3部構成の2部目の記事で、ここではPromptFlow上でMLflowを利用してログ/メトリック収集方法を紹介します。
特にAzure ML/AI Stuido上でPromptFlowを開発した場合は、組み込みのメトリック収集・監視がありますが、詳細なログやメトリックの収集、独自の比較等しようとした場合に組み込みのものだけでは不足する、ということがあると思います。
これを解決するためにPromptFlow組み込みのメトリック収集ではなくMlFlowを利用したメトリック等の収集方法をご紹介します。
なおMLflowの概要については1部目に記載していますので、こちらをご参照ください。
(1) Azure ML & MLflowで可視化: Azure ML StudioとMLflow Trackingによるデータ収集・可視化の紹介
(2) PromptFlowログの可視化:Azure AI/ML Studio & MLflowと連携し収集・可視化する (本記事)
(3) RAG実施時の検索エンジン(Azure AI Search)精度指標の検討 (※記載中)
PromptFlowとは
PromptFlowは、以下のイメージの通りAzure ML Studio、及びAzure AI Studioから利用できる機能の1つで、LLMを利用したアプリケーションの開発ライフサイクルを合理化するために設計されたツールとなっています。またPromtFlowのSDKやCLI、VSCode拡張機能もOSSとして提供されており、Azureだけでなくオンプレ、他AWS等のクラウドでも利用可能なツールになっています。
前記の通りPromptFlowを活用することで、組み込みでのメトリックのロギングやLLMの精度評価等行うことが出来ますが、カスタマイズが難しいといった課題があります。
そこで本記事では、PromptFlow上でMLflowを利用したメトリックやログの記録方法について紹介いたします。
※出典:Microsoft Learn: 大規模言語モデル (LLM) アプリを開発するためのプロンプト フローの概要
Azure ML/AI Studio上でのPromptFlowの実行結果と課題
はじめにAzure ML/AI Studio上でのPromptFlowを実行した際の実行結果詳細画面を紹介し、通常のMLflowを利用した場合との課題を記載いたします。
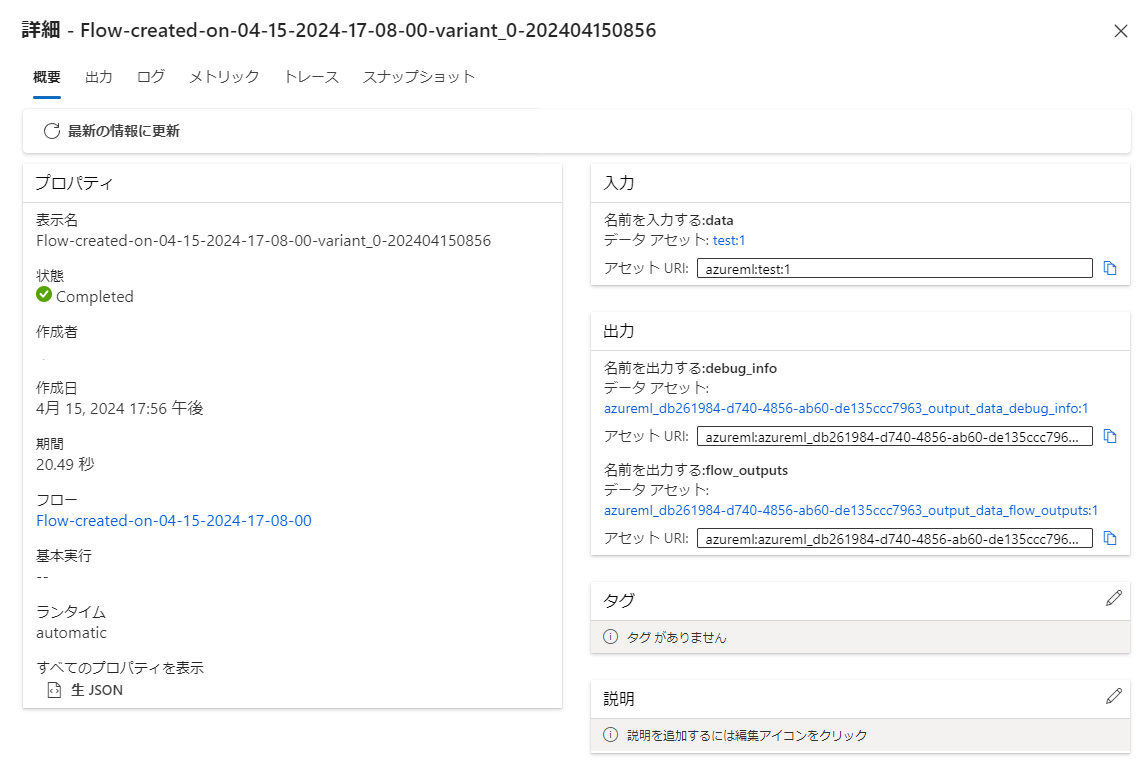
見て頂いたら分かる通りPromptFlowに特化した結果画面となっており、通常のMLflowにて実験を記録した画面と比較し以下の点が大きく異なっています。
- 優れている点:
- 出力ではLLMの生成結果等が一覧で確認ができる
- トレースでは、各ノードの入出力や実行時間、入出力トークン数が一覧で確認できる
- 不足している点:
- メトリック画面では、一覧表示のみでグラフで可視化等が出来ない
- 子ジョブ(ジョブの入れ子)がなく、そうした実行が想定されていない
- PromptFlowのロギングメソッドは、メトリック(数値)以外に対応していない
ジョブ一覧画面のダッシュボードビューでグラフ等が表示出来るものの、評価実行時に各データにて子ジョブとして作成されないため可視化等が多少不便になっています。
また以下のエラーの通り、PromptFlowのPythonノードでMLflowのTracking APIを実行してもエラーが発生し、PromptFlow実行中のジョブ上への記録には対応していません。
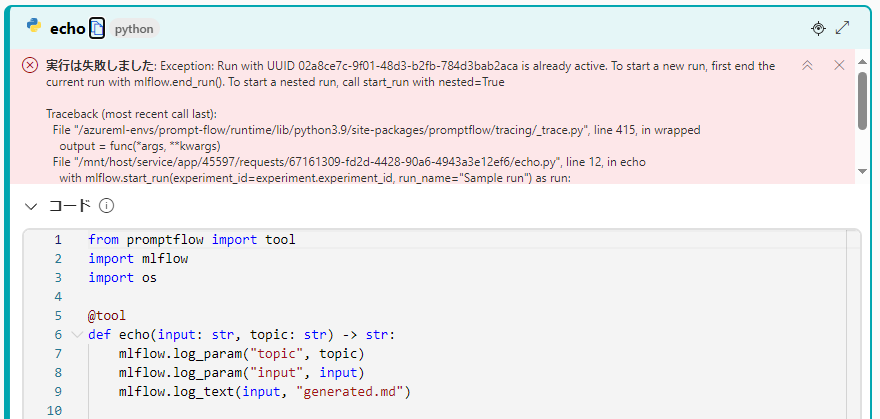
上記のエラーについて調べた結果、以下のことが分かりました。
