前回の①に続けて、少し実践的な訓練データ・テストデータの分け方をしていきます。
まずデータを用意します。
今度は変数 x が2つあります。

このように機械学習では、変数 x が2つ以上あるとき
それらを1つにまとめて大文字 $\mathbf{X}$ として扱っていきます。
次に、訓練データとテストデータに分けます。
訓練データ
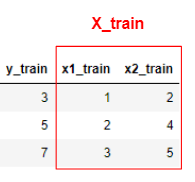
テストデータ
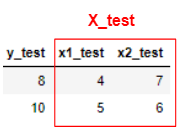
そして訓練データからモデル式を作成していきます。
これを最小二乗法というもので計算すると、下記のように求まります。
$$y=0.9+2x_1+2.0\times10^{-16}x_2$$
そしてこれをテストデータに当てはめていきます。
$$y_{pred}=0.9+2x_{1_{test}}+2.0\times10^{-16}x_{2_{test}}=9,11$$ $$y_{test}=8,10$$
上記のことから、正解データの y_test に対して
自分が予測した y_pred は、おおよそ合っていることが分かりました。
$y$ に対して $x$ が2つ以上ある場合には
基本的に、訓練データとテストデータを上記のように考えていきます。
実際の機械学習では、今回のようなデータに対して
y を家賃、x1, x2 はそれを構成する要素(駅徒歩・築年数など)として
データの分析を進めています。
また、前回の記事①と今回の記事②は
どちらとも線形回帰という手法を行っておりますので
近いうちに、また投稿させていただければと思います。