はじめに
OpenAI Agents SDKやAutoGen、LangGraph等、様々なエージェント フレームワークが出てきていますが、これらのチュートリアルやサンプルをみてみても「どうしたら上手く活用できるのか」という点がいまいちピンと来ていませんでした。
こうした中、LangChainのGitHubレポジトリでLangGraphを用いて実装された「Open Deep Research」があり内容を確認したところ、プランニングからフィードバックといったエージェントに関する機能が一通りの実装されており、かつ規模も手ごろで実用的だと感じたため調査してみました。
今回、他のフレームワークとの比較と技術習得を兼ねて、この「Open Deep Research」をOpenAI Agents SDKで再実装してみましたので、その移行時のポイントと所感について皆さんと共有したいと思います。
また参考としてAzure OpenAI Serviceで利用可能な各モデル(GPT-4.1、GPT-4o、o1-mini、o3-mini、o1)にて実行した結果についても掲載させて頂きます。
Open Deep Research概要
Open Deep Researchの処理イメージを下記に引用します。こちらの図の通り最初にトピックとアウトラインを与えると、必要な構成(セクション)を検討(Planning)し、このセクション毎にWebから検索、記事を記載(LLMによるチェック含む)し、これを結合することで記事を作成するものとなっています。
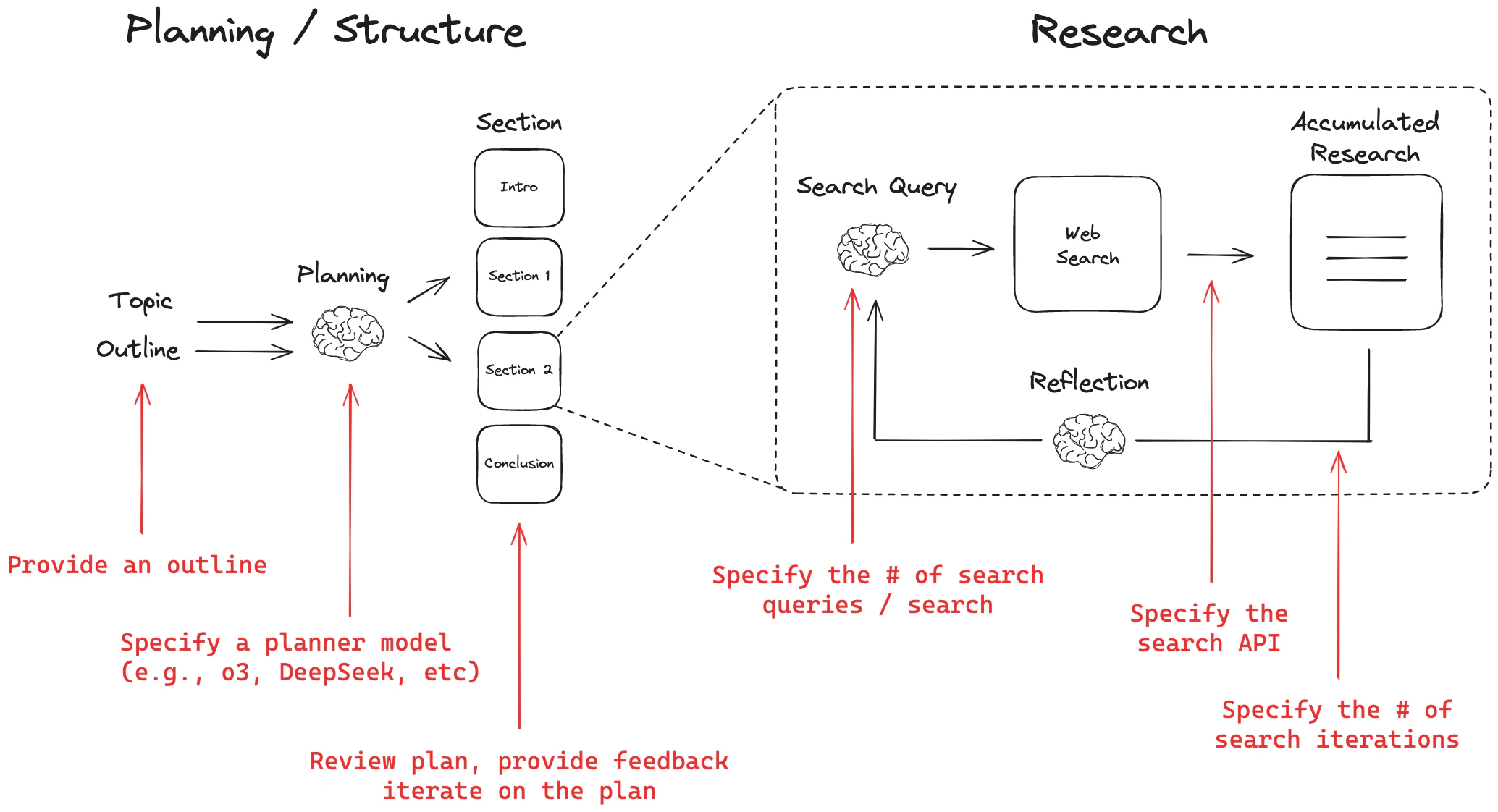
LangGraphにて出力した実際の処理フローは下記の通りになります。
最初の構成を検討するPlanningフェーズにて、ユーザからのフィードバックを行い、その結果に基づいて記事を生成するという処理になりますが、これらについてOpenAI Agents SDKにて再実装してみます。
実装したコードについては、本記事の付録に掲載していますので、何かのご参考になれば幸いです。
LangGraphからOpenAI Agents SDKへの移行ポイント
LangGraphからOpenAI Agents SDKへ移行した際のポイントとして「実行制御と状態の保持」と「プランニング等におけるLLMの呼び出し」に関して説明します。
なお利用したOSSのバージョンは以下の通りとなっています。
- LangChain: v0.3.23
- LangGraph: v0.3.30
- OpenAI Agents SDK: v0.0.10
- Open Deep Research ※2025年4月17日時点で最新のもの
実行制御と状態の保持
LangGraphはDAG(Directed Acyclic Graph: 有向非巡回グラフ)ベースのフレームワークですが、このグラフの構築個所を以下に抜粋します(ソース L459付近)。
状態についてはグラフ初期化時に状態保持クラスや必要に応じて入出力や設定クラスについても渡しグラフを構築します。
# ------- (省略) --------
# Outer graph for initial report plan compiling results from each section --
# Add nodes
builder = StateGraph(ReportState, input=ReportStateInput, output=ReportStateOutput, config_schema=Configuration)
builder.add_node("generate_report_plan", generate_report_plan)
builder.add_node("human_feedback", human_feedback)
builder.add_node("build_section_with_web_research", section_builder.compile())
builder.add_node("gather_completed_sections", gather_completed_sections)
builder.add_node("write_final_sections", write_final_sections)
builder.add_node("compile_final_report", compile_final_report)
# Add edges
builder.add_edge(START, "generate_report_plan")
builder.add_edge("generate_report_plan", "human_feedback")
builder.add_edge("build_section_with_web_research", "gather_completed_sections")
builder.add_conditional_edges("gather_completed_sections", initiate_final_section_writing, ["write_final_sections"])
builder.add_edge("write_final_sections", "compile_final_report")
builder.add_edge("compile_final_report", END)
# ------- (省略) --------
一方でOpenAI Agents SDKには、2025年4月18日時点ではツール等に渡すコンテキストを設定する機能はあるものの状態の管理やDAGといった機能はないため、純粋にコードにて実装しています。
OpenAI Agents SDKのドキュメントによると、複数のエージェントのオーケストレーションの方法としてLLMによる方法とコードによる方法と2つ紹介されており、今回は後者の「コードによるオーケストレーション」にて実装した形になります。
# ------- (省略) --------
async def main() -> None:
# 設定と状態の初期化
config = Configuration()
report_state = ReportState(topic=topic, completed_sections=list())
while True:
# フィードバックが完了するまで、レポートの生成計画を作成する
await generate_report_plan(report_state, config)
if await feed_back(report_state):
break
# 再検索が必要なセクションについて検索を実施
for s in report_state['sections']:
if s.research:
section_state = await build_section_with_web_research({"topic": topic, "section": s, "search_iterations": 0}, config)
report_state["completed_sections"].append(section_state["completed_section"])
# ------- (省略) --------
プランニング(実行計画)等におけるLLMの呼び出し
LangGraphのOpenDeepResearchでは、通常の文章生成以外のプランニングや検索クエリ等の生成では下記の通り構造化出力(Structured outputs)を用いて文書構造の作成や再検索等の判断を実施しています(ソース L78付近)。
これは前述のOpenAI Agents SDKのドキュメントにて記載されている「コードによるオーケストレーション」にて記載されている方法と同様となっています。
async def generate_report_plan(state: ReportState, config: RunnableConfig):
# ------- (省略) --------
# Set writer model (model used for query writing)
writer_model = init_chat_model(model=writer_model_name, model_provider=writer_provider)
structured_llm = writer_model.with_structured_output(Queries)
# Format system instructions
system_instructions_query = report_planner_query_writer_instructions.format(topic=topic, report_organization=report_structure, number_of_queries=number_of_queries)
# Generate queries
results = structured_llm.invoke([SystemMessage(content=system_instructions_query),
HumanMessage(content="Generate search queries that will help with planning the sections of the report.")])
# Web search
query_list = [query.search_query for query in results.queries]
# ------- (省略) --------
このコードをOpenAI Agents SDKを用いて記載し直すと以下の通りとなります。
Agent作成時に、指示としてSystemMessageのコンテンツを設定し、構造化出力のためにoutput_typeを指定しています。
次にRunnerにてAgentを実行する際に、入力としてHumanMessageのコンテンツを設定しています。
output_typeの詳細は、OpenAI Agents SDKのドキュメントに記載されていますが、LangChainと同様にPydanticモデルに対応しているので、特に元のクラスを変更することなく利用することが可能です。
# Format system instructions
system_instructions_query = report_planner_query_writer_instructions.format(topic=topic, report_organization=report_structure, number_of_queries=number_of_queries)
# Generate queries
generate_search_queries_agent = Agent(
name="Generate search queries agent",
instructions=system_instructions_query,
output_type=Queries,
model=config.writer_model_name,
)
result = await Runner.run(starting_agent=generate_search_queries_agent,
input="Generate search queries that will help with planning the sections of the report.")
# Web search
query_list = [query.search_query for query in result.final_output.queries]
(参考) LangGraphとOpenAI Agents SDKの比較
今回移行した際に検討・確認した範囲におけるLangGraphとOpenAI Agents SDKの比較は以下になります。
他にもエージェント機能として比較した方が良い項目があるかと思いますが範囲を絞らせて頂きました。ご了承ください。
| LangGraph / LangChain | OpenAI Agents SDK | |
|---|---|---|
| 対応LLM | OpenAI、Anthropic等多岐 | LiteLLMと統合(ベータ版) |
| グラフ生成 | Mermaid、Graphviz | Graphvizのみ |
| 状態の管理 | LangGraphにて管理可能 | コードで実装 |
| 会話履歴の管理 | LangChainにて実装可能 | Responses APIを利用 |
| Human-in-the-loop | interrupt関数を使用 | コードで実装 |
| Handoffの実装方法 | LLMの構造化出力にて判断させコードにて遷移させる | handoff引数やhandoff関数を用いて実装する |
| MCPの対応 | LangChain MCP Adaptersを利用 | SDKに組み込み |
Azure OpenAI Serviceの各モデルにおける実行結果
参考までにトピックを「生成AIのエージェントと今後の展望(2025年)」とした場合のAzure OpenAI Serviceで利用可能な各モデルでの実行結果を共有させて頂きます。
実行結果の特徴ですが、o1、o3-miniは各セクション作成後のWebの詳細検索は実施されず、GPT-4.1-nanoはソース(出典)の記載方法が各セクションで異なっており安定性に欠ける結果となりました。
詳細については各実行結果をご確認ください。
GPT-4.1-mini (2025-04-14)
GPT-4.1-miniでの実行結果
# 生成AIのエージェントと今後の展望(2025年)
生成AIエージェントは、単なる指示に応じて文章や画像を作成する生成AIとは異なり、自律的に環境を認識し、複雑な目標達成のために多様なタスクを計画・実行できる高度なAIシステムです。その能動的かつ継続的な自己改善能力により、日常生活から企業の業務プロセスまで幅広い領域で応用が拡大しています。本レポートでは、生成AIエージェントの基本的な仕組みや2024年の技術進展を踏まえ、2025年に期待される最新トレンドや実際の企業活用事例、さらに導入に際しての課題と解決策までを総合的に解説します。急速に進化するAIエージェント技術の全体像とその社会的意義を明確にし、未来のデジタルトランスフォーメーションの鍵としての可能性を探ることを目的としています。
## 生成AIエージェントの基礎知識
AIエージェントとは、ユーザーに代わって目標達成のために最適な手段を自律的に選択し、複数のタスクを遂行する高度なAIシステムです。人間の介入を最小限に抑え、設定された目標に向けて環境を認識し、分析、計画し、実際の行動を行います。複数のAIモデルや外部API、ウェブ検索など様々なリソースを活用し、単一の生成AIでは対応困難な複雑なタスクも処理可能です[1][2][3][4]。
生成AIとの違いは、生成AIが主に文章や画像、音声といったコンテンツの生成に特化し、ユーザーの指示に「受動的」に応答するのに対し、AIエージェントは「能動的」に目標に基づくタスクを企画・実行し、環境と対話しながら自己修正も行う点にあります[1][2][3]。生成AIはプロンプト応答型であり、自律性は低い一方、AIエージェントは自律的に環境に適応し複合的に行動する能力を備えています[2]。
AIエージェントは主に2種類に分類されます。個人向けのパーソナルエージェントはスケジュール管理や情報収集、日常生活の支援を提供し、一方で企業向けの企業エージェントは業務自動化、生産性向上、データ分析、カスタマーサポート等に活用されます[1][3]。また、構造的には反応型、モデルベース型、目標ベース型、効用ベース型、学習型、階層型など多様なタイプが存在し、用途や環境に適した設計がなされます[3]。
AIエージェントの基本仕組みは、環境の認識(センサー等を通じた情報収集)、意思決定(機械学習や強化学習による行動選択)、そしてアクチュエーターを介した物理的・デジタル的行動実行からなります。これにより、継続的な学習や適応、自己反省を繰り返しながら目標達成を目指します[3]。
このように、AIエージェントは単なるコンテンツ生成を超え、複雑で連続的な業務や環境への能動的な対応を可能にすることで、業務効率化やサービス品質向上に欠かせない技術として注目されています。
### Sources
[1] AIエージェントとは? 生成AIとの違いや特徴を分かりやすく解説: https://www.softbank.jp/biz/blog/business/articles/202412/what-is-ai-agent/
[2] AIエージェントとは?特徴や生成AIとの違い、種類や活用シーンを紹介: https://aismiley.co.jp/ai_news/what-is-ai-agent-introduction/
[3] 【初心者向け】AIエージェントとは?生成AIとの違いや特徴、活用例 ...: https://promo.digital.ricoh.com/ai-for-work/column/detail006/
[4] AIエージェントで何ができる?生成AIとの違い・自律的に考える ...: https://ai-market.jp/technology/ai-agent/
## 2024年の生成AIエージェント技術の進展
2024年は生成AIエージェント技術において劇的な進展が見られました。特にマルチエージェントシステム、GUIエージェント、AIエージェントを用いたシミュレーション技術、そして評価手法に関する最新動向が注目されています。
まずマルチエージェントシステムでは、複数のAIエージェントが役割分担と協調を行いながら複雑なタスクを自律的に処理する仕組みが実用化段階に入りました。人間の組織構造に類似した階層的システムが構築され、ソフトウェア開発の設計・テストから多言語翻訳まで多様な領域で活用が進んでいます。このアプローチは専門性に応じたエージェント分割による高精度化や、並列処理による時間短縮、拡張性の利点をもたらしています[1][2]。
次にGUIエージェントの進展も著しく、自然言語指示によって既存のグラフィカルユーザーインターフェースを横断的に操作可能となり、Webブラウザやデスクトップアプリケーションの複雑な操作が自動化されています。スクリーンショット解析技術の向上によりUI要素の理解が精緻化し、ユーザーは手軽に多様なアプリケーション操作を対話形式で指示できるようになりました。ただし、悪意のある攻撃に対する脆弱性も課題として残っています[1][3]。
AIエージェントを用いたシミュレーション技術は、マルチエージェントの相互作用を駆使し、社会や市場動向、購買行動、感染症拡大などの複雑な社会現象をリアルに模倣可能となっています。各エージェントが独自の記憶と学習機能を持ち、長期的かつ動的な相互作用を通じて高度に適応するため、従来のルールベースシミュレーションでは困難だった状況の再現が可能です。これにより政策立案や教育、都市計画など幅広い分野での応用が期待されています[1][4]。