- PromptFlow上では環境変数にTracking URIは設定されるものの
experiment_idやrun_idが設定されておらず、どの実験、またはジョブかが不明 - デザイナーからの単発の実行か、評価ボタンを押したバッチ実行かがPromptFlowのPythonノード上から判別が出来ない
そこで本記事では、PromptFlow上でMLflowを用いてメトリックやパラメータ等を記録し、また子ジョブについても設定する方法について紹介させて頂きます。
(参考) Azure AI StudioとAzure ML Studioの関係
Azure AI StudioとAzure ML Studioの関係を述べる前に簡単にAzure AI Studioのアーキテクチャについて以下に記載いたします。
Azure AI Studioは大きく「AI Hub」と「AI プロジェクト」の2つから構成されており、それぞれのリソースのリソースプロバイダーは共通しておりMicrosoft.MachineLearningServices/workspacesから提供され、リソース種類は「Hub」と「Project」となっています。
※ちなみにAzure Machine Learning Workspaceもリソースプロバイダーが共通しており、リソース種類が「Default」となっています。
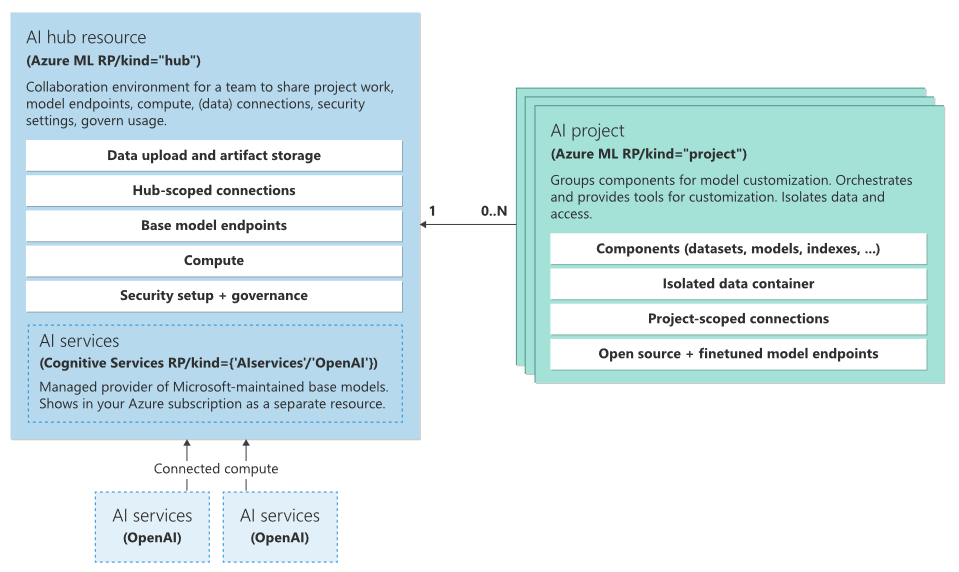
※出典:Architecture - Azure AI Studio
リソースプロバイダーから分かる通りAI Hub、AIプロジェクトともAzure Machine Learning Workspaceの一種になっており※、このうち「Azure AI プロジェクト」は24年4月時点では通常のAzure MLワークスペースとほぼ同じでAzure ML Studio上からワークスペースを選択できるようになっています。
※補足:AI Hub/AI ProjectともAzure MLワークスペースの機能が利用でき、MLflow Tracking URIは両方ともに存在します。
またAI Hub中の「AI Services」は、現在"multi-service account(マルチサービス リソース)"と呼ばれているサービスを新しく再編したもので以下のような違いがあります(24年4月時点)。
ちなみに以下の表はそれぞれのサービスを東日本リージョンで作成し、このリソースJSON中に記載されているエンドポイントから作成しています。
※Microsoftのドキュメントでは、OpenAI、Content Safety、Speech、Visionのみサポートしている記述となっていますが、実際には以下のサービスが利用できますのでご注意ください。
| API Endpoint名 | サービス名 | Azure AI Services | Azure AI services multi-service account |
備考 |
|---|---|---|---|---|
| Computer Vision | Computer Vision | 〇 | 〇 | |
| Container | - | 〇 | 〇 | |
| Content Safety | Content Safety | 〇 | ||
| Content Moderator | Content Moderator | 〇 | ※廃止予定 | |
| Conversational Language Understanding Authoring |
言語サービス | 〇 | 〇 | ※会話言語理解 |
| ConversationalLURuntime | 言語サービス | 〇 | 〇 | ※会話言語理解 |
