この記事について
AWS re:Invent 2024で発表されたAmazon Bedrock Data Automation について、AWSドキュメントを読み解きつつ、実際に試しながら解説してみました。
Amazon Bedrock Data Automationとは?
Bedrock Data Automation (BDA) is a cloud-based service that simplifies the process of extracting valuable insights from unstructured content—such as documents, images, video, and audio. BDA leverages generative AI to automate the transformation of multi-modal data into structured formats, enabling developers to build applications and automate complex workflows with greater speed and accuracy.
※Data automation より引用
Amazon Bedrock Data Automation (BDA)は、文書、画像、動画、音声などの非構造化データから洞察を得ることができるようなサービスです。
ユースケース
以下のユースケースがあるようです。
- ドキュメント処理
- 文書処理タスクをこなす(分類、抽出、正規化、検証など)
- メディア分析
- 動画データを分析し、各シーンの要約、動画内に表示されるテキストの抽出、不適切な部分を識別するなど
- 生成型AIアシスタント
- 文書だけでなく、画像や動画、音声などをベースとして回答させるようにすることでRAG機能が強化されたAIアシスタントをアプリケーションに組み込むことができる
機能/用語の解説
プロジェクト
画像もしくは音声、動画データの書き起こしをするために作成が必要なものです。
書き起こしたいデータの種類毎に、プロジェクトを作成する、といったところでしょうか。
プロジェクト作成自体は以下の画面のように名前を入れてプロジェクトを作成を押下すれば簡単にできます。
標準出力
Amazon Bedrock側で事前定義された出力形式に基づいて、出力をしてくれる、というものになります。
結果はStandardOutPutDocument.jsonというファイルに出力されます。
一部分を切り取ってみるとこんな感じです。
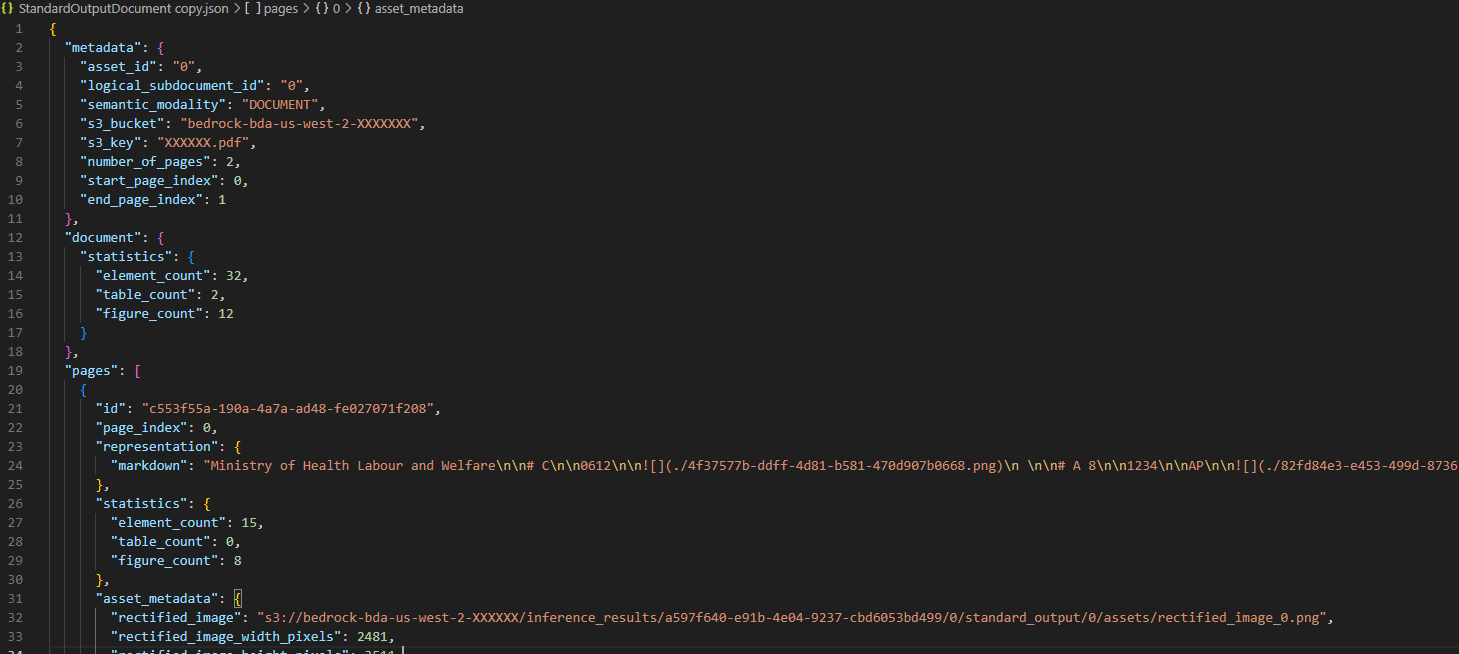
なお、標準出力においてもプロジェクト毎に出力の仕方がある程度選択可能です。

