教師あり学習って何だろう
先の記事で機械学習について、なんとなくどういったものなのかをまとめました。機械学習は大きく分けて、教師あり学習、教師なし学習、強化学習に分類できます。今回はその中でも、教師あり学習に焦点を当て、もっと詳細にまとめます。
こちらの記事も読んでみてください。
この記事の立ち位置
たくさんのデータを、学習したデータをもとに予測・分析を行う機械学習には、その学習方法や目的、データの特徴、によって教師あり学習、教師なし学習、強化学習の3種類に分類されます。
学習用データにラベルがついている、つまり、答えがあるものが、教師あり学習、ラベルがついていないものが教師なし学習です。そして、事前にデータをそろえるのではなく、結果を設定し、システムを実行していく中で、学習していくのが強化学習です。この中でこの記事では、教師付き学習について深堀していきます。手順や、目的、評価方法、モデルなどについて触れていきます。
目的とメリットデメリット
教師あり学習は、明確な正解・不正解がある問題に対して最も有効です。例としては、画像に写っているものを人間が判断し、ラベルを付けていきます。車が写っているものには「車」、バイクが写っているものには「バイク」と、ラベルを付けたデータを大量に学習させ、この学習させたモデルに、新しくラベルの付いていない画像に写っているものが「車」か「バイク」かを判別させます。