| Custom Question Answering | 言語サービス | 〇 | 〇 | ※カスタム質問応答 |
| Custom Text Authoring | 言語サービス | 〇 | 〇 | |
| Custom_Vision_Prediction | Custom Vision | 〇 | ※Computer Vision推奨 | |
| Custom_Vision_Training | Custom Vision | 〇 | ※Computer Vision推奨 | |
| DocumentTranslation | 翻訳 | 〇 | 〇 | |
| Face | Face API | 〇 | ※廃止済み | |
| FormRecognizer | Document Intelligence | 〇 | 〇 | |
| Language | 言語サービス | 〇 | 〇 | |
| LUIS | Language Understanding | 〇 | 〇 | ※廃止予定 |
| OpenAI | Azure OpenAI | 〇 | ||
| QnAMaker | QnA Maker | 〇 | 〇 | ※廃止予定 |
| QuestionAnswering | QnA Maker | 〇 | 〇 | ※廃止予定 |
| Speech Services | 言語サービス | 〇 | 〇 | |
| Text Analytics | 言語サービス | 〇 | 〇 | |
| TextTranslation | 翻訳 | 〇 | 〇 | |
| Token | - | 〇 | 〇 | ※制限付きアクセス トークン |
| Turing | - | 〇 | 〇 | ※現在サービス無し |
| Unified Speech | - | 〇 | ||
| Video Translation | - | 〇 | 〇 |
PromptFlow上でのMLflowを用いたログの記録方法
今回作成するPromptFlowのグラフを以下に示します。
このフローはPromptFlowの標準フローにMLflowへの保存処理を追加したものになり、LLMノード(joke)の処理結果のメトリックを各子ジョブに保存するフローとなっています。
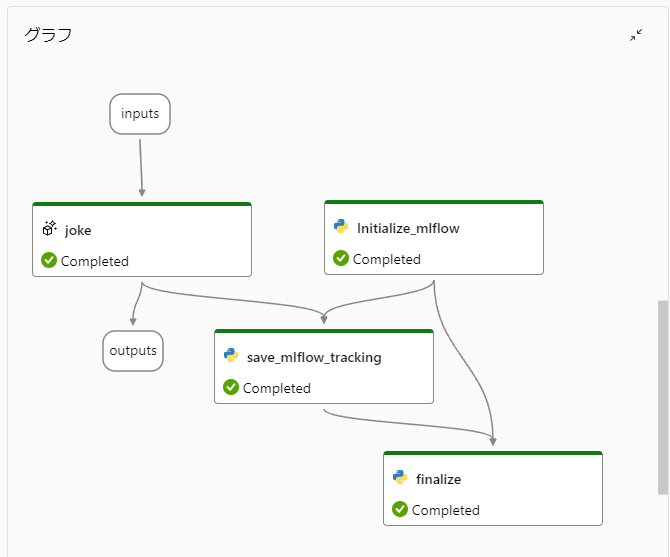
PromptFlowで「評価」ボタンを押下した際のバッチ実行では、各ノードの実行結果はBlobストレージに保存されており、その保存先はPromptFlowの実行結果の「詳細」ボタンを押下した際に表示される画面の出力「debug_info」にて確認できます。
ちなみに評価フローで作成した際のAggregation(集約)ノード中で「log_metric」関数によりメトリックを記録することが出来、こちらは最終的にMLflowのメトリックとして記録されますが、Aggregationノード中でしか利用できないという制約がございます。
以下にそれぞれのPythonノードの内容を記載し、その処理概要について説明いたします。
initialize_mlflowノード
initialize_mlflowノードでは、今回評価実行時の各実行データのメトリックをMLflowに記録することを想定し、子ジョブを作成します。
ポイントとしてはOperationContext.get_instance().get_context_dict()により、何行目の実行データ(line_number)なのか、どのジョブ(root_run_id)なのかを取得しています。
これらの情報を元にMLflowのcreate_runメソッドにて、マニュアルで親run_idを指定し子ジョブを作成しています。
