TreasureDataを操作するコマンドラインツールに「tdコマンド」があります。
これを使うとデータベースの操作、クエリの実行や結果のエクスポートや、バルクインポートなどが捗ります。
http://toolbelt.treasuredata.com/
このコマンドを利用するときにハマったことを紹介します。
複数のcsvファイルを一括でインポートする方法
カラムの構成が同じファイルが複数に分かれており、それを一括で取り込みたいときに便利な方法があります。
ファイル名を指定する際、*.csvという形でワイルドカード指定が出来ます。
td import:auto --format csv --column-header --encoding Windows-31J --all-string \
--time-value `date +%s`,10 --auto-create foo_db.bar_table path/to/example_*.csv
Tips: 上記コマンド例で使っている、インポートするファイルに時刻が無い時の対処法
--time-value `date +%s`,10とすれば、10のパーティションに分かれるように良い感じにインポートできます。
細かい説明は次の通りです。
--time-value (unixtime)オプションを付与することで、任意のtimeを付与させることができます。
注意点として、TreasureDataはtimeを1時間ごとにパーティションを区切って効率的なデータ処理を行うので、
全部のデータを--time-value 0にするとクエリの効率などが悪くなります。
そのため、データの更新日などでtimeの範囲がわかるのであれば、
--time-value UNIXTIME,HOURSのように指定することで、
ある時間からHOURS時間の範囲でtimeをばらけてデータを挿入してくれます。
引用元 https://oss.sios.com/bigdata-blog/ua59up
機種依存文字を含むcsvファイルのエンコーディング指定
td importコマンドでencodingに困ったときに参考になるTipsです。
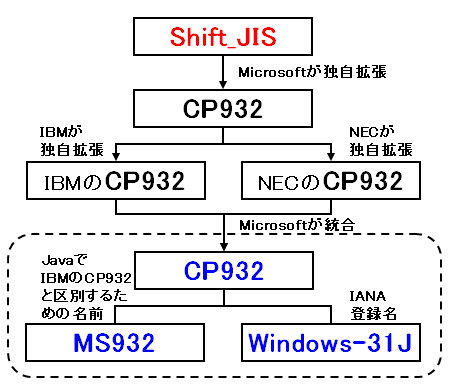
いわゆるWindowsで作成された機種依存文字を含むcsvファイルを取り込む際、Shift_JISでの指定では化けてしまいます。
しかしながらCP932と指定しても、エラーとなります。その時はWindows-31JまたはMS932を指定しましょう。
-
動く
- Windows-31J
- MS932
-
動かない
- CP932
こうなる背景としては、td importコマンドでは裏でtd-import.jarを呼び出しており、これはJavaで書かれています。
そのためCP932ではなく、Windows-31JないしMS932を指定する必要があるようです。
少々不思議なことですが、このどちらを指定しても、結果は同じです。
Javaの世界では、IBMのCP932とWindows-31Jを区別するために、MS932という用語が使われます。
(中略)
たいていの場合はそれで問題ないかもしれませんが、プログラミングにおいて、文字コードに「Windows-31J」と指定すべきところを、「Shift_JIS」と指定したがゆえに、文字化けを引き起こすことがあります。「Windows-31J」で定義されている文字が「Shift_JIS」にはない場合です。
引用元 http://una.soragoto.net/topics/13.html
バルクインポートに関するドキュメント
次のURLから、さまざまなTipsを参照できます。
http://docs.treasuredata.com/categories/bulk-import
- Bulk Import Overview
- Bulk Import from CSV file
- Bulk Import from TSV file
- Bulk Import from JSON file
- Bulk Import from Amazon S3
- Bulk Import from MySQL
- Bulk Import from PostgreSQL
- Bulk Import from MongoDB
- Bulk Import Internals
- Bulk Import Tips and Tricks
あわせて読みたい
- マスタ情報を持つMySQLテーブルをTreasureDataへ簡単に転送する方法
http://qiita.com/y-ken/items/ef48de726dcbc4d9de98