初めに
pythonのpandasについて初学者なりにまとめたいと思います。
学習に使っているのはこちらのキノコードです。
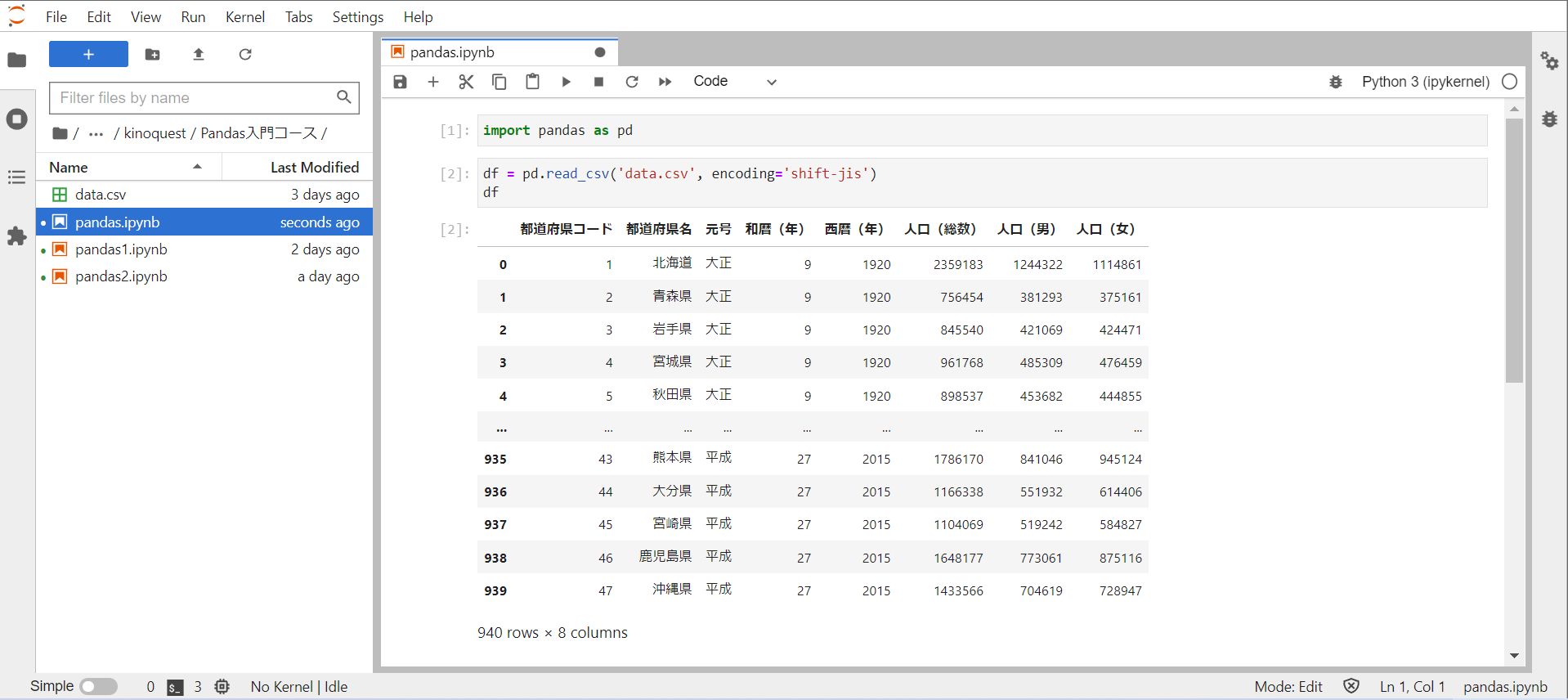
CSVファイル
読み込み
使用するCSVファイル
出典:政府統計の総合窓口(e-Stat)
「男女別人口-全国,都道府県(大正9年~平成27年)」(総務省)を加工して作成
csvファイルをデータフレームとして読み込むには、read_csv関数を使用します。