このように、正解となる結果を高い精度で導くことが、教師あり学習の目的になります。
メリット
教師あり学習のメリットは、学習精度が高く、学習速度の速いことがあげられます。
これは、答えが用意されているため、これを参考にして、同じ答えを持つデータ同士の特徴、異なるラベルを持つデータと何が異なるのか、というパターンを学習することができるからです。
もちろん、機械学習全般に言えることですが、高精度で簡単な予測を行うことができます。
デメリット
デメリットとしては、この教師データと呼ばれる答えを、用意するための時間とコストがかかるということ、そして、間違ったラベルを付けたり、ラベルが足りていなかったりすると、予測精度の低下を招くため、慎重にデータ作成を行う必要があります。もとからあるデータを使用する、もしくは収集の際に自動でラベルを付ける、などの工夫をすればこのコストは抑えられるかもしれません。ただ、より多くの学習用データを用意するためには、複数のソースからデータを使用することもあります。その際には、データの形式をそろえたり、不要なデータの削除、不足しているデータの追加を行う必要があり、時間も人件費などのコストもかかります。
学習手法
教師あり学習の学習手法、学習モデルとも言いますが、ここではその種類と、具体的なモデルについて、説明します。
使用する場面によって、使用するモデルも異なるため、モデルによってどのような特徴があるのかを把握する必要があります。
教師あり学習は、その目的によって回帰と分類の2種類に分類されます。ここではそれぞれについて、主要なモデルとともに紹介していきます。
ただ、ここでモデルのを詳細に紹介することはしません。詳しく説明すると、より専門的になり、長くなってしまうので、機会があれば別でまとめます。
回帰
回帰とは、連続する数値の傾向をもとに予測を行うことを言います。気温の予測や売り上げの予測や、販売価格の予測などがこれに当てはまります。つまり、すでにわかっている過去の数値から、未来の数値を予測することを回帰といいます。
回帰では、この数値を表すモデルを形成し、そのモデルに沿うと、将来このくらいの値をとりそうだという予測を行います。
モデルの形状はさまざまで、直線のものから曲線であったり様々です。
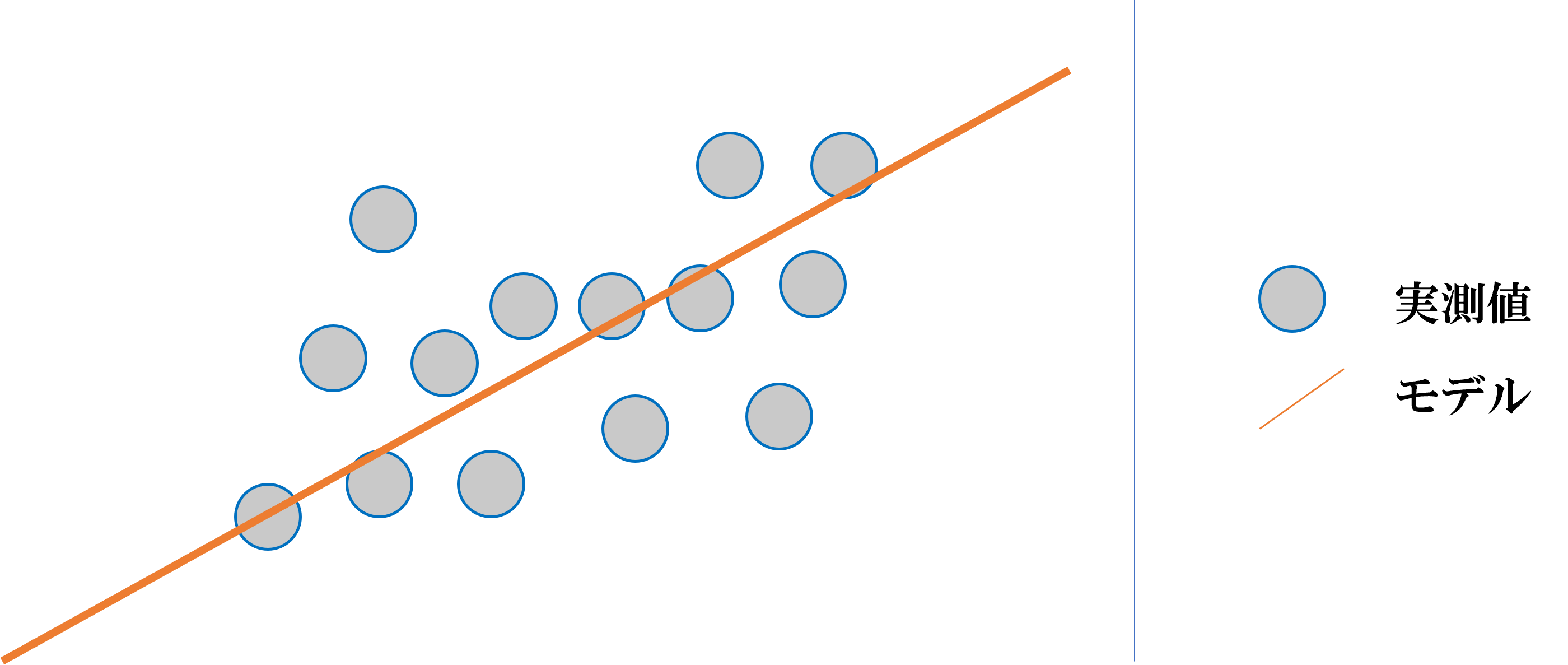
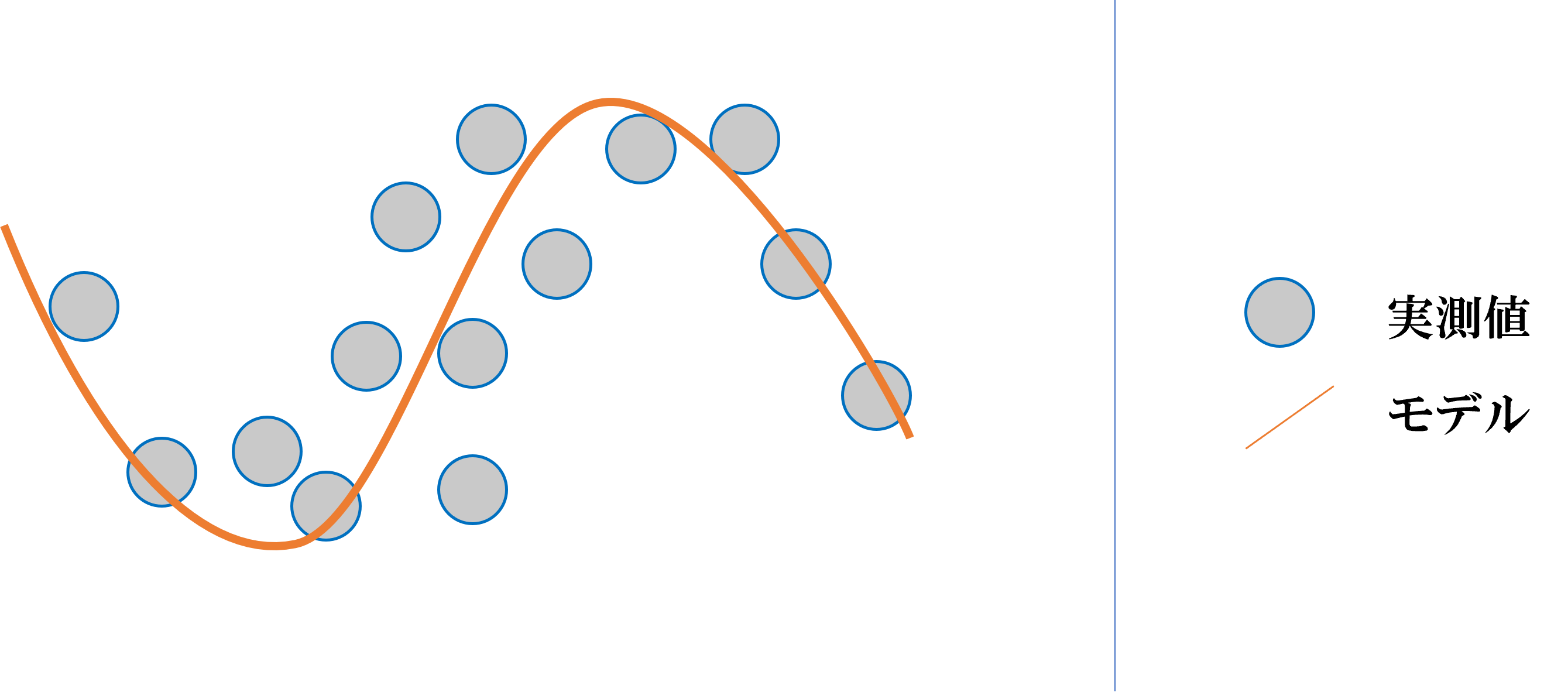
直線1つであらわされる回帰モデルを、線形回帰といいそれ以外を非線形回帰といいます。
線形回帰
非線形回帰
分類
分類とは、あるデータがどのクラスに属するかを予測するものを指します。画像の分類を例にすると、乗り物の画像のデータを「車」「バイク」「自転車」などを分類することができます。