カスタム出力
標準出力にはない出力形式で結果を出力できる、というものになります。後述のブループリントが関わってきます。
ブループリント
入力ファイルの目的の出力形式と抽出ロジックを定義できる機能です。
予め、Bedrock側に「ドキュメントをXXの形式で抽出してもらいますよ」というお願いをして、それを元にテキスト抽出をすることができる、といったところでしょうか。
AWS側でいくつかのブループリントが用意されているようです。ユーザー自身が手動で作成することも可能です。実際、サンプルのブループリントを作成し、その使い勝手を試してみました。
テスト用のプロジェクトを作成し、
Invoiceというサンプルのブループリントを作成してみました。
抽出対象の画像に対し事前情報の説明を与えているようです。
説明
An invoice is a document that contains the list of service rendered or items purchased from a company by a person or another company. It contains details such as when the payment is due and how much is owed.
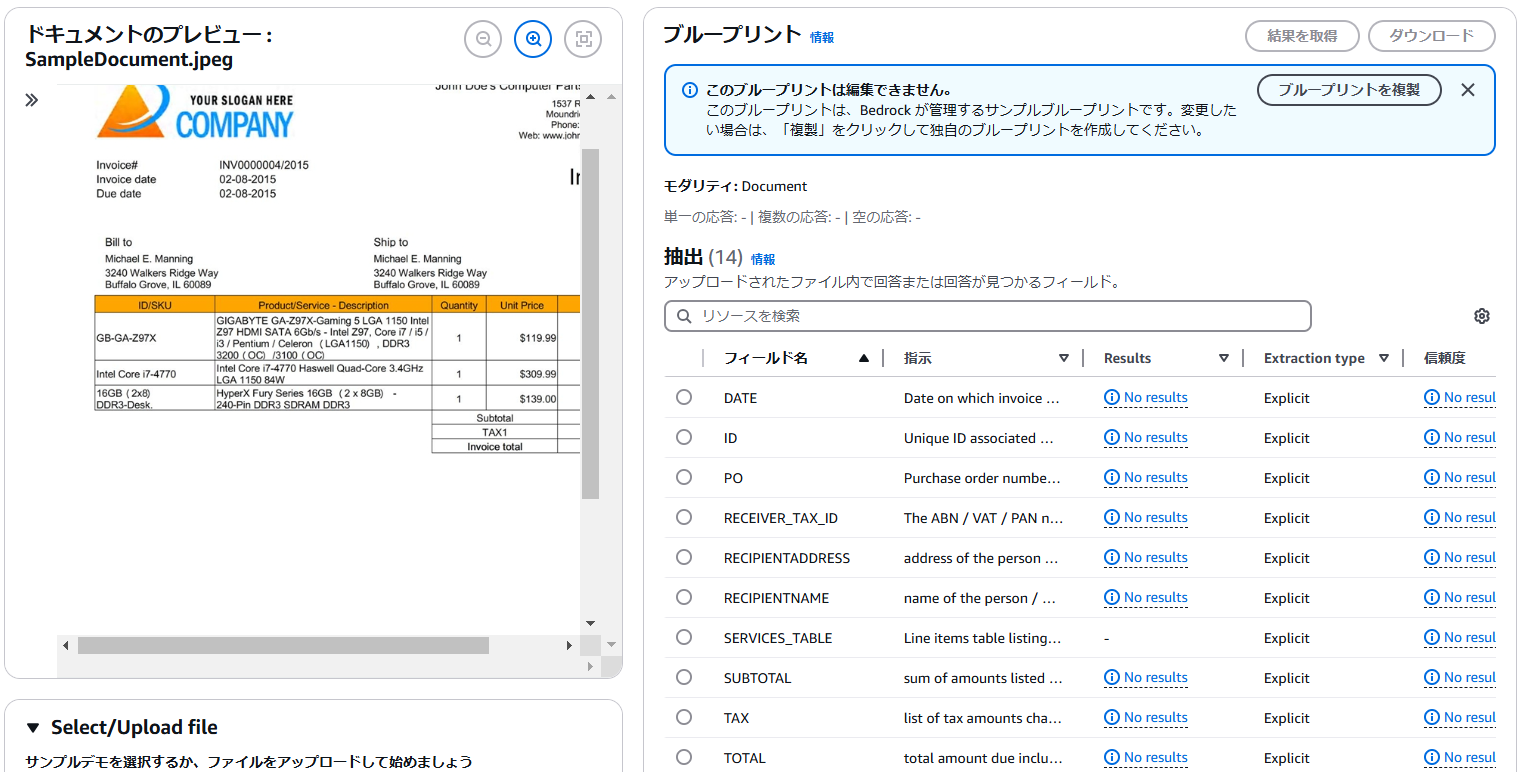
この「ブループリント」に基づいて、プロジェクト内でアップロードされた画像に関して情報を抽出してくれるようです。
画面右側の「抽出」欄で、事前定義されたフィールド名に該当する結果が見つかるか、またその情報の信頼度を出力してくれています。

