初めに
PythonのPandasについて初学者なりにまとめたいと思います。
学習に使っているのはこちらのキノコードです。
JupyterLabを使用します。
使用するExcelファイル
こちらをリンク先を保存してローカルに落として利用しています。
データ集計
前準備
jupyterlabを起動し、エクセルファイルをカレントディレクトリに格納。Pandasをimportし、表示数を変更します。
その後、read_excelで読み込みます。

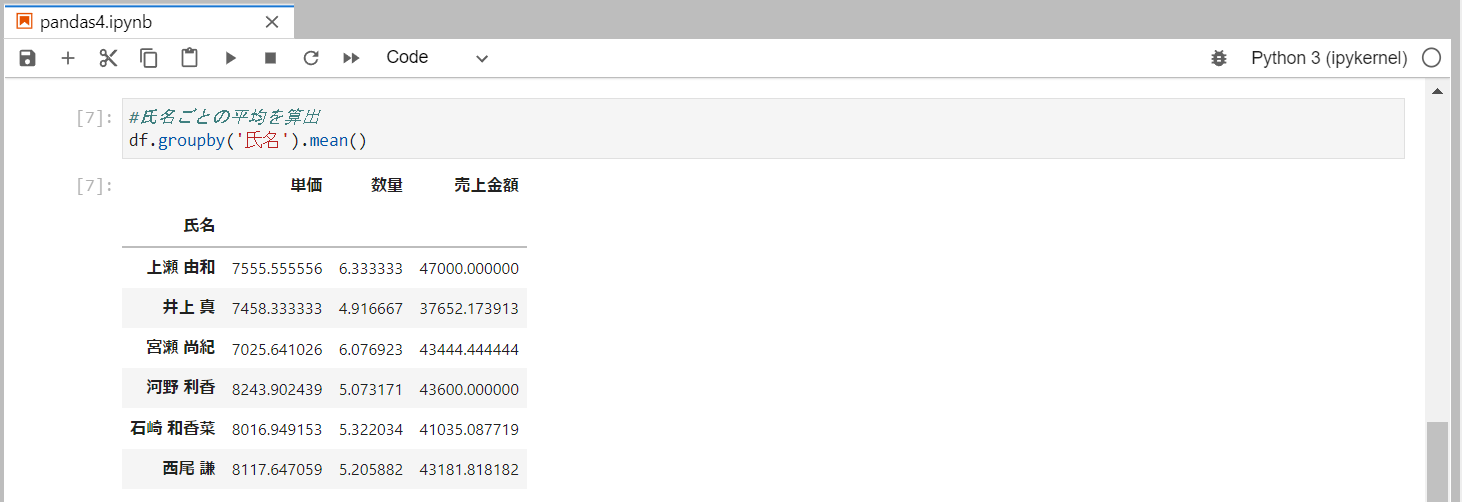
氏名ごとの平均を算出
groupbyメソッドを使用することで、指定のカラムごとにデータをまとめたGroupByオブジェクトを作成することができます。