なおAzure AIプロジェクトにて実行する場合はMLFLOW_TRACKING_URIにAzure AIハブのものが設定されているので、マニュアルで設定する必要があります。
(24年4月時点では公式なAPIから取得する方法が見つからず、内部のAPIを実行しているためバージョンアップ等により利用できなくなる可能性がある点に注意ください)
from promptflow import tool
from mlflow import MlflowClient
from mlflow.utils.mlflow_tags import MLFLOW_PARENT_RUN_ID
from promptflow.tracing._operation_context import OperationContext
@tool
def initialize_mlflow() -> str:
# 評価時のみ実行
context = OperationContext.get_instance().get_context_dict()
if "line_number" not in context["_otel_attributes"]:
return None
# Azure AI上の場合は、以下のコメントアウトを解除してください。
# import os
# provider_config = os.environ["CONNECTION_PROVIDER_CONFIG"]
# tracking_uri = os.environ["MLFLOW_TRACKING_URI"]
# tracking_uri = provider_config.replace("azureml://", tracking_uri[:tracking_uri.find("subscriptions")])
# mlflow.set_tracking_uri(tracking_uri)
client = MlflowClient()
run = client.get_run(run_id=context["root_run_id"])
# 各実行は子ジョブを作成する
line_number = context["_otel_attributes"]["line_number"]
child_run = client.create_run(run.info.experiment_id, run_name=f"Run {int(line_number):09}", tags= {"framework": "Prompt Flow", MLFLOW_PARENT_RUN_ID: run.info.run_id})
return child_run.info.run_id
save_mlflow_trackingノード
save_mlflow_trackingノードですが、こちらは少し複雑になっており、LLMノードの実行結果を前述の「debug_info」から取得し、MLflowのメトリック/パラメータとして記録し直しています。
get_run_info、get_output_asset_id、get_asset_path処理は、PromptFlowの実行結果の出力タブ中に表示されている「エクスポート」の「データ エクスポート スクリプトのダウンロード」から取得できるノートブック中の処理を一部修正しています。
それぞれ実施している処理概要は以下の通りです。
-
get_output_asset_idにて「debug_info」のasset_idを取得 -
get_asset_pathにてストレージアカウント上の保存パスを取得 -
