1. はじめに
立命館大学大学院 情報理工学研究科の岡本悠希です。2021/8/23~9/10の3週間,㈱ 日立製作所・研究開発グループの夏季インターンシップに参加しました。今回のインターンシップでは,環境音と呼ばれる音声や楽音に限らないあらゆる音を対象とした研究に取り組みました。その中でも特に,複数の混ざり合った環境音の中から,特定のある1音のみを抽出する“環境音抽出”という技術に取り組みましたので,実施した研究内容について紹介します。
*本インターンシップでの研究成果はICASSP2022に採択されました。[link]
2. 研究背景
映画やゲームなどのメディアコンテンツ作品において,環境音は,作品への没入感や臨場感を高めるために利用されます。環境音を得る方法としては,大量の環境音が収録されたデータベースから音を探す方法が考えられます。音を探す作業を簡略化するため,データベースから環境音を検索するシステムなども多く研究されています [1]。例えば,「風の音」のような音の種類名を基に環境音を検索するシステムや,「ビュービュー」のような音の特徴を模倣した擬音語と呼ばれる文字列を与えて検索するシステムなどがあります。しかしながら,目的とする環境音がデータベースに存在するとは限りません。一方,インターネット上には音の種類(以下,音響イベント)などのラベルが付与されていない環境音データが大量に存在します。これらの環境音データから目的の環境音のみを分離・抽出できれば,メディアコンテンツ作品への利用など,様々な用途での活用が期待できます。
3. インターンシップで取り組んだ内容
3.1 従来手法と課題
深層学習の技術を用いて特定の環境音のみを抽出する手法はこれまでいくつか提案されています。従来手法の1つに,「車の音」のような音響イベントを指定して,複数の音が混ざり合った音(以下,混合音)の中から指定した音響イベントに該当する環境音を抽出する方法 [2,3]があります。環境音には,音の長さ,音高,音色のように音響イベントの種類だけでは表現できない特性が存在します。例えば,「笛の音」という音響イベントの音には様々な音高があるため,従来手法では特定の音高の音だけを抽出することはできません。解決策として,「甲高い笛の音」,「低い笛の音」のように音響イベントのクラスを分ける方法も考えられますが,クラス分けに膨大な時間を必要とします。
3.2 提案手法
今回のインターンシップでは,従来手法で使用していた音響イベントの代わりに,擬音語を使用した環境音の抽出手法を提案しました。擬音語は,音の長さ,高さ,音色などの特徴を表現するのに有効であるとされています。そのため,擬音語を用いることで,抽出したい特定の音のみを指定することができます。提案手法の概要は以下の通りです。
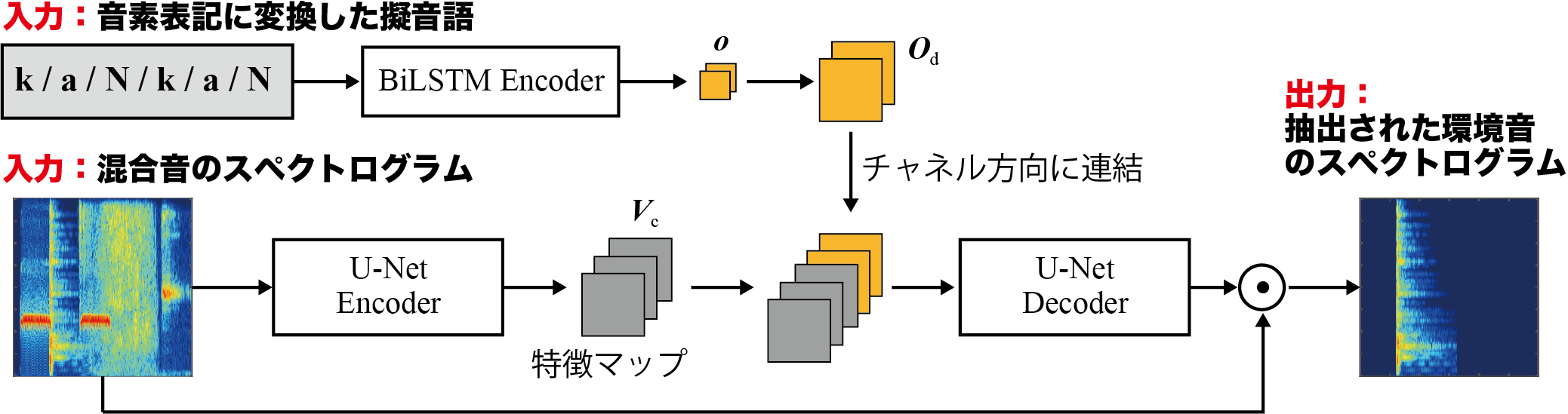
提案手法は,U-Net [4]と呼ばれる深層学習モデルをベースとした手法になっています。全体の処理フローは,以下の5ステップになります。