学習には車の画像には「車」というラベルをつけ、バイクの画像には「バイク」というラベルを付けるなど、画像と画像に写っているもののラベルをデータとしてあたえ、新しくラベルの付いていないデータに対して、写っているものが何かを判別できるようになります。
この分類では、学習によってクラス間の境界線を決定します。
分類にも回帰と同様に、線形と非線形に分けることができます。
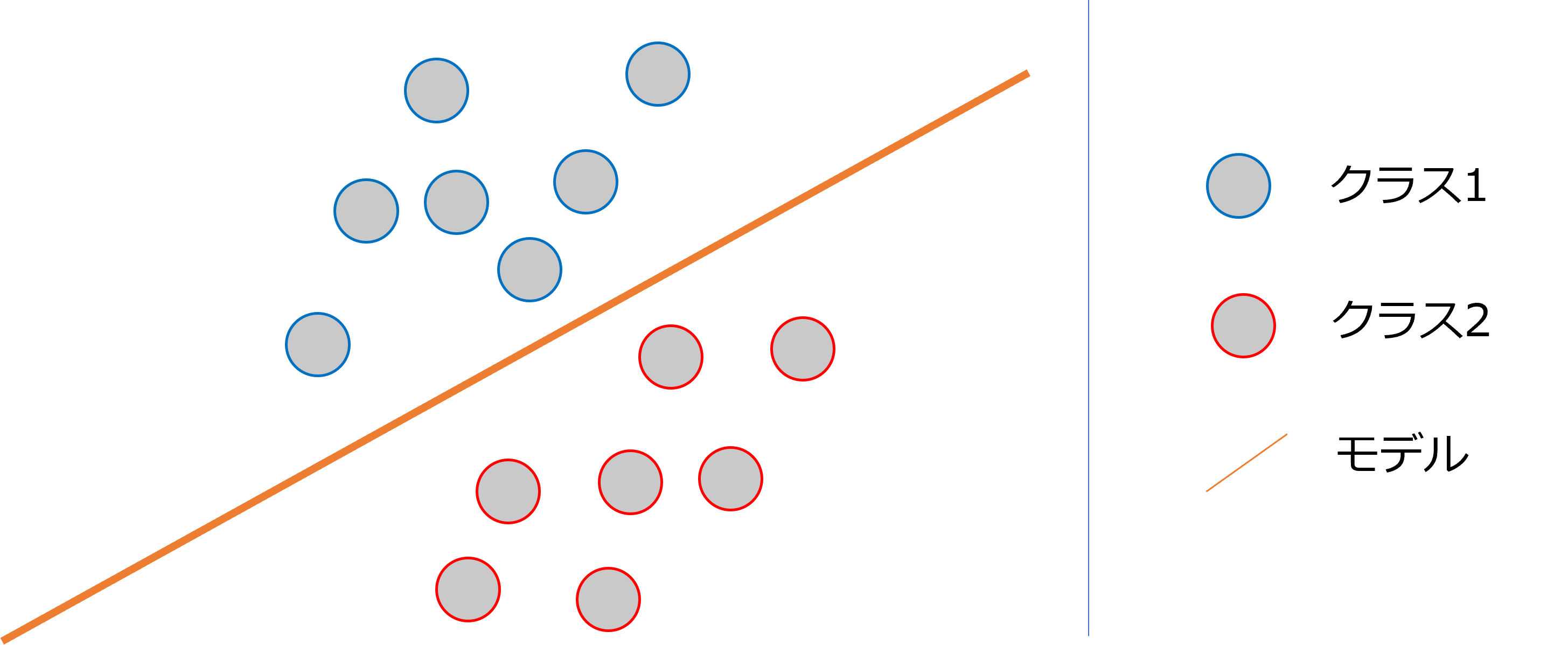
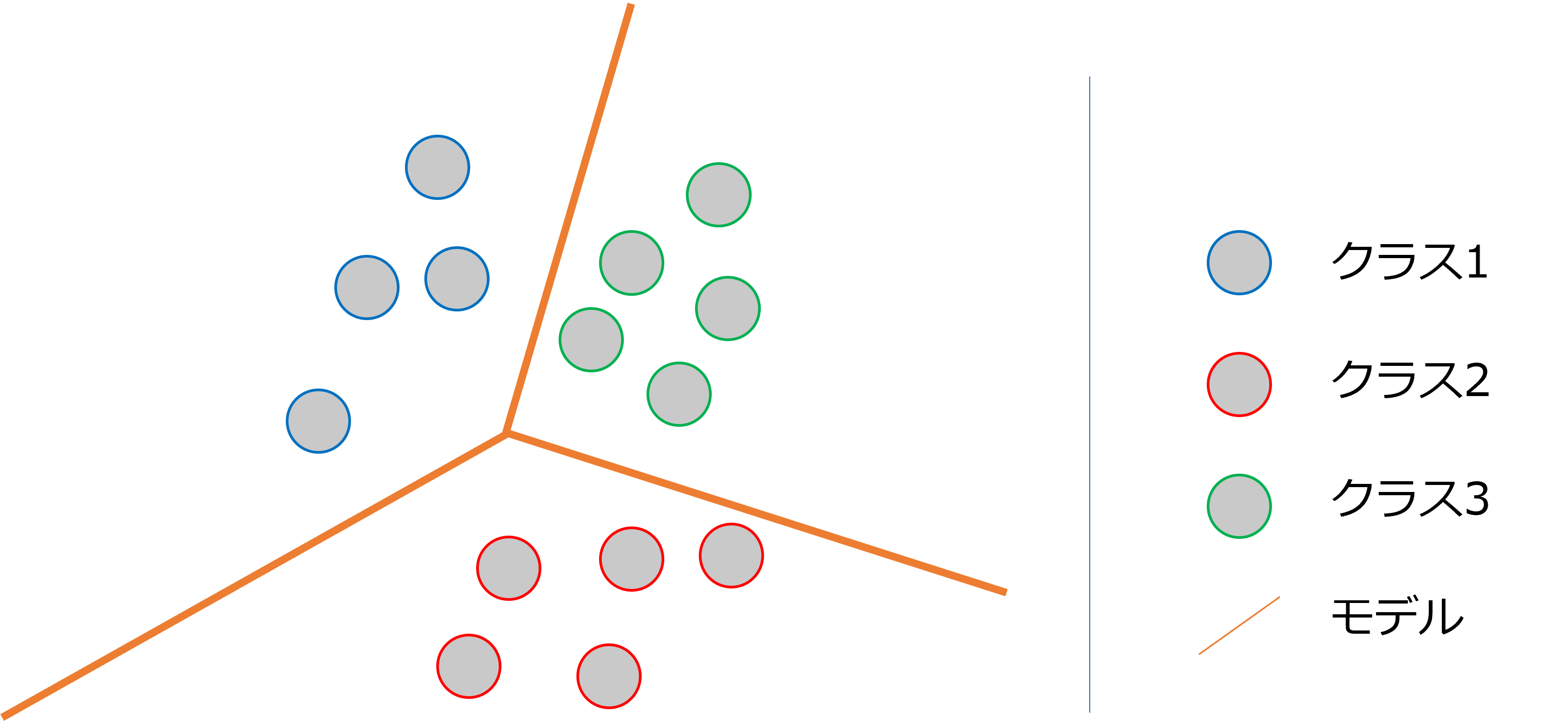
二次元平面上にあるデータで、1つの直線で分離できることを、線形分離可能といい、このアルゴリズムを線形分離器といいます。そして、これ以外の分類アルゴリズムを非線形分離機といいます。
線形分離
非線形分離
主要なモデル
・単回帰
線形回帰のモデルの一つで、参考となる既知の変数「独立変数」から、知りたい変数「従属変数」がそれぞれ一つずつしかないモデルです。
例としては「身長と体重」を学習させ、わかっている身長から体重を予測することを言います。
・重回帰
単回帰と異なる部分として、「従属変数」が複数あるものを重回帰といいます。
・サポート・ベクター・マシン(SVM)
特に分類に向いた手法ですが、分類と回帰の両方に使用できます。回帰に使用する際は、サポートベクター回帰(SVR)といわれます。
