより安くすることができます。
- DataSet API のステートフル操作では、キー/値インデックスではなく、簡略化されたインメモリ/アウトオブコアのデータ構造を使用します。
- DataSet APIでは、特殊な同期化された(スーパーステップベースの)反復処理が導入されており、これは制限されたストリームでのみ可能です。詳細については、[反復処理のドキュメント](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/batch/iterations.html)を参照してください。
## タイムリーなストリーム処理
### 導入
タイムリー・ストリーム処理は、[ステートフル・ストリーム処理](https://ci.apache.org/projects/flink/flink-docs-release-1.11/concepts/stateful-stream-processing.html)の拡張であり、計算において時間が何らかの役割を果たします。
特に、時系列分析を行う場合や、特定の期間(一般的にはウィンドウと呼ばれる)に基づいて集計を行う場合、イベントが発生した時間が重要なイベント処理を行う場合などがこれに該当します。
以下のセクションでは、タイムリーなFlinkアプリケーションを使用する際に考慮すべきトピックをいくつか紹介します。
### 時間の概念:イベント時間と処理時間
ストリーミング・プログラムで時間を参照するとき(例えばウィンドウを定義するときなど)、時間の異なる概念を参照することができます。
- __処理時間__ 処理時間とは、それぞれの演算を実行しているマシンのシステム時間を指す。ストリーミングプログラムが処理時間で実行される場合、すべての時間ベースの操作(タイムウィンドウのようなもの)は、それぞれの演算子を実行しているマシンのシステムクロックを使用する。時間単位の処理時間ウィンドウは、システムクロックが満一時間を示した時間の間に特定の演算子に到着したすべてのレコードを含むことになる。例えば、アプリケーションが午前9時15分に実行を開始する場合、最初の1時間ごとの処理時間ウィンドウには、午前9時15分から午前10時までの間に処理されたイベントが含まれ、次のウィンドウには、午前10時から午前11時までの間に処理されたイベントが含まれる。処理時間は最も単純な時間の概念であり、ストリームとマシン間の調整を必要としません。最高]のパフォーマンスと最低のレイテンシを提供します。しかし、分散型で非同期な環境では、処理時間はシステムにレコードが到着する速度(例えばメッセージキューから)、システム内のオペレータ間でレコードが流れる速度、および(予定されているかどうかに関わらず)停止の影響を受けやすいため、決定性を提供しません。
- __イベントタイム__ イベントタイムとは、個々のイベントがその生成デバイスで発生した時間のことです。この時間は通常、Flinkに入る前のレコード内に埋め込まれており、そのイベントタイムスタンプは各レコードから抽出することができます。イベントタイムでは、時間の進行はデータに依存し、いかなる壁時計にも依存しません。イベントタイムプログラムは、イベントタイムの進行を信号化するメカニズムであるイベントタイム透かしを生成する方法を指定しなければならない。この透かしのメカニズムについては、[後述のセクション](https://ci.apache.org/projects/flink/flink-docs-release-1.11/concepts/timely-stream-processing.html#event-time-and-watermarks)で説明します。完璧な世界では、イベントタイム処理は、イベントがいつ到着したか、またはその順序に関係なく、完全に一貫した決定論的な結果をもたらします。しかし、イベントが順番通りに(タイムスタンプによって)到着することが知られていない限り、イベント時間処理は、順番外のイベントを待つ間、いくつかの待ち時間を発生させます。有限の時間の間だけ待つことが可能なので、これは決定論的なイベント時間アプリケーションがどのようにできるかに限界があります。すべてのデータが到着したと仮定すると、イベントタイム操作は期待通りに動作し、順番外のイベントや遅刻したイベントを処理している場合や、履歴データを再処理している場合でも、正確で一貫性のある結果を生成します。例えば、1時間ごとのイベント・タイム・ウィンドウには、到着した順番や処理された時間に関係なく、その時間に該当するイベント・タイムスタンプを持つすべてのレコードが含まれます。(詳細については、レイト・イベントのセクションを参照してください)。イベントタイムプログラムがリアルタイムでライブデータを処理している場合、タイムリーに進行していることを保証するために処理時間操作を使用することがあることに注意してください。

### イベント時間とウォーターマーク
注: FlinkはDataflowモデルの多くのテクニックを実装しています。イベントタイムとウォーターマークについては、以下の記事を参照してください。