平均の集計にはmeanメソッドを使用します。
氏名ごとの売上金額のみ平均を算出
氏名と売上金額のみのデータフレームを作成して平均を抽出します。
データフレームから任意のカラムを抽出して、新たなデータフレームを作成するには下記のように記述します。
データフレームオブジェクト[抽出したいカラム名のリスト]

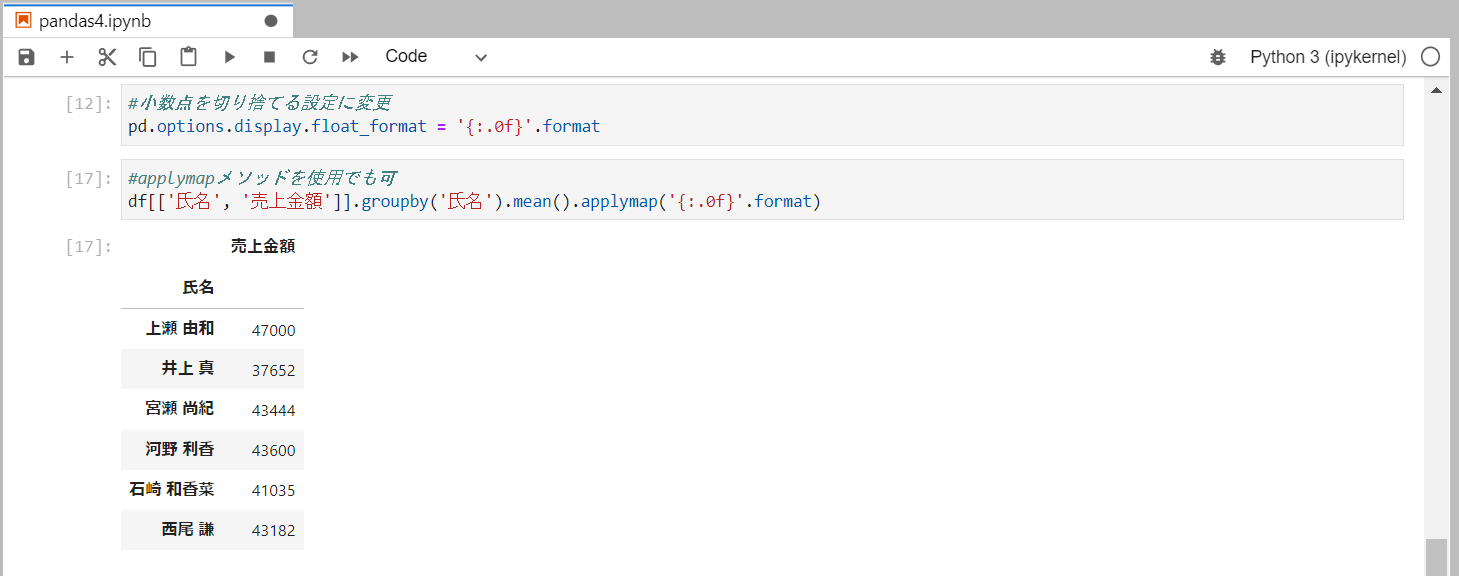
小数点以下を切り捨てて表示
小数点以下を非表示にするには、2通りの方法があります。
いずれもformatメソッドを使用しますが、適用方法が異なります。
・1つ目は、options属性で小数の書式を変更する方法です。