最後にAIエージェントの評価手法では、従来の最終結果のみを評価する方法の限界を克服するため、タスク実行の中間プロセスやステップごとに性能を分析する新たなフレームワークが登場しました。例えば、AI自身が他のAIエージェントを評価する「Agent-as-a-Judge」や複数ドメイン間で根本的能力を評価する「MMAU」などが開発され、評価の精度向上と効率化に寄与しています[1][5]。
これらの技術進展は生成AIエージェントの多様な活用可能性を大幅に拡大させ、2025年以降の日常生活やビジネス実装に大きな影響を与えることが期待されます。
### Sources
[1] AIエージェント技術最新トレンド:2025年を見据えて2024年を振り返る: https://www.brainpad.co.jp/doors/contents/ai_agent_trend/
[2] LLMエージェントのデザインパターン、Agentic Design Patternsを理解する: https://zenn.dev/loglass/articles/b9ee37737deb85
[3] UFO: A UI-Focused Agent for Windows OS Interaction (論文紹介): https://arxiv.org/abs/2402.07939
[4] Project Sid: Many-agent simulations toward AI civilization (論文紹介): https://arxiv.org/abs/2411.00114
[5] Agent-as-a-Judge: Evaluate Agents with Agents (論文紹介): https://arxiv.org/abs/2410.10934
## 2025年における生成AIエージェントの最新トレンドと展望
2025年は「AIエージェント元年」とされ、多くの企業が自律型AIエージェントの実用化に踏み切っています。AIエージェントは単なる指示待ちAIではなく、環境を認識し、複雑なタスクを自律的に計画・遂行できる技術として大きく進化しました。MicrosoftのCopilot StudioやOpenAIのOperatorなど、主要なプラットフォームが多様な業務を自動化し、業務効率化や意思決定支援に貢献しています[1][2][3]。
自律型エージェントはプロアクティブにユーザーのニーズを察知し、旅行手配の予約や支払い、業務プロセスの自動化までを担います。AI同士が連携するマルチエージェントシステムの採用も拡大し、物流、金融、製造業など複雑な業務の効率化を実現しています。例えば、製造業ではIoTセンサーによるリアルタイムデータ解析で在庫管理や予防保全が進み、金融業界では不正取引検知や市場分析への応用が活発化しています[2][3]。
また、AIエージェントは個人の行動や環境情報をリアルタイムで分析し、健康管理や学習支援など高度なパーソナライゼーションを実現。スマートホームの家電制御やロボティクス技術との融合により、生活全般の利便性も向上しています。エージェントコマースとしてAIが自動的に購買や予約を行う市場も拡大中です[1][2]。
将来的にはAIエージェントが企業のIT部門の中心となり、従業員ごとに専用エージェントが協働し、業務のあらゆる側面をサポートする新たな労働環境の創出が期待されています。一方で、意思決定の透明性や倫理面、プライバシー保護といった課題にも注力する必要があります[1][3]。
総じて、2025年の生成AIエージェントは技術的成熟とビジネス応用の深化により、ロボティクス・IoT連携やパーソナライゼーションを伴った社会全体のデジタルトランスフォーメーションを加速する柱として位置づけられています。
### Sources
[1] AIエージェントが描く2025年の世界 | HUMAN ∞ TRANSFORMATION: https://www.ridgelinez.com/hx/contents/transformation-20250123/
[2] 【2025年最新】AIエージェントとは?仕組み・活用事例・導入メリットを徹底解説! | Aidiotプラス: https://aidiot.jp/media/ai/post-7998/
[3] 2025年AIエージェント元年:ビジネスと社会の大転換点 | Zenn: https://zenn.dev/acntechjp/articles/20250405_ai_agent_era
## 生成AIエージェントの企業活用事例と効果
2024年から2025年にかけて、多くの企業が生成AIエージェントの導入を加速させており、業務効率化や新規事業創出、人手不足解消など多様なメリットが報告されています。生成AIは従来のチャット型AIと異なり、自律的にタスクを判断・実行できるため、より高度な業務プロセスの自動化が可能です。
まず、大手企業の事例としては、パナソニック コネクトがChatGPTをベースに開発したAIアシスタントの導入により、約1年で全社員の労働時間を18.6万時間削減しました。社員のAIスキルも向上し、戦略策定や商品企画といった高度業務への活用が進んでいます。また、情報漏洩などの重大トラブルも未然に防いでいます。一方、LINEヤフーは独自AIアシスタントにより7%の生産性向上を実現し、AIペアプログラマー導入で約10〜30%の効率改善を達成しました。さらにメルカリは出品時のAIアシスト機能によりユーザーの操作負荷を軽減し、売れやすい商品情報の自動提案で顧客体験を大幅に改善しています。学研ホールディングスも教育システムにChatGPTを活用し、個別学習支援を強化しています[1][2][3][4]。
具体的なメリットは、①業務効率化:文書作成やメール対応の自動化により人間は創造的業務に専念可能、②人手不足の解消:AIが定型・非定型業務の一部を代替、③顧客体験の向上:パーソナライズされた対応の実現、④新規ビジネス創出:AIを活用した新サービスやプロダクトの開発があります。成功要因は目的の明確化、適切なAIモデル選定、段階的導入と効果測定、データ品質管理、組織体制と人材育成の整備にあります。これにより単なるツール導入を超え、企業の競争力強化につなげることができます[1][2][3][4]。
今後さらにマルチモーダル処理や高度な推論能力、RAG(検索拡張生成)技術などによる精度向上、環境適応型AIエージェントの進化が期待され、業界横断型の連携も進展する見込みです。生成AIエージェントは企業のDX推進と人材課題解決に不可欠な技術として、2025年以降さらに広く普及していくでしょう。
### Sources
[1] 生成AIの急成長〜企業が知っておくべき最新トレンドと導入ポイント: https://aidiot.jp/media/ai/post-7973/
[2] 【2025年版】生成AIの最新トレンドと企業活用の実践ガイド - ASCII.jp: https://ascii.jp/elem/000/004/259/4259087/
[3] AIエージェント5つの種類を徹底解説!導入メリットや事例を紹介: https://www.lightblue-tech.com/column/ai%E3%82%A8%E3%83%BC%E3%82%B8%E3%82%A7%E3%83%B3%E3%83%885%E3%81%A4%E3%81%AE%E7%A8%AE%E9%A1%9E%E3%82%92%E5%BE%B9%E5%BA%95%E8%A7%A3%E8%AA%AC%EF%BC%81%E5%B0%8E%E5%85%A5%E3%83%A1%E3%83%AA%E3%83%83/
[4] 業界×AIエージェントの活用方法: 2025年最新動向 - Zenn: https://zenn.dev/acntechjp/articles/20250402_industry_ai_agents
[5] AIエージェントとは?仕組みから活用例まで完全解説【2025年最新】: https://usknet.com/dxgo/contents/dx-technology/what-is-ai-agent/
## 生成AIエージェント導入に伴う課題と解決策
生成AIエージェントの企業導入にあたっては、データセキュリティ、法規制対応、運用体制構築、組織文化変革、評価指標の整備といった多面的な課題に対処する必要があります。まず、データセキュリティでは、社内データを情報の機密度ごとに分類し、段階的なアクセス制御を実施することが肝要です。特に金融や医療分野では暗号化や匿名化技術、24時間監視体制の確立が不可欠であり、多層的なセキュリティ対策により機密情報の漏洩リスクを抑えつつ安全な利用を実現しています[1][4]。
法規制面では、国内外のAI関連ガイドラインを四半期ごとにチェックし、社内ルールとしてAI利用範囲や責任区分を明確化します。AIの出力情報の検証プロセスを整備し、法務部門と情報システム部門が連携して運用状況を監査することが効果的です[1]。
運用体制の確立では、推進チームの結成や教育プログラムの段階的展開が重要です。組織内でのAIリテラシー向上を図ることで、従業員の抵抗感を軽減し、活用効果を高めます。さらに、AI管理者や監督者の配置により運用負荷の軽減と継続的改善を促進できます[1][4]。
組織文化の面では、AIエージェントが自律的判断を行う新たなワークスタイルに適応するため、役割の再定義や人間とAIの協働モデルを導入します。AIによる高度な業務支援が進む中で、人間の創造性や倫理的判断の価値再編が求められ、従業員のリスキリングや組織の柔軟性強化も課題となります[2][4]。
評価指標の整備に関しては、工数削減率、エラー低減率、顧客満足度などのKPIを設定し、段階的に効果を検証します。ROIを高めるためには、AI活用と業務プロセス全体の最適化を同時に進めることが求められます。また、投資対効果を可視化し、段階的な展開計画を全社で共有することが成功の鍵です[1][5]。
これらの課題を統合的に管理し、段階的かつスモールスタートで導入を進めるアプローチが推奨されます。企業はまず限定的な範囲でAIエージェントを試験導入し、効果と課題を把握した上で全社展開へと拡大するべきです。こうした慎重かつ計画的な進め方によって、安全性と効率性を両立した生成AIの活用が実現し、組織のDX推進に貢献します。
### Sources
[1] 【2025年版】生成AIの最新トレンドと企業活用の実践ガイド: https://usknet.com/dxgo/contents/dx-technology/the-latest-trends-in-generative-ai-and-practical-guide-for-business/
[2] 賢くなりすぎるAI、新しい組織論の構築が不可欠に: https://xtech.nikkei.com/atcl/nxt/column/18/03130/040800008/?i_cid=nbpnxt_pgmn_topit
[4] デジタルマーケティングの未来を変える:AIエージェント活用で実現 ... : https://dmp.intimatemerger.com/media/posts/14714
[5] 2025年に訪れる“AIエージェント元年” 中小・中堅企業が生産性を ... : https://note.com/mask_ai/n/n41f3682bb814
## まとめと今後の展望
本レポートで示した生成AIエージェントの技術動向と企業活用の現状を踏まえ、2025年以降の展望を以下の表に整理する。
| 項目 | 現状の特徴 | 2025年の展望・課題 |
|------------------|--------------------------------|-----------------------------------------|
| 技術進展 | マルチエージェントシステムの実用化。GUIエージェントによる多様なUI操作自動化。評価手法の多様化。 | 自律的かつプロアクティブに環境適応。高度な連携・推論機能の強化。安全性・倫理面の課題解決。 |
| 企業活用 | 効率化・人手不足解消・新規事業創出を実現。多業種で生産性向上や顧客体験改善に寄与。 | 組織内に専用AIエージェント導入拡大。業務全般への統合的活用とリスキリング促進。 |
| パーソナライゼーション | 個人の行動分析による支援が進展。スマートホームやロボティクスとの連携基盤整備。 | 利用者ごとに最適化されたサービスの普及。IoT連携による生活全般の高度支援。 |
| 導入課題・対応策 | セキュリティ・法規制・運用体制に対し段階的対応が進む。組織文化変革や評価指標整備が必要。 | 組織全体の柔軟な変革と透明性確保。包括的なAI管理体制と倫理基準の定着が急務。 |
生成AIエージェントは単なるタスク自動化を超え、環境認識・自己修正が可能な高度自律システムとして成熟しつつあります。企業は段階的かつ計画的に導入を進め、実効性の高い活用法を模索する必要があります。今後は技術進化と倫理面の調和を図りつつ、ユーザーの生活や働き方を根本から変革する社会実装が期待されます。具体的には、AIエージェントと人間の協働による新たな労働モデル構築や、多領域AI連携による複雑問題の解決が次の課題となるでしょう。
GPT-4.1-nano (2025-04-14)
GPT-4.1-nanoでの実行結果
# 生成AIのエージェントと今後の展望(2025年)
## 序論
生成AIとAIエージェントは、私たちの働き方や暮らし方を大きく変えつつあります。生成AIは、文章や画像、音声などのコンテンツを素早く作り出す技術ですが、AIエージェントはそれらを活用し、自律的に判断や行動を行うシステムです。2022年以降、技術の進化により、AIエージェントは多様な環境へ適応し、複雑なタスクをこなすようになっています。今後もその自律性や協調性の向上が期待され、2025年には社会のあらゆる場でなくてはならない存在となる見込みです。こうした動向を踏まえ、本報告では、生成AIの背景や進化、未来展望を明らかにし、その社会的・ビジネス的な役割とともに、直面する課題についても考察します。
## 生成AIとAIエージェントの基本理解
生成AIとAIエージェントは、どちらも人工知能技術を活用したシステムですが、その役割や仕組みには明確な違いがあります。まず、生成AIはChatGPTのように、入力されたプロンプトに従って文章や画像、音声などのコンテンツを受動的に生成する技術です。これに対し、AIエージェントは設定された目標に向かって自律的に環境を認識し、判断・行動を行う能動的なシステムです(【1】【2】【3】)。
AIエージェントの特徴は、環境認識能力と環境に基づいた自律的な意思決定を行う点にあります。例えば、環境から入手したデータをもとに、次に取るべき行動を計画し、実行し、結果を評価して改善するサイクルを繰り返します。これにより、人間の介入なしに複雑なタスクや問題解決を行うことが可能です。これらの能力は、環境をリアルタイムに認識し、適応しながらタスクを遂行するための自律行動の根幹となっています。
一方、生成AIは主にユーザーからの指示に応じてコンテンツを作成します。たとえば、文章や画像の生成、翻訳や要約など、クリエイティブな作業を支援します(【4】【5】【6】)。この違いにより、生成AIは情報やコンテンツの生成に優れ、AIエージェントは複雑な業務の自動化や意思決定支援に適しています。
これらを踏まえると、生成AIは「受動的な指示待ち」としての役割を持つのに対し、AIエージェントは、「能動的に環境を認識し、自律的に行動する」システムと理解できます(【7】【8】【9】)。そして、これら二つの技術は組み合わせることで、より高度な業務支援や価値創造を実現することが期待されています。
### 出典
【1】https://usknet.com/dxgo/contents/dx-technology/what-is-ai-agent/
【2】https://aidiot.jp/media/ai/post-7998/
【3】https://www.nextech-week.jp/hub/ja-jp/blog/article_10.html
【4】https://www.comitx.jp/blog-list/b250304-1/
【5】https://harbest.io/documents/1469/
【6】https://www.zdh.co.jp/bi-online/aiagent/
【7】https://techvify-japan.co.jp/what-is-ai-agent/
【8】https://ai-market.jp/technology/ai-agent/
【9】https://www.mri.co.jp/knowledge/opinion/2025/202504_1.html
## AIエージェントの進化と現状分析
2022年以降、生成AIの大きな進展に伴い、AIエージェントは従来のただ情報を出すツールから、自律的に複雑なタスクを遂行できるシステムへと大きく変貌しています。例えば、OpenAIのChatGPTやGoogleのGeminiは、高度な自然言語理解とマルチモーダル処理能力を搭載し、質問応答だけでなく、画像や動画の生成、複雑な意思決定まで一貫して行えるようになっています[6][10]。
技術面では、対話理解・自己判断・状況適応を可能にする複数の新技術が登場し、エージェントのブラックボックス性を軽減し透明性を高める努力も進んでいます。一方、マルチエージェントシステムやゲーミングシミュレーションなどでは、多数のAIが協調・競合しながら、大規模な社会や経済のシミュレーションが実現しつつあります[13][14]。
ただし、現状のAIエージェントは、多段階推論の信頼性や誤動作のリスク、データのプライバシーやセキュリティの課題も併存しています[4][12][16]。特に自律的に意思決定を行うシステムでは、責任の所在や偏見の排除など法的・倫理的課題も深刻です。これらについては、AIガバナンスプラットフォームや信頼性評価手法が導入されつつあり、今後の進展とともに解決策が模索されています[9][15][17]。
今後の展望として、エージェント型AIは、各種業務の自動化・意思決定支援や、異種情報の融合、高度な社会シミュレーションにおいて重要な役割を果たすと見込まれます。多国籍な研究や政府支援のプロジェクトにおいても、長期記憶や自己改善を備えた高信頼性の自律エージェントの開発が進められ、実用性と倫理性の両立に向け、継続的な技術革新が期待されています[3][5][11]。
このように2022年以降の技術進化とともに、AIエージェントはより高度に、自律的、かつ社会的に適応できる存在へと変貌しており、2025年以降の社会やビジネスの基盤技術として不可欠な存在になると予測されます。
---
### 出典リスト
[3] IBM, 2024年最重要AIトレンド:人工知能のトップ・トレンド、https://www.ibm.com/jp-ja/think/insights/artificial-intelligence-trends