get_node_resultで、上記で保存したパスとノード名、実行データ行(line_number)によりBlobファイルパスを作成し、結果データ(JSON)をダウンロード - 結果データ中にある入出力情報とメトリックをMLflowのロギングAPIを用いて記録
from promptflow import tool
import logging
import requests
import json
from pathlib import Path
from azureml.core import Workspace
from mlflow import MlflowClient
from promptflow.tracing._operation_context import OperationContext
logger = logging.getLogger("myLogger")
def get_workspace(context: dict) -> Workspace:
from azureml.core.authentication import MsiAuthentication
return Workspace.get(
name=context["workspace_name"],
subscription_id=context["subscription_id"],
resource_group=context["resource_group"],
auth=MsiAuthentication()
)
def get_run_info(ws: Workspace, run_id: str):
logger.info(f"Getting Run Info for Run: {run_id}")
run = ws.get_run(run_id=run_id)
display_name = run.display_name
input_run_id = run.properties.get('azureml.promptflow.input_run_id')
return display_name, input_run_id
def get_output_asset_id(ws: Workspace, run_id: str, asset_name: str):
logger.info(f"Getting Output Asset Id for Run {run_id}")
if ws.location == "centraluseuap":
url = f"https://int.api.azureml-test.ms/history/v1.0/subscriptions/{ws.subscription_id}/resourceGroups/{ws.resource_group}/providers/Microsoft.MachineLearningServices/workspaces/{ws.name}/rundata"
else:
url = f"https://ml.azure.com/api/{ws.location}/history/v1.0/subscriptions/{ws.subscription_id}/resourceGroups/{ws.resource_group}/providers/Microsoft.MachineLearningServices/workspaces/{ws.name}/rundata"
payload = {
"runId": run_id,
"selectRunMetadata": True
}
response = requests.post(url, json=payload, headers=ws._auth.get_authentication_header())