float_format属性に、formatメソッドの内容を代入します。
pd.options.display.float_format = '{:.0f}'.format
・2つ目は、applymapメソッドで適用させる方法です。
applymapメソッドの引数に、formatメソッドの内容を指定することにより、データフレームの各要素にformatメソッドで指定した書式が適用されます。
df[['氏名', '売上金額']].groupby('氏名').mean().applymap('{:.0f}'.format)
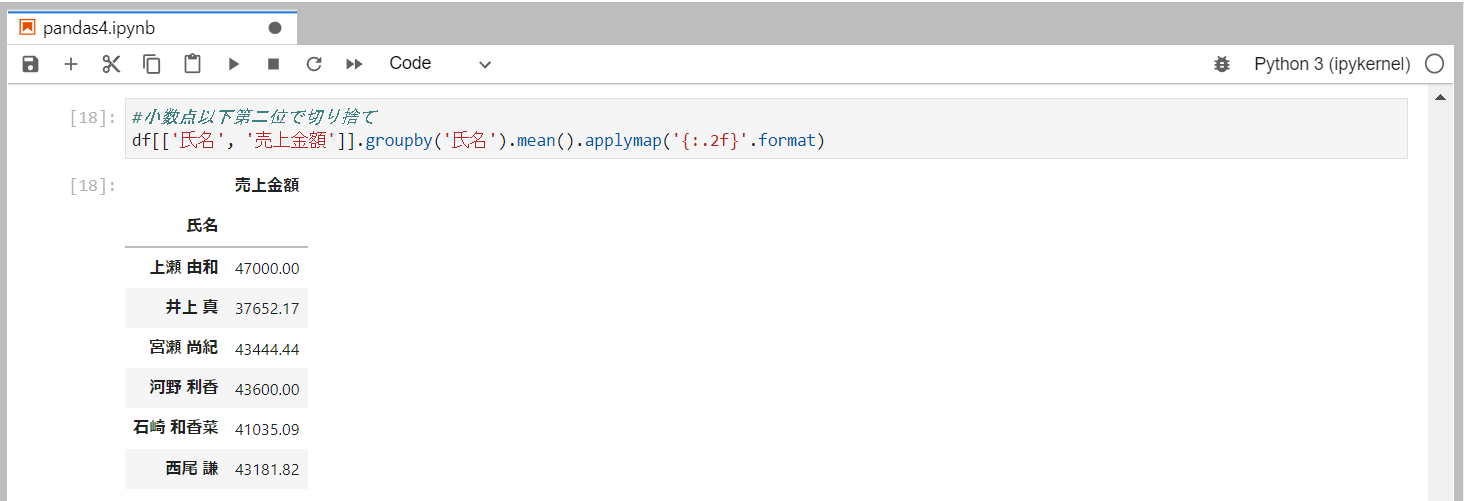