[4] NTT技術ジャーナル, 期待高まる国産生成AI、https://journal.ntt.co.jp/article/25744
[5] Forbes Japan, 自律AIエージェントの未来像、https://forbesjapan.com/articles/detail/60792
[6] arXiv.org, Recent advances in multimodal models, https://arxiv.org/abs/2411.00114
[9] Gartner, 生成AIのリスク管理とガバナンス、https://www.gartner.co.jp/ja/newsroom/press-releases/pr-20240910-genai-hc
[10] Zenn Dev, 生成AI最前線:2025年予測と展望、https://zenn.dev/takuyanagai0213/articles/2878bca0ccc400
[11] MRIオピニオン, AI研究と未来展望、https://www.mri.co.jp/knowledge/opinion/2024/202412_1.html
[12] ledge.ai, OpenAIの研究論文理解能力評価、https://ledge.ai/articles/openai_paperbench_ai_research_reproduction
[13] DeepResearch, シミュレーションとAIエージェントの進化、https://www.deep-research.co.jp/media/aimaster/
[14] Shift AI Times, 生成AI&AIエージェントに関する2025年予測、https://shift-ai.co.jp/blog/6505/
## 今後の展望と技術動向
2025年までに期待されるAIエージェントの進化は、従来の自動化や知識生成の域を超え、より高度な自律性と協調性を備えたシステムの台頭に向かっています。特に、言語理解と推論能力の向上により、AIエージェントは複雑な課題の分解と計画立案を自己完結的に行えるようになると予測されます。NVIDIAやGoogleの最新研究では、推論能力において「Chain-of-Thought」(思考の連鎖)や「推論スケーリング」といった技術が進歩し、モデルが段階的に論理を追う仕組みが構築されつつあります。これにより、算数の問題や科学的推論、さらには長期の計画立案など、多段階の課題解決が可能となってきています。
また、マルチエージェントシステムの発展も著しいです。複数のAIエージェントが協調・交渉しながら、分散型の大型タスクを処理する技術が実用化され、例えば生産現場や金融システム、都市交通管理等で導入の兆しが見えています。異なる専門性を持つエージェント間のコミュニケーションや役割分担の最適化により、ロバストかつ柔軟なシステムの構築が可能となります。
一方、技術的な課題も残存します。推論の説明性・透明性の確保が急務であり、OpenAIやスタンフォード大学などの研究では、「推論過程の評価方法」や「モデルの理解度向上」のための指標開発が進んでいます。これに合わせ、知識グラフや長期記憶、提案された外部ツール連携機能を組み合わせることにより、より正確で信頼性の高いAIエージェントの実現が見込まれています。
さらに、省エネルギーとスケーラビリティの観点から、エッジAIや軽量モデルの開発も本格化し、リアルタイム処理やプライバシー保護に寄与するシステムの普及も期待される。こうした技術革新が促進されることで、AIエージェントは社会インフラ、産業、ヘルスケアなど多岐にわたる分野で、高度に自律した協働システムとして重要な役割を担うことになるだろう。
これらの動向を総合すると、2025年までにAIエージェントは単なるツールから「意思決定を自律的に行う知的パートナー」へと進化し、社会の様々な課題解決に革新的なソリューションをもたらすとともに、新しい産業の仕組みや組織構造の変革を牽引することが期待されている。
## ビジネス応用と具体事例
2025年に向けて、生成AIとともに進化を遂げるAIエージェントは、多種多様な産業や業務プロセスで着実に実践活用されています。この応用範囲は、単なる自動化や情報提供にとどまらず、自律的な意思決定やツール連携、多エージェント協調といった高度な機能の導入へと拡大しています。
まず、製造業ではAIエージェントが生産ラインの予知保全や品質管理に活用されています。例えば、トヨタ自動車は、AIプラットフォームを提供し、現場の作業員が自らAIを構築・運用できる仕組みを導入することで、不良検知やラインの稼働効率化を実現しています。一方、AIを用いた全自動の生産計画や需要予測により、在庫の最適化やコスト削減も進んでいます。
金融分野では、AIエージェントを駆使した不正検知や投資アドバイスが広く取り入れられ、リアルタイムで大量の取引や顧客の行動を解析。例えば、りそなホールディングスは、AIによる不正検知システムで高精度の異常検出を実現し、既存システムの運用効率を向上させています。
小売・ECにおいては、顧客体験の向上や販売促進のために、AIエージェントがパーソナライズされたレコメンドや自動在庫管理、広告クリエイティブの自動生成を担います。たとえば、楽天は、AIによる需要予測や販促コンテンツ作成を通じて、顧客満足度と売上の両面で大きな効果を上げています。
また、医療分野では、患者インタラクションをサポートするAIエージェントが導入され、問い合わせ対応や医師へのレポート作成、自動診断支援も進んでいます。こうしたシステムの導入により、医療スタッフの負荷軽減と診療の質向上に寄与しています。
加えて、人材育成や管理、システム運用といったバックオフィスでも、AIエージェントは反復業務や意思決定支援を自動化し、労働生産性を向上させる例が増えています。たとえば、ソニーはAIを用いた電子文書の自動分析・要約システムを導入し、情報共有の効率化と誤り低減を達成しています。
このように、多くの企業がAIエージェントの導入と活用を進めることで、業務効率化やコスト削減、顧客満足の向上といった具体的な成果を出し始めています。これらの事例から、2025年においても産業横断的にAIエージェントを活用することで、新たな競争力を獲得し続ける企業が着実に増加していくことが予測されます。
---
### 参考資料
1. サイバーエージェント公式ブログ(2024)「生成AIの進化と未来戦略」
https://developers.cyberagent.co.jp/blog/archives/55940/
2. Salesforce Japan(2024)「製造業のAI活用事例・サービス28選」
https://n-v-l.co/blog/manufacturing-ai-use-cases
3. Salesforce Japan(2024)「製造業のAI導入・活用事例・サービス10選」
https://www.salesforce.com/jp/blog/jp-manufacturing-ai/
4. 日本経済新聞(2024)「企業のAI導入事例と効果」
https://www.nikkei.com/
5. ThinkIT(2024)「AIエージェント最新動向と事例分析」
https://thinkit.co.jp/
---
## エージェント開発と導入の課題
生成AIの進展により、企業や社会全体でAIエージェントの導入が加速していますが、その導入にはさまざまな課題が伴います。技術的側面では、データの品質と量の確保が重要であり、学習データに偏りがあると公平性や正確性に問題が生じる危険性があります。例えば、偏ったデータに基づく判断が差別や不公平な結果をもたらす可能性があり、これが社会的な信頼喪失につながる懸念もあります。
また、AIエージェントの動作の透明性・説明責任も大きな課題です。複雑なモデルや多層的な推論フレームワーク(例えば、ReActやChain-of-Thought、Tree-of-Thoughts)を使った場合、その判断過程を言語化し、誰もが理解できる状態にすることが求められます。これができないと、結果の信頼性や倫理的な責任の所在も曖昧になり、規制対応やリスク管理が困難となります。
さらに、セキュリティやプライバシーの観点でも課題が存在します。生成AIに機密情報や個人情報を入力した場合の情報漏洩リスク、悪意のあるプロンプト(プロンプトインジェクション)、ハルシネーション(誤情報生成)、ディープフェイクによる虚偽情報の拡散など、多層的な脅威が想定されます。これらに対しては、アクセス制御や暗号化、ログ管理、誤情報を排除するための継続的な検証といった対策が不可欠です。
一方、組織面では、AIリテラシーの不足や抵抗感により導入が遅れるケースもあります。従業員への教育や、段階的導入を進めることで、組織の理解と共創体制を育む必要があります。技術の進化を追いつつ、倫理・安全・ガバナンス体制を整備し、適切にリスクを管理することが、今後のAIエージェント導入の最大の課題といえるでしょう。
この課題を克服するためには、企業は既存の技術を適切に選択しつつ、規範やガイドラインに則った運用、組織内外の連携、教育を徹底する必要があります。これにより、AIエージェントの適切かつ安全な運用と、長期的な価値創出が実現できると考えられます。
## 必要なスキルと今後の人材戦略
2025年の生成AIエージェント社会においては、従来の知識・技術だけでなく、AIとの適切な対話や倫理観を備えた人材の育成が不可欠となる。具体的には、AIリテラシーと批判的思考、倫理観を備えるために、以下の習得方法と心構えを提案する。
まず、「AIリテラシー」として、生成AIの仕組みと限界を理解し、その出力を鵜呑みにせず検証する力を養うこと。プロンプト設計や情報の正確性判断を実践し、批判的思考を身につける必要がある。次に、「指示の出し方」については、具体的な指示や段階的な指示を工夫し、AIの能力を最大限引き出す練習を重ねることが重要だ。例えば、「役割を明示し、達成すべきステップを具体化したプロンプト」を作成する訓練を推奨する。
さらに、「批判的思考」と「倫理観」を育むために、AIの出力の偏りや誤情報を識別し、それに対処するトレーニングを行う。情報の出所や根拠を確認し、フェイクニュースや差別的表現のリスクについての理解を深めることが重要だ。また、倫理的観点では、「AIの使用目的や結果に対して責任を持つ」心構えを持ち、適正な指示や利用ルールの設定を心掛ける。
これらのスキル習得には、実践的なワークショップやプロンプトエンジニアリングの訓練、学習コミュニティへの参加を推奨する。また、AI時代の変化に応じて、継続的な学習や情報アップデートを常に心がけ、多様なシナリオに対応できる柔軟性を持つことも重要だ。倫理観と批判的思考を持ち、AIとの共創と責任ある利用を意識した人材戦略を推進していく必要がある。
このように、多面的なスキルとマインドセットを兼ね備えた人材こそが、2025年以降のAIエージェント社会の未来を牽引できる中心となるだろう。
## 参考資料
([1] AI基礎リテラシーと実践法: https://thefas.jp/thinking-methods/advance-question-w-generative-ai/)
([2] プロンプト戦略と活用例: https://note.com/ramiailab/n/nab4a73d37f60)
([3] 教育と倫理観の育成例: https://strchem.eng.hokudai.ac.jp/uncategorized/ai_1.html)
## 結論とまとめ
2025年に向けて、生成AIとAIエージェントは急速に進化し、社会やビジネスの基盤技術として不可欠な存在となる見込みです。生成AIは、ユーザー指示に応じてコンテンツを受動的に生成する一方で、AIエージェントは自律的に環境を認識し、複雑なタスクを自ら遂行します。この違いを理解し、それらを効果的に組み合わせることが、次世代の価値創造の鍵となるでしょう。
技術動向を見渡すと、多段階推論やマルチエージェント協調など、高度な推論能力と社会シミュレーションの実現が進行中です。しかし、説明性やプライバシー、倫理的リスクも伴い、これらの課題への適切な対応が求められます。組織ではAIリテラシーの向上やリスクマネジメントを徹底し、長期的な運用の安定性を確保すべきです。
今後は、エネルギー効率やリアルタイム処理を可能にする軽量モデルの普及により、AIエージェントは社会の多様な分野で自律的な意思決定役割を担います。一人ひとりの技術理解と倫理観の養成が、AIとの共創を円滑にし、持続可能な発展を促進します。
| 項目 | 現状 | 2025年の展望 | 重要ポイント |
|-----------------------|----------------------------|----------------------------------|------------------------------------------------|
| 推論・判断能力 | 多段階推論の基礎形成 | 高度な論理推論と計画実行 | 複雑な課題解決に対応できる自律性の向上 |
| 協調・社会適応性 | 単一エージェント中心 | マルチエージェント協調システム | 社会システムのシミュレーションと管理 |
| 透明性・説明性 | 一部に改善の動き | 説明性・責任範囲の明確化 | 信頼性と倫理性の担保 |
| 運用・実装課題 | データ偏り・セキュリティ | 高信頼性と安全性の確保 | 法規制やガバナンスの整備 |
今後のアクションとしては、技術革新と倫理基準を両立させつつ、リテラシー教育と規範整備を推進し、社会全体でのAIエージェント導入を加速させることが不可欠です。
GPT-4.1 (2025-04-14)
GPT-4.1での実行結果
# 生成AIのエージェントと今後の展望(2025年)
本レポートは、2025年における生成AIエージェントの技術的進化と社会実装の動向を明らかにし、その活用の現状と今後の展望を整理することを目的としています。生成AIエージェントは、単なる自動化や情報生成を超え、自律的な意思決定と行動が可能なAIへと急速に進化しています。こうした技術はビジネスや産業、日々の暮らしに大きな変革をもたらし、効率化のみならず新たな価値創出の源泉になりつつあります。
今、社会や企業は生成AIエージェントとの共存による新たな競争力強化や業務プロセスの革新、そして倫理・安全性といった課題への対応が求められています。本レポートでは、最新の実例や技術トレンド、社会的インパクトを具体的に分析し、2025年を展望する上で押さえるべきキーポイントを示していきます。
## 生成AIエージェントの定義と主要技術進化
生成AIエージェントとは、人間が与えた目標に対して、周囲の環境を自律的に認識・分析し、計画・実行までを自ら行うAIシステムです。従来のAIは与えられたデータによる予測や分類に特化していましたが、AIエージェントは得られた情報や状況の変化に応じて、主体的に意思決定し行動できる点が大きな違いです[1][2]。
その仕組みは「モデル」(主に大規模言語モデルやマルチモーダルモデル)、「ツール」(外部API連携やデータベース検索など)、そして「オーケストレーションレイヤー」から構成されます。エージェントは、ReAct(Reasoning and Acting)やChain-of-Thoughtといった推論フレームワークを使い、自己内省しながら複雑なタスクも分解しながら遂行できるのが特徴です[2][3]。これにより、単なる情報のやりとりだけではなく、システムや外部サービスと連携して自動的に業務を進めることも可能となっています。
また、AIエージェントはマルチモーダル技術の進化により、テキストだけでなく画像・音声・動画情報を組み合わせて理解・応答できるようになりました。たとえば、Google Gemini 2.0 Flashは、テキストと画像の両方を処理し、適切なアウトプットを生成します[2]。さらに、外部データベースやWeb検索を適時活用するRAG(検索拡張生成)技術なども導入され、より現実世界のタスクや判断にリアルタイムで対応できるようになっています[4]。
実業務では、MicrosoftのCopilot StudioやGoogle Agentspace、NECの自律型AIエージェント、Salesforce Agentforceなどの導入が進み始めています。これらは、カスタマーサポート自動化、社内の問い合わせ対応、専門タスク処理など、多様な職場で活用されており、生産性向上・コスト削減が期待されています[3][5]。
このように、2025年に向けて生成AIエージェントは「自律性」「マルチモーダル対応」「外部連携」の3つの進化を軸に、従来型AIから大きく発展し、多様な業務への実装が広がっています。
### Sources
[1] https://note.com/kakeyang/n/ne320e0c2b8c3
[2] https://aiperformer.jp/media/aiagent1
[3] https://ai-market.jp/technology/ai-agent/
[4] https://www.lightblue-tech.com/column/ai%E3%82%A8%E3%83%BC%E3%82%B8%E3%82%A7%E3%83%B3%E3%83%885%E3%81%A4%E3%81%AE%E7%A8%AE%E9%A1%9E%E3%82%92%E5%BE%B9%E5%BA%95%E8%A7%A3%E8%AA%AC%EF%BC%81%E5%B0%8E%E5%85%A5%E3%83%A1%E3%83%AA%E3%83%83/
[5] https://global.fujitsu/-/media/Project/Fujitsu/Fujitsu-HQ/technology/key-technologies/news/ta-ai-agent-innovation-20250328/ta-ai-agent-innovation-20250328-jp.pdf?rev=469155cc91854ef2b43cb02fd86e2cdb&hash=EBC098F2424B989D689224A366273BB8
## 2025年における生成AIエージェントの主な活用分野と実例
2025年、生成AIエージェントは多様な分野で活用が進み、ビジネス、産業、生活に大きな変化をもたらしています。特に企業現場では、AIエージェントが自律的に業務を実行することで、業務効率化や省人化が加速しています。
ビジネス分野では、営業支援やカスタマーサポートへの導入が進み、AIチャットボットやバーチャルアシスタントによる24時間対応が一般化しています。例えば、NTTデータは営業業務のAI自動化サービスを開始し、契約書作成や提案書準備などの事務作業をAIエージェントが自動実行することで、担当者はより付加価値の高い業務に集中できる環境を整えています。また、人事領域でも社内外の問い合わせ対応や面接日程調整などをAIが担い、人的コストの削減とスピードアップに寄与しています[1][2][3].