- [Streaming 101](https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101) by Tyler Akidau
- [The Dataflow Model paper](https://research.google.com/pubs/archive/43864.pdf)
イベントタイムをサポートするストリームプロセッサには、イベントタイムの進行状況を測定する方法が必要です。
例えば、1時間ごとのウィンドウを構築するウィンドウオペレータは、イベント時間が1時間の終わりを超えたときに通知され、オペレータが進行中のウィンドウを閉じることができるようにする必要がある。
イベント時間は、処理時間(壁時計によって測定される)とは独立して進行することができる。例えば、あるプログラムでは、オペレータの現在のイベント時間は、両方が同じ速度で進行している間に、処理時間(イベントを受信する際の遅延を考慮して)のわずかに遅れてもよい。
一方、別のストリーミングプログラムでは、Kafkaトピック(または別のメッセージキュー)にすでにバッファリングされている履歴データを早送りすることで、数週間分のイベント時間をわずか数秒の処理で進行させることができるかもしれません。
イベント時間の進行状況を測定するためのFlinkのメカニズムは、ウォーターマークです。ウォーターマーク(t)は、イベント時刻がそのストリームの時刻tに達したことを宣言します。
つまり、タイムスタンプt' <= tを持つストリームからは、これ以上の要素は存在しないはずです。
下の図は、(論理的な)タイムスタンプを持つイベントのストリームと、インラインで流れるウォーターマークを示しています。
この例では、イベントは(タイムスタンプに関して)順番に並んでおり、ウォーターマークは単にストリーム内の周期的なマーカーであることを意味します。

ウォーターマークは、以下に示すように、イベントがタイムスタンプによって順序付けられていない順序外のストリームでは非常に重要です。
一般的に、ウォーターマークは、ストリームのその時点までに、特定のタイムスタンプまでのすべてのイベントが到着しているという宣言です。
ウォーターマークが演算子に到達すると、演算子は内部イベントのタイムクロックを透かしの値まで進めることができます。

イベント時間は、新しく作成されたストリーム要素(または要素)が、それらを生成したイベント、またはそれらの要素の作成のきっかけとなったウォーターマークのいずれかから継承されることに注意してください。
#### 並列ストリームのウォーターマーク
ウォーターマークはソース関数で、またはソース関数の直後に生成されます。
ソース関数の各並列サブタスクは通常、独立してウォーターマークを生成します。
これらのウォーターマークは、特定の並列ソースでのイベント時間を定義します。
ウォーターマークがストリーミング・プログラムを流れると、それらが到着した演算子のイベント時間が進みます。演算子がそのイベント時間を進めるたびに、それはその後継演算子のために下流に新しいウォーターマークを生成します。
演算子の中には、複数の入力ストリームを消費するものがあります。
例えば、ユニオンや、keyBy(....)関数や partition(....)関数の後に続く演算子などです。
そのような演算子の現在のイベント時間は、入力ストリームのイベント時間の最小値です。
入力ストリームがイベント時間を更新すると、演算子もイベント時間を更新します。
下の図は、並列ストリームを流れるイベントとウォーターマークの例を示しており、オペレータがイベント時間を追跡しています。

### 遅延
特定の要素がウォーターマーク条件に違反する可能性があり、つまり、ウォーターマーク(t)が発生した後でも、タイムスタンプt' <= tを持つより多くの要素が発生することを意味します。
実際、多くの実世界のセットアップでは、特定の要素は任意に遅延させることができ、特定のイベント・タイムスタンプのすべての要素が発生した時間を指定することは不可能です。
さらに、遅延を制限することができたとしても、ウォーターマークを過度に遅延させることは、イベントタイムウィンドウの評価に過度の遅延をもたらすため、望ましくないことが多い。
このため、ストリーミングプログラムは、明示的にいくつかの遅延要素を期待してもよい。
遅延要素とは、システムのイベントタイムクロック(ウォーターマークによってシグナルされる)が、遅延要素のタイムスタンプの時間をすでに過ぎた後に到着する要素のことです。
イベントタイムウィンドウで後期要素を扱う方法の詳細については、[許容される遅延](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/stream/operators/windows.html#allowed-lateness)を参照してください。
### ウィンドウイング
イベントの集約(カウント、合計など)は、ストリーム上ではバッチ処理とは異なる動作をします。
