初めに
PythonのPandasについて初学者なりにまとめたいと思います。
学習に使っているのはこちらのキノコードです。
JupyterLabを使用します。
使用するExcelファイル
こちらをリンク先を保存してローカルに落として利用しています。
データ集計
前準備
jupyterlabを起動し、エクセルファイルをカレントディレクトリに格納。Pandasをimportし、表示数を変更します。
その後、read_excelで読み込みます。

pivot_tableの基本
pivot_tableメソッドにindex,columns,values, aggfuncを渡します。
この時、columnsを渡さなかった場合はgroupbyと同じような挙動になります。
aggfuncに何も渡さなかった場合、デフォルトではmean(平均)が算出されます。
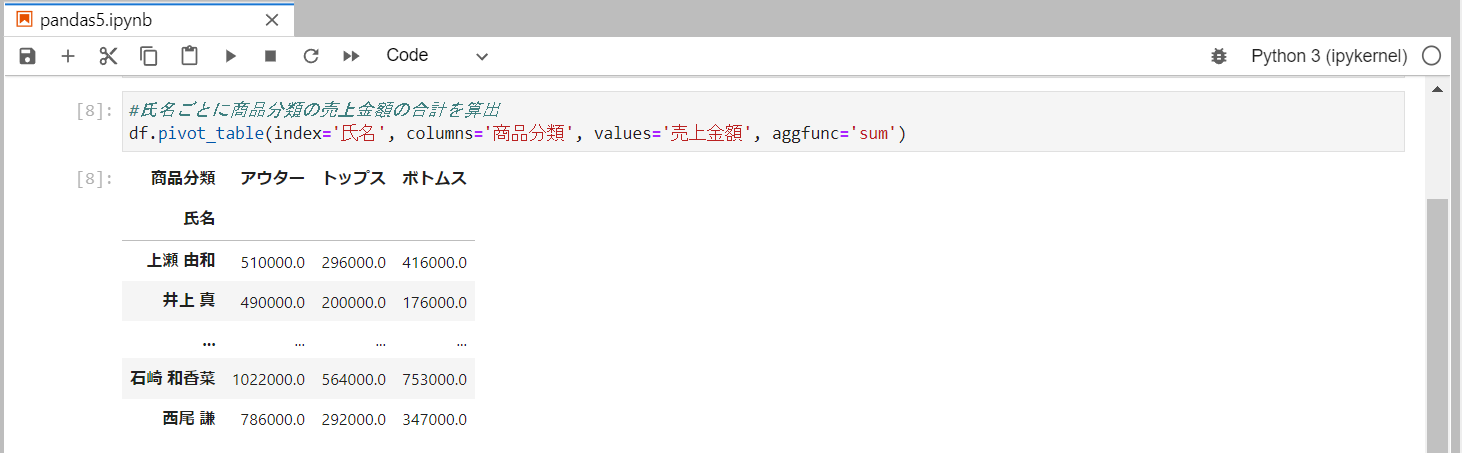
氏名ごとに商品分類ごとの売上金額の合計を算出
aggfuncに'sum'を渡します。
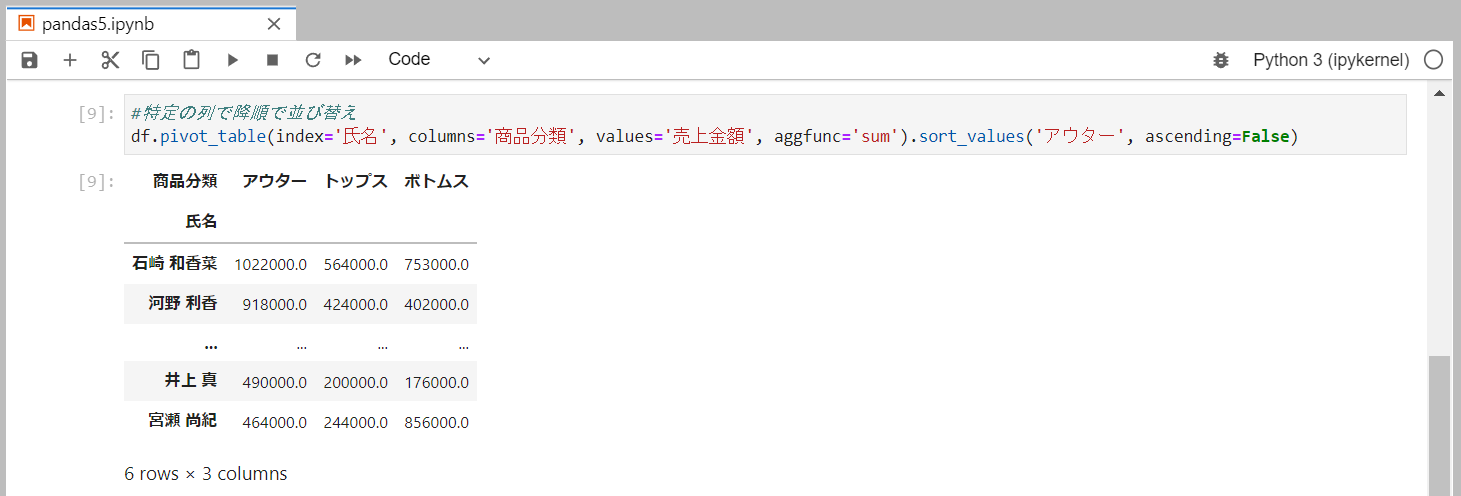
特定の列で並び替え
pivot_tableに対してsort_valuesを使用します。