実際に試してみる
注意点
本機能は現状プレビュー版で、2024年12月16日時点で、
利用可能リージョンは米国東部リージョン(オレゴン)のみです。
サービスクォータは以下です。
https://docs.aws.amazon.com/bedrock/latest/userguide/bda-limits.html
また、料金体系の詳細については料金ページをご覧ください。
テスト
テスト用のファイルアップロードについては、
AWS側が用意しているサンプル・ローカルから・S3からインポートの3種類の方法があります。
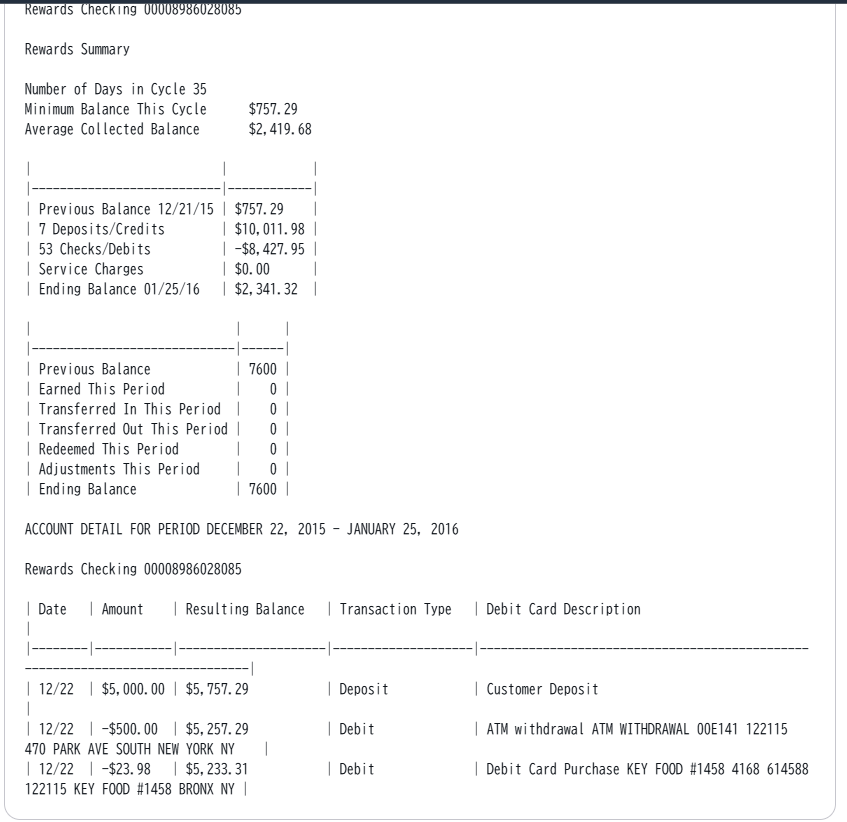
まずはAWS側が用意しているサンプルのBackStatement.jpgを試してみます。