たとえば、ストリームは一般的に無限大(束縛されていない)なので、ストリーム内のすべての要素をカウントすることは不可能です。
その代わり、ストリーム上の集約(カウント、合計など)は、「過去5分間のカウント」や「過去100要素の合計」のように、ウィンドウによってスコープされます。
ウインドウは、時間駆動型(例:30秒ごと)またはデータ駆動型(例:100要素ごと)のどちらでも構いません。
一般的には、タンブリングウィンドウ(重なりのないウィンドウ)、スライドウィンドウ(重なりのあるウィンドウ)、セッションウィンドウ(活動していない間隙があるウィンドウ)など、異なるタイプのウィンドウを区別することができます。

[ウィンドウの追加例](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/stream/operators/windows.html)については、この[ブログ記事](https://flink.apache.org/news/2015/12/04/Introducing-windows.html)をチェックアウトしてください。
## Flinkのアーキテクチャ
Flinkは分散システムであり、ストリーミングアプリケーションを実行するためには、コンピュートリソースの効果的な割り当てと管理が必要です。[Hadoop YARN](https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/YARN.html)、[Apache Mesos](https://mesos.apache.org/)、[Kubernetes](https://kubernetes.io/)などのすべての一般的なクラスタリソースマネージャと統合されていますが、スタンドアロンクラスタとして、あるいはライブラリとして実行するように設定することもできます。
このセクションでは、Flinkのアーキテクチャの概要を説明し、その主要コンポーネントがアプリケーションの実行と障害からの回復のためにどのように相互作用するかを説明します。
### フリンククラスタの解剖学
Flink ランタイムは、ジョブマネージャと 1 つ以上のタスクマネージャの 2 つのタイプのプロセスで構成されます。

クライアントはランタイムやプログラム実行の一部ではありませんが、データフローを準備してジョブマネージャに送信するために使用されます。
その後、クライアントは切断(detached mode)、または接続したままで進捗レポートを受信することができます(attached mode)。
クライアントは、実行のトリガーとなる Java/Scala プログラムの一部として、またはコマンドラインプロセスの ./bin/flink run ..... のいずれかで実行されます。
ジョブマネージャとタスクマネージャは様々な方法で起動することができます: [スタンドアロンクラスタ](https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/deployment/cluster_setup.html)としてマシン上で直接、コンテナ内で、または [YARN](https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/deployment/yarn_setup.html) や [Mesos](https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/deployment/mesos.html) のようなリソースフレームワークで管理されます。
タスクマネージャはジョブマネージャに接続し、利用可能な状態であることを発表し、仕事を割り当てられます。
#### ジョブマネージャ
ジョブマネージャは、次のタスク(または一連のタスク)をいつスケジュールするかの決定、終了したタスクや実行失敗への対応、チェックポイントの調整、失敗時のリカバリーの調整など、Flink アプリケーションの分散実行の調整に関連した多くの責任を持っています。
このプロセスは3つの異なるコンポーネントで構成されています。
- ___ResourceManager:___ ResourceManagerは、Flinkクラスタ内のリソースのデ/アロケーションとプロビジョニングを担当し、Flinkクラスタ内のリソーススケジューリングの単位であるタスクスロットを管理します([タスクマネージャを参照](https://ci.apache.org/projects/flink/flink-docs-release-1.11/concepts/flink-architecture.html#taskmanagers))。Flinkは、YARN、Mesos、Kubernetes、スタンドアロンデプロイメントなど、さまざまな環境やリソースプロバイダに対応した複数のResourceManagerを実装しています。スタンドアロンのセットアップでは、ResourceManagerは利用可能なTaskManagersのスロットを分配することしかできず、自分で新しいTaskManagersを起動することはできません。