小数点以下2桁を切り捨て
formatメソッドでは、「:.小指数点以下の桁数f」で、小数点以下の桁数を設定することができます。
# 0桁
'{:.0f}'
# 2桁
'{:.2f}'
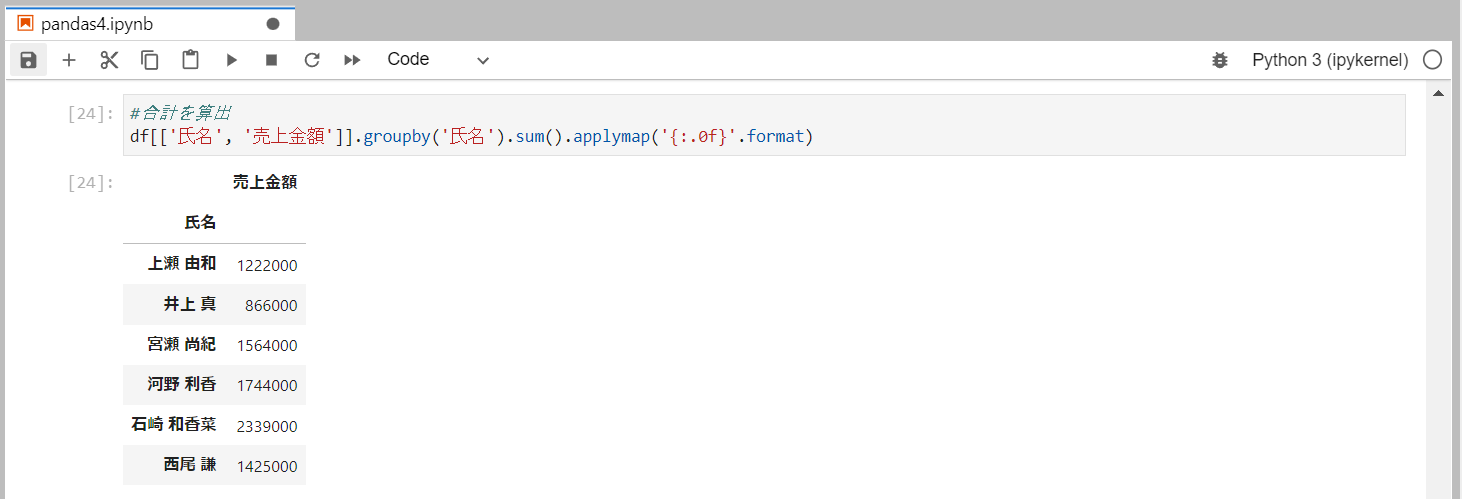
合計を算出
sumメソッドを使用します。
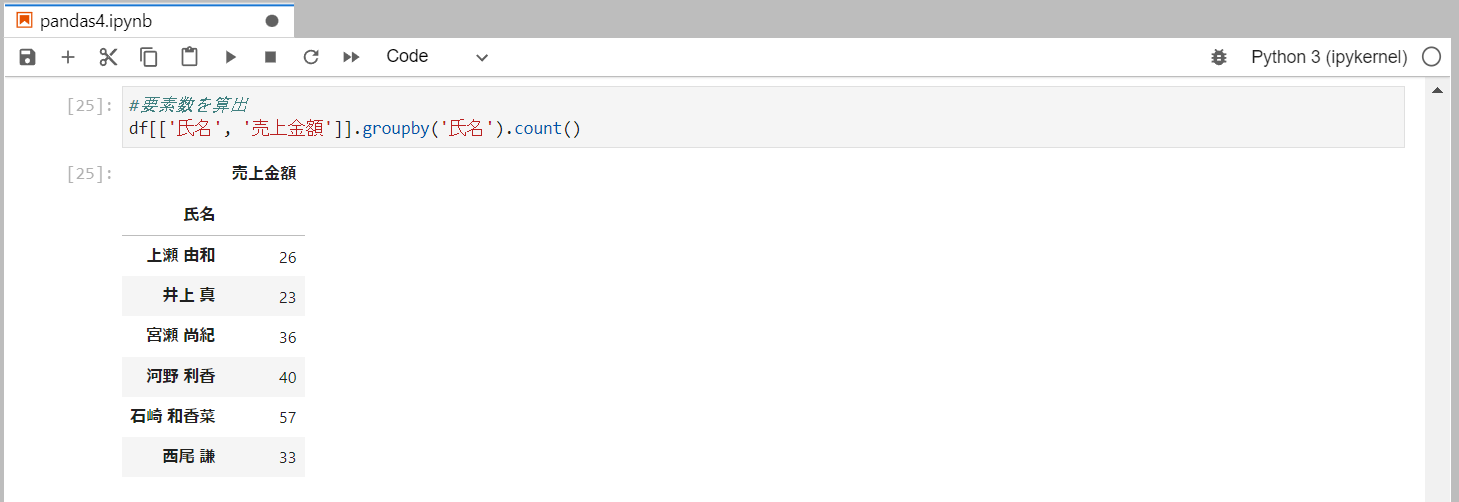
要素数を算出
countメソッドを使用します。
countメソッドは欠損値を除いた数を集計します。
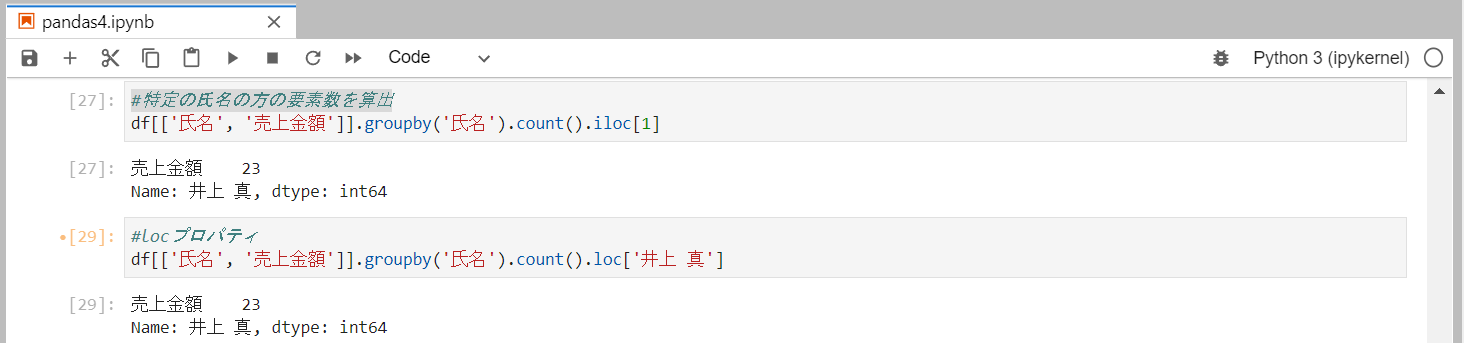
特定の要素数を算出