read_csv関数の引数に、読み込みたいcsvファイルのパスを指定します。
続いて、引数encodingに文字コードを渡すことで、ファイルを読み込む際の文字コードを指定することができます。
CSVファイルと同じ階層にPythonファイルを配置することでパスを省略できます。
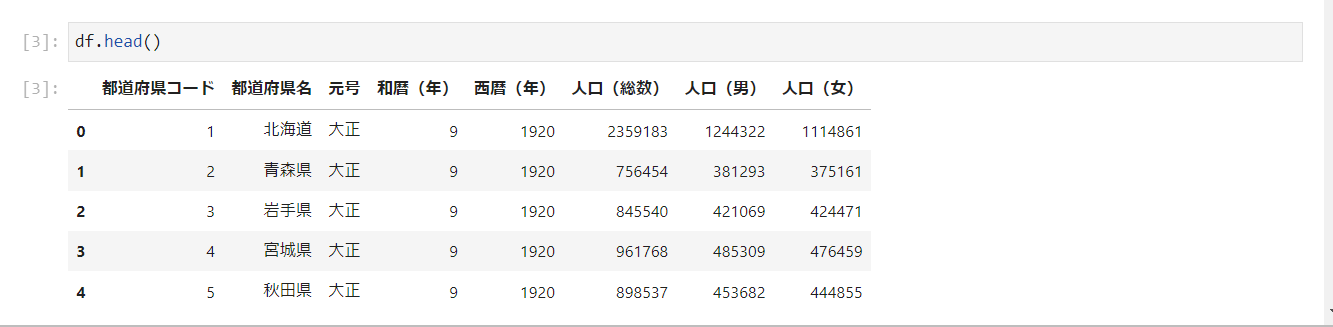
head/tail
haed()メソッドで行頭から何行表示させるか指定できます。省略するとデフォルトの5行になります。