- ___Dispatcher:___ Dispatcherは、実行のためにFlinkアプリケーションを投入するためのRESTインターフェースを提供し、投入されたジョブごとに新しいJobMasterを起動します。また、ジョブの実行に関する情報を提供するためにFlink WebUIを実行します。
- ___JobMaster:___ ジョブマスターは1つの[ジョブグラフ](https://ci.apache.org/projects/flink/flink-docs-release-1.11/concepts/glossary.html#logical-graph)の実行を管理します。Flinkクラスタ内で複数のジョブを同時に実行することができ、それぞれが独自のジョブマスターを持っています。
少なくとも 1 つのジョブマネージャが常に存在します。高可用性の設定では、複数のジョブマネージャが存在し、そのうちの一人が常にリーダーで、他の一人がスタンバイしている場合があります ([高可用性 (HA)](https://ci.apache.org/projects/flink/flink-docs-release-1.11/concepts/flink-architecture.html#tasks-and-operator-chains) を参照してください)。
#### タスクマネージャ
タスクマネージャ(ワーカーとも呼ばれる)は、データフローのタスクを実行し、データストリームをバッファリングして交換します。
タスクマネージャは常に1つ以上存在しなければなりません。
タスクマネージャのリソーススケジューリングの最小単位はタスクスロットです。
TaskManager内のタスクスロットの数は、同時処理タスクの数を示します。
1つのタスクスロットで複数のオペレータが実行される可能性があることに注意してください([「タスクとオペレータチェーン」](https://ci.apache.org/projects/flink/flink-docs-release-1.11/concepts/flink-architecture.html#tasks-and-operator-chains)を参照)。
### タスクとオペレータチェーン
分散実行のために、Flinkは演算子のサブタスクをタスクにチェーン化します。各タスクは 1 つのスレッドで実行されます。演算子をタスクにチェーン化することは有用な最適化であり、スレッド間のハンドオーバやバッファリングのオーバーヘッドを削減し、全体的なスループットを向上させながらレイテンシを減少させます。
チェイニング動作は設定できます。
詳細は[チェイニングのドキュメント](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/stream/operators/#task-chaining-and-resource-groups)を参照してください。
下図のサンプルデータフローは、5 つのサブタスクで実行され、5 つの並列スレッドで実行されています。

### タスクスロットとリソース
各ワーカー(TaskManager)はJVMプロセスであり、別々のスレッドで1つ以上のサブタスクを実行することができます。TaskManagerが受け入れるタスクの数を制御するために、いわゆるタスクスロット(少なくとも1つ)を持っています。
各タスクスロットは、タスクマネージャのリソースの固定サブセットを表します。
例えば、3つのスロットを持つタスクマネージャは、管理メモリの1/3を各スロットに割り当てます。
リソースをスロット化するということは、サブタスクが他のジョブのサブタスクと管理メモリを争うことはなく、その代わりに一定量の管理メモリが予約されていることを意味します。
現在のところスロットはタスクの管理メモリを分離するだけなので、CPUの分離は行われません。
タスクスロットの数を調整することで、ユーザーはサブタスクをどのように分離するかを定義することができます。
TaskManagerごとに1つのスロットを持つことは、各タスクグループが別のJVMで実行されることを意味します(別のコンテナなどで起動することができます)。
複数のスロットを持つことは、より多くのサブタスクが同じJVMを共有することを意味します。
同じJVM内のタスクは、TCP接続(多重化を介して)とハートビートメッセージを共有します。
また、データセットとデータ構造を共有することができるため、タスクごとのオーバーヘッドを減らすことができます。

デフォルトでは、Flinkはサブタスクが異なるタスクのサブタスクであっても、同じジョブのサブタスクであればスロットを共有することができます。
その結果、1つのスロットがそのジョブのパイプライン全体を保持することになります。
このスロット共有を許可すると、主に2つの利点があります。