降順で指定する場合はascending=Falseを指定します。
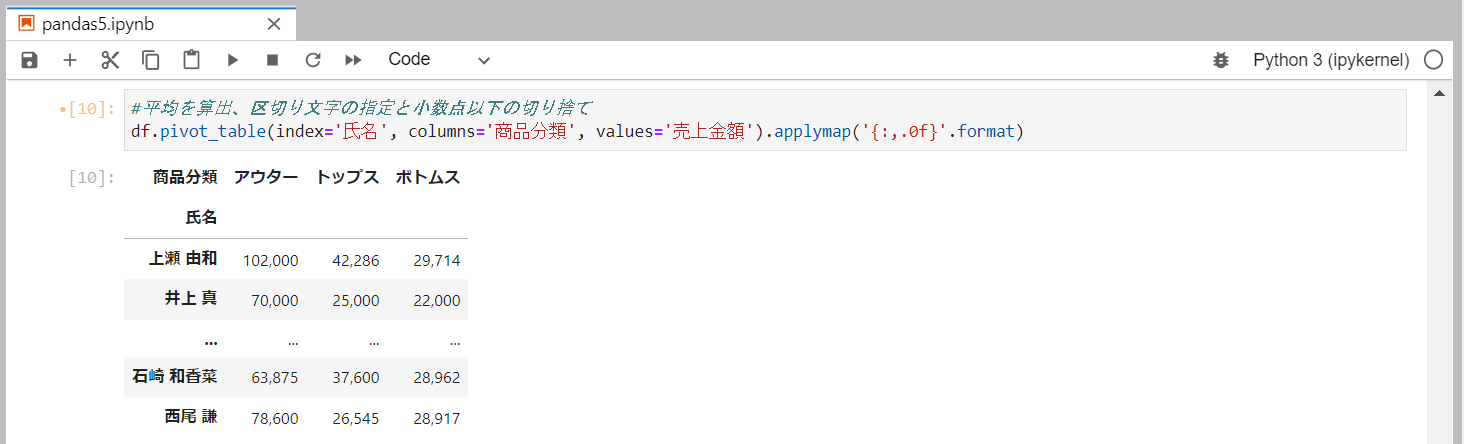
氏名ごとに商品分類ごとの売上金額の平均を算出
aggfuncに'mean'を渡します。ただ、デフォルトで'mean'になっているので、明示的に指定しても、省略してもOKです。今回、小数点以下の切り捨てと区切り文字の指定も同時に行います。