書き起こし結果は以下のようでした。中々良い感じに読み取れているようですね。

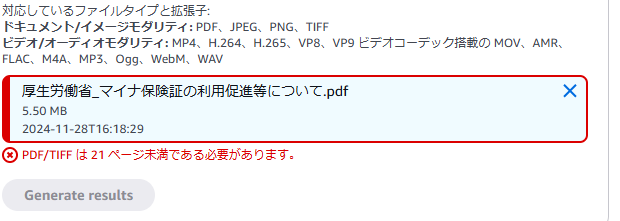
また、日本語のドキュメントについても試してみます。厚生労働省マイナ保険証の利用促進等についてを読み込もうとしましたが、以下のように21ページ以上のデータをアップロードしようとすると、エラーになってしまうようでした。
そのため別のドキュメント(参照:厚生労働省「マイナンバーカードの健康保険証利用」)で試しました。
使用したドキュメントがあまり良くなかった(あるいは追加何か設定をしなければいけなかった)可能性はもしかしたらあるかも知れませんが、テスト結果から判断して、
日本語の検出はまだ難しそうでした。
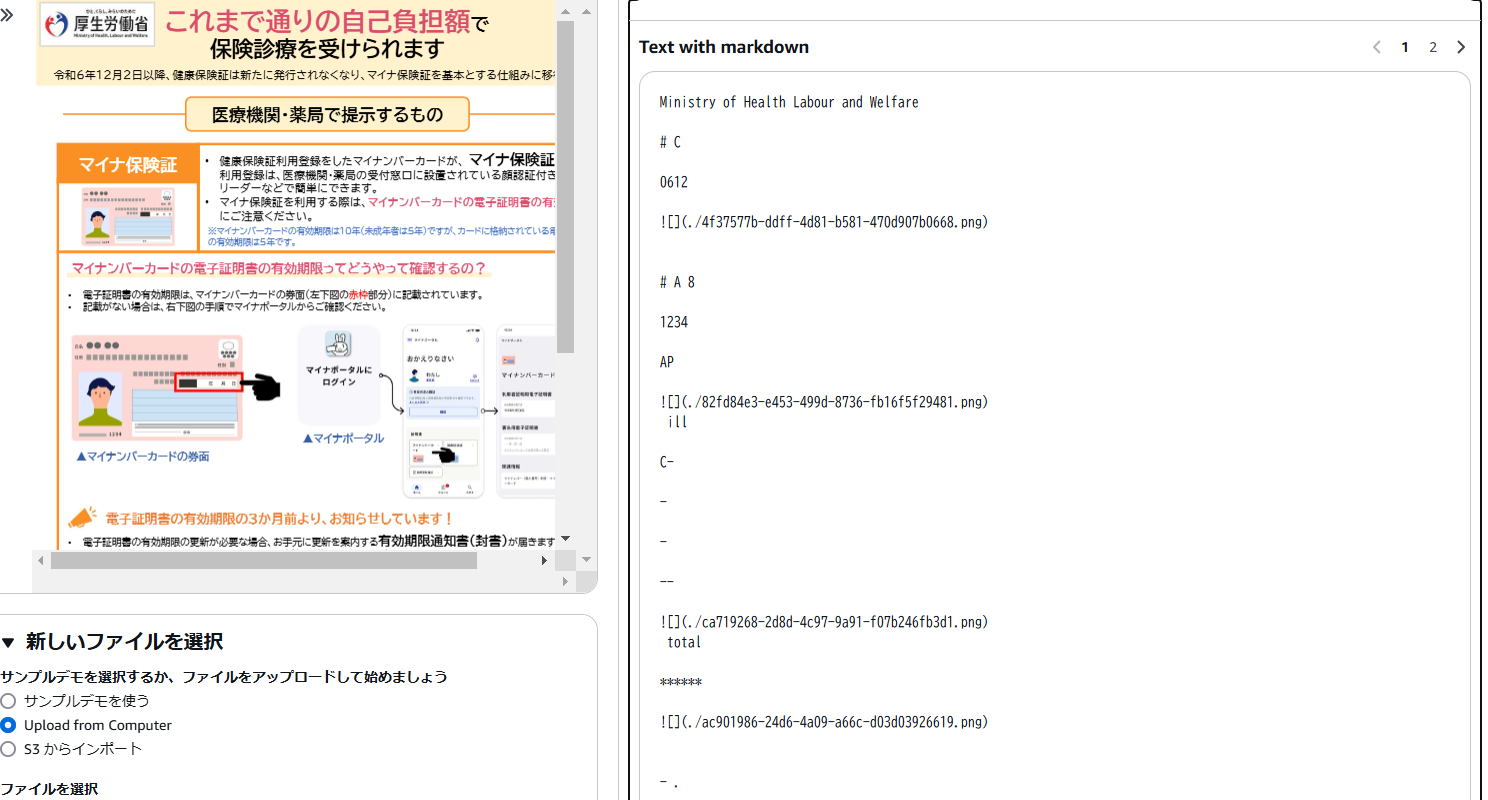
抽出結果(一部)
Ministry of Health Labour and Welfare
# C
0612

# A 8
1234
AP

ill
C-
-
-
--

total
******

- .
- ,
- .
- CELLINED, L
()
(07121).

121

ELT .
CloudShell
フィードバック
© 2024, Amazon W
まとめ
簡単ではありますが、
AWS re:Invent 2024で発表されたAmazon Bedrock Data Automation について、実際に試しながら解説してみました。
日本語への対応はまだまだ難しい?かなと感じましたが、いずれにせよBedrockの機能の幅が広がったことで期待が高まりますね。
本機能は、Bedrockの機能「ナレッジベース」 との連携もできるとのことなので、例えば、Kendraで読み込むことのできない画像PDFデータを代わりにBDAで読み取り、ナレッジベースと連携しRAGを実現する、という手段を取ることもできるなと感じました。
私自身、業務で、「テキスト情報がないためにKendraでインデックス化できないドキュメントに対してRAGをどのように組み込むか」で悩んだ経験がありますが、BDAが今後その解決策を提供してくれるかもしれませんね。
また、 guidance-for-multimodal-data-processing-using-amazon-bedrock-data-automationというリポジトリもあるようなので、こちらも今後試していきたい所です。