- Flinkクラスタは、ジョブで使用される最高の並列度と同じ数のタスクスロットを必要とします。プログラムに含まれる(並列度が異なる)タスクの総数を計算する必要はありません。
- リソースの利用率を上げるのは簡単です。スロットを共有しないと、非集約的な source/map() サブタスクは、リソース集約的なウィンドウサブタスクと同じくらい多くのリソースをブロックしてしまいます。スロットを共有すると、この例ではベースの並列度を 2 から 6 に増やすことで、スロットのあるリソースをフルに利用することができます。

### Flinkアプリケーションの実行
Flinkアプリケーションとは、main()メソッドから1つまたは複数のFlinkジョブを生成するユーザープログラムです。
これらのジョブの実行は、ローカルの JVM (LocalEnvironment) または複数のマシンからなるクラスタのリモートセットアップ (RemoteEnvironment) で行うことができます。
各プログラムに対して、ExecutionEnvironmentはジョブの実行を制御したり(並列性の設定など)、外部の世界と対話したりするためのメソッドを提供します([Flinkプログラムの構造を参照](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/datastream_api.html#anatomy-of-a-flink-program))。
Flinkアプリケーションのジョブは、長時間稼働する[Flinkセッションクラスタ](https://ci.apache.org/projects/flink/flink-docs-release-1.11/concepts/glossary.html#flink-session-cluster)、専用の[Flinkジョブクラスタ](https://ci.apache.org/projects/flink/flink-docs-release-1.11/concepts/glossary.html#flink-job-cluster)、または[Flinkアプリケーションクラスタ](https://ci.apache.org/projects/flink/flink-docs-release-1.11/concepts/glossary.html#flink-application-cluster)に投入することができます。
これらのオプションの違いは、主にクラスタのライフサイクルとリソースの分離保証に関連しています。
#### Flinkセッションクラスタ
- ___クラスタのライフサイクル:___ Flink セッションクラスタでは、クライアントは複数のジョブの投入を受け付けることができる既存の長時間稼働するクラスタに接続します。すべてのジョブが終了した後も、セッションが手動で停止されるまでクラスタ(およびジョブマネージャ)は稼働し続けます。したがって、Flink セッションクラスタの寿命は、どの Flink ジョブの寿命にも縛られません。
- ___リソースの分離:___ TaskManager スロットはジョブ投入時に ResourceManager によって割り当てられ、ジョブが終了すると解放されます。すべてのジョブが同じクラスタを共有しているため、ジョブ投入フェーズではネットワーク帯域幅などのクラスタリソースの競合が発生します。この共有設定の制限事項として、1つのTaskManagerがクラッシュすると、そのTaskManager上で実行中のタスクを持つすべてのジョブが失敗するということがあります。
- ___その他の考慮点:___ 既存のクラスタを利用することで、リソースの申請やタスクマネージャの起動にかかる時間を大幅に節約できます。これは、ジョブの実行時間が非常に短く、起動時間が長いとエンドツーエンドのユーザーエクスペリエンスに悪影響を及ぼす場合に重要です。例えば、短いクエリの対話型分析の場合のように、ジョブが既存のリソースを使用して素早く計算を実行できることが望ましいです。
`注: 以前は、Flink セッションクラスタはセッションモードの Flink クラスタとしても知られていました。`
#### Flinkジョブクラスタ
- ___クラスタライフサイクル:___ Flinkジョブクラスタでは、利用可能なクラスタマネージャ(YARNやKubernetesのようなもの)を使用して各ジョブのためにクラスタをスピンアップし、このクラスタはそのジョブにのみ利用可能です。ここでは、クライアントは最初にクラスタマネージャにリソースを要求してJobManagerを起動し、このプロセス内で実行されているDispatcherにジョブを投入します。タスクマネージャはその後、ジョブのリソース要件に基づいて怠惰に割り当てられます。ジョブが終了すると、Flink ジョブクラスタは解体されます。
- ___リソースの分離:___ JobManager での致命的なエラーは、その Flink ジョブクラスタで実行されている 1 つのジョブにのみ影響します。