if response.status_code != 200:
raise Exception(f"Failed to get output asset id for run {run_id} because RunHistory API returned status code {response.status_code}. Response: {response.text}")
output_asset_id = response.json()["runMetadata"]["outputs"][asset_name]["assetId"]
return output_asset_id
def get_asset_path(ws: Workspace, asset_id):
logger.info(f"Getting Asset Path for Asset Id {asset_id}")
if ws.location == "centraluseuap":
url = f"https://int.api.azureml-test.ms/data/v1.0/subscriptions/{ws.subscription_id}/resourceGroups/{ws.resource_group}/providers/Microsoft.MachineLearningServices/workspaces/{ws.name}/dataversion/getByAssetId"
else:
url = f"https://ml.azure.com/api/{ws.location}/data/v1.0/subscriptions/{ws.subscription_id}/resourceGroups/{ws.resource_group}/providers/Microsoft.MachineLearningServices/workspaces/{ws.name}/dataversion/getByAssetId"
payload = {
"value": asset_id,
}
response = requests.post(url, json=payload, headers=ws._auth.get_authentication_header())
if response.status_code != 200:
raise Exception(f"Failed to get asset path for asset id {asset_id} because Data API returned status code {response.status_code}. Response: {response.text}")
data_uri = response.json()["dataVersion"]["dataUri"]
relative_path = data_uri.split("/paths/")[-1]
return relative_path
def get_node_result(ws: Workspace, run_id: str, node_name: str, line_number: str) -> str:
logger.info(f"Getting Node Artifact Relative Path for Run {run_id}")
flow_artifact_asset_id = get_output_asset_id(ws, run_id, "debug_info")
relative_path = get_asset_path(ws, flow_artifact_asset_id)
