今回は教師あり学習における
訓練データとテストデータについて説明します。
■ 訓練データとテストデータ
訓練データ:モデル式(データの関連性を表す式)を作るデータ
テストデータ:作成した式がどのくらい正確性のあるものかを確認するデータ
自分がデータの関連性を式で表せたとしても、それを試すデータがなかったら困りますよね。
では、簡単な具体例を挙げて説明していきます。
例えば、下記のようなデータがあるとします。
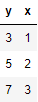
ここで、この表のデータを下記のように分割します。
訓練データ

テストデータ

このとき、まずデータの関連性を見つけたいので
訓練データから y と x の式(モデル式)の候補を考えます。
候補1:$y=3x$
候補2:$y=2x+1$
訓練データを用いてモデル式を作成しました。
ただこれだけでは、本当にこの式が成り立つのかは分かりません。
そのために、検証用としてテストデータがあるのです。
作成したモデル式に対して、下記のデータでも成り立つか確認をします。
確かめる方法は、モデル式にテストデータの x を代入して、本当に y となるかどうかです。
候補1:$y=3x=3\times3=9$
候補2:$y=2x+1=2\times3+1=7$
正解:$y=7$
このことから、今回用意したデータに関しては
候補1ではなく候補2の方が正確性が高いことが分かりました。
このように、機械学習では訓練データからデータの関連性を見つけ出し(モデル式の作成)
テストデータにて実際に正確であるかどうかをチェックする仕組みを取っています。
■ X_train, y_train を当てはめる
では、X_train, y_train, X_test, y_test とはいったい何なのでしょうか?
train:訓練データ(トレーニングの略)
test:テストデータ(モデル式を検証するデータ)
今回用意したデータに当てはめるとこのようになります。
訓練データ

テストデータ

先ほどと同じように、訓練データからモデル式を考えます。
候補1:$y=3x$
候補2:$y=2x+1$
これでモデル式が完成しました。
あとは、これらがどのくらいの正確性を示すのかを、テストデータを用いて検証します。
先ほどは、モデル式にテストデータの x を代入して、予測値 y を出し
実際の y と一致するかといったように検証をしました。
このときの予測値を y_pred と表記します。(predict:予測する)
テストデータ
候補1:$y_{pred}=3x_{test}=3\times3=9$
候補2:$y_{pred}=2x_{test}+1=2\times3+1=7$
正解:$y_{test}=7$
よって、今回作成したモデル式では
候補2の方が正確性が高いということが分かりました。
つまり、まとめると下記になります。
X_train, y_train:モデル式(データの関連性の式)を作るためのデータ
X_test:モデル式に代入をして、自分の回答 y_pred を出すためのデータ
y_test:本当の正解データ(数学の模範解答と同じ)、自分で出した y_pred と答え合わせするためのもの
y_test のみが模範解答として扱われるのは、少し分かりづらいですよね。
教師あり学習(テストデータあり)では、基本的にこの考え方をもとに
様々なモデル式の作成・検証を行っています。