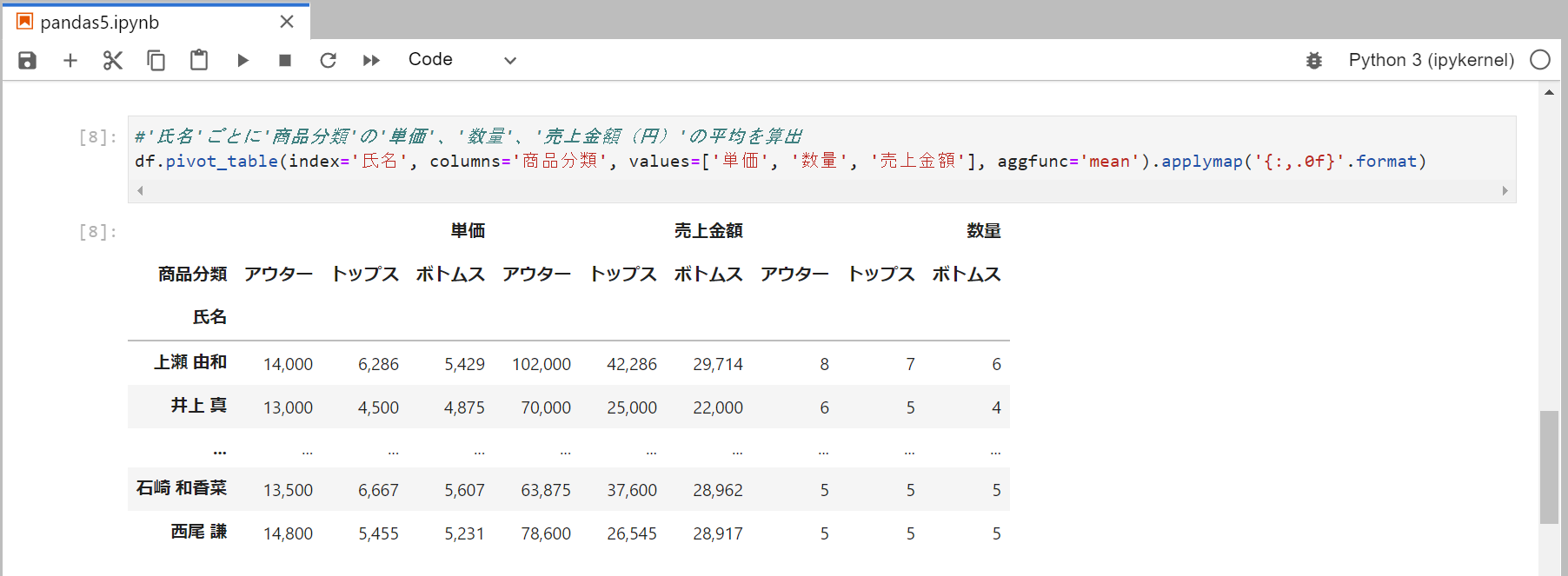
氏名ごとに商品分類の単価、数量、売上金額の平均を算出
集計するデータが複数ある場合には、リストで指定します。
複数インデックスの場合も同じくリストで渡す。
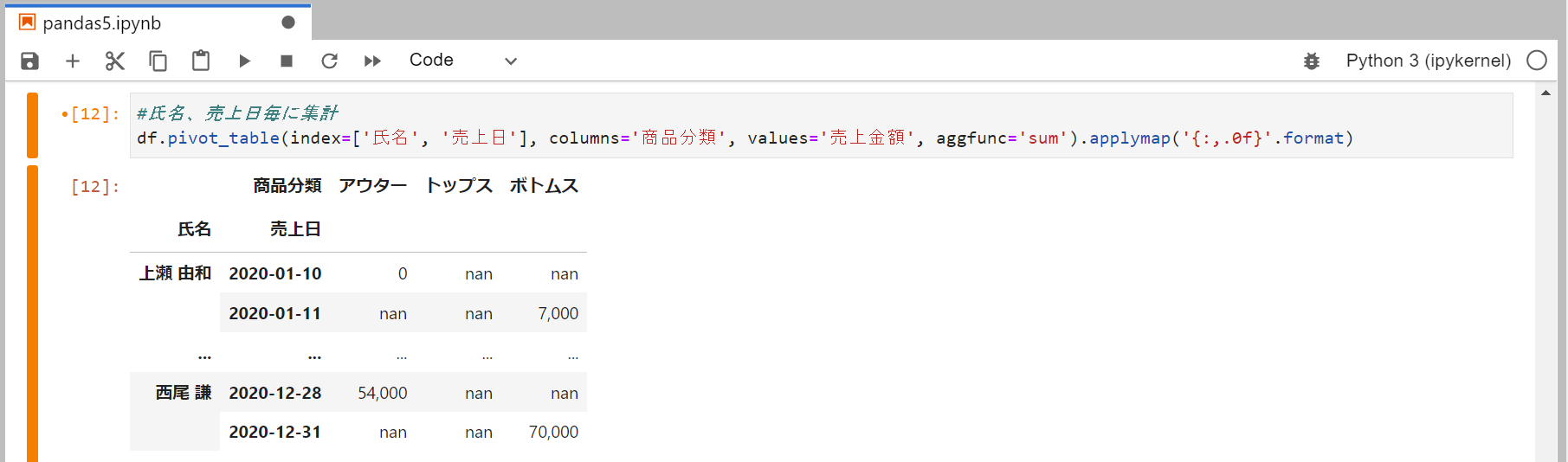
欠損値の処理