産業分野では、製造ラインや物流拠点での品質管理や異常検知にAIエージェントが積極的に使われています。ある製造業では、生産ラインの品質チェックをAIが自動化した結果、不良品の発見率を40%向上させ、人件費も大幅に抑制しました[4]。物流では、AIが倉庫の在庫管理や配送計画を自律的に最適化し、少人数での高効率運用が可能となっています[1][2][4]。
生活領域でも、スマートホームやパーソナルアシスタントとしてのAIエージェント導入が拡大しています。スケジュール管理やリマインダー設定、健康管理サポート、情報収集など、家庭や個人の生活を効率化する役割を果たしています[1][4]。
最新トレンドとして、複数のAIエージェントが連携して複雑な業務を処理するマルチエージェントシステムや、人それぞれに最適化されたパーソナライズAIも登場しています。これらの進展により、単なる効率化にとどまらず、ビジネスモデルや働き方自体の革新が期待されています[1][3][4]。
### Sources
[1] 【2025年最新】AIエージェントとは?仕組み・活用事例・導入メリットを徹底解説!: https://aidiot.jp/media/ai/post-7998/
[2] AIエージェントにできることとは?最新動向と企業での活用事例: https://markezine.jp/article/detail/48558
[3] 【業務効率化したい】エージェントとは?生成AIとの違いも解説: https://ai-front-trend.jp/ai-agent/
[4] AIエージェントによって変わる働き方 | DOORS DX - ブレインパッド: https://www.brainpad.co.jp/doors/contents/02_about-ai-agents_3/
## 社会・産業構造へのインパクトと課題
生成AIエージェントの登場は、社会や産業の構造に大きな変化をもたらしつつあります。AIエージェントは、従来の単純なAIツールと異なり、自律的に考え、判断し、行動できるのが特長です。これにより、業務プロセス全体の効率化やコスト削減が進み、企業の生産性や競争力は大幅に向上しています。例えば、24時間365日稼働する「デジタル労働力」として、反復的かつ複雑な業務をAIに任せることで、人間は創造的な業務や戦略立案に集中できるようになり、組織の役割分担や構造も大きく再編されています[4]。
業種による影響も顕著です。製造業では在庫管理や予防保全が、金融業では不正取引検知や投資分析が、IT開発ではコーディングの自動化が進み、高度な自律型AIによる業務の自動化が現実になりつつあります。この変化により、雇用は単純作業からAIの監督やデータ分析、AI活用戦略の立案へとシフトし、「エージェント・プロダクトマネージャー」や「AI倫理担当」など新しい職種も誕生しています[5]。
一方で、AIエージェントの普及は新たな課題も生み出しています。第一に、プライバシーやセキュリティの問題があります。AIエージェントは大量のデータを収集・処理するため、個人情報の流出や悪用、外部からの攻撃リスクが高まります。また、AIによる意思決定の根拠が不透明となりやすく、説明責任やガバナンス体制の整備が求められています[1][2][3]。
さらに、学習データの偏りやシステム設計の不備による倫理的課題、AIの判断ミスに対する責任の所在なども明確になっていません。公平性や透明性の担保、AIエージェントの挙動の継続的な監査・評価も重要なテーマです。
今後は、段階的な導入と人間中心のガバナンス、XAI(説明可能なAI)の導入、データ品質とセキュリティ確保、新しい人材育成が急務とされます。企業や組織は、AIと人間の最適な協働による新しい働き方や競争力の確立を目指しつつ、リスクの制御と社会的信頼の獲得に向けた不断の努力が必要です。
### Sources
[1] 2025年の戦略的テクノロジのトップ・トレンド - ガートナージャパン: https://www.gartner.co.jp/ja/articles/top-technology-trends-2025
[2] AIエージェントとは?生成AIとの違いやメリット、活用事例を紹介: https://www.nextech-week.jp/hub/ja-jp/blog/article_10.html
[3] PHYSICAL AI(フィジカルAI)とは?次世代のAI技術を徹底解説: https://arpable.com/artificial-inteligence/physical-ai-overview/
[4] デジタル労働力がどのように企業を変革するか - Salesforce: https://www.salesforce.com/jp/news/stories/agentic-ai-reshapes-workforce/
[5] 2025年AIエージェント元年:ビジネスと社会の大転換点 - Zenn: https://zenn.dev/acntechjp/articles/20250405_ai_agent_era
## 今後の展望と成功に向けたポイント
生成AIエージェントは2025年に向けて、企業や社会の在り方を大きく変化させると予測されています。近年、自律的なAIエージェントは従来の「指示待ち型」AIから進化し、状況を自ら把握し、目標達成に向けて計画・実行・最適化を繰り返す存在となっています。特に複数のAIエージェント同士が協力し、マルチエージェントシステムとして高度な課題解決やイノベーション創出を実現する動きが進展しています。これにより、業務効率化やプロセス自動化を超えて、企業の競争力強化や新規市場開拓が加速することが期待されます[1][5]。
今後の発展シナリオでは、AIエージェントの「ハイパーパーソナライゼーション」やIoT・ロボットとの連携によるエージェントエコノミーの拡大が鍵となります。例えば、オンラインショッピングや顧客サービスの場面で、AIエージェントが個人の趣味嗜好や状況に応じた選択・調整を自律的に実行し始めています。また、企業では複雑な業務やサプライチェーンの全体最適に向けて、複数のAIエージェントが連携し、リアルタイムの意思決定や運用の最適化が可能となります[1][3][5]。
成功に向けて企業や社会が取るべき戦略的アプローチとして、①AIエージェント導入による業務・プロセス改革、②データ統合とマルチエージェント連携、③AIガバナンスや説明可能なAI(XAI)の推進、④人材育成・組織文化の変革、が挙げられます。特に、全社的なデータ連携やクロスファンクショナルな組織体制の構築、倫理ガイドラインの策定と定着が重要です[2][4][5]。
未来の可能性と持続的成長のための留意点としては、アルゴリズムのバイアスや意思決定の透明性、プライバシー・セキュリティ対策、そして現場現実との乖離(イノベーションの「死の谷」)をいかに乗り越えるかが不可欠です。トップ層のリーダーシップ、現場からの成功体験の共有、そして倫理的運用への不断の努力が、持続的成長のカギとなるでしょう[3][4][5]。
### Sources
[1] AIエージェントが描く2025年の世界: https://global.fujitsu/ja-jp/technology/key-technologies/news/ta-ces2025-report-generative-ai-20250110
[2] コンサルティング業界におけるAI革命:2024年の実績と2025年への展望: https://note.com/ark_consulting/n/ncb46a78a6e31
[3] AIエージェント元年に展望する、産業と企業経営のディスラプティブな変化: https://www2.deloitte.com/jp/ja/blog/d-nnovation-perspectives/2025/generative-ai.html
[4] AIエージェント今後の展望:2025年に予測されるトレンドと社会への影響: https://blog.scuti.jp/ai-agents-future-prospects-trends-and-social-impact-in-2025/
[5] 【追加登壇決定】経済産業省 島田雄介氏など6名が登壇 国内初のAIエージェントカンファレンス「AI Agent Day 2025」: https://prtimes.jp/main/html/rd/p/000000006.000155740.html
## まとめ・分野別展望の可視化
生成AIエージェントは2025年を前に急速な技術進化と社会実装が進み、その自律性・マルチモーダル対応・外部連携力を発揮して、ビジネス、産業、生活の幅広い領域にインパクトを与えています。業務効率化や省人化、多様な分野での自動化は労働環境や役割分担を変革しつつあり、今後は複数エージェントの連携による高度な課題解決や、個人・組織に最適化されたサービス進化が加速する見通しです。一方で、倫理や透明性、セキュリティ面の課題対応も重要度を増してきています。今後の成功には、人間中心のガバナンスやAI活用体制整備、現場との連携が鍵となります。
### 主要分野別・生成AIエージェントの現状と展望(2025年)
| 分野 | 導入状況(2024年) | 2025年への展望 |
|--------------|--------------------------------------|--------------------------------------|
| ビジネス | 営業・サポート自動化が本格化 | パーソナライズ/24h体制・マルチエージェント連携拡大 |
| 産業 | 製造・物流で品質・在庫管理に活用 | サプライチェーン全体最適化・複雑業務の自律化 |
| 生活 | スマートホーム・個人アシスタント拡大 | より高度な生活最適化・健康/教育分野への浸透 |
| 社会・構造 | 職種転換、AI労働力台頭 | 新職種創出、制度・倫理ルール強化 |
今後は、AIエージェントとの協働体制強化や、データエコシステム・人材育成の推進、説明可能性やセキュリティの確保が重要です。各分野での実装効果の可視化と現場主導のイノベーションを次のステップとしていくべきでしょう。
GPT-4o-mini (2024-07-18)
GPT-4o-miniでの実行結果
# 生成AIのエージェントと今後の展望(2025年)
AIエージェントは、進化の最前線にある技術であり、私たちの生活やビジネス運営を根本から変える力を秘めています。特に、これらのエージェントは、独自に環境を認識し、自律的に意思決定を行う能力を持つため、企業の生産性や業務効率を飛躍的に向上させることが期待されています。本報告書では、AIエージェントの定義や機能、技術動向、業界別の利用例、さらには未来展望に至るまで、幅広く掘り下げていきます。
特に2025年に向けては、AIエージェントが大規模言語モデル(LLM)などの技術進化によって、より高度なタスクを自律的に処理できるようになる見込みです。この進化は、金融、医療、マーケティングなどの各業界で顧客体験やオペレーションの革新を促進し、私たちのビジネス環境を大きく変えるでしょう。報告書全体を通じて、AIエージェントがもたらす可能性と、それに伴う課題についての理解を深めることを目的としています。
## AIエージェントの定義と機能
AIエージェントは、タスクの実行、意思決定、行動を自律的に行うシステムです。この技術は、従来のAIアシスタントとは異なり、明示的な人間の指示を必要とせず、複雑なタスクを遂行する能力を持っています。AIエージェントは、少なくとも以下の3つの基本的な機能を備えています。
まず、**環境認識**があります。AIエージェントは、センサーやデータを通じて周囲を認識し、その情報を利用して自らの行動を調整します。これは、視覚センサーや音声センサー、さらにはデータベースからの情報収集を含む広範なデータ処理を可能にします【6†source】【7†source】。このように、AIエージェントは周囲の状況を理解し、適切な対処を行うことが求められます。
次に、AIエージェントは**自律的意思決定**の能力を持っています。彼らは、複数の選択肢を評価し、自らの目標に基づいて最適な意思決定を行います。これは、強化学習や確率的推論を用いた高度なアルゴリズムを利用することで実現されます【3†source】【8†source】。これにより、AIエージェントは経験から学び、将来的な判断の質を向上させるためのフィードバックループを構築します。
最後に、AIエージェントは**行動実行能力**を備えています。具体的には、設定された目標を達成するために複数のタスクを実行するためのフローを自ら設計でき、外部システムやAPIとの統合も行います。これにより、彼らは単なる作業支援ツールを超え、ビジネスプロセス全体を効率的に管理する力を持つようになります【1†source】【2†source】。
これらの機能を通じて、AIエージェントは、人間の知識やスキルの延長として働き、企業の運営や意思決定において重要な役割を果たす一歩先を行く存在となることが期待されています。
### Sources
[1] State of AI Agents in 2025: A Technical Analysis | by Carl Rannaberg: https://carlrannaberg.medium.com/state-of-ai-agents-in-2025-5f11444a5c78
[2] AI Agents: The Next Evolution in Enterprise Automation - RevGen: https://www.revgenpartners.com/insight-posts/ai-agents-the-next-evolution-in-enterprise-automation/
[3] AI Agents Explained: From Basic Automation to Autonomous Decision Making | Blott Studio: https://www.blott.studio/blog/post/ai-agents-explained-from-basic-automation-to-autonomous-decision-making
[4] Types of AI Agents: Definitions, Pros, Cons & Use Cases - AI21 Labs: https://www.ai21.com/blog/types-of-ai-agent/
[5] The Rise of AI Agents—Collaborative Intelligence - CyberArk: https://www.cyberark.com/resources/hybrid-and-multi-cloud-security/the-rise-of-ai-agents-collaborative-intelligence
## AIエージェントの技術動向
AIエージェントは、2025年に向けて重要な進化を遂げています。これらのエージェントは、プロジェクトを理解し、必要なツールを使って自律的にタスクを実行できる能力を持ち、より高度な生産性と効率性を約束しています。現在、AIエージェントは大規模言語モデル(LLM)によってパワーされており、これらの技術の進展がエージェントの機能や自律性を一段と向上させると期待されています【1】【2】。
2025年には、AIエージェントはより自立的に作業を行い、複雑な意思決定を最小限の人間の介入で行う能力が高まると見られています。これには、タスクの自動化や、複数のエージェントの協力が含まれます。例えば、あるエージェントがデータ分析を行い、別のエージェントがその結果をもとに戦略を提案するという協働の可能性があります。このようなマルチエージェントシステムは、特に業務の効率化に寄与します【3】【4】。
さらに、エージェントの技術的進化には、品質の向上や機能の多様性も伴っています。特に「マルチLLM AIエージェント」と呼ばれる新しいタイプのエージェントは、複数の大規模言語モデルを併用することで、タスクごとに最適なモデルを選び出し、より良い結果を出すことが可能になります。これにより、ビジネスの各種ニーズに対する柔軟性と適応性が向上し、日々の業務における負担が軽減されることが期待されています【5】【6】。
AI技術の進化は、この分野のさらなる発展を促進し、2025年には企業や個人がAIエージェントを用いた新しいワークフローの構築に取り組むことが見込まれています。従って、高度なAIエージェントの導入は、競争力を維持する上でも重要な要素になるでしょう【7】【8】。
### Sources
[1] AI Agents in 2025: Expectations vs. Reality | IBM: https://www.ibm.com/think/insights/ai-agents-2025-expectations-vs-reality
[2] AI Agents in 2025: A Comprehensive Review and Future Outlook: https://medium.com/@sahin.samia/current-trends-in-ai-agents-use-cases-and-the-future-ahead-1026c4d753fd
[3] Why Multi-LLM AI Agents Are the Smartest Investment for 2025: https://medium.com/@futurewithai/why-using-a-multi-llm-ai-agent-could-be-your-most-valuable-investment-in-2025-84a0fbb1049b
[4] AI in the workplace: A report for 2025 - McKinsey: https://www.mckinsey.com/capabilities/mckinsey-digital/our-insights/superagency-in-the-workplace-empowering-people-to-unlock-ais-full-potential-at-work
[5] What's NEXT in Marketing: From AI agents to beyond LLM-these are ...: https://marketech-apac.com/whats-next-in-marketing-from-ai-agents-to-beyond-llm-these-are-ai-marketing-trends-for-2025/
[6] AI Agents in 2025: A Comprehensive Review and Future Outlook: https://medium.com/@sahin.samia/current-trends-in-ai-agents-use-cases-and-the-future-ahead-1026c4d753fd
[7] AI in the workplace: A report for 2025 - McKinsey: https://www.mckinsey.com/capabilities/mckinsey-digital/our-insights/superagency-in-the-workplace-empowering-people-to-unlock-ais-full-potential-at-work
[8] AI Agents in 2025: Expectations vs. Reality | IBM: https://www.ibm.com/think/insights/ai-agents-2025-expectations-vs-reality
## 業界別のAIエージェントの利用例
現在、AIエージェントはさまざまな業界で実際に活用されており、特に金融、医療、マーケティングの分野で顕著な進展が見られます。これらのエージェントは、業務の効率性を向上させ、顧客体験を強化するために設計されています。
### 金融業界
金融業界では、AIエージェントが特に活用されています。例えば、JPモルガンのCOiNプラットフォームは、法的文書を迅速かつ正確に検査するためにAIを活用しています。これにより、従来数千時間かかっていた業務が数分で完了するようになりました[1]。さらに、AIは不正検知にも活用されており、取引パターンを分析することで、不正行為を即座に検出する能力があります。これにより、HSBCやバンク・オブ・アメリカなどの大手金融機関が、顧客に迅速な対応を提供しつつ、不正のリスクを大幅に削減しています[2][3]。
### 医療業界
医療業界でもAIエージェントの導入が進んでいます。たとえば、クリーブランドクリニックでは、AIエージェントが患者の予約管理を効率化し、フォローアップを自動化することで、36%の予約キャンセル率を減少させました[4]。さらに、AIは医療画像の解析においても用いられ、腫瘍や骨折の検出を人間よりも高い精度で行うことができることが示されています。これにより、早期診断を支援するだけでなく、医療提供者の負担を軽減しています[5][6]。
### マーケティング業界
マーケティングでは、AIエージェントがソーシャルメディアの自動化や顧客とのエンゲージメントに利用されています。例えば、Socialsonicという企業は、AIを活用してソーシャルメディア上でのコンテンツ作成やユーザーとのインタラクションを自動化し、エンゲージメントを45%向上させています[7]。AIが顧客の行動を分析することで、パーソナライズされたコミュニケーションを実現し、企業の売上増加にも寄与しています[8]。
これらの事例は、AIエージェントがさまざまな業界で重要な役割を果たし、業務効率を向上させるだけでなく、顧客体験を改善するための新たな手段を提供していることを示しています。
### Sources
[1] AI Agents Use Cases: 50+ Applications Transforming Industries - Markovate: https://markovate.com/ai-agents-use-cases/
[2] The Rise of AI Agents: A New Era in Healthcare Operations: https://www.thoughtful.ai/blog/the-rise-of-ai-agents-a-new-era-in-healthcare-operations
[3] 16 Real-World AI Agents Examples in 2025 - Aisera: https://aisera.com/blog/ai-agents-examples/
[4] How AI Agents Are Driving ROI: 5 Useful Case Studies from the Real World - Creole Studios: https://medium.com/@creolestudios/how-ai-agents-are-driving-roi-5-useful-case-studies-from-the-real-world-d6f0202edb5
[5] Top 10 AI Agents in Healthcare: Use Cases & Examples ['25]: https://research.aimultiple.com/ai-agents-in-healthcare/
[6] AI Agents for Sales Automation - Drift: https://www.drift.com/ai-agents-for-sales-automation/
[7] AI Agents in Healthcare: Use Cases & Examples ['25]: https://research.aimultiple.com/ai-agents-in-healthcare/
[8] AI Agents in Marketing: Driving Customer Engagement and Sales: https://www.socialsonic.com/ai-agents-in-marketing/
## AIエージェントの未来展望
2025年以降、AIエージェントはその自律性が高まり、より複雑なタスクを自己学習しながら管理する能力を持つようになると予測されています。これにより、AIエージェントは、バックエンドの業務から顧客対応まで、幅広い業務において効率を向上させる役割を果たすことが期待されています【1】。例えば、サプライチェーンの最適化や顧客サポートの自動化において、AIエージェントは迅速な意思決定を行い、ヒューマンタッチを維持するための戦略的な統合が求められます【2】【5】。
社会的・倫理的課題として、AIエージェントの導入に伴い、バイアスや公平性の問題、高いプライバシー基準、そしてデジタルディバイドの拡大が挙げられます。AIエージェントのデータに基づく意思決定は、元となるデータに依存するため、例えば歴史的なデータに由来するバイアスが存在する場合、不平等を助長するリスクがあります【5】。したがって、透明な意思決定プロセスやアルゴリズムの定期的な監査が求められます。
また、AIエージェントの普及により、労働市場における仕事の自動化が進む一方で、スキルの再教育と再配置が求められることになります。特に、業務自動化が進むことで、従来の仕事が消失する可能性があり、これに対処するためには教育制度がより柔軟に対応できるよう再構築される必要があります【4】【6】。
さらに、AIの倫理的な利用が求められるなか、責任ある開発指針が重要視されるでしょう。バイアス、透明性、そして説明可能なAI(XAI)の導入は、関係者の信頼を築くための鍵となります。法律や規制が進展することで、企業は倫理基準に基づいた製品を提供し、社会的価値を高めるために積極的な責任を果たすことが求められます【3】【7】。
2025年以降のAIエージェントの発展は、単に技術的進歩に留まらず、社会全体に与える影響を理解し、適切に管理することが求められます。これにより、AIと人間の協力による新しい創造的な可能性が開かれるでしょう。