ilocまたはlocプロパティを使用すると、データフレームから指定の行や要素を抽出することができます。
角括弧内に行番号を指定すると、その行のデータをシリーズで取得することができます。
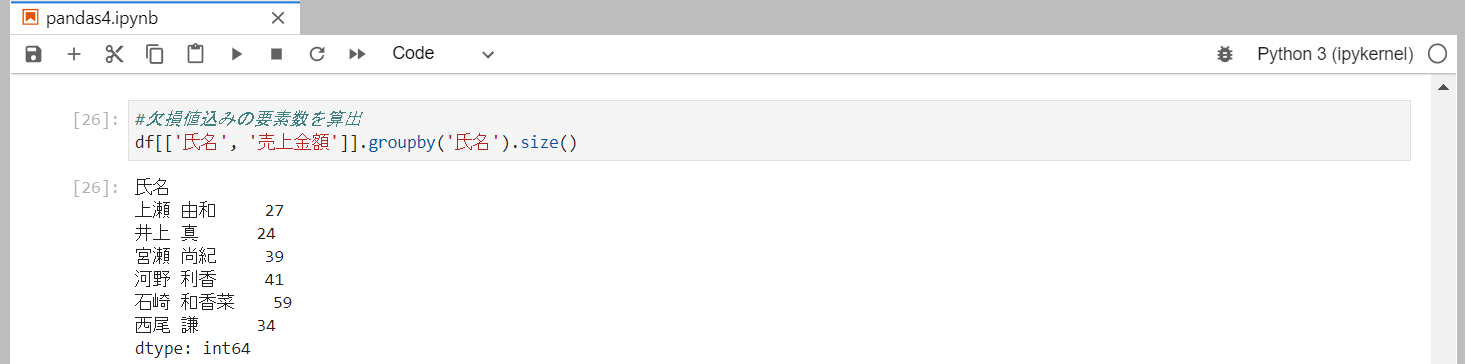
欠損値込みの要素数を算出
欠損値込みのデータフレームの要素数を集計するにはsizeメソッドを使用します。
sizeメソッドの取得結果は、シリーズで表示されます。
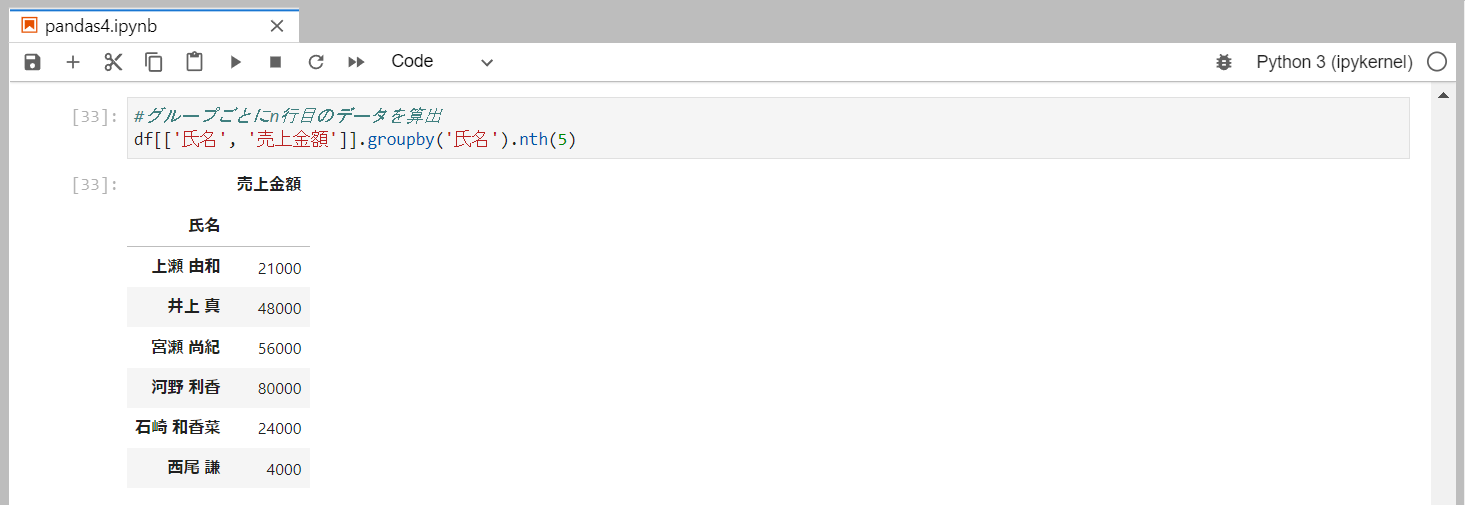
グループのn行目を抽出
グループごとにn行目のデータのみ取得するには、nthメソッドを使用します。
降順に並び替えかつn番目を抽出