relative_path += f"node_artifacts/{node_name}/{int(line_number):09}.jsonl"
from azureml.data.azure_storage_datastore import AzureBlobDatastore
datastore:AzureBlobDatastore = ws.get_default_datastore()
client = datastore.blob_service.get_container_client(container=datastore.container_name)
blob_client = client.get_blob_client(relative_path)
return blob_client.download_blob().readall()
@tool
def save_single(result: str, child_run_id: str) -> str:
context = OperationContext.get_instance().get_context_dict()
run_id = context["root_run_id"]
if "line_number" in context["_otel_attributes"]:
line_number = context["_otel_attributes"]["line_number"]
ws = get_workspace(context)
display_name, input_run_id = get_run_info(ws, run_id)
node_result = json.loads(get_node_result(ws, run_id, "joke", line_number))
info = node_result["run_info"]
client = MlflowClient()
client.log_param(child_run_id, "run_display_name", display_name)
client.log_param(child_run_id, "input_temperature", info["inputs"]["temperature"])
client.log_param(child_run_id, "input_top_p", info["inputs"]["top_p"])
client.log_param(child_run_id, "input_max_tokens", info["inputs"]["max_tokens"])
client.log_param(child_run_id, "input_topic", info["inputs"]["topic"])
client.log_param(child_run_id, "output", info["output"])
client.log_metric(child_run_id, "completion_tokens", info["system_metrics"]["completion_tokens"])
client.log_metric(child_run_id, "prompt_tokens", info["system_metrics"]["prompt_tokens"])
client.log_metric(child_run_id, "total_tokens", info["system_metrics"]["total_tokens"])
client.log_metric(child_run_id, "duration", info["system_metrics"]["duration"])