### Sources
[1] AI Agents in 2025: A Comprehensive Review and Future Outlook: https://medium.com/@sahin.samia/current-trends-in-ai-agents-use-cases-and-the-future-ahead-1026c4d753fd
[2] AI Trends Report 2025: All 16 Trends at a Glance - Statworx: https://www.statworx.com/en/content-hub/blog/ai-trends-report-2025
[3] Predictions for AI in 2025 | Key Trends and Innovations - Saiwa: https://saiwa.ai/blog/predictions-for-ai-in-2025/
[4] AI Agents and Digital Labor: Ethical and Social Implications - LinkedIn: https://www.linkedin.com/pulse/ai-agents-digital-labor-ethical-social-implications-pipelinercrm-gqhhc
[5] Top AI Trends for 2025: Unlocking the Potential of AI to Drive Memorable and Meaningful Experiences: https://www.newmetrics.net/insights/top-ai-trends-for-2025-unlocking-the-potential-of-ai-to-drive-memorable-and-meaningful-experiences/
[6] AI and Job Displacement: The Automation Debate: https://saiwa.ai/blog/predictions-for-ai-in-2025/
[7] Responsible AI: Ethics and Transparency Take Center Stage: https://www.newmetrics.net/insights/top-ai-trends-for-2025-unlocking-the-potential-of-ai-to-drive-memorable-and-meaningful-experiences/
## 結論
AIエージェントは、2025年に向けて飛躍的な進化を遂げると予測されています。これまでに述べたように、これらのエージェントは環境認識、自律的意思決定、行動実行能力を駆使し、さまざまな業界での業務効率化と顧客体験の向上に貢献しています。また、大規模言語モデル(LLM)の発展により、AIエージェントはますます自立的にタスクを処理できる能力を身につけ、マルチエージェントシステムが実用化されることで、更なる協働の可能性が広がります。
以下の表は、AIエージェントの機能と技術動向、業界別の応用をまとめたものです。
| 項目 | 説明 |
|----------------|----------------------------------------|
| 環境認識 | センサーを通じて周囲の情報を収集し、行動を調整する能力 |
| 自律的意思決定 | 複数の選択肢を評価し、最適な判断を行う能力 |
| 行動実行能力 | 複数タスクの実行フローを自律的に設計できる能力 |
| 技術進化 | マルチLLM、自己学習機能の進化 |
| 業界適用例 | 金融、医療、マーケティングでの業務効率化 |
これらの発展は、企業が競争力を維持する上で重要な要素となるでしょう。しかし、AIエージェントの導入に伴い、バイアスや倫理面での課題も浮上しています。仕事の自動化が進むことで、労働市場に影響を及ぼし、スキルの再教育が求められます。
次なるステップは、透明性の確保や倫理基準の強化を進めることです。これにより、AIエージェントの利点を最大限に引き出し、社会全体における信頼を確立することが求められます。
GPT-4o (2024-11-20)
GPT-4oでの実行結果
# 生成AIのエージェントと今後の展望(2025年)
生成AIエージェントは、技術革新と社会の変化が交差する中、新たな地平を切り拓く存在として注目されています。本報告書では、この急速に進化を遂げる生成AIエージェントの技術的進歩や現時点での応用事例を概観するとともに、さらなる発展が予想される2025年以降に焦点を当て、未来の可能性と課題について議論します。
AI技術の急速な発展により、生成AIエージェントは単なるツールから自律的な課題解決を担う存在へと変貌しています。その能力は業務効率化や顧客体験の向上にとどまらず、医療や製造などの複雑な分野にまで浸透しつつあります。一方で、社会的・倫理的な課題も浮き彫りになっており、慎重な対応が求められています。この背景を理解し、次世代社会の形成に向けた洞察を得るために、本報告書は欠かせない指針となるでしょう。
## 生成AIエージェントの進化と技術的背景
生成AIエージェントは、急速に進化している技術の一つです。これらのエージェントは、環境を認識し、その状況に応じた適切な判断を自律的に行い、タスクを遂行できる特徴を持っています。この進化の背景には、大規模言語モデル(LLM)や強化学習を中心としたAI技術の急速な発展があります。
2024年から話題が活性化した生成AIエージェントは、従来の質問応答や単純な作業を超え、複雑なタスクの自律的な処理まで対応可能になっています。特に複数のAIエージェントが役割を分担しながら協調して作業を進める「マルチエージェント」技術の普及は注目に値します。この技術は、ソフトウェア開発におけるテストやデバッグ、多言語翻訳プロジェクトなど、人間のチームによる協力が必要だった領域に新たな可能性をもたらしています。また、GUIを直接操作できる「GUIエージェント」の登場により、ウェブブラウザやアプリの画面操作も自然言語の指示で簡単に行えるようになりました。これにより、API調整が不要で、多様なアプリケーションへの柔軟な対応が実現しています。[1][2]
さらに、AIエージェントはシミュレーション技術にも応用されています。複数のエージェントで構成された社会的な相互作用を模倣することで、人間同士の行動や市場動向の予測、都市計画など、さまざまな応用が進んでいます。この技術にはエージェント間の記憶と適応性が重要視されており、高度なシミュレーションを可能にしています。[3][4]
技術の進化による生成AIエージェントの能力向上には課題もあります。たとえば、性能評価方法の標準化が進んでおらず、タスク遂行の精度や過程を測定する新たな手法が求められています。2024年に登場した「Agent-as-a-Judge」や「MMAU」などの評価手法は、段階的なタスク評価や発展的な能力分析を可能にし、従来の課題を克服する可能性を秘めています。[5]
これらの進展は、生成AIエージェントが各産業や社会において多様な役割を果たす時代の到来を示しており、2025年以降もさらなる進化が期待されています。
### Sources
[1] AIエージェント技術最新トレンド:https://www.brainpad.co.jp/doors/contents/ai_agent_trend/
[2] 生成AI業務活用の2025年を予測:https://xtech.nikkei.com/atcl/nxt/column/18/03054/122500004/
[3] AIエージェントの未来:https://www.salesforce.com/jp/news/stories/ai-agents-trends-2025/
[4] 2025年はAIエージェント元年:https://www.powerweb.co.jp/knowledge/columnlist/gen_ai_agent_deepresearch/
[5] 【2025年最新】生成AIの今後の展望:https://shift-ai.co.jp/blog/6505/
## 生成AIエージェントの具体的な適用分野
生成AIエージェントは、多様な分野で活用されており、業務効率化や意思決定の支援、顧客体験の向上などを実現しています。以下に、代表的な実例を示しながら、具体的な適用分野をご紹介します。
### 1. 業務効率化とコスト削減
生成AIエージェントは、定型的業務の自動化に寄与し、効率化とコスト削減を実現しています。例えば、メールや書類整理の自動化、問い合わせの一次対応、企業内のデータ要約ツールなど、多くの企業が導入を進めています。三菱商事ではAzure OpenAI Serviceを活用し、投資判断を効率化する文章要約ツールやチャットを導入しています[1][2]。
### 2. 顧客体験の向上
顧客対応の迅速化やパーソナライズ化を通じて満足度を向上させる事例も増加しています。例えば、富士通はSalesforceのAIエージェントを導入し、顧客対応の効率化を図る同時に、15%の問い合わせを自動化する実績を上げています[2][3]。
### 3. 医療現場での活用
生成AIエージェントは医療画像診断支援や症状の分析・提案を通じて医療分野でも利用されています。高精度で大量のデータを処理し、医師の診断を補助することで、医療サービス全体の質向上に貢献しています[3][4]。
### 4. ソフトウェア開発の支援
AIエージェントはソフトウェア開発やテスト工程を効率化します。コードレビューやバグ検出、仕様書の生成支援などの領域で、企業の開発スピード向上に役立っています。トヨタ自動車では、熟練エンジニアの知識を生成AIで伝承するシステムを導入し、次世代技術の開発スピード向上を実現しています[2][4].
### 5. 製造・物流分野の最適化
AIエージェントは需要予測を活用して在庫管理や配送の効率化、画像認識による品質管理などを支援します。この技術により「スマートファクトリー」の進化が加速しています[2][5]。
生成AIエージェントの活用は、産業や業務の垣根を越えて広がり続けています。これらの事例は、生成AIエージェントが単なる効率化ツールではなく、業務革新や付加価値創出において重要な役割を担う技術であることを示しています。
### Sources
[1] お客様と ISV の生成 AI 成功事例 | Google Cloud 公式ブログ: https://cloud.google.com/blog/ja/topics/partners/real-world-examples-of-how-customers-are-innovating-with-gen-ai/
[2] AI エージェントで実現する業務効率化とイノベーション | Microsoft公式: https://news.microsoft.com/ja-jp/2024/12/18/241218-operational-efficiency-and-innovation-enabled-by-ai-agents-latest-case-studies-from-japan/
[3] AIエージェントの活用事例13選 | alt: https://alt.ai/aiprojects/blog/gpt_blog-8942/
[4] 36 AIエージェントの実例 | Botpress: https://botpress.com/ja/blog/real-world-applications-of-ai-agents
[5] AIエージェント5つの種類を徹底解説 | Lightblue: https://www.lightblue-tech.com/column/aiagent-commentary/
## 今後の生成AIエージェントの課題と展望
生成AIエージェントは、技術進化とともに多様な課題を抱えていますが、それ以上に未来への可能性を秘めています。まず課題として、生成AIエージェントの自律性が増すことで、予期せぬ結果や社会的・倫理的影響が懸念されています。例えば、データの偏りや透明性の欠如により、不正確な意思決定が行われるリスクがあります。また、高度な自律性がシステムダウンやセキュリティ問題を引き起こす可能性も指摘されています。これらの問題は、説明可能なAI(Explainable AI)の導入や、用途に応じた自律性制限を検討するなど識別可能かつ規制可能な解決策の早急な導入が必要です[1][2][3][4]。
一方で、生成AIエージェントは数多くの分野でその力を発揮する未来が期待されています。2025年には、AIエージェントが「自律的な課題解決」能力をさらに強化し、人間の手を離れた領域で独自の戦略立案・遂行が可能となると予想されます。実績としては、AIエージェントが金融サービスの効率化からリスク管理までを担うほか、物流管理や製造現場でも複雑なタスクをこなす事例が報告されています[3][4][5]。さらに、VR空間で人間が探索できる3Dモデルの生成やマルチエージェントシステムによる複数AIの協働など、社会の構造やコンテンツ制作に革新をもたらす可能性があります[2][6]。
今後、人間とAIエージェントの共生を成功させる鍵は、「倫理的枠組みの構築」と「価値基準の設定」にあります。AIが持つ自律性を監視しつつ、人間と協力する新しい形式の創造的なタスクが増えることが期待されます。これにより、生成AIエージェントは課題解決のパートナーとしてだけでなく、未来の社会を形成する重要な存在となるでしょう[4][6].
### Sources
[1] Source: 2025年AIトレンド4選|注目のAI技術と社会への影響: https://atarayo.co.jp/method/ai-2025-trend/
[2] Source: BM25も立派なAI?最新Deep Researchまでの技術進化を追う: https://zenn.dev/chips0711/articles/bfd887b18b3954
[3] Source: 2025年の「AI」はこうなる−さらに進化するAI世界の展望: https://weekly-economist.mainichi.jp/articles/20241227/se1/00m/020/001000d
[4] Source: AIエージェントが描く2025年の世界: https://global.fujitsu/ja-jp/technology/key-technologies/news/ta-ces2025-report-generative-ai-20250110
[5] Source: AIエージェント時代と金融サービスの未来変革: https://global.fujitsu/ja-jp/insight/tl-aiagents-financial-industry-20250418
[6] Source: DeepSeekの衝撃! 低価格で高性能AIを実現できた理由: https://www.microsoft.com/en-us/microsoft-365/blog/2025/03/25/introducing-researcher-and-analyst-in-microsoft-365-copilot/
## 結論
生成AIエージェントの進化は、技術的背景、具体的な適用分野、そして今後の課題と展望によって多角的にその重要性を示しています。技術的には、大規模言語モデルや強化学習の発展に支えられ、「マルチエージェント」や「GUIエージェント」といった新しい形態が多くの産業に革新をもたらしました。実際の適用例としては、業務効率化、顧客対応の最適化、医療支援、ソフトウェア開発、物流管理など、幅広い分野で成果を挙げ、人間の負担を軽減する役割を果たしています。一方で、課題としては倫理的配慮、自律性の管理、公平なデータ構造の構築が指摘されており、これらへの対応が今後の発展の鍵です。
以下は生成AIエージェントの特徴と課題を比較した表です:
| **項目** | **特徴** | **課題** |
|---------------------------|--------------------------------------------------------------------------|------------------------------------------------------------------------------|
| **技術的進化** | マルチエージェント、GUIエージェントによる多様な適応 | 性能評価の標準化が未整備 |
| **適用分野** | 業務効率化、医療支援、製造・物流、多言語翻訳など | 社会的・倫理的影響への懸念 |
| **未来の可能性** | 自律的課題解決能力、人間との協働、新たなコンテンツ制作の助力 | 自律性の管理、説明可能なAI技術の導入 |
2025年以降、生成AIエージェントは人間の創造性や意思決定プロセスを補助する「パートナー」の役割をさらに拡張すると予測されます。そのため、技術進化の方向性を見極めると同時に、社会的規範や倫理的枠組みを積極的に形成する必要があります。これにより、生成AIエージェントは人類の課題解決における不可欠な原動力となるでしょう。
o3-mini (2025-01-31)
o3-miniでの実行結果
# 生成AIのエージェントと今後の展望(2025年)
本レポートでは、生成AIのエージェントがどのように技術革新を推進し、産業や私たちの日常生活に変革をもたらすかについて探求します。2025年に向けて、エージェント技術は高度な自律性と適応性を発揮し、意思決定プロセスやクリエイティブな応用領域での可能性を広げつつあります。
読者は、このレポートを通じて生成AIエージェントの基本的な概念と、今後の進化がもたらす革新的な展望について理解を深めることができます。具体的な事例や最新技術の動向を交えながら、エージェント技術が未来のデジタル社会において果たす役割について明確に示すことを目指します。
## 生成AIの概要と進化の背景
生成AIは、大量のデータから学習し、新たなコンテンツを自動的に生成する技術です。この技術は、画像、音声、テキストなど幅広いメディアに対応できるため、クリエイティブな分野やビジネス用途において急速に重要視されています。基本となる考え方は、学習した既存のパターンや情報を元に、独自のアウトプットを生み出すことであり、近年はその精度と実用性が大幅に向上しています。これにより、生成AIは対話型エージェント、デジタルアシスタント、シミュレーション、広告・マーケティング、さらにはデザイン分野など、さまざまな領域における革新的なユースケースを生み出しています。
一方で、生成AIの進化は、深層学習アルゴリズムの改良や計算資源の向上、大規模データセットの利用拡大といった技術的要因によって加速されており、エージェントとしての機能統合にも寄与しています。具体的には、自然言語処理や強化学習の融合により、より状況に即した判断や自律的なタスク遂行が実現されるようになりました。以下の表は、生成AIの基本概念、主要ユースケース、及び技術進化の背景を簡潔にまとめたものです。
| 項目 | 説明 |
| -------------- | ------------------------------------------------------------ |
| 基本概念 | 大量データから学習し、画像・音声・テキスト等の新規コンテンツを生成 |
| 主要ユースケース | 対話型エージェント、デジタルアシスタント、クリエイティブデザイン支援等 |
| 技術進化の背景 | 深層学習アルゴリズムの進化、ハードウェアの高速化、大規模データの活用 |
今後の展開として、生成AIはさらなる技術革新とともに、その応用範囲の拡大、倫理的・法的課題の整理、及び実環境での信頼性向上が求められます。これにより、より高度なエージェントシステムの実現が期待されます。
## AIエージェントの基本概念と技術的仕組み
本セクションでは、AIエージェントの定義とその動作メカニズム、及びデータ収集から意思決定・行動に至るプロセスについて具体的に解説する。AIエージェントは、環境から膨大なデータを継続的に収集・処理し、ニューラルネットワークや各種アルゴリズムを駆使して高度な意思決定を行う自律型システムである。エージェントは、ユーザーのニーズや環境変化に迅速に対応するため、ルールベースと機械学習手法を組み合わせたハイブリッドアプローチを採用する。内部動作としては、まずセンサーや外部データソースを通じたデータ収集が行われ、次に前処理やフィーチャーエンジニアリングによりデータが最適化される。そして、ディープラーニングや強化学習を用いて状況認識が行われ、最終的にエージェントは得られた情報に基づく適切なアクションを選択・実行する。
エージェントのプロセスを以下の項目で概観する:
* データ収集と前処理
* モデル構築と学習
* 状況認識と意思決定
* 行動実行とフィードバックループ
これらの段階は相互に連携し、継続的な改善と最適化を可能にする。今後は、これらの技術基盤をさらに発展させることで、より高度な応答性と柔軟性を持つエージェントの実現が期待される。具体的な次のステップとして、実環境での実証実験や倫理面・安全性の評価を強化し、技術的成熟度を高める取り組みが求められる。
## 2025年に見込まれる生成AIエージェントの進化トレンド
生成AIエージェントは、今後数年で大きな転換期を迎えると予測される。2025年に向け、従来の単一タスク中心のアプローチから、複数の情報を統合し、より動的な対応が可能なシステムへと変化する見込みである。特に注目すべきは、マルチモーダル対応の進展で、テキスト、画像、音声などの多様なデータを同時に処理できるようになる。これにより、ユーザーインターフェースが革新され、現実世界での応用範囲が拡大することが予想される。
また、信頼性の向上は、ユーザーの安全性やシステムの安定運用に直結する重要な要素である。新たなエラー検出・修正アルゴリズム、さらには高度な解釈可能性の導入により、生成AIエージェントは従来以上に安心して利用できるプラットフォームへと進化する。また、マルチエージェントシステムの進展も見逃せない。複数のエージェントが協調し、タスクを分担・連携することで、複雑な問題解決が迅速かつ効率的に行われるようになる。こうした発展は、業界横断的な応用の拡大を意味し、ビジネスプロセスの最適化や自動化の加速につながる。
以下は各進展要素の要点である:
- マルチモーダル対応:多様なデータ統合と新たなユーザー体験の提供
- 信頼性向上:エラー低減、解釈可能性強化、安全性の向上
- マルチエージェントシステム:協調的タスク管理と効率化
今後の課題としては、倫理的観点やセキュリティの確保、インフラ整備が挙げられる。これらの点を踏まえ、技術開発と実装プロセスの両面での取り組みが、生成AIエージェントの持続可能な発展に向けた次の一歩となるだろう。
## 業務活用事例と実装詳細
生成AIエージェントは多岐にわたる業務プロセスの効率化に貢献しています。企業内では、カスタマーサポート、マーケティング、データ分析、さらにはHRなど各分野で導入が進んでおり、具体的な実装手法としてはAPI連携、セキュアなクラウド環境での運用、さらには既存システムとの統合が挙げられます。たとえば、カスタマーサポートの分野では、チャットボットがリアルタイムで顧客対応を行い、応答時間の短縮と問い合わせ内容の自動分類が実現されています。また、マーケティングチームでは、生成AIを用いたコンテンツ作成やキャンペーンのパーソナライズの実装が見られ、更なる顧客エンゲージメントの向上につながっています。さらに、社内データの分析や整理においても、生成AIエージェントはビッグデータの管理・解析に貢献し、迅速な意思決定をサポートしています。
下記の表は、各活用事例における実装の特徴と効果を簡潔に整理したものです。
| 活用事例 | 実装詳細 | 導入効果 |
|-----------------------|----------------------------------------|--------------------------------------------|
| カスタマーサポート | チャットボットAPI、問い合わせ自動分類 | 応答時間短縮、顧客満足度向上 |
| マーケティング | コンテンツ生成ツール、パーソナライズ戦略 | エンゲージメント増加、ターゲットマーケティングの精緻化 |
| データ分析 | クラウド統合、ビッグデータ解析ツール | 意思決定の迅速化、業務プロセスの最適化 |
| HR | 自動履歴書解析、面接自動スケジューリング | 採用効率の改善、人的リソースの最適配置 |
今後のステップとしては、各企業は自社の業務プロセスに沿ったカスタマイズとパイロット導入を進め、実運用フェーズでの調整や効果測定を重点的に実施することが求められます。さらに、セキュリティ対策と運用の透明性確保を念頭に、生成AIエージェントの持続可能な活用が今後の競争力強化に直結することが示唆されます。
## 課題とリスク管理
生成AIエージェントの普及により、倫理的な課題、セキュリティリスク、そして仕事環境の大幅な変革といった複数の懸念が顕在化している。まず、倫理問題として、アルゴリズムの偏りが生む不公正な判断やプライバシーの侵害、無意識のバイアスの問題が取り上げられる。これに対しては、透明性の向上や厳格な倫理規範の策定が急務であり、利用者や関係者間での合意形成が求められる。
同時に、セキュリティリスクは、誤用や悪意のある攻撃に対して脆弱である点が挙げられる。情報漏洩やサイバー攻撃、システムの悪用を未然に防ぐため、リアルタイム監視システムの導入、強化された認証プロセスが必要である。また、AIシステム自体の信頼性を確保するために、定期的な脆弱性評価と対策のアップデートが不可欠である。
さらに、生成AIエージェントの導入は、従来の業務プロセスや職務内容に大きな変革をもたらす。これにより、業務の自動化と効率化が期待される一方、職務の再編成や労働市場における再教育の必要性が生じる。以下のポイントが今後の焦点となる:
- 倫理ガイドラインの策定と運用
- セキュリティ対策の強化とモニタリング体制の整備
- 産業全体の再教育プログラムとキャリア支援
今後は、各方面のステークホルダーが連携し、リスク管理と課題解決に向けた具体策の実装を加速する必要がある。これにより、持続可能な生成AIエージェント利用の基盤が確立されることが期待される。
## 結論
本報告では、生成AIエージェントの現状と、その2025年に向けた展望について検討してきました。技術的進歩、産業応用の拡大、倫理的配慮、法制度の整備など多岐にわたる観点から、生成AIエージェントはこれまで単にツールとしての役割に留まらず、企業や社会全体に対して新たな価値を提供する存在へと変貌しています。今後は、技術革新とともに、ユーザーデータのプライバシー保護やバイアス低減など倫理的・法的課題にも体系的な対応が求められることは明白です。また、業界各社によるコラボレーションやオープンイノベーションの推進は、AIエージェントの質を向上させる鍵として位置づけられます。
以下は本報告の主要なポイントをまとめたものです:
- 技術進化:生成AIエージェントのアルゴリズムは急速に進化しており、リアルタイムの対話や複雑なタスク処理が可能となっている。
- 応用領域の拡大:医療、教育、カスタマーサポートなど多様な業界での応用が進み、業務効率化やサービス向上に寄与している。
- 倫理と法規制:プライバシー保護、バイアス制御、透明性の確保が社会的合意形成の一環として重要視されている。
- 未来への展望:生成AIエージェントは今後も進化を続けるとともに、産業の枠組みを再定義し、新たな経済圏の形成に貢献する可能性が高い。
次のステップとして、企業や研究機関はエージェント技術の高度化とともに、倫理的・法的な枠組みの整備を進め、持続可能なイノベーションの実現に向けた取り組みを強化する必要があります。
o4-mini (2025-04-16)
o4-miniでの実行結果
# 生成AIのエージェントと今後の展望(2025年)
生成AIはテキストや画像などのコンテンツを自動生成する力で注目を集めてきましたが、指示待ちの「受動的」役割にとどまる従来型モデルには限界があります。そこで、目標達成のために自律的に計画・判断・行動するAIエージェントが企業現場における次世代インフラとして浮上しつつあります。業務自動化や複数ツール連携を通じ、より高い生産性と柔軟性を実現する点が最大の強みです。
本レポートでは、生成AIエージェントの基本概念から最新市場動向、主要業界の導入事例、技術・組織面の課題と成功パターン、さらには2025年以降に求められる戦略的ロードマップまでを一貫して論じ、自社での実践に向けた具体的指針を示します。
## 生成AIエージェントの基礎概念
生成AIとは、学習データに基づきテキストや画像、音声などの新たなコンテンツを自動生成する技術です。代表例として、ChatGPTやDALL·Eがあり、ユーザーの指示に合わせて多様なアウトプットを作成します[2].
一方、AIエージェントは人間が設定した目標を達成するために、自律的に計画・意思決定し、必要なアクションを実行するシステムです。目標に応じて環境からデータを取得し、複数のタスクを組み合わせて処理を進めます[1].
生成AIはコンテンツ生成に特化していますが、AIエージェントはその生成能力を内包しつつ、行動計画の立案や外部システムとの連携なども行います。多くのAIエージェントは内部で生成AIを活用し、対話やレポート作成などを行いながら自律的に次のステップを判断します[2].
両者の最大の違いは「自律性」の有無です。生成AIはユーザーの指示に従って応答する受動的な役割に留まりますが、AIエージェントは与えられた目標に対して必要なタスクを能動的に選択し実行します[3]. 例えば、スケジュールを管理する生成AIは依頼に応じて予定表を作るだけですが、AIエージェントは利用者のカレンダーを監視し、適切なタイミングでリマインドや調整を提案します.
さらに、適用範囲にも違いがあります。生成AIは資料作成やクリエイティブ制作などの一連のコンテンツ生成業務に強みがあり、AIエージェントは業務プロセスの自動化や意思決定支援、顧客対応の自律化など広範なビジネス領域で活用されます[3]. これらの特性を理解し、業務に合わせて使い分けることで生産性向上や新たな価値創出が可能となります.
### Sources
[1] AIエージェントとは?生成AIとの違いや課題、今後の展望 - Rikkeisoft: https://rikkeisoft.com/ja/blog-2/what-is-agentic-ai/
[2] 業界×AIエージェントの活用方法: 2025年最新動向 - Zenn: https://zenn.dev/acntechjp/articles/20250402_industry_ai_agents
[3] 生成AIとAIエージェントの違いとは?3つの顧客接点における活用例 - CBA: https://blog.cba-japan.com/what-is-the-difference-between-generative-ai-and-ai-agents/
## 2025年時点におけるAIエージェント技術の現状
生成AI市場は成熟期を迎え、多様な業務を自律的に実行する「AIエージェント」への関心が高まっています。特に、大手クラウド事業者がフルマネージドなエージェントサービスを相次いで投入し、企業の導入ハードルが低下しました[2]。
AIエージェントは、情報検索から業務自動化までを一連のフローとして実行できる点が特徴です。従来のチャット型AIが「一度に一つの推論」を行うのに対し、エージェントは外部ツール連携やマルチステップ処理を通じて、複数段階の複雑な推論を自律実行します[3]。
市場では目的や機能別に生成AIサービスが5つのカテゴリに分類されています。うち「AIエージェント(特化型)」カテゴリには、Copilot Studio(Microsoft)、Manus(Monica)、Clineなどが含まれ、業務フローの自動化や開発支援を担います。また、チャット系AI(ChatGPT、Claude、Google Gemini、M365 Copilot)、AI検索(Perplexity、Genspark)、スライド作成(Canva AI、Gamma)、コード生成(GitHub Copilot、Cursor、Devin)といった多彩なサービスが並行して発展しています[1]。
主要なプラットフォームとしては、AWSのAmazon Bedrock Agents、AzureのAzure AI Agent Service、Google CloudのVertex AI Playbooksが挙げられます。これらはいずれもマルチエージェント構成、外部データ検索、会話履歴管理などをサポートし、開発者はローコードやAPI連携で自社用途に合わせたエージェントを構築可能です[2]。
2025年時点では、AIエージェント技術は「自律性」「拡張性」「対話性」を強みとし、金融や製造、カスタマーサポートなど幅広い業務領域での活用が進んでいます。今後はRAG(Retrieval‑Augmented Generation)との連携やセキュリティ強化を通じ、信頼性と安全性を担保しつつさらなる市場拡大が期待されます。
### Sources
[1] 【2025年最新】生成AIおすすめサービスは?活用事例・選び方まで実際に使った専門家が徹底解説: https://www.ai-souken.com/article/recommend-ai-services
[2] 生成AIのAIエージェントを大手3社(AWS、Azure、Google Cloud)で徹底比較してみた: https://blog.g-gen.co.jp/entry/comparing-agent-architecture-across-cloud-vendors
[3] AIエージェント5つの種類を徹底解説!導入メリットや事例を紹介: https://www.lightblue-tech.com/column/ai%E3%82%A8%E3%83%BC%E3%82%B8%E3%82%A7%E3%83%B3%E3%83%885%E3%81%A4%E3%81%AE%E7%A8%AE%E9%A1%9E%E3%82%92%E5%BE%B9%E5%BA%95%E8%A7%A3%E8%AA%AC%EF%BC%81%E5%B0%8E%E5%85%A5%E3%83%A1%E3%83%AA%E3%83%83/
## 業界別活用事例と得られる効果
この節では製造、金融、小売、医療業界における生成AIエージェントの導入事例を示し、具体的な成果と定量効果を解説します。各業界の代表例を通して、AI導入による生産性向上やコスト削減の実態を明らかにします。
製造業
DCS中島合金株式会社は、鋳造工程での熟練技能の数値化プラットフォーム「Hepaisto」を導入しました。生成AIが添加剤投入量の適正値を瞬時に算出し、品質の安定化と生産性向上を実現しています。これにより属人化が解消され、技能継承が容易になったことで、有給取得率も改善されました [1]。
金融業
ある国内メガバンクでは、稟議書や報告文書の自動生成に生成AIを活用する実証実験を実施しました。医事務や審査文書の作成業務をAIが補助した結果、バックオフィス業務全体の工数が約30%削減され、担当者のレビュー時間も大幅に短縮できたと報告されています [2]。
小売業
セブン‐イレブンは画像生成AIを用いた商品企画プロセスを構築し、OpenAIやStability AIによるビジュアルを活用して企画アイデアを迅速に可視化しています。導入後は企画段階の時間が最大で90%削減され、リアルタイムの消費者動向分析による迅速な意思決定が可能になりました [1]。
医療業界
恵寿総合病院では、生成AIを活用した退院時サマリー自動作成を試験導入しました。プロンプト設計によってAIが要約文を生成し、医師の確認・修正だけで済む仕組みにより、作業時間が従来の1/3に短縮。年間約540時間の工数削減が見込まれています [1]。
### Sources
[1] 「生成AIの活用事例21選から分かる企業成長戦略とは?」: https://ai-market.jp/case_study/generativeai-usecases/
[2] 「【初心者必読】生成AIで業務効率化!今から始める成功パターンと具体事例」: https://www.proofx.xyz/generativeai-optimize/
## 導入に向けた課題と成功パターン
AIエージェント導入には、技術的・組織的な障壁が存在します。まず技術面では、学習や動作に必要な質の高いデータが不足しがちです。既存システムとの連携にも多大なコストと手間がかかり、セキュリティやプライバシーリスクへの対策も不可欠です。これらの課題を放置すると、プロジェクトが頓挫する恐れがあります[1]。
組織的には、従業員のAIリテラシー不足が問題となります。AIの特性や限界を理解しないまま導入を進めると、誤った期待や混乱を招きます。また、従来の業務プロセスに固執する抵抗感も大きな障壁です。さらに、初期投資に対するROIが明確でないと、予算確保や意思決定が難航します[1]。
これらを乗り越える成功企業に共通する要因は三つあります。第一に、人間との協働モデルの構築です。AIの得意領域と人間の創造性や倫理判断を明確に分担し、初期は人間の承認を挟むなど段階的に自律度を高める仕組みを整えます[1]。
第二に、段階的導入プロセスです。限定的なパイロット運用で効果を検証し、KPIを設定した上で範囲を徐々に拡大します。短いフィードバックループを回しながら改善を重ねることで、リスクを抑制しつつ成功確率を高めます[1]。
第三に、データ連携強化です。部門間のサイロを解消し、APIエコシステムを整備。データクレンジングや標準化を進めると同時に、リアルタイムデータパイプラインを構築することで、AIエージェントの性能を最大化します[1]。
これらを組み合わせることで、技術的・組織的な壁を突破し、持続的な価値創出が可能になります。
### Sources
[1] 業界×AIエージェントの活用方法: 2025年最新動向 - Zenn: https://zenn.dev/acntechjp/articles/20250402_industry_ai_agents
## 2025年以降の展望と戦略指針
業界の境界を越えるクロスドメインエージェント
今後のAIエージェントは、特定産業や業務に閉じず、製造/物流/小売など異なるドメインをシームレスに横断して最適化を図るクロスドメインエージェントへと進化します。例えば、サプライチェーン最適化エージェントが物流ルート最適化や需要予測エージェントと連携し、業界の壁を超えた統合的な価値創出が可能になります[1]。
環境適応型エージェントの台頭
従来のヒューマンワークフロー模倣型ではなく、AIの特性を活かして環境変化に応じた最適戦略を自律的に設計・実行する環境適応型エージェントが登場します。これにより業務プロセスそのものが再定義され、人間とAIの協働モデルが新たな段階を迎えます[1]。
協調学習エコシステムの形成
組織単独で学習・運用されていたエージェントが、セキュアなデータ共有と協調学習によって相互に知見を拡張し合うエコシステムが構築されます。複数企業の集合知を活用することで、個別学習では到達できない高度な推論能力や予測精度が実現し、業界全体の競争力向上につながります[1]。
戦略的意思決定フレームワーク
AIエージェント導入にあたっては、以下の4要素で優先順位を判断します[1]。
1. 問題適合性:データ量や反復性など、自社課題との親和性評価
2. 価値創出ポテンシャル:効率化に加え新規ビジネス機会の有無
3. 実現可能性:技術・組織成熟度を踏まえた現実的評価
4. 投資優先度:ROIや業務インパクトを基に導入順序を決定
組織的準備とロードマップ設計
短期(1年以内)は小規模パイロットでROI検証、中期(1–3年)は水平展開と基盤統合、長期(3年以上)は新事業モデル創出を目指します。同時にAIリテラシー向上や越境人材育成、ガバナンス体制整備を並行して進めることで、持続的な価値創出を実現します[1]。
### Sources
[1] 業界×AIエージェントの活用方法: 2025年最新動向: https://zenn.dev/acntechjp/articles/20250402_industry_ai_agents
## 結論
本レポートでは、生成AIとAIエージェントの自律性や適用範囲の違い、市場動向、業界別の具体事例、導入時の技術・組織的課題と成功パターン、そして2025年以降の発展方向を整理しました。AIエージェントは単なる対話型生成AIを超え、マルチステップ処理と外部システム連携によって業務全体を自律的に最適化できる点で、企業のデジタルトランスフォーメーションにおける中核技術となり得ます。
以下のロードマップを通じて、フェーズごとに検証・拡大・革新を進めることが導入成功の鍵です。
| フェーズ | 期間 | 主な施策 | 期待効果 |
|--------|----------|------------------------------|----------------------------------------|
| 短期 | 1年以内 | 限定部門でのパイロット運用、ROI検証 | AIリテラシー向上、初期効果の可視化 |
| 中期 | 1–3年 | 横展開と基盤統合、データ標準化 | 業務自動化範囲の拡大、データ品質と安全性の強化 |
| 長期 | 3年以上 | 新規事業モデル創出、協調学習導入 | クロスドメイン最適化、持続的競争力の獲得 |
これを踏まえ、まずはパイロットで効果を把握し、段階的にスケールさせることで、確実にAIエージェントの価値を最大化してください。
o1 (2024-12-17)
o1での実行結果
#生成AIのエージェントと今後の展望(2025年)
生成AIエージェントへの関心は近年急速に高まり、社会のさまざまな領域で活用が期待されています。このテクノロジーは自律的に学習し、新しいアイデアやソリューションを生み出す能力を持つため、これまでにない革新的な可能性をもたらします。
本報告書では、2025年を見据えた生成AIエージェントの発展動向を明らかにし、その社会的・産業的インパクトを考察します。私たちは、この新たな技術がどのように役立ち、私たちの生活や経済にどのような影響を与えるのかを深く探求することを目指しています。
## 生成AIエージェントの概要
生成AIエージェントは、大規模言語モデルなどから得られる豊富な自然言語生成能力を活用して、ユーザーとの対話や資料作成、意思決定支援など多岐にわたるタスクを自律的に実行できる点が特徴です。従来のAIシステムが一般的に「特定のタスク」を繰り返し学習し実行するのに対し、生成AIエージェントは目的と状況に応じて柔軟にタスクを組み合わせ、自ら推論しながら最適な手段を探る能力があります。ここでは、他のAI技術との位置づけを明確にするため、要点を以下の表にまとめました。
| 分類 | 対応可能な範囲 | 対話・応答品質 | 適用事例 |
|--------------------------------------|----------------------|--------------------|-----------------------------------|
| 生成AIエージェント | 多用途かつ柔軟 | 自然かつ文脈重視 | 自動文章作成、顧客対応、戦略提案等 |
| 従来型AI技術(ルールベース・機械学習) | 目的限定・パターン化 | 設計された範囲で精度 | 画像認識、特定領域の予測分析など |
このように生成AIエージェントは、汎用性を確保しつつ高度な自然言語生成・理解機能により幅広い領域で活用される可能性を秘めています。一方で、膨大な学習データが必要、生成内容の信頼性確保の課題なども依然として存在します。これらの課題を解決するためには、データの精度管理や倫理的側面への配慮が欠かせません。
今後、タスク管理能力や意思決定の透明性を高める技術が進歩し、幅広い産業領域で生成AIエージェントが採用されると考えられます。具体的には、複雑な業務オペレーションの自動化や個別化された提案を行うシステムが多く登場するでしょう。これにより、効率だけでなく新しい付加価値の創出が期待されます。
## 主な応用分野と事例
生成AIエージェントは、自然言語処理や画像生成などの技術を組み合わせ、複雑なタスクを自律的に行う点で注目を集めています。まず顕著な例として、カスタマーサポート分野ではチャットボットがすでに導入され、ユーザーからの問い合わせを自動解決する取り組みが進んでいます。今後は問い合わせ内容を学習し、新たな質問や要望にも即時に対応できる柔軟性を備えたエージェントが増えるでしょう。
さらにクリエイティブ領域では、広告コピーやデザイン案などを自動生成し、短時間で多彩なアイデアを示すツールとしての活用が期待されます。また、学習支援ツールとしてのエージェントも注目されており、例えばオンライン授業に合わせて受講者の反応を分析し、最適な補足説明をリアルタイムで挿入することで、より効率的な学習体験を作り出せる可能性があります。
製造業や物流分野では、画像認識を駆使して作業手順の最適化や在庫管理を自動化する事例が増加し、業務効率化に大きく寄与しています。加えて医療領域では、AIエージェントが膨大な症例データから適切な診断や治療プランを提案するための研究が進行中です。これらの導入事例を観察すると、2025年までにはさまざまな産業で寄与度を高め、より高度な自律性をもった生成AIエージェントが社会の多彩な場面で一般化することが期待されます。
## 導入に伴う課題と対応策
生成AIエージェントの導入においては、法規制とセキュリティ対策、そしてデータ品質の確保が大きな課題となる。まず、国や地域によって異なる個人情報保護法や利用規約に準拠しなければならないため、開発・運用プロセスでの契約見直しやコンプライアンス管理が欠かせない。また、高度な自然言語処理技術を悪用しようとする外部からの攻撃リスクが高まることから、暗号化や認証管理など徹底したセキュリティ対策が必要だ。さらに、AI学習で用いるデータが不十分であったり偏りを含んでいたりすると、エージェントの応答や意思決定が不正確・不公平になる恐れがある。
これらを克服するには、以下のポイントを重点的に実施すると効果的である:
- 法規制への対応: 事業領域に応じたガイドラインの調査と順守手順の策定
- セキュリティ強化: アクセス権限の細分化や継続的な脆弱性診断の導入
- データ品質管理: 多様なソースからの学習データ収集と定期的な再評価
これらの対策を講じたうえで、運用状況をモニタリングしながらアップデートを繰り返す体制を構築することが、今後の重要なステップとなる。特に、エージェントが自動的に生成する情報の説明責任を明確にし、問い合わせやクレームに迅速に対応できる仕組みを設けることが課題解決のカギだ。これらを総合的に実践することで、企業や社会が生成AIエージェントの恩恵を安心して享受できるようになるだろう。
## 今後の展望と結論
生成AIエージェントは、ユーザーに合わせた高度な文章・画像・音声の生成だけでなく、多様なタスクを自己判断で実行できる「自律性」も獲得しつつある。具体的には、ビジネス文書のドラフト作成、製品企画の要点提示、さらに学習者の到達度に応じた学習プランの構築など、領域を問わず柔軟な支援が期待できる。また、自然言語での指示内容を深く把握し、外部システムと連携しながら意思決定を行うことにより、新たなサービスやソリューションの創出が進む見通しである。
今後は、扱うデータの正確性やプライバシー保護が大きな課題となる。特に企業導入においては、コストの最適化や運用リスクの軽減が求められ、安全かつスケーラブルな環境整備とガイドラインの整備が不可欠になるだろう。以下に主なポイントを整理する:
- 高度化した自然言語理解による多彩な業務サポート
- 自動化や外部システム連携による新規価値の創出
- データのセキュリティと倫理的利用の両立
- 機能拡張とガイドライン策定を同時に行う運用体制の確立
今後は、企業や研究機関が互いに知見を共有しながら、運用リスクや責任範囲を明確にしつつ、ユーザーの目的に合った最適なエージェント設計を進めていく必要がある。具体的な次のステップとしては、実運用を想定したテスト環境の構築や専門家との連携を強化し、定期的に成果を評価・改善するプロセスを確立することが挙げられる。
終わりに
今回、学習の一環として、LangChainのOpen Deep ResearchをOpenAI Agents SDKで再実装してみました。
個人的にはLangGraphのグラフ遷移について一部動作が分かり辛い(Map-Reduce等)と感じたくらいで、構造化出力やプロンプト等がそのまま流用できたため思っていたより比較的簡単に再実装出来ました。
ただ1つ課題だったのが2025年3月にBing Search APIが廃止されAPIキーの発行ができなくなった点です。Azure AI FoundryのAgent Serviceを利用すれば可能ですが構成が複雑になるため、早期にAzure OpenAI ServiceのResponses APIにWeb検索機能が提供されることを期待しています。
またOpenAI Agents SDKは明記されていませんが、マルチエージェントの説明に記載されている「LLMによるオーケストレーション」を軸に作成されており、LangGraphの「コードによるオーケストレーション」とは異なる方式を採っているため、適しているシーンが異なると感じました。例えばLangGraphとOpenAI Agents SDKを組み合わせることで、LangGraphで全体のフロー制御を行い、OpenAI Agents SDKでLLM/MCP呼び出しを行うことで、より効率的・効果的な開発が可能になるかもしれません。
(「なぜLangChainを使わずにOpenAI Agents SDKを使っているのか?」というツッコミがありそうですが。)
まだ「エージェント」とは何かが明確に定まっていない部分もありますが、引き続きどのような手法を取ればハルシネーションなどが発生せず、LLMを用いて作業の効率化や代替ができるかを検討していきたいと思います。
参考記事
(参考)LangChainのOpen DeepResearchをOpenAI Agents SDKで再実装したコード
付録:作成したコード
main.py
main.pyは、元のコードではgraph.pyにおけるグラフ構築箇所と、graph.ipynbで実際にグラフを実行している個所をコードに変更したものになります。
import asyncio
import os
from openai import AsyncAzureOpenAI
from agents import set_default_openai_client, set_tracing_disabled, set_default_openai_api
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
from dotenv import load_dotenv
from agents.tracing.processors import default_processor
from state import (
ReportState
)
from configuration import Configuration
from custom_agents import (
generate_report_plan,
build_section_with_web_research,
write_first_or_final_sections,
compile_final_report
)
from utils import format_sections
REPORT_STRUCTURE = """Use this structure to create a report on the user-provided topic in Japanese:
1. Introduction (no research needed)
- Brief overview of the topic area