サポートベクターとは「データを分割する直線に最も近いデータ」のことを言います。サポートベクターを定めると、分類の際の基準が明確になり、精度が高まることが期待されます。
また、少ないデータで高い識別性能を期待でき、過学習も起こりにくいという特徴があります。
2クラス分類向けであるため、クラス数の多い学習には向きません。そして、学習データが増えると計算量が膨大になります。
・ロジスティック回帰
複数の要因から、2値の結果が起こる確率を分析・予測する手法です。
「買う/買わない」や「はい/いいえ」などの二つしか答えがないものを2値といいます。
要因は連続値でも、2値でもよく、商品の購入率を分析するときには「気温」「時間」「価格」などの連続値と「性別」などの2値の値から、「買う/買わない」の確率を分析します。
・決定木
分類木と回帰木があり、その名の通り、分類と回帰が可能です。
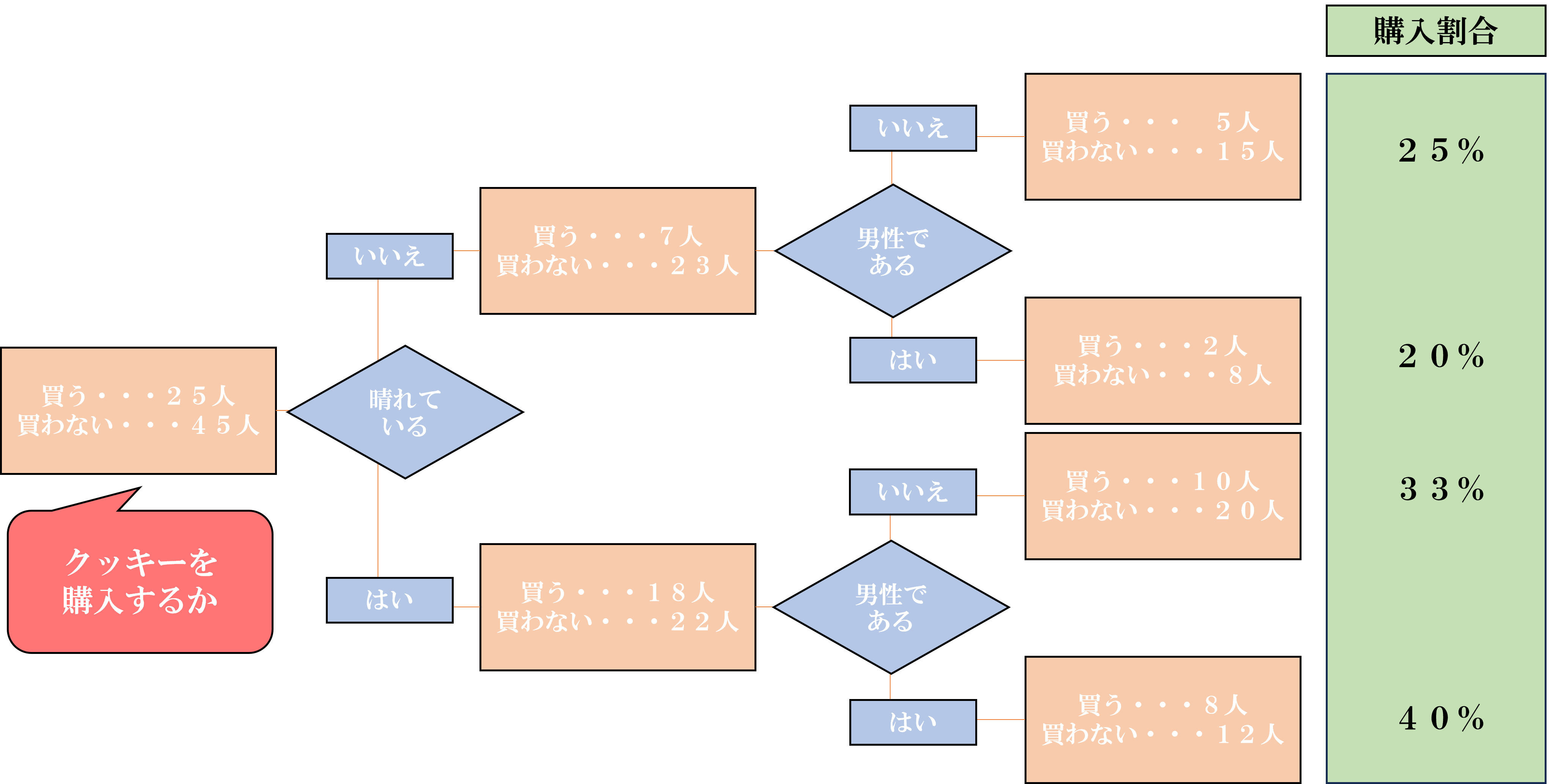
この分類や回帰を行うために、樹木状のモデル、つまり樹形図を作成する分析方法が決定木になります。少しわかりづらいと思ったので図であらわします。
この図では、「晴れていない日」に「男性以外」がクッキーを買う確率は25%というように、要因で枝分かれしていき、割合を計算していきます。
・ランダムフォレスト