dfをsort_valuesメソッドで降順に並び替え、nthメソッドを使用します。

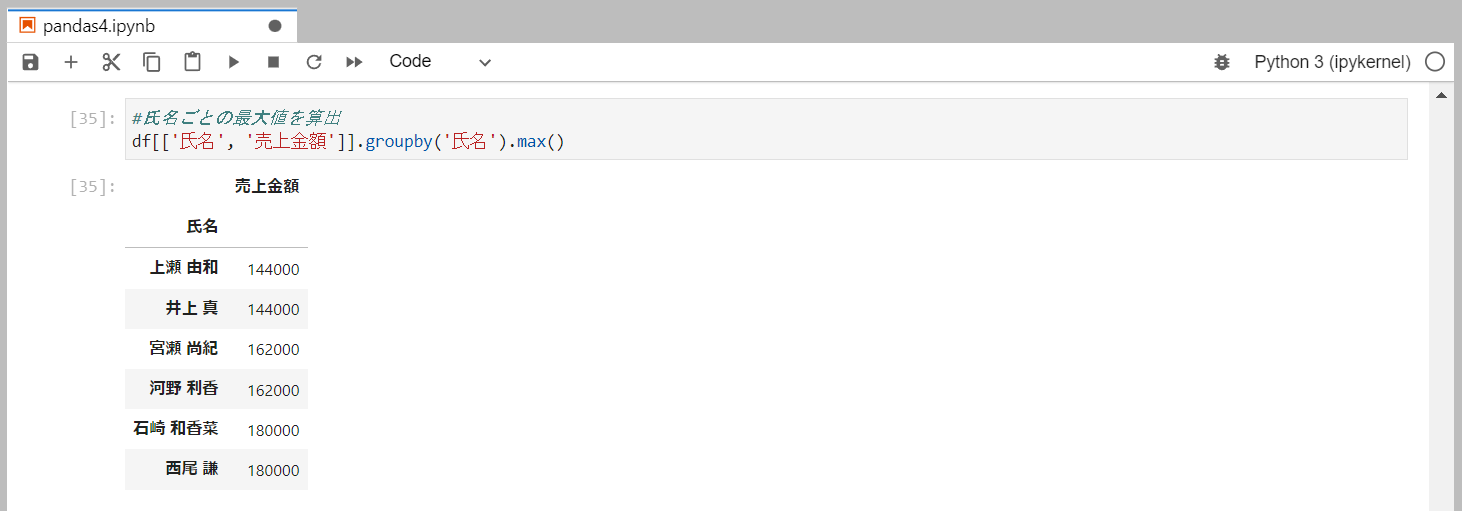
氏名ごとの最大値を抽出
最大値はmax()メソッドを使用します。
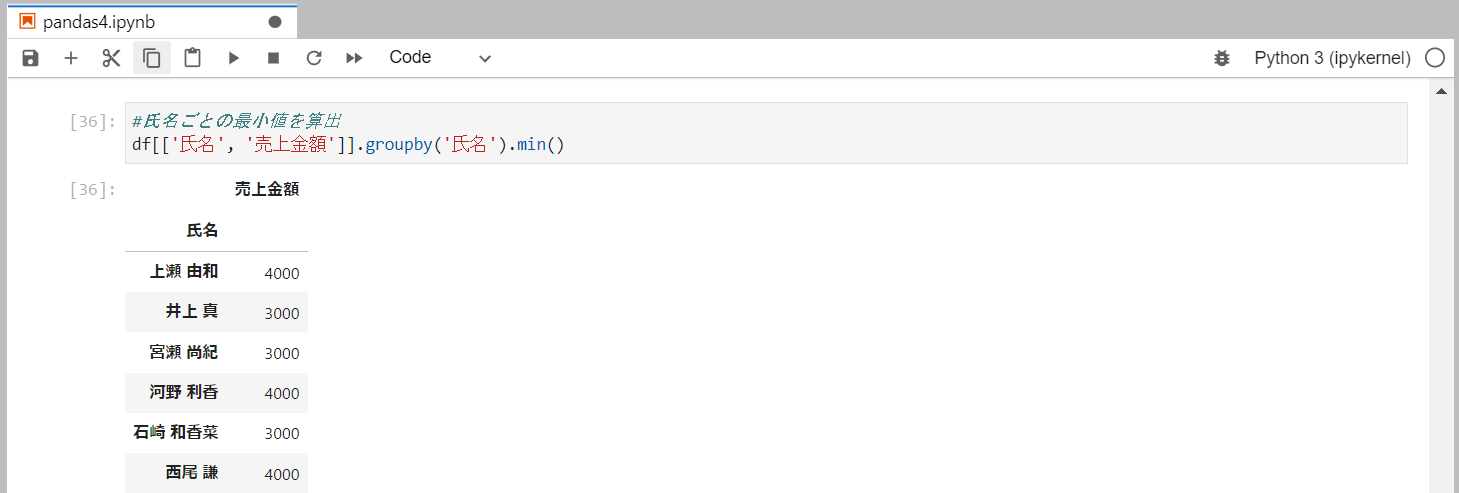
氏名ごとの最小値を抽出
最小値はmin()メソッドを使用します。
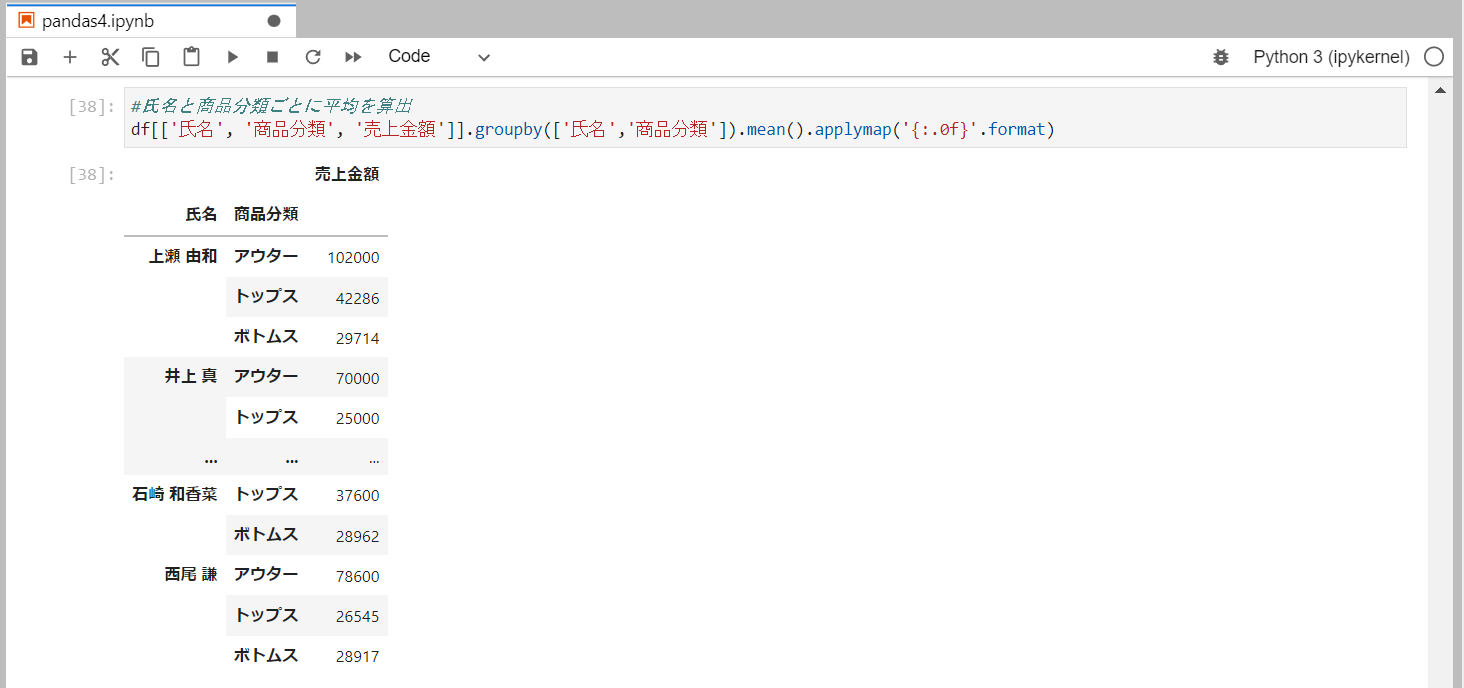
氏名と商品分類ごとに平均を算出
平均はmean()メソッドを使用します。
併せて小数点以下を切り捨てします。
マルチインデックスを解除する