2. Main Body Sections:
- Each section should focus on a sub-topic of the user-provided topic
3. Conclusion
- Aim for 1 structural element (either a list of table) that distills the main body sections
- Provide a concise summary of the report"""
topic = "生成AIのエージェントと今後の展望(2025年)"
# OpenAIへのトレースを停止する。
set_tracing_disabled(True)
# デフォルトAPIをResponsesからChat Completionsに。
set_default_openai_api("chat_completions")
# 背後でOpenAIにTrace情報を送信するProcessorが動作しているので停止する
default_processor().shutdown()
load_dotenv()
# Azure OpenAIクライアントを初期化
credential = DefaultAzureCredential()
openai_client = AsyncAzureOpenAI(
api_version=os.getenv("OPENAI_API_VERSION"), # 2025-03-01-preview or later
azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
azure_ad_token_provider=get_bearer_token_provider(credential, "https://cognitiveservices.azure.com/.default"),
max_retries=10,
)
# OpenAI Agents SDKにクライアントをセット
set_default_openai_client(openai_client)
async def feed_back(state: ReportState):
# Get sections
topic = state["topic"]
sections = state['sections']
sections_str = "\n\n".join(
f"Section: {section.name}\n"
f"Description: {section.description}\n"
f"Research needed: {'Yes' if section.research else 'No'}\n"
for section in sections
)
# Get feedback on the report plan from interrupt
feedback_message = f"""Please provide feedback on the following report plan.
\n\n{sections_str}\n
\nDoes the report plan meet your needs?\nPass 'true' to approve the report plan.\nOr, provide feedback to regenerate the report plan:"""
print(feedback_message)
feedback = input('>> ')
if feedback == "true":
return True
elif feedback:
state["feedback_on_report_plan"] = feedback
return False
else:
raise TypeError(f"Interrupt value of type {type(feedback)} is not supported.")
async def main() -> None:
# 設定と状態の初期化
config = Configuration(
report_structure=REPORT_STRUCTURE,
number_of_queries=1,
max_search_depth=1,
writer_model_name="gpt-4o-mini",
planner_model_name="gpt-4o-mini",
)
report_state = ReportState(topic=topic, completed_sections=list())
while True:
# フィードバックが完了するまで、レポートの生成計画を作成する
await generate_report_plan(report_state, config)
if await feed_back(report_state):
break
# 再検索が必要なセクションについて検索を実施
for s in report_state['sections']:
if s.research:
section_state = await build_section_with_web_research({"topic": topic, "section": s, "search_iterations": 0}, config)
report_state["completed_sections"].append(section_state["completed_section"])
# 再検索を実施したセクションを整形する
report_state["report_sections_from_research"] = None if "completed_sections" not in report_state else format_sections(report_state["completed_sections"])
# 再検索が不要なセクション(序文と結論等)について文章を生成
for s in report_state['sections']:
if not s.research:
section_state = await write_first_or_final_sections(
{"topic": topic, "section": s, "report_sections_from_research": report_state["report_sections_from_research"]},
config,
report_state['sections'][0] == s
)
report_state["completed_sections"].append(section_state["completed_section"])
compile_final_report(report_state)
print("---------------------------------------")
print(report_state["final_report"])
print("---------------------------------------")
if __name__ == "__main__":
asyncio.run(main())
configuration.py
configuration.pyは、元のコードよりLangGraph/LangChainに関連するコードを省いています。
from dataclasses import dataclass
DEFAULT_REPORT_STRUCTURE = """Use this structure to create a report on the user-provided topic:
1. Introduction (no research needed)
- Brief overview of the topic area
2. Main Body Sections:
- Each section should focus on a sub-topic of the user-provided topic
3. Conclusion
- Aim for 1 structural element (either a list of table) that distills the main body sections
- Provide a concise summary of the report"""
@dataclass(kw_only=True)
class Configuration:
"""The configurable fields for the chatbot."""
report_structure: str = DEFAULT_REPORT_STRUCTURE # Defaults to the default report structure
number_of_queries: int = 2 # Number of search queries to generate per iteration
max_search_depth: int = 2 # Maximum number of reflection + search iterations
planner_model_name: str = "gpt-4o"
writer_model_name: str = "gpt-4o"
.env
.envファイルの例は以下の通りです。
OPENAI_API_VERSION=2025-03-01-preview
AZURE_OPENAI_ENDPOINT=https://<Azure OpenAI Resource Name>.openai.azure.com/
AZURE_OPENAI_DEPLOYMENT=<Deployment Name>
custom_agents.py
custom_agents.pyは、元のコードではgraph.pyだったもので、LangGraph/LangChainを用いていたものをOpenAI Agents SDKに置き換えています。
主な修正事項については本文を参照してください。
from agents import Agent, Runner
from state import (
ReportState,
SectionState,
SectionOutputState,
Queries,
Sections,
Feedback
)
from prompts import (
report_planner_query_writer_instructions,
report_planner_instructions,
query_writer_instructions,
section_writer_instructions,
first_section_writer_instructions,
final_section_writer_instructions,
section_grader_instructions,
section_writer_inputs
)
from configuration import Configuration
from utils import google_search_async
async def generate_report_plan(state: ReportState, config: Configuration):
# Inputs
topic = state["topic"]
feedback = state.get("feedback_on_report_plan", None)
# Get configuration
report_structure = config.report_structure
number_of_queries = config.number_of_queries
# Convert JSON object to string if necessary
if isinstance(report_structure, dict):
report_structure = str(report_structure)
# Format system instructions
system_instructions_query = report_planner_query_writer_instructions.format(topic=topic, report_organization=report_structure, number_of_queries=number_of_queries)
# Generate queries
generate_search_queries_agent = Agent(
name="Generate search queries agent",
instructions=system_instructions_query,
output_type=Queries,
model=config.writer_model_name,
)
result = await Runner.run(starting_agent=generate_search_queries_agent, input="Generate search queries that will help with planning the sections of the report.")
# Web search
query_list = [query.search_query for query in result.final_output.queries]
state["queries"] = query_list
# Search the web
# source_str = await duckduckgo_search(query_list)
source_str = await google_search_async(query_list)
# Format system instructions
system_instructions_sections = report_planner_instructions.format(topic=topic, report_organization=report_structure, context=source_str, feedback=feedback)
# Set the planner
# Report planner instructions
planner_message = """Generate the sections of the report. Your response must include a 'sections' field containing a list of sections.
Each section must have: name, description, plan, research, and content fields."""
# Run the planner
# Generate the report sections
generate_report_sections_agent = Agent(
name="Generate the sections of the report",
instructions=system_instructions_sections,
output_type=Sections,
model=config.planner_model_name,
)
result = await Runner.run(starting_agent=generate_report_sections_agent, input=planner_message)
# Get and set sections
state["sections"] = result.final_output.sections
async def generate_queries(state: SectionState, config: Configuration):
# Get state
topic = state["topic"]
section = state["section"]
# Get configuration
number_of_queries = config.number_of_queries
# Format system instructions
system_instructions = query_writer_instructions.format(topic=topic,
section_topic=section.description,
number_of_queries=number_of_queries)
# Generate queries
generate_search_queries_agent = Agent(
name="Generate search queries agent",
instructions=system_instructions,
output_type=Queries,
model=config.writer_model_name,
)
result = await Runner.run(starting_agent=generate_search_queries_agent,
input="Generate search queries on the provided topic.")
state["search_queries"] = result.final_output.queries
async def search_web(state: SectionState, config: Configuration):
# Get state
search_queries = state["search_queries"]
# Web search
query_list = [query.search_query for query in search_queries]
# Search the web
# source_str = await duckduckgo_search(query_list)
source_str = await google_search_async(query_list)
state["source_str"] = source_str
state["search_iterations"] = state["search_iterations"] + 1
async def write_section(state: SectionState, config: Configuration) -> bool:
# Get state
topic = state["topic"]
section = state["section"]
source_str = state["source_str"]
# Format system instructions
section_writer_inputs_formatted = section_writer_inputs.format(topic=topic,
section_name=section.name,
section_topic=section.description,
context=source_str,
section_content=section.content)
# Generate section
generate_section_agent = Agent(
name="Generate a section of the report",
instructions=section_writer_instructions,
model=config.writer_model_name,
)
result = await Runner.run(starting_agent=generate_section_agent, input=section_writer_inputs_formatted)
# Write content to the section object
section.content = result.final_output
# Grade prompt
section_grader_message = ("Grade the report and consider follow-up questions for missing information. "
"If the grade is 'pass', return empty strings for all follow-up queries. "
"If the grade is 'fail', provide specific search queries to gather missing information.")
section_grader_instructions_formatted = section_grader_instructions.format(topic=topic,
section_topic=section.description,
section=section.content,
number_of_follow_up_queries=config.number_of_queries)
# Use planner model for reflection
feedback_agent = Agent(
name="Grade the report and consider follow-up questions for missing information",
instructions=section_grader_instructions_formatted,
output_type=Feedback,
model=config.planner_model_name,
)
# Generate feedback
result = await Runner.run(starting_agent=feedback_agent, input=section_grader_message)
feedback = result.final_output_as(Feedback)
# If the section is passing or the max search depth is reached, publish the section to completed sections
if feedback.grade == "pass" or state["search_iterations"] >= config.max_search_depth:
# Publish the section to completed sections
state["completed_section"] = section
return True
# Update the existing section with new content and update search queries
else:
state["search_queries"] = feedback.follow_up_queries
state["section"] = section
return False
async def build_section_with_web_research(state: SectionState, config: Configuration) -> SectionOutputState:
await generate_queries(state, config)
await search_web(state, config)
while not await write_section(state, config):
await search_web(state, config)
return {"completed_section": state["completed_section"]}
async def write_first_or_final_sections(state: SectionState, config: Configuration, is_first: bool) -> SectionOutputState:
# Get state
topic = state["topic"]
section = state["section"]
completed_report_sections = state["report_sections_from_research"]
# Format system instructions
if is_first:
system_instructions = first_section_writer_instructions.format(topic=topic, section_name=section.name, section_topic=section.description, context=completed_report_sections)
else:
system_instructions = final_section_writer_instructions.format(topic=topic, section_name=section.name, section_topic=section.description, context=completed_report_sections)
# Generate section
generate_section_agent = Agent(
name="Generate a section of the report",
instructions=system_instructions,
model=config.planner_model_name,
)
result = await Runner.run(starting_agent=generate_section_agent, input="Generate a report section based on the provided sources.")