複数の決定木を使用することで、平均や多数決を計算でき、より精度の高いデータを求めることができます。
・k近傍法
一般的に分類に使用されますが、回帰にも使用できます。
分析したいデータに近いデータを分類済みのデータから近い順にいくつか選びます。選んだデータに最も多く含まれているグループに、分析したいデータが分類されると考えることがk近傍法です。
・ニューラルネットワーク
主にディープラーニングで使用される手法で、人間の脳内にある神経細胞とそのつながりを数式的に表したものになります。
複数の層に分割されており、1つの入力層、複数の隠れ層、1つの出力層に分かれています。この順にデータが移動していくのですが、データが移動する際に、すべてのデータがそのまま移動するわけではなく、移動しないデータがあったり、重みの影響を受け、値が調整されて移動することもあります。この処理を繰り返すことで、分析・予測を行うことができます。
評価方法
機械学習では、収集したデータを学習用データとテストデータに分け、学習と評価を行います。学習用データで学習し、モデルを形成したのち、テストデータを使用し、予測・分析をした結果をラベルと比較し、精度を判別します。評価も学習モデルによって、異なります。
例えば、分類を目的とした学習では、テストデータを分類した結果が何件中何件当たっていたかが評価の指標になります。
回帰の場合は、モデルで評価した結果と実際に計測した結果がどのくらい異なるかが、評価の指標になります。