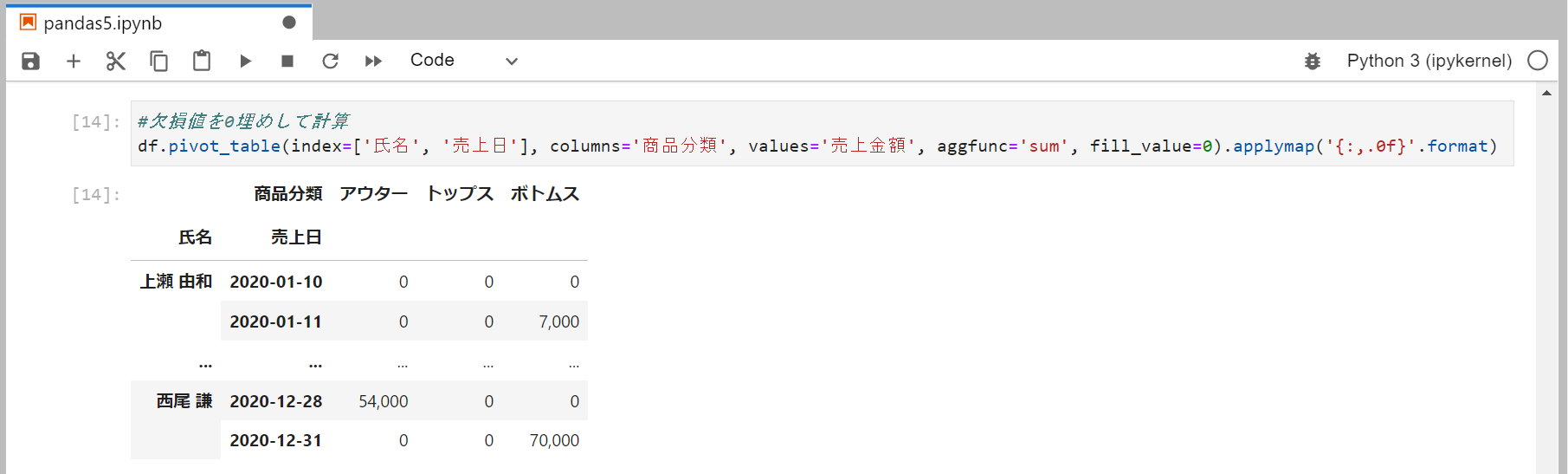
fill_value=0を指定することでNanを0として扱う
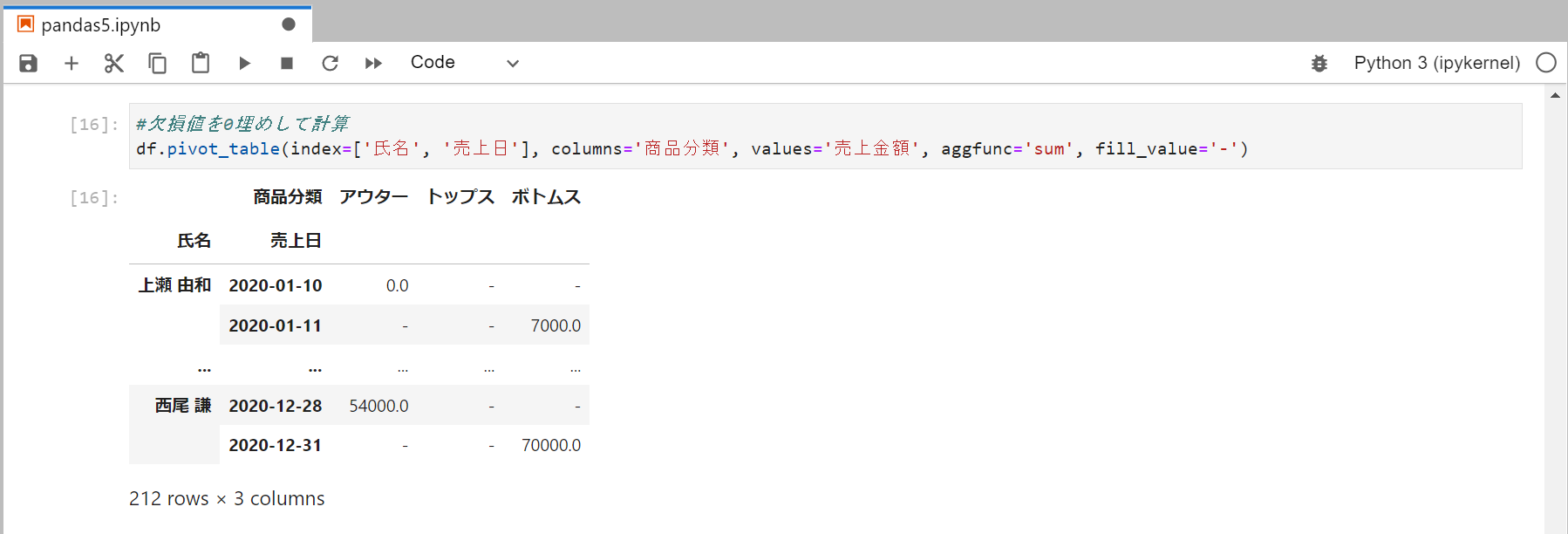
文字列を指定することも可能
集計行列の追加
margins=Trueを引数に追加します。

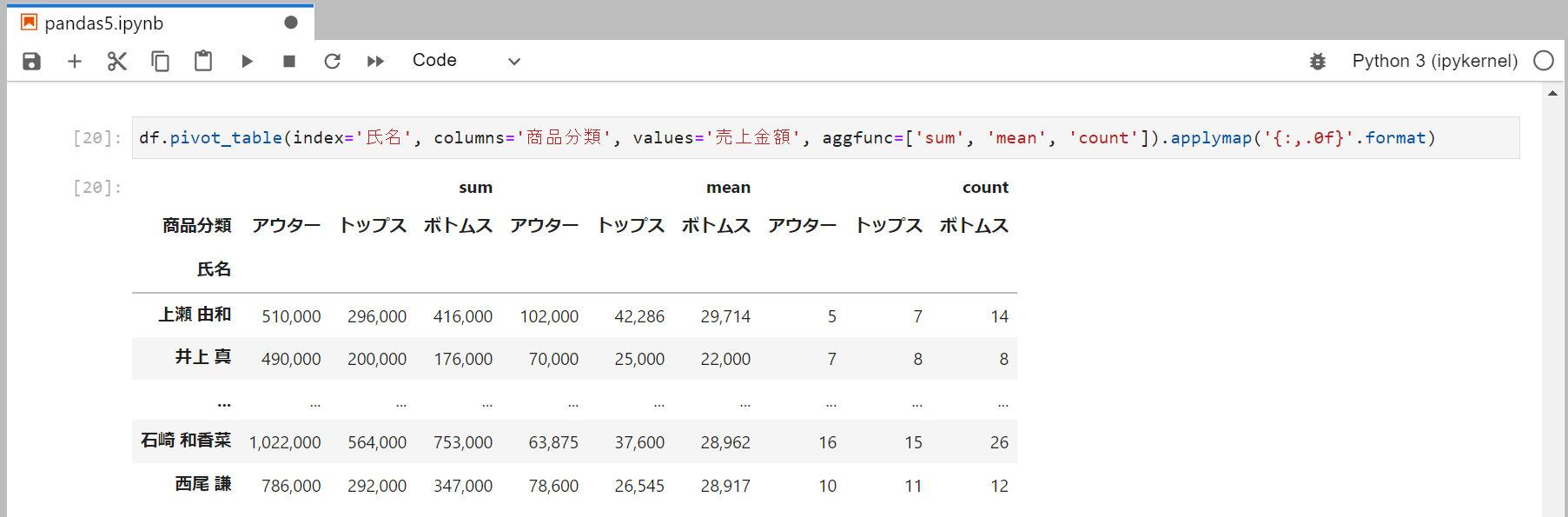