# Write content to section
section.content = result.final_output
# Write the updated section to completed sections
return {"completed_section": section}
def compile_final_report(state: ReportState):
# Get sections
sections = state["sections"]
completed_sections = {s.name: s.content for s in state["completed_sections"]}
# Update sections with completed content while maintaining original order
for section in sections:
section.content = completed_sections[section.name]
# Compile final report
all_sections = "\n\n".join([s.content for s in sections])
state["final_report"] = all_sections
prompts.py
prompts.pyは、ほぼ変更ありませんが、gpt-4o-miniだと、元のfinal_section_writer_instructionsが正しく動作しなかったので、first_section_writer_instructions、final_section_writer_instructionsの2つに分割しています。
report_planner_query_writer_instructions="""You are performing research for a report.
<Report topic>
{topic}
</Report topic>
<Report organization>
{report_organization}
</Report organization>
<Task>
Your goal is to generate {number_of_queries} web search queries that will help gather information for planning the report sections.
The queries should:
1. Be related to the Report topic
2. Help satisfy the requirements specified in the report organization
Make the queries specific enough to find high-quality, relevant sources while covering the breadth needed for the report structure.
</Task>
<Format>
Call the Queries tool
</Format>
"""
report_planner_instructions="""I want a plan for a report that is concise and focused.
<Report topic>
The topic of the report is:
{topic}
</Report topic>
<Report organization>
The report should follow this organization:
{report_organization}
</Report organization>
<Context>
Here is context to use to plan the sections of the report:
{context}
</Context>
<Task>
Generate a list of sections for the report. Your plan should be tight and focused with NO overlapping sections or unnecessary filler.
For example, a good report structure might look like:
1/ intro
2/ overview of topic A
3/ overview of topic B
4/ comparison between A and B
5/ conclusion
Each section should have the fields:
- Name - Name for this section of the report.
- Description - Brief overview of the main topics covered in this section.
- Research - Whether to perform web research for this section of the report.
- Content - The content of the section, which you will leave blank for now.
Integration guidelines:
- Include examples and implementation details within main topic sections, not as separate sections
- Ensure each section has a distinct purpose with no content overlap
- Combine related concepts rather than separating them
Before submitting, review your structure to ensure it has no redundant sections and follows a logical flow.
</Task>
<Feedback>
Here is feedback on the report structure from review (if any):
{feedback}
</Feedback>
<Format>
Call the Sections tool
</Format>
"""
query_writer_instructions="""You are an expert technical writer crafting targeted web search queries that will gather comprehensive information for writing a technical report section.
<Report topic>
{topic}
</Report topic>
<Section topic>
{section_topic}
</Section topic>
<Task>
Your goal is to generate {number_of_queries} search queries that will help gather comprehensive information above the section topic.
The queries should:
1. Be related to the topic
2. Examine different aspects of the topic
Make the queries specific enough to find high-quality, relevant sources.
</Task>
<Format>
Call the Queries tool
</Format>
"""
section_writer_instructions = """Write one section of a research report.
<Task>
1. Review the report topic, section name, and section topic carefully.
2. If present, review any existing section content.
3. Then, look at the provided Source material.
4. Decide the sources that you will use it to write a report section.
5. Write the report section and list your sources.
</Task>
<Writing Guidelines>
- If existing section content is not populated, write from scratch
- If existing section content is populated, synthesize it with the source material
- Strict 150-200 word limit
- Use simple, clear language
- Use short paragraphs (2-3 sentences max)
- Use ## for section title (Markdown format)
</Writing Guidelines>
<Citation Rules>
- Assign each unique URL a single citation number in your text
- End with ### Sources that lists each source with corresponding numbers
- IMPORTANT: Number sources sequentially without gaps (1,2,3,4...) in the final list regardless of which sources you choose
- Example format:
[1] Source Title: URL
[2] Source Title: URL
</Citation Rules>
<Final Check>
1. Verify that EVERY claim is grounded in the provided Source material
2. Confirm each URL appears ONLY ONCE in the Source list
3. Verify that sources are numbered sequentially (1,2,3...) without any gaps
</Final Check>
"""
section_writer_inputs="""
<Report topic>
{topic}
</Report topic>
<Section name>
{section_name}
</Section name>
<Section topic>
{section_topic}
</Section topic>
<Existing section content (if populated)>
{section_content}
</Existing section content>
<Source material>
{context}
</Source material>
"""
section_grader_instructions = """Review a report section relative to the specified topic:
<Report topic>
{topic}
</Report topic>
<section topic>
{section_topic}
</section topic>
<section content>
{section}
</section content>
<task>
Evaluate whether the section content adequately addresses the section topic.
If the section content does not adequately address the section topic, generate {number_of_follow_up_queries} follow-up search queries to gather missing information.
</task>
<format>
Call the Feedback tool and output with the following schema:
grade: Literal["pass","fail"] = Field(
description="Evaluation result indicating whether the response meets requirements ('pass') or needs revision ('fail')."
)
follow_up_queries: List[SearchQuery] = Field(
description="List of follow-up search queries.",
)
</format>
"""
first_section_writer_instructions="""You are an expert technical writer crafting a section that synthesizes information from the rest of the report.
<Report topic>
{topic}
</Report topic>
<Section name>
{section_name}
</Section name>
<Section topic>
{section_topic}
</Section topic>
<Available report content>
{context}
</Available report content>
<Task>
1. Section-Specific Approach:
For Introduction:
- Use # for report title (Markdown format)
- 50-100 word limit
- Write in simple and clear language
- Focus on the core motivation for the report in 1-2 paragraphs
- Use a clear narrative arc to introduce the report
- Include NO structural elements (no lists or tables)
- No sources section needed
3. Writing Approach:
- Use concrete details over general statements
- Make every word count
- Focus on your single most important point
</Task>
<Quality Checks>
- For introduction: 50-100 word limit, # for report title, no structural elements, no sources section
- For conclusion: 100-150 word limit, ## for section title, only ONE structural element at most, no sources section
- Markdown format
- Do not include word count or any preamble in your response
</Quality Checks>"""
final_section_writer_instructions="""You are an expert technical writer crafting a section that synthesizes information from the rest of the report.
<Report topic>
{topic}
</Report topic>
<Section name>
{section_name}
</Section name>
<Section topic>
{section_topic}
</Section topic>
<Available report content>
{context}
</Available report content>
<Task>
1. Section-Specific Approach:
For Conclusion/Summary:
- Do not write report title
- Use ## for section title (Markdown format)
- 100-150 word limit
- For comparative reports:
* Must include a focused comparison table using Markdown table syntax
* Table should distill insights from the report
* Keep table entries clear and concise
- For non-comparative reports:
* Only use ONE structural element IF it helps distill the points made in the report:
* Either a focused table comparing items present in the report (using Markdown table syntax)
* Or a short list using proper Markdown list syntax:
- Use `*` or `-` for unordered lists
- Use `1.` for ordered lists
- Ensure proper indentation and spacing
- End with specific next steps or implications
- No sources section needed
3. Writing Approach:
- Use concrete details over general statements
- Make every word count
- Focus on your single most important point
</Task>
<Quality Checks>
- For introduction: 50-100 word limit, # for report title, no structural elements, no sources section
- For conclusion: 100-150 word limit, ## for section title, only ONE structural element at most, no sources section
- Markdown format
- Do not include word count or any preamble in your response
</Quality Checks>"""
state.py
state.pyも、ほぼ変更なしで、ReportState、SectionState、SectionOutputStateについて一部変更しています。
from typing import Annotated, List, TypedDict, Literal, Any
from pydantic import BaseModel, Field
import operator
class Section(BaseModel):
name: str = Field(
description="Name for this section of the report.",
)
description: str = Field(
description="Brief overview of the main topics and concepts to be covered in this section.",
)
research: bool = Field(
description="Whether to perform web research for this section of the report."
)
content: str = Field(
description="The content of the section."
)
class Sections(BaseModel):
sections: List[Section] = Field(
description="Sections of the report.",
)
class SearchQuery(BaseModel):
search_query: str = Field(None, description="Query for web search.")
class Queries(BaseModel):
queries: List[SearchQuery] = Field(
description="List of search queries.",
)
class Feedback(BaseModel):
grade: Literal["pass","fail"] = Field(
description="Evaluation result indicating whether the response meets requirements ('pass') or needs revision ('fail')."
)
follow_up_queries: List[SearchQuery] = Field(
description="List of follow-up search queries.",
)
class ReportStateInput(TypedDict):
topic: str # Report topic
class ReportStateOutput(TypedDict):
final_report: str # Final report
class ReportState(TypedDict):
topic: str # Report topic
queries: list[str] # ---(追加)---
feedback_on_report_plan: str # Feedback on the report plan
sections: list[Section] # report section
completed_sections: Annotated[list, operator.add] # Send() API key
report_sections_from_research: str # String of any completed sections from research to write final sections
final_report: str # Final report
class SectionState(TypedDict):
topic: str # Report topic
section: Section # Report section
search_iterations: int # Number of search iterations done
search_queries: list[SearchQuery] # List of search queries
source_str: str # String of formatted source content from web search
report_sections_from_research: str # String of any completed sections from research to write final sections
completed_section: Section # ---(変更)--- Final key we duplicate in outer state for Send() API
class SectionOutputState(TypedDict):
completed_section: Section # ---(変更)---Final key we duplicate in outer state for Send() API
utils.py
utils.pyは、検証用としてGoogle検索のスクレイピングモードのみ残しています。
他の検索エンジンも利用する場合は元のコードを参照してください。
import os
import asyncio
import requests
import random
import concurrent
import aiohttp
import time
from typing import List, Union
from urllib.parse import unquote
from bs4 import BeautifulSoup
from state import Section
def format_sections(sections: list[Section]) -> str:
""" Format a list of sections into a string """
formatted_str = ""
for idx, section in enumerate(sections, 1):
formatted_str += f"""
{'='*60}
Section {idx}: {section.name}
{'='*60}
Description:
{section.description}
Requires Research:
{section.research}
Content:
{section.content if section.content else '[Not yet written]'}
"""
return formatted_str
def deduplicate_and_format_sources(search_response, max_tokens_per_source, include_raw_content=True):
"""
Takes a list of search responses and formats them into a readable string.
Limits the raw_content to approximately max_tokens_per_source tokens.
Args:
search_responses: List of search response dicts, each containing:
- query: str
- results: List of dicts with fields:
- title: str
- url: str
- content: str
- score: float
- raw_content: str|None
max_tokens_per_source: int
include_raw_content: bool
Returns:
str: Formatted string with deduplicated sources
"""
# Collect all results
sources_list = []
for response in search_response:
sources_list.extend(response['results'])
# Deduplicate by URL
unique_sources = {source['url']: source for source in sources_list}
# Format output
formatted_text = "Content from sources:\n"
for i, source in enumerate(unique_sources.values(), 1):
formatted_text += f"{'='*80}\n" # Clear section separator
formatted_text += f"Source: {source['title']}\n"
formatted_text += f"{'-'*80}\n" # Subsection separator
formatted_text += f"URL: {source['url']}\n===\n"
formatted_text += f"Most relevant content from source: {source['content']}\n===\n"
if include_raw_content:
# Using rough estimate of 4 characters per token
char_limit = max_tokens_per_source * 4
# Handle None raw_content
raw_content = source.get('raw_content', '')
if raw_content is None:
raw_content = ''
print(f"Warning: No raw_content found for source {source['url']}")
if len(raw_content) > char_limit:
raw_content = raw_content[:char_limit] + "... [truncated]"
formatted_text += f"Full source content limited to {max_tokens_per_source} tokens: {raw_content}\n\n"
formatted_text += f"{'='*80}\n\n" # End section separator
return formatted_text.strip()
async def google_search_async(search_queries: Union[str, List[str]], max_results: int = 5, include_raw_content: bool = True, lang:str = "ja"):
"""
Performs concurrent web searches using Google.
Uses Google Custom Search API if environment variables are set, otherwise falls back to web scraping.
Args:
search_queries (List[str]): List of search queries to process
max_results (int): Maximum number of results to return per query
include_raw_content (bool): Whether to fetch full page content
Returns:
List[dict]: List of search responses from Google, one per query
"""
# Handle case where search_queries is a single string
if isinstance(search_queries, str):
search_queries = [search_queries]
# Define user agent generator
def get_useragent():
"""Generates a random user agent string."""
lynx_version = f"Lynx/{random.randint(2, 3)}.{random.randint(8, 9)}.{random.randint(0, 2)}"
libwww_version = f"libwww-FM/{random.randint(2, 3)}.{random.randint(13, 15)}"
ssl_mm_version = f"SSL-MM/{random.randint(1, 2)}.{random.randint(3, 5)}"
openssl_version = f"OpenSSL/{random.randint(1, 3)}.{random.randint(0, 4)}.{random.randint(0, 9)}"
return f"{lynx_version} {libwww_version} {ssl_mm_version} {openssl_version}"
# Create executor for running synchronous operations
executor = concurrent.futures.ThreadPoolExecutor(max_workers=1)
# Use a semaphore to limit concurrent requests
semaphore = asyncio.Semaphore(2)
async def search_single_query(query):
async with semaphore:
try:
results = []
# Web scraping based search
# Add delay between requests
await asyncio.sleep(0.5 + random.random() * 1.5)
print(f"Scraping Google for '{query}'...")
# Define scraping function
def google_search(query, max_results):
try:
safe = "active"
start = 0
fetched_results = 0
fetched_links = set()
search_results = []
while fetched_results < max_results:
# Send request to Google
resp = requests.get(
url="https://www.google.com/search",
headers={
"User-Agent": get_useragent(),
"Accept": "*/*"
},
params={
"q": query,
"num": max_results + 2,
"hl": lang,
"start": start,
"safe": safe,
},
cookies = {
'CONSENT': 'PENDING+987', # Bypasses the consent page
'SOCS': 'CAESHAgBEhIaAB',
},
proxies=None
)
resp.raise_for_status()
# Parse results
soup = BeautifulSoup(resp.text, "html.parser")
result_block = soup.find_all("div", class_="ezO2md")
new_results = 0
for result in result_block:
link_tag = result.find("a", href=True)
title_tag = link_tag.find("span", class_="CVA68e") if link_tag else None
description_tag = result.find("span", class_="FrIlee")
if link_tag and title_tag and description_tag:
link = unquote(link_tag["href"].split("&")[0].replace("/url?q=", ""))
if link in fetched_links:
continue
fetched_links.add(link)
title = title_tag.text
description = description_tag.text
# Store result in the same format as the API results
search_results.append({
"title": title,
"url": link,
"content": description,
"score": None,
"raw_content": description
})
fetched_results += 1
new_results += 1
if fetched_results >= max_results:
break
if new_results == 0:
break
start += 10
time.sleep(1) # Delay between pages
return search_results
except Exception as e:
print(f"Error in Google search for '{query}': {str(e)}")
return []
# Execute search in thread pool
loop = asyncio.get_running_loop()
search_results = await loop.run_in_executor(
executor,
lambda: google_search(query, max_results)
)
# Process the results
results = search_results
# If requested, fetch full page content asynchronously (for both API and web scraping)
if include_raw_content and results:
content_semaphore = asyncio.Semaphore(3)
async with aiohttp.ClientSession() as session:
fetch_tasks = []
async def fetch_full_content(result):
async with content_semaphore:
url = result['url']
headers = {
'User-Agent': get_useragent(),
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'
}
try:
await asyncio.sleep(0.2 + random.random() * 0.6)
async with session.get(url, headers=headers, timeout=10, proxy=os.getenv("http_proxy", None)) as response:
if response.status == 200:
# Check content type to handle binary files
content_type = response.headers.get('Content-Type', '').lower()
# Handle PDFs and other binary files
if 'application/pdf' in content_type or 'application/octet-stream' in content_type:
# For PDFs, indicate that content is binary and not parsed
result['raw_content'] = f"[Binary content: {content_type}. Content extraction not supported for this file type.]"
else:
try:
# Try to decode as UTF-8 with replacements for non-UTF8 characters
html = await response.text(errors='replace')
soup = BeautifulSoup(html, 'html.parser')
result['raw_content'] = soup.get_text()
except UnicodeDecodeError as ude:
# Fallback if we still have decoding issues
result['raw_content'] = f"[Could not decode content: {str(ude)}]"
except Exception as e:
print(f"Warning: Failed to fetch content for {url}: {str(e)}")
result['raw_content'] = f"[Error fetching content: {str(e)}]"
return result
for result in results:
fetch_tasks.append(fetch_full_content(result))
updated_results = await asyncio.gather(*fetch_tasks)
results = updated_results
print(f"Fetched full content for {len(results)} results")
return {
"query": query,
"follow_up_questions": None,
"answer": None,
"images": [],
"results": results
}
except Exception as e:
print(f"Error in Google search for query '{query}': {str(e)}")
return {
"query": query,
"follow_up_questions": None,
"answer": None,
"images": [],
"results": []
}
try:
# Create tasks for all search queries
search_tasks = [search_single_query(query) for query in search_queries]
# Execute all searches concurrently
search_results = await asyncio.gather(*search_tasks)
return deduplicate_and_format_sources(search_results, max_tokens_per_source=4000)
finally:
# Only shut down executor if it was created
if executor:
executor.shutdown(wait=False)