- STEP1: 擬音語と混合音をそれぞれEncoderに入力し,特徴マップを獲得
- STEP2: 特徴マップをチャネル方向に連結し,Decoderに入力
- STEP3: Decoderにより,擬音語で指定した環境音のみを残すような時間周波数ソフトマスクを推定
- STEP4: 時間周波数ソフトマスクと混合音の要素積を求め,環境音のスペクトログラムを抽出
- STEP5: スペクトログラムを時間波形に変換して,擬音語で指定した環境音のみを得る
3.3 評価実験
3.3.1 実験条件
- 評価実験に使用したデータセット
- 環境音データ:RWCP 実環境音声・音響データベース [5]
- 44種類の音響イベント,約3,600音の環境音を使用
- 擬音語データ:RWCP-SSD-Onomatopoeia [6]
- 1個の環境音あたり3個の擬音語を使用
- 環境音データ:RWCP 実環境音声・音響データベース [5]
上記のデータセットを用いて混合音を合計10,930音作成し,概ね7:2:1の割合になるように分割し,それぞれ学習用,検証用,評価用データとしました。
-
評価指標
環境音の抽出性能を評価するため,混合音と抽出音の総合的な歪み度合いの差であるSignal-to-Distortion Ratio Improvement (SDRi) を採用しました。 -
提案手法の比較対象とした従来手法
提案手法の擬音語を入力する部分に,音響イベントを入力とする手法を従来手法として比較評価を行いました。
3.3.2 実験結果
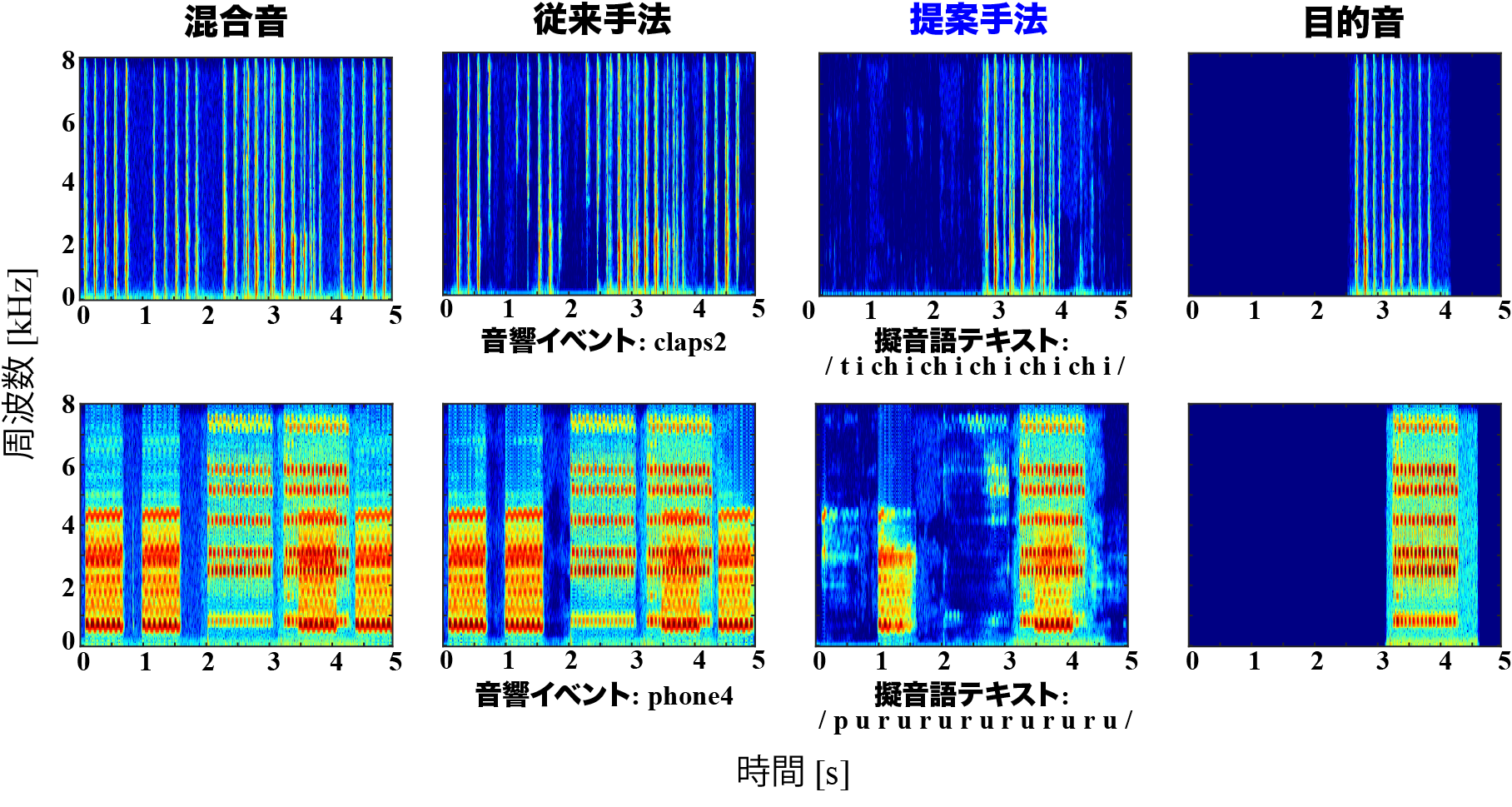
従来手法はSDRiが2.84 dBであったのに対し,提案手法は5.11 dBと2.27dB高くなりました。実際に抽出された音のスペクトログラムを比較してみると,従来法では目的音以外の音も抽出されているのに対し,提案手法は擬音語で指定した目的音のみを抽出できています(図の上段3列目)。一方,目的音と干渉音が重なる区間においては,一部抽出できていない箇所が存在するため,今後さらなる性能向上の余地があると考えています(図の下段3列目)。
3.4 考察
-
環境音抽出に擬音語を使用する手法の有効性
実験結果より,環境音抽出において擬音語を使用することで,従来手法では抽出できなかった特定の1音のみを抽出可能であるということを示しました。よって,特定の1音のみを抽出する手法として,擬音語を用いることは有効であるということが確認できました。 -
目的音の抽出性能について
提案法は,SDRiの標準偏差が大きくなるという傾向が確認されました。目的音とそれ以外の干渉音が重なり合う区間においては,干渉音も抽出されてしまい,それが原因で抽出性能に差が生まれ,標準偏差の値が大きくなったと考えられます。
4. おわりに
- 本記事では,夏季インターンシップにて取り組んだ擬音語を用いた環境音抽出の研究について紹介しました。今回のインターンシップでは,メンターの方を始め多くの社員の方々から助言頂きながら研究を進めことができ,非常に勉強になりました。今回の経験を今後の研究活動に活かしていきたいと思います。