複数の集計
合計、平均、個数などを同時に集計することもできます。
aggfuncに集計方法のメソッドをリストで渡します。
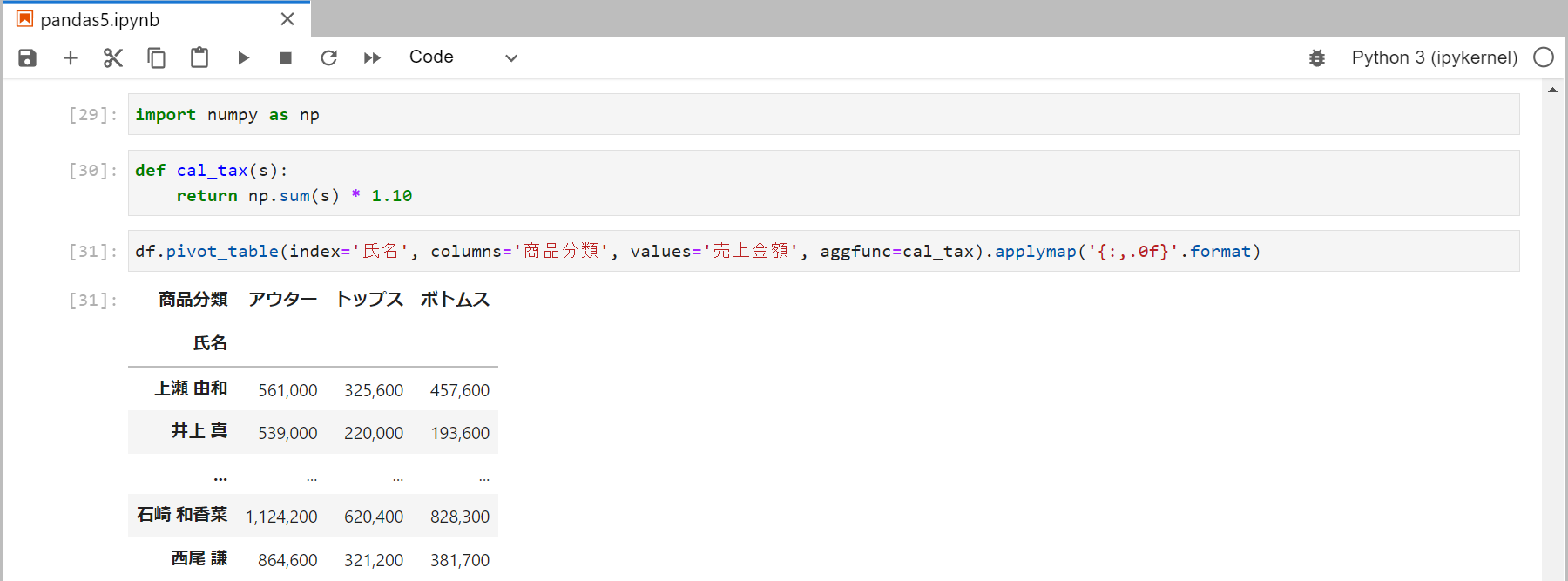
自作関数での集計
消費税10%を加算する場合
関数を定義し、aggfuncに関数を渡すことで自作関数で集計できる