複数のグルーピングを行うとマルチインデックスになります。
インデックスをグルーピングされたくない場合はgroupbyにas_index=Falseを指定します。

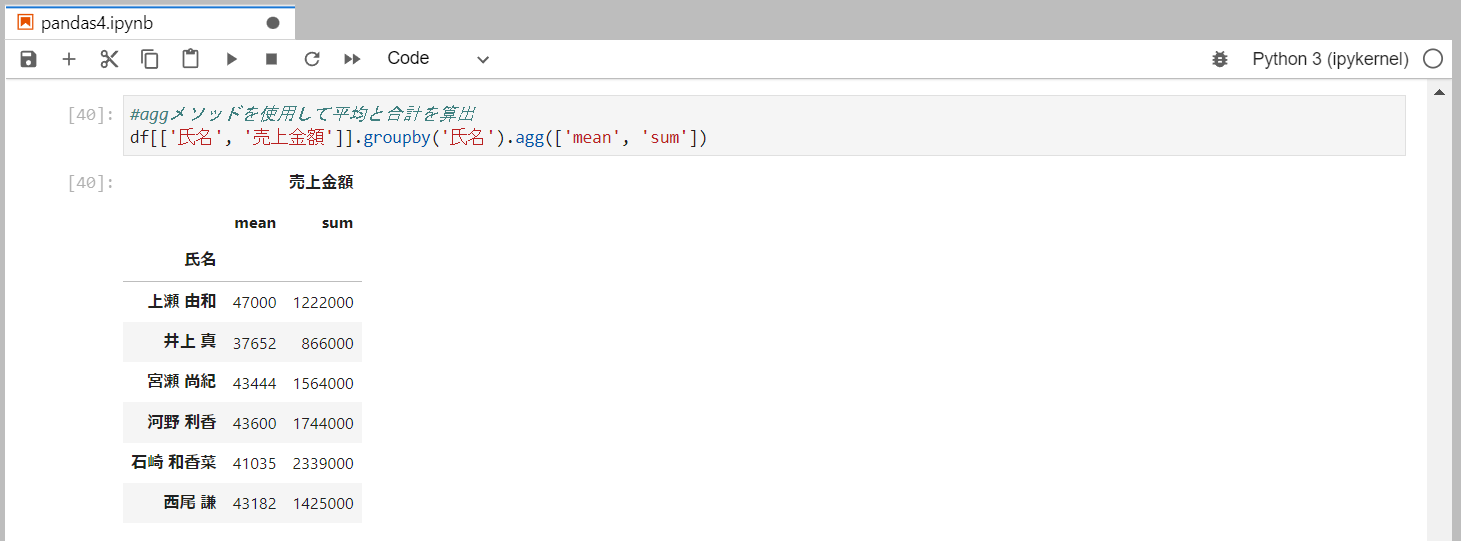
複数の集計を行うaggメソッド
複数の集計方法をまとめて行う場合には、aggメソッドを併せて使用します。
aggメソッドの引数に、集計方法をリストで指定します。
3桁ごとにカンマを振る
applymap()メソッドで'{:,.0f}'を指定します。

表示形式を変更する
桁区切り文字をアンダースコアに、小数点以下を1桁まで切り捨てをしてみます。

平均、合計、個数、最大値、最小値、標準偏差、分散を抽出