参考文献
[1] S. Ikawa and K. Kashino, “Acoustic event search with an onomatopoeic query: measuring distance between onomatopeic words and sounds,” Proc. Detection and Classification of Acoustic Scenes and Events (DCASE), pp. 59-63, 2018.
[2] Y. Sudo, K. Itoyama, K. Nishida, and K. Nakadai, "Environmental sound segmentation utilizing Mask U-Net," Proc. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 5340-5345, 2019.
[3] T. Ochiai, M. Delcroix, Y. Koizumi, H. Ito, K. Kinoshita, and S. Araki, “Listen to what you want: Neural networl-based universal sound selector,” Proc. INTERSPEECH, pp. 1441-1445, 2020.
[4] O. Ronneberger, P. Fischeer, and T. Brox, “U-Net: Convolutional networks for biomedical image segmentation,” Proc. International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), pp. 234-241, 2015.
[5] S. Nakamura, K. Hiyane, F. Asano, and T. Endo, “Sound scene data collection in real acoustical environments,” The Journal of the Acoustic Society of Japan (E), vol. 20, no. 3, pp. 225-231, 1999.
[6] Y. Okamoto, K. Imoto, S. Takamichi, R. Yamanishi, T. Fukumori, and Y. Yamashita, “RWCP-SSD-Onomatopoeia: Onomatopoeic words dataset for environmental sound synthesis,” Proc. Workshop on Detection and Classification of Acoustic Scenes and Events (DCASE), pp. 125-129, 2020.