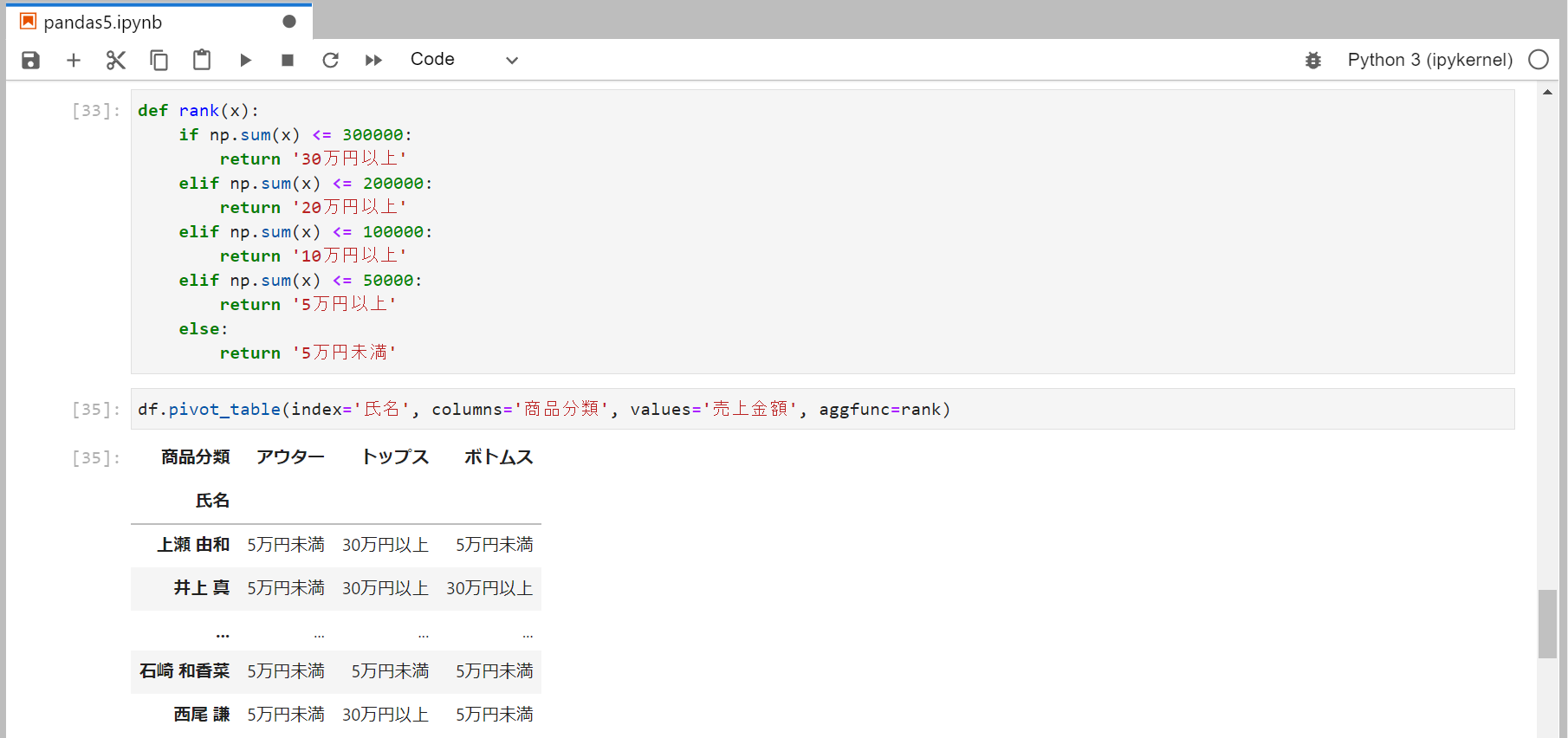
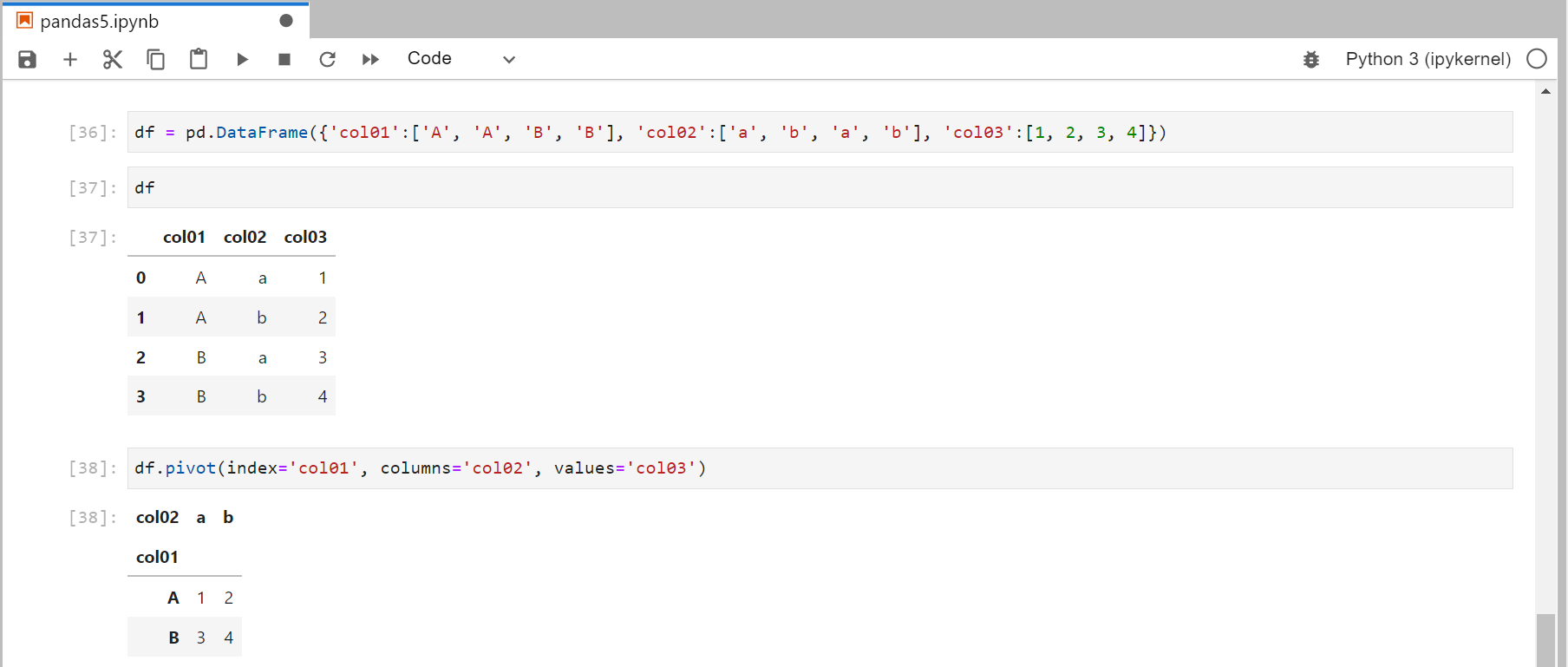
文字列の集計
pivot_tableではなく、pivotメソッドを使えば文字列の集計ができる
終わり
ピボットテーブルはエクセルでお世話になっているのでPythonでも似たような集計ができるのはありがたいです。