標準偏差はstd、分散はvarで抽出できます。

要約統計量を抽出
aggメソッドにdescribeを渡すことでようやく統計量を抽出できます。

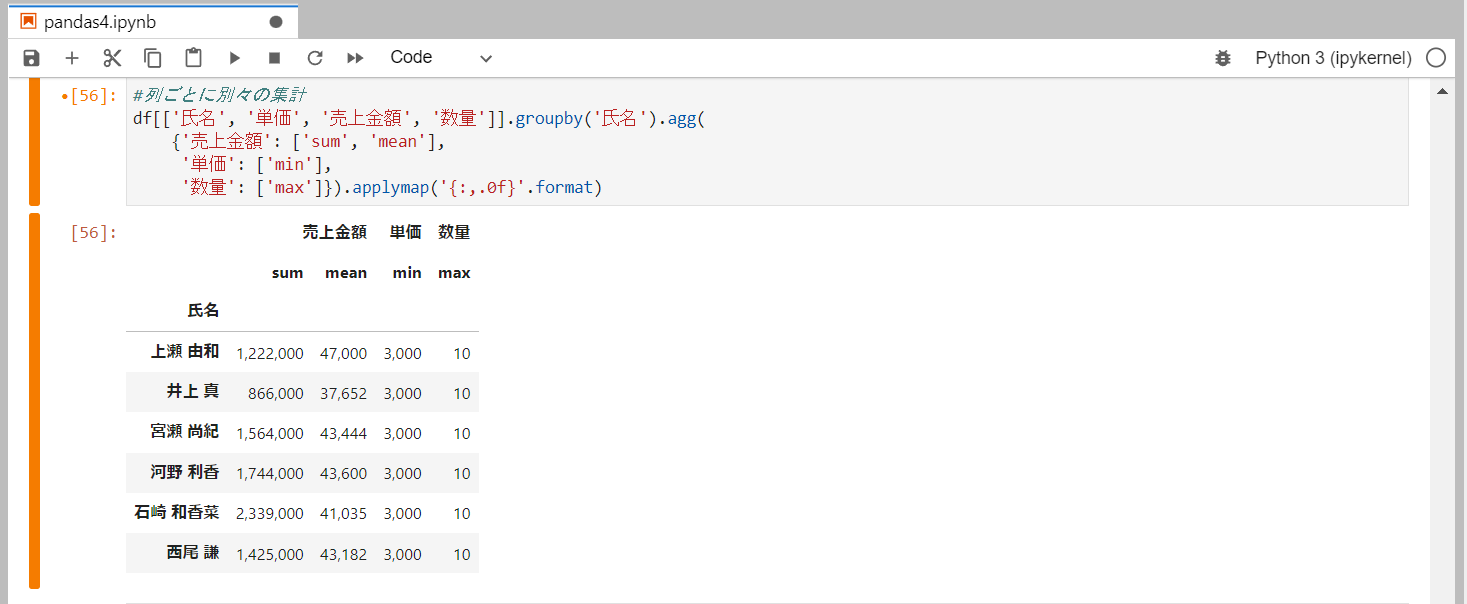
列ごとに別々に集計
aggメソッドに辞書型で{列名:[集計方法, 集計方法],列名: [集計方法, 集計方法]}と複数指定することができます。
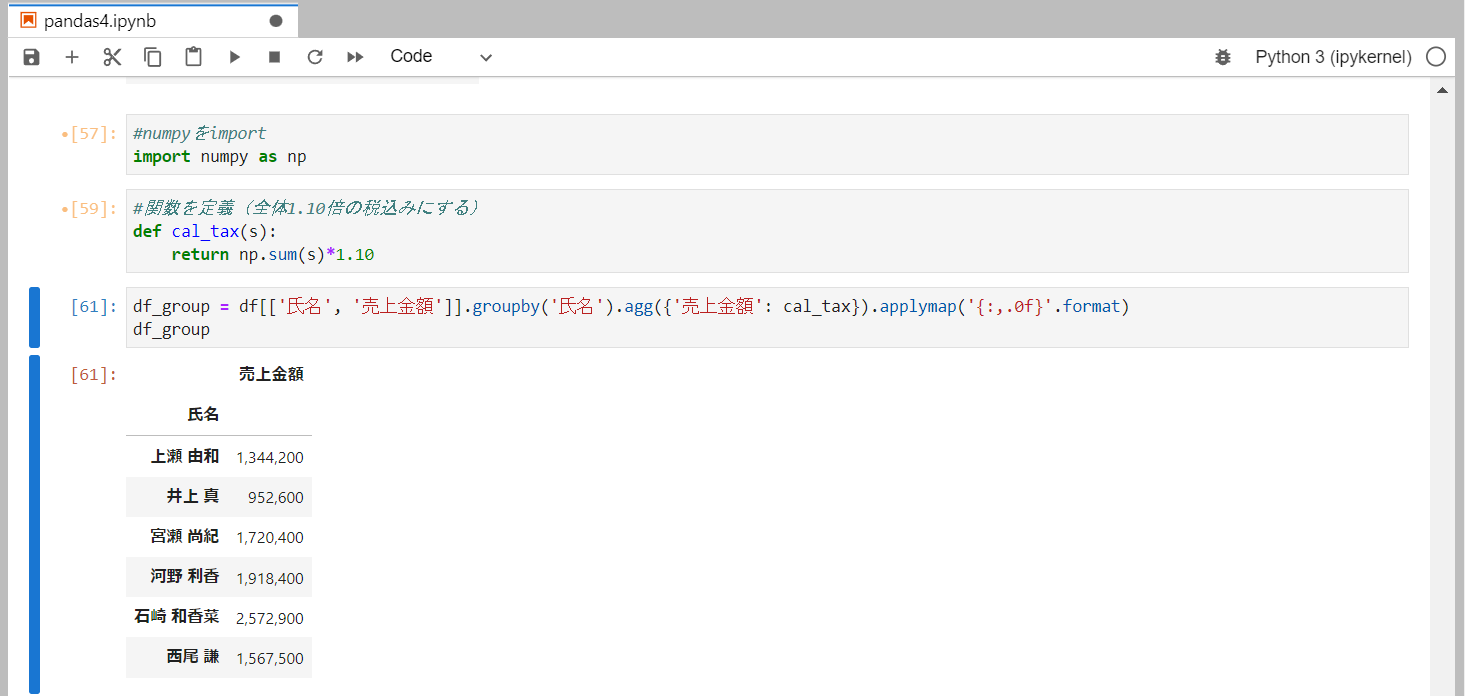
関数を使用して集計
売上金額を税込みで集計
終わり
groupbyだけでなくpivot_tableでの集計方法もあるのでそちらも学びたいと思います。
関連する過去の記事