return result
finalizeノード
finalizeノードでは、作成した子ジョブをMLflow完了させる処理を記載しています。
※ここではサンプルなので異常終了時については考慮していません。必要に応じてstatusをFAILED等に設定してください。
from promptflow import tool
from mlflow import MlflowClient
@tool
def aggregate(result: str, child_run_id: str):
client = MlflowClient()
# 子ジョブを完了する
if child_run_id:
client.set_terminated(child_run_id, "FINISHED")
return result
実行結果
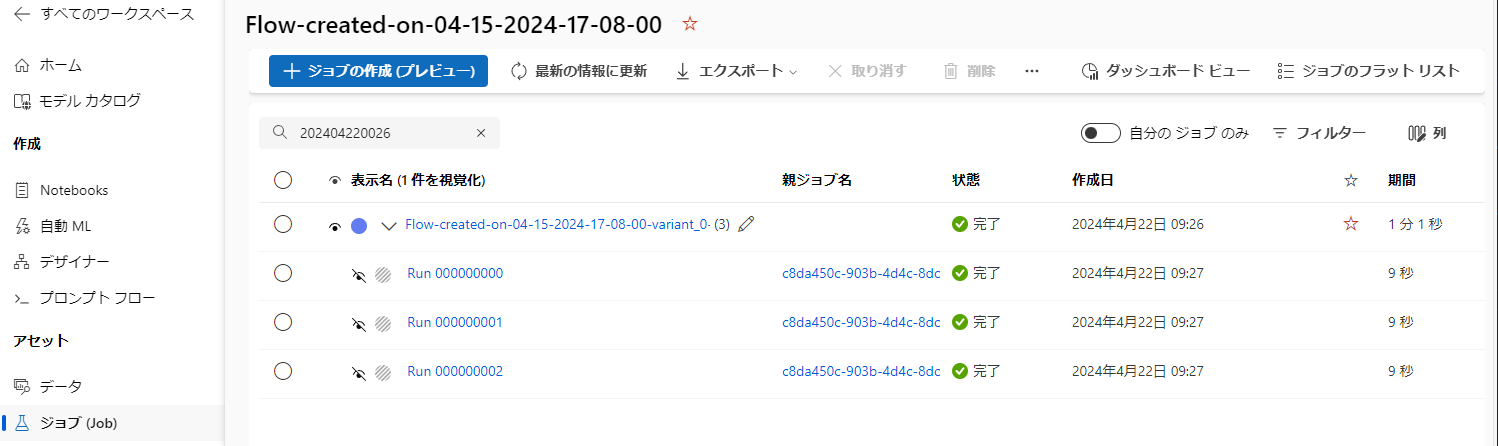
上記のPromptFlowを3行のサンプルデータにて評価を実行した結果のAzure ML Studioにおけるジョブビューは以下の通りとなります。
このジョブビューは、Azure AI Studio上では表示されないため、表示する場合はAzure ML Studioにて実施してください。
もし階層表示になっていない場合は画面右上の「ジョブのツリー」ボタンをクリックしビューを切り替えてください。
なおPromptFlow画面の「バッチ実行の表示」から表示される画面では子ジョブが表示されないのでご注意ください。
また以下は子ジョブのみ表示するように設定したダッシュボードビューの比較テーブルです。
各実行結果と各メトリックの変化が分かりやすく表示されていることが出来ました。
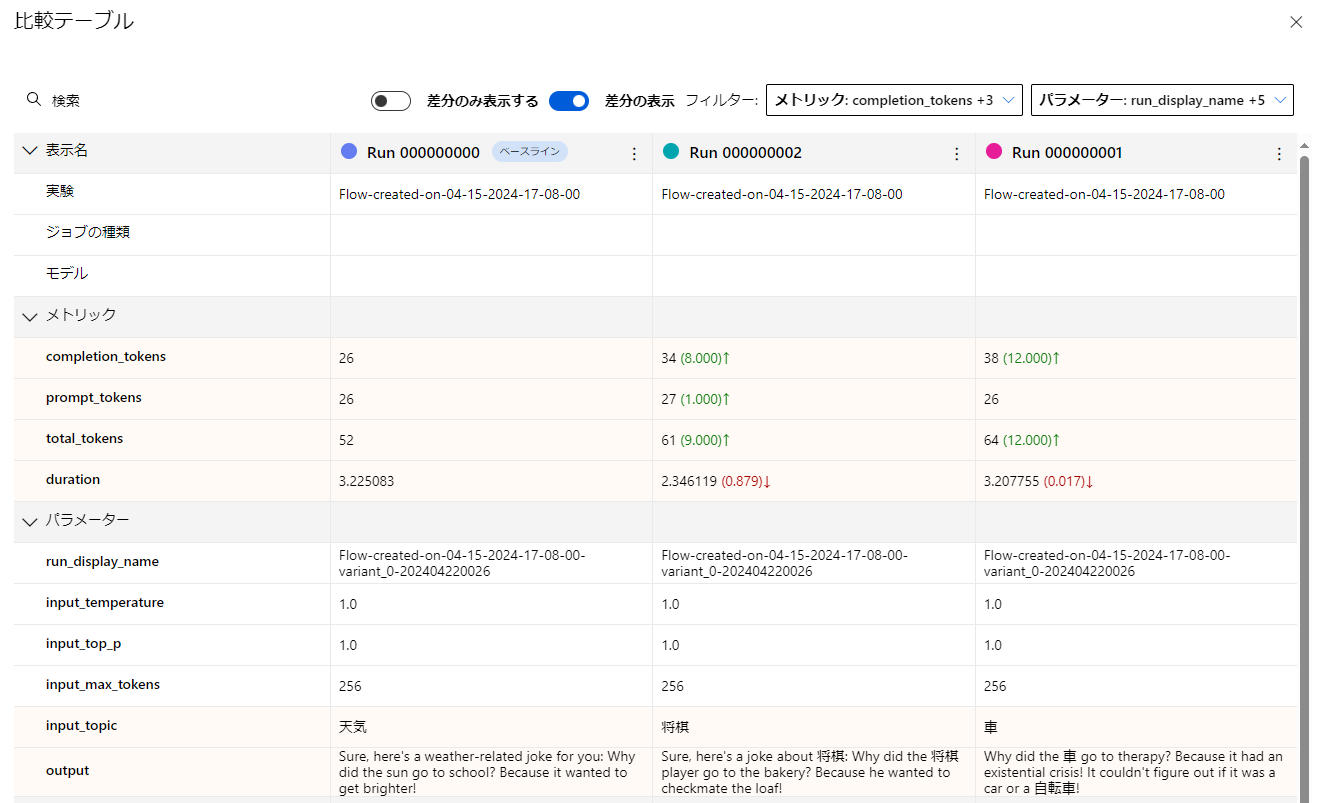
今回はサンプルとしてPromptFlowのジョブに対して紐づけるように作成しましたが、initialize_mlflowを変更し、独自に実験を作成、そこにメトリックを記録していくことも可能です。
この際の注意点として、以下の2点があります。
- 標準フローでは上記のような評価に対して子ジョブを紐づけるといった構成は基本不可。
各実行を子ジョブでグループ化したい場合は評価フローにて作成しAggregationノードで終了処理等を記述する必要がある。 - 上記の場合でも評価実行時にはフローが同時実行されるため、親ジョブを作成する際はセマフォ等で同時実行制御をする必要がある。
最後に
今回、PromptFlowの組み込み方式ではなくMLflowを使ってメトリックを収集する方法をご紹介いたしました。
残念ながら2024年4月末時点では正式なAPIが見つからず、非公式な方法でのジョブID等の取得とデータ収集を実施し、またPromptFlow画面上から実行した場合やデプロイした場合については、実行結果がBlobストレージ上に出力されないため取得する方法を見つけることが出来ませんでした。
現在PromptFlowは絶賛開発中で、今後のエンハンスで実行結果の収集や可視化・分析機能が強化され上記のような処理が不要になるかもしれませんが、その間の補足としてご活用頂ければ幸いです。
関連記事
(1) Azure ML & MLflowで可視化: Azure ML StudioとMLflow Trackingによるデータ収集・可視化の紹介
(2) PromptFlowログの可視化:Azure AI/ML Studio & MLflowと連携し収集・可視化する (本記事)
(3) RAG実施時の検索エンジン(Azure AI Search)精度指標の検討 (※記載中)