tail()メソッドは逆に行末から何行表示させるか指定できます。
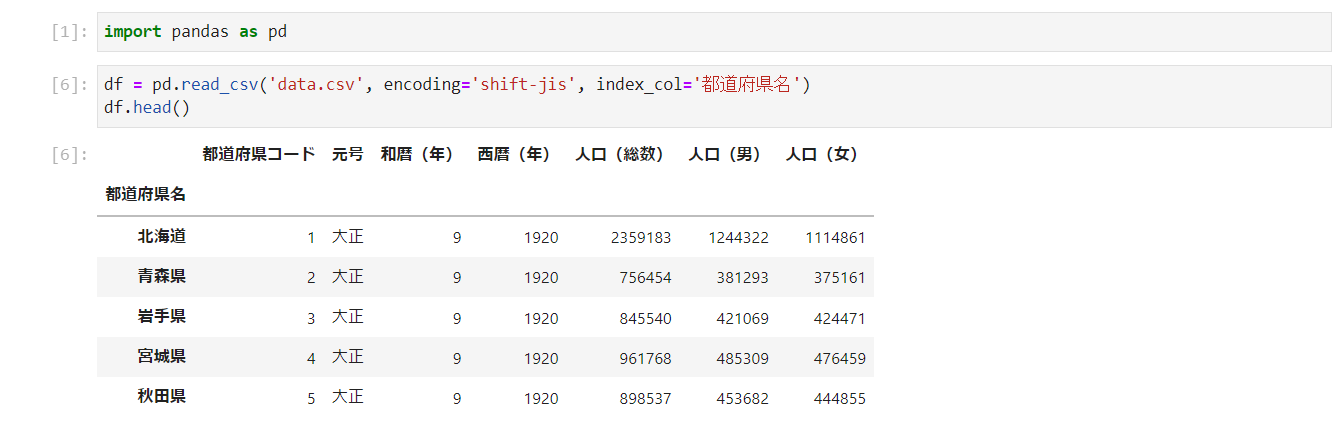
indexを指定して読み込む
read_csv()にindex_col="インデックスに指定したいカラム"で任意の列をインデックスに指定することができます。
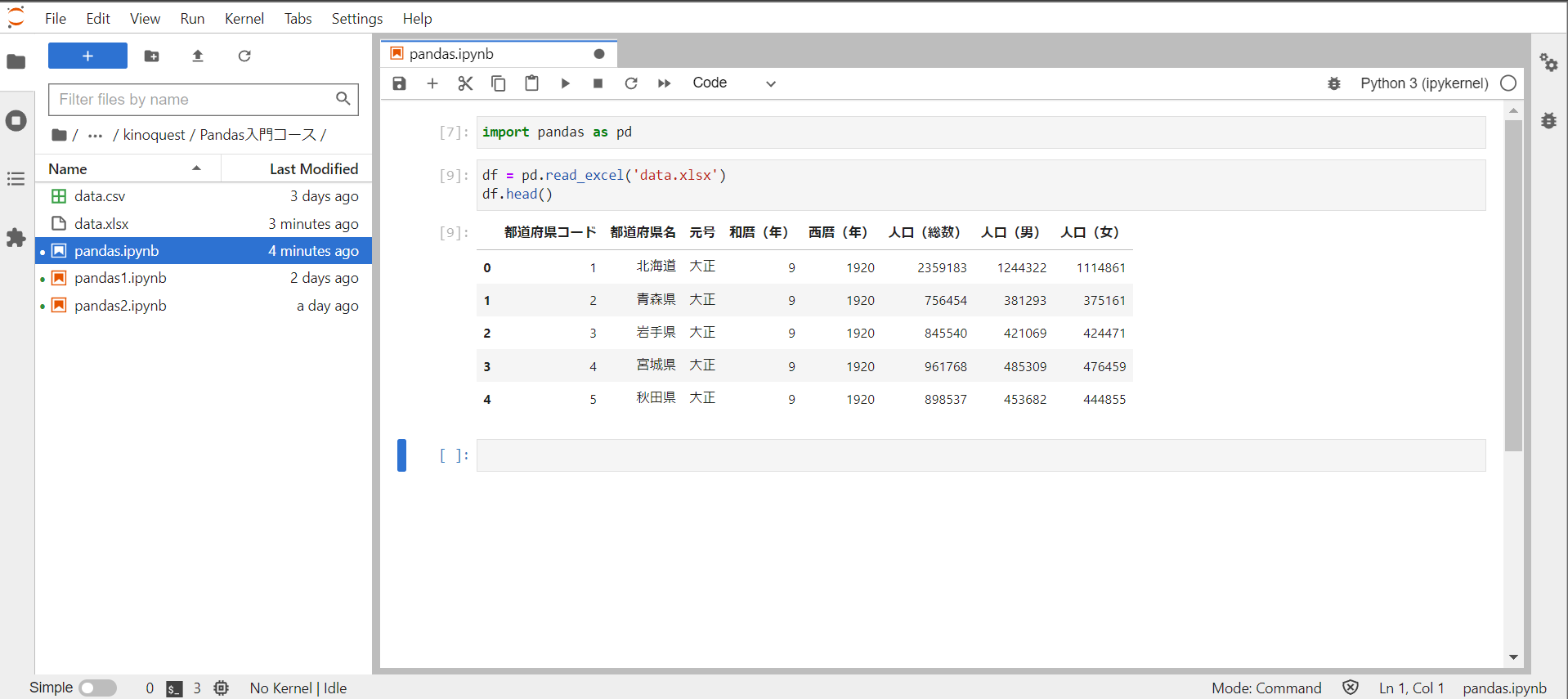
Excelファイル
読み込み
先ほどのCSVをExcelにコピペしたものを準備して行います。