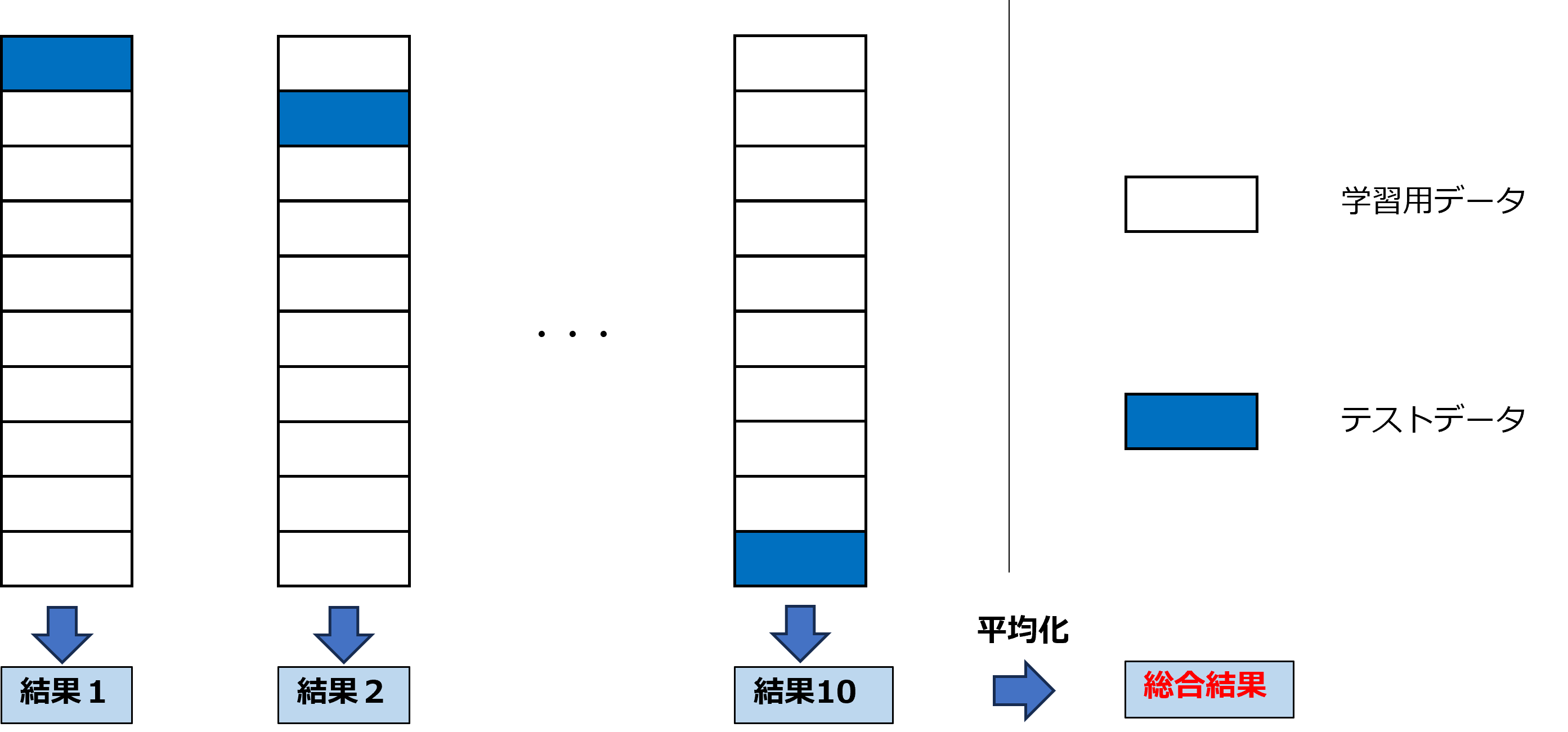
交差検証(クロスバリデーション) とは
交差検証とは、用意したデータを分割し、すべてのデータがテストデータと学習データに使用されるように、学習とテストを繰り返し、スコアの平均を求める手法です。
活用例
ここまでで紹介してきたように、教師あり学習は、正解や答えが明確にある問題に対して、大きな効果を発揮します。特に、学習データが多いとよりその効果は大きくなり、様々な場面で役に立ちます。ここではその一部を紹介します。
・天気予測
・価格予測需要予測
・天気予測
・価格予測
・画像認識
・音声認識
・スパムメール判別
さいごに
今回は、教師付き学習についてまとめました。機械学習において、基本的ではありますが、重要な部分でたくさんの分野でも使用されているものなので、理解していて損はありません。
次は、教師なし学習についてもまとめています。
ReceiptRollerでは電子レシートをはじめとし、様々なソリューションを提供していきます。
今回の機械学習のほかに、OCRについての記事も投稿していますので読んでみてください。
レシートOCRは、LINEからどなたでも無料でご利用いただけますので、
ぜひ試してください!
また、OCRのデモ体験がこちらのページからできます!
参考