- ___その他の考慮事項:___ ResourceManager は、TaskManager プロセスを起動してリソースを割り当てるために、外部のリソース管理コンポーネントを適用して待機する必要があるため、Flink ジョブクラスタは、長時間稼働し、高い安定性が要求され、起動時間が長くなることに敏感ではない大規模なジョブに適しています。
`注:以前は、Flinkジョブクラスタは、ジョブ(またはジョブごと)モードのFlinkクラスタとしても知られていました。`
#### Flinkアプリケーションクラスタ
- ___クラスタのライフサイクル:___ Flinkアプリケーションクラスタは、1つのFlinkアプリケーションからのジョブのみを実行する専用のFlinkクラスタで、main()メソッドはクライアントではなくクラスタ上で実行されます。代わりに、アプリケーションロジックと依存関係を実行可能なジョブJARにパッケージ化し、クラスタエントリポイント(AppplicationClusterEntryPoint)がmain()メソッドを呼び出してジョブグラフを抽出します。これにより、例えばKubernetes上の他のアプリケーションと同様にFlinkアプリケーションをデプロイすることができます。したがって、Flinkアプリケーションクラスタの寿命は、Flinkアプリケーションの寿命に拘束されます。
- ___リソースの分離:___ Flinkアプリケーションクラスターでは、ResourceManagerとDispatcherが単一のFlinkアプリケーションにスコープされ、Flinkセッションクラスターよりも優れた分離を実現します。
`注: Flinkジョブクラスターは、Flinkアプリケーションクラスターの「run-on-クライアント」の代替として見ることができます。`
## 用語集
### Flink アプリケーションクラスタ
(Flink Application Cluster)
Flink Application Clusterは、1つのFlink ApplicationからのFlinkジョブのみを実行する専用のFlink Clusterです。Flink クラスタの寿命は、Flink アプリケーションの寿命に拘束されます。
### Flinkジョブクラスタ
(Flink Job Cluster)
Flinkジョブクラスタは、単一のFlinkジョブのみを実行する専用のFlinkクラスタです。Flink クラスタの寿命は、Flink ジョブの寿命に拘束されます。
### Flink クラスタ
(Flink Cluster)
通常は1つのJobManagerと1つ以上のFlink TaskManagerプロセスで構成される分散システム。
### イベント
(Event)
イベントとは、アプリケーションによってモデル化されたドメインの状態の変化に関する記述です。イベントは、ストリームまたはバッチ処理アプリケーションの入力および/または出力とすることができます。イベントは特殊なタイプのレコードです.
### 実行グラフ
(ExecutionGraph)
物理グラフを参照してください。
### 機能
(Function)
関数はユーザーによって実装され、Flink プログラムのアプリケーション ロジックをカプセル化します。ほとんどの関数は、対応する演算子でラップされています。
### インスタンス
(Instance)
インスタンスという用語は、実行時に特定の型 (通常は Operator や Function) の特定のインスタンスを記述するために使われます。Apache Flink はほとんどが Java で書かれているので、これは Java での Instance や Object の定義に対応します。Apache Flink の文脈では、同じ演算子や関数型の複数のインスタンスが並列に実行されていることを 強調するために、並列インスタンスという用語も頻繁に使われます。
### Flink アプリケーション
(Flink Application)
Flinkアプリケーションとは、1つまたは複数のFlinkジョブをmain()メソッドから(または他の何らかの方法で)投入するJavaアプリケーションのことです。ジョブの投入は通常、実行環境上でexecute()を呼び出すことで行われます。
アプリケーションのジョブは、長期間稼働している Flink セッションクラスタ、専用の Flink アプリケーションクラスタ、または Flink ジョブクラスタのいずれかに投入することができます。
### Flinkジョブ
(Flink Job)
Flinkジョブは、論理グラフ(データフローグラフとも呼ばれる)のランタイム表現であり、Flinkアプリケーション内でexecute()を呼び出すことで作成され、送信されます。
### ジョブグラフ
(JobGraph)
論理グラフを参照してください。
### フリンクジョブマネージャ
(Flink JobManager)