Excelファイルをデータフレームとして読み込むには、read_excel関数を使用します。
read_excel関数の引数に、読み込みたいExcelファイルのパスを指定します。
Excelファイルと同じ階層にPythonファイルを配置することでパスを省略できます。
読み込み開始行を指定
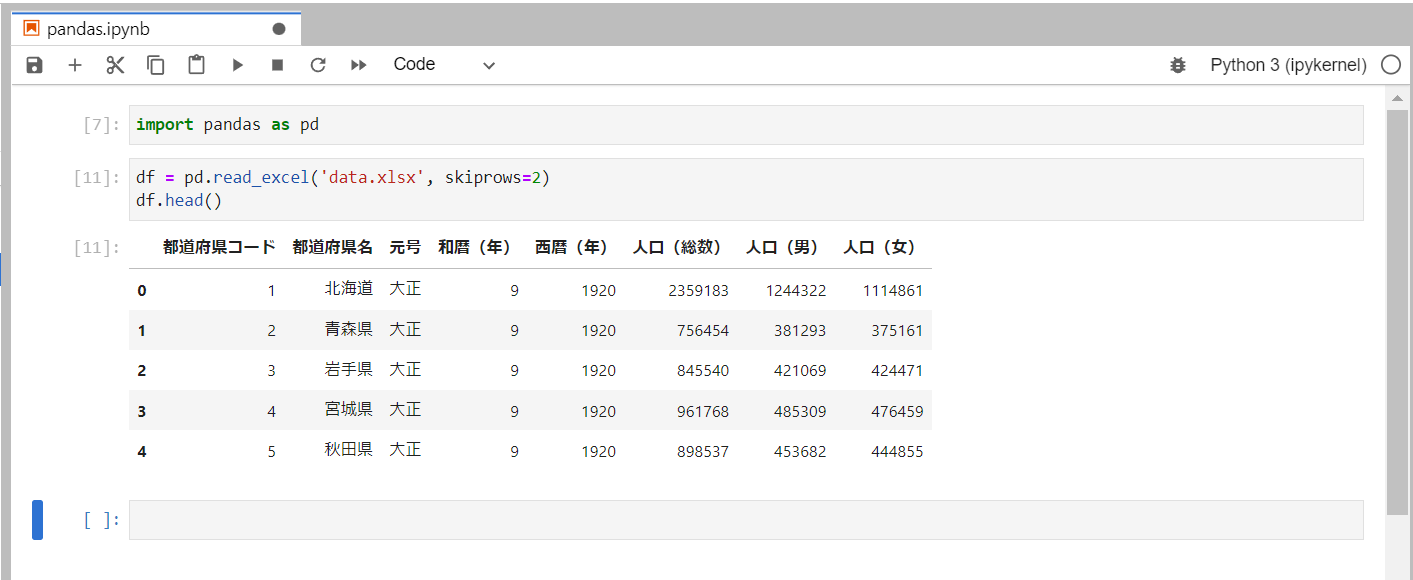
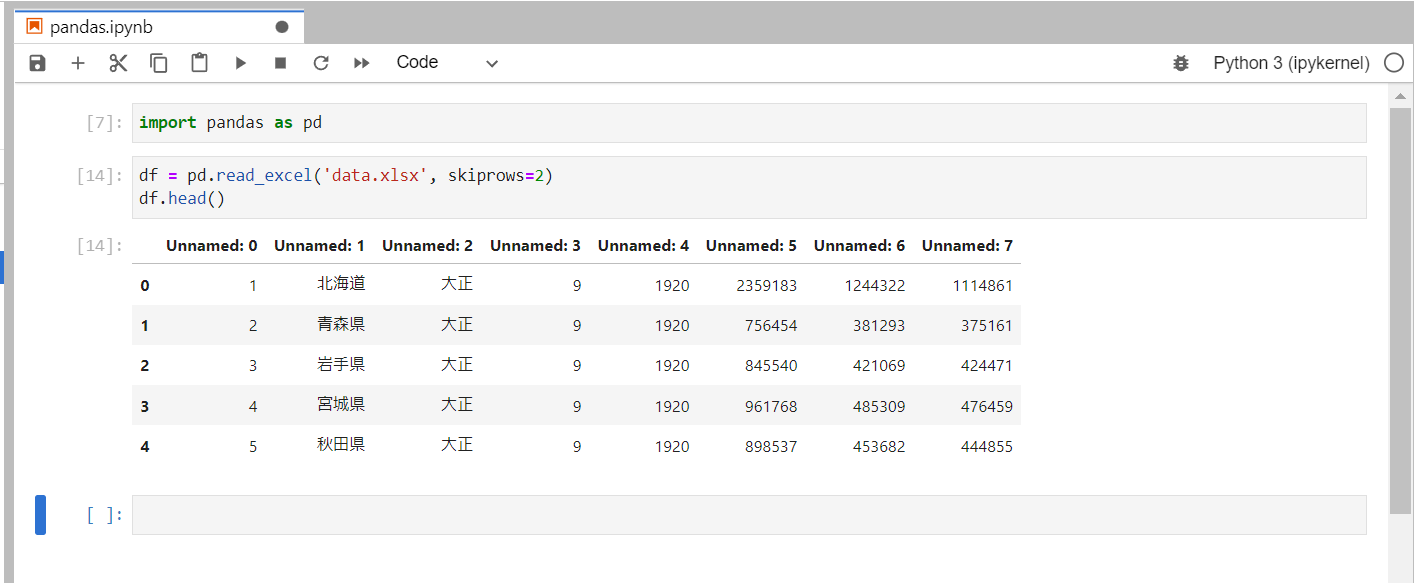
このように2行空行があった場合に3行目から読み込むように指定してみます。
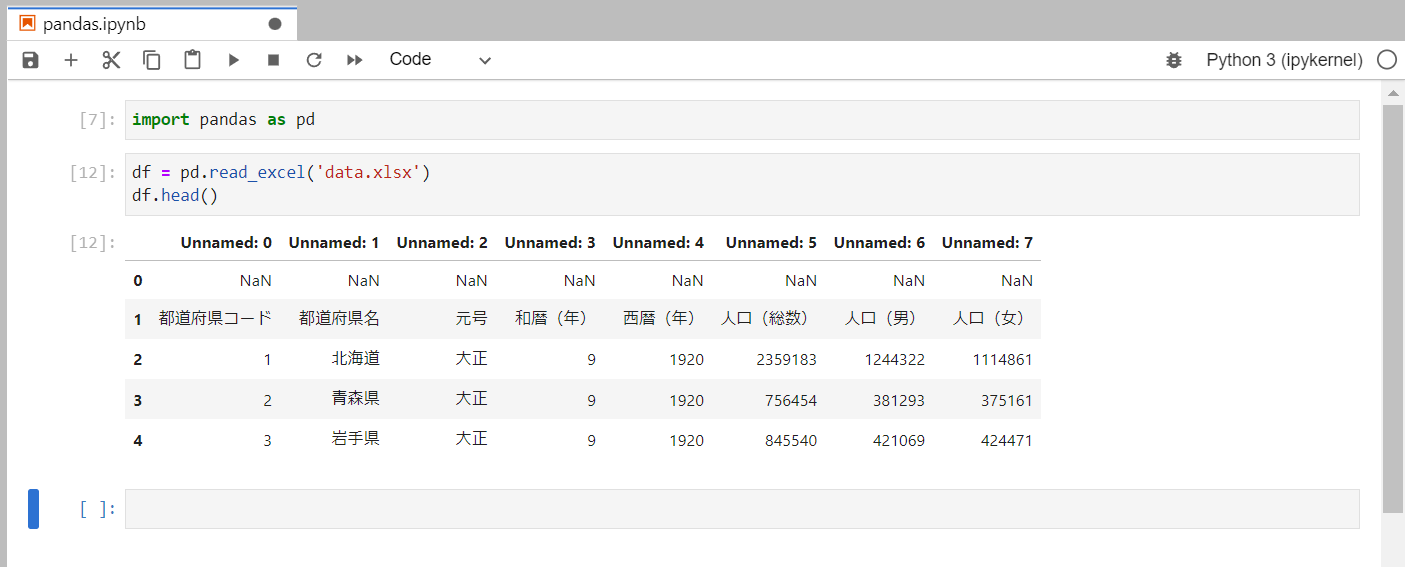
read_excel()に引数skiprowsに数値を渡すことで、指定した数値の分だけ行をスキップして読み込むことができます。
headerを指定
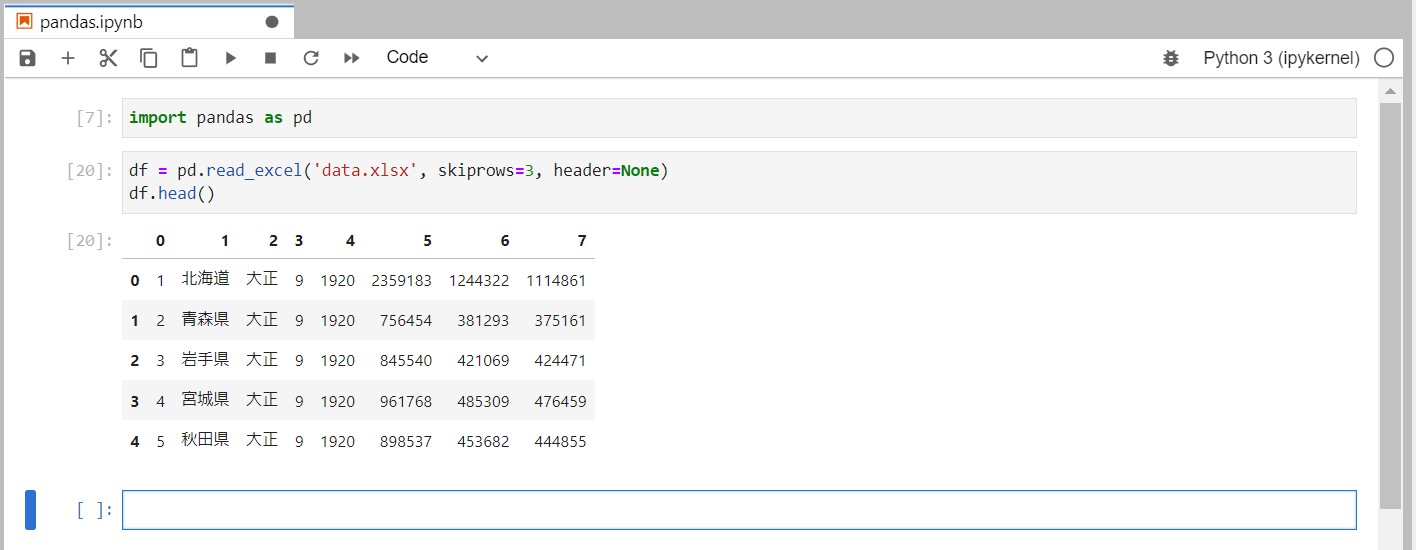
このようにヘッダーがないデータを読み込んでみます。
Unnamedとなってしまいました。