JobManager は Flink クラスタのオーケストレータです。3つの異なるコンポーネントから構成されています。Flink Resource Manager、Flink Dispatcher、そして実行中のFlinkジョブごとに1つのFlink JobMasterです。
### Flink ジョブマスター
(Flink JobMaster)
ジョブマスターはジョブマネージャで動作するコンポーネントの一つです。ジョブマスターは単一のジョブのタスクの実行を監督する責任があります。
### 論理グラフ
(Logical Graph)
論理グラフは有向グラフで、ノードは演算子、エッジは演算子の入出力関係を定義し、データストリームやデータセットに対応します。論理グラフは、Flink アプリケーションからジョブを送信することで作成されます。
論理グラフは、データフローグラフとも呼ばれます。
### 管理状態
(Managed State)
Managed State はフレームワークに登録されているアプリケーションの状態を記述します。マネージドステートでは、Apache Flink がパーシステンスやリスケーリングなどの処理を行います。
### 演算子
(Operator)
論理グラフのノード。演算子は特定の操作を行い、通常は関数によって実行されます。ソースとシンクは、データの取り込みと取り出しのための特殊な演算子です。
### 演算子の連鎖
(Operator Chain)
オペレータチェーンは、2つ以上の連続したオペレータで構成され、その間の再分割は一切行われません。同じOperator Chain内のOperatorは、シリアル化やFlinkのネットワークスタックを経由せずに、直接お互いにレコードを転送します。
### パーティショニング
(Partition)
パーティションは、データストリームまたはデータセット全体の独立したサブセットです。データストリームまたはデータセットは、各レコードを1つ以上のパーティションに割り当てることで、パーティションに分割されます。データストリームまたはデータセットのパーティションは、実行時にタスクによって消費されます。データストリームやデータセットの分割方法を変更する変換は、しばしば再分割と呼ばれます。
### 物理グラフ
(Physical Graph)
物理グラフは、分散ランタイムで実行するために論理グラフを変換した結果です。ノードはタスクであり、エッジはデータストリームやデータセットの入出力関係やパーティションを示します。
### レコード
(Record)
レコードは、データセットまたはデータストリームの構成要素です。オペレータと関数は、入力としてレコードを受け取り、出力としてレコードを出力します。
### Flink セッションクラスタ
(Flink Session Cluster)
複数の Flink ジョブの実行を受け入れる長期実行型の Flink クラスタです。このFlink Clusterの寿命は、どのFlinkジョブの寿命にも縛られません。以前は、セッション モードの Flink セッション クラスターとしても知られていました。Flink Application Clusterと比較してください。
### ステートバックエンド
(State Backend)
ストリーム処理プログラムの場合、Flinkジョブのステートバックエンドは、そのステートが各TaskManager(TaskManagerのJavaヒープまたは(埋め込み)RocksDB)にどのように格納されるかを決定し、チェックポイント(JobManagerのJavaヒープまたはFilesystem)にどこに書き込まれるかを決定します。
### サブタスク
(Sub-Task)
サブタスクとは、データストリームのパーティションの処理を担当するタスクのことです。サブタスク」という用語は、同じオペレータまたはオペレータチェーンに対して複数の並列タスクがあることを強調しています。
### タスク
(Task)
物理グラフのノード。タスクは基本的な作業単位で、Flinkのランタイムによって実行されます。タスクは、オペレータまたはオペレータチェーンの1つの並列インスタンスをカプセル化します。
### Flinkタスクマネージャ
(Flink TaskManager)
タスクマネージャは Flink クラスタのワーカープロセスです。タスクはタスクマネージャにスケジューリングされて実行されます。これらのプロセスは、後続のタスク間でデータを交換するために相互に通信します。
### 変換
(Transformation)
変換は、1つまたは複数のデータストリームまたはデータセットに適用され、その結果、1つまたは複数の出力データストリームまたはデータセットが得られる。変換は、データストリームやデータセットをレコード単位で変更することもありますが、パーティショニングを変更したり、集約を実行したりするだけの場合もあります。オペレータと関数がFlinkのAPIの「物理的」な部分であるのに対し、変換はAPIの概念に過ぎません。具体的には、ほとんどの変換は特定の演算子によって実装されています。