引数headerにカラムに指定したい行番号をリストで渡すことで、任意の行をカラムに指定することができます。
この際にNoneを渡すと、カラムが自動的に連番で附番されます。
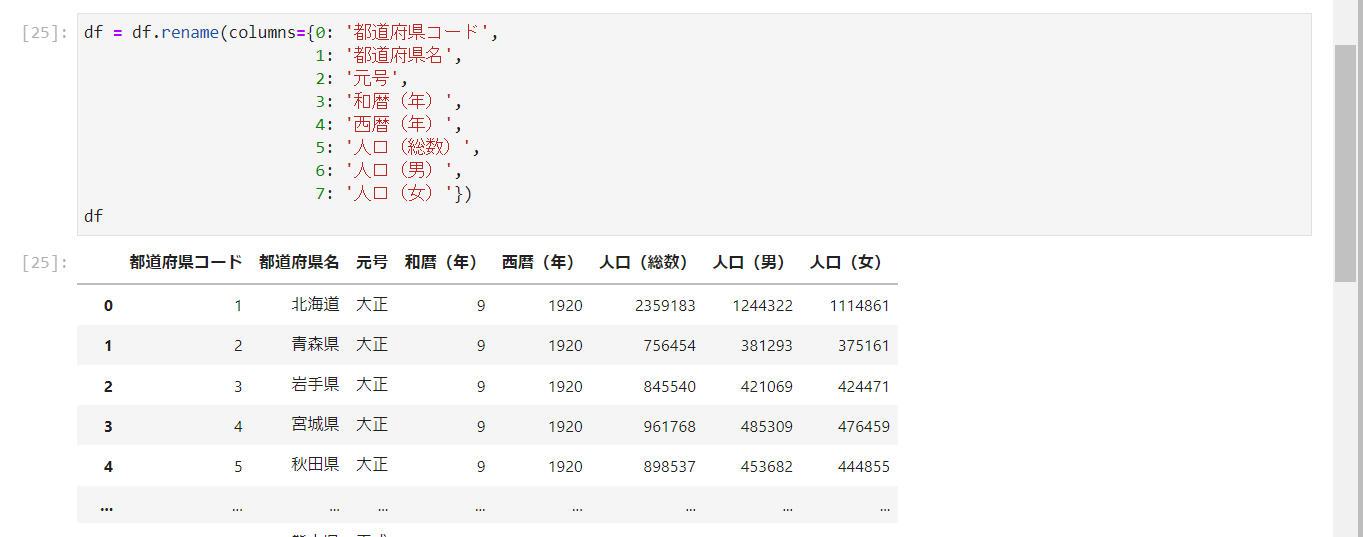
カラム名の変更
rename()メソッドを使用するとカラム名やインデックスを変更することができます。辞書型で変更前と変更後のカラム名またはインデックス名を渡します。
終わりに
read_csvとread_excelはしっかりおぼえたい。