Webスクレイピングとは、Webページの情報をプログラムを使って取得できる技術です。
例えば、以下のようなことができます。
・あるサイトの特定部分のテキストを定期的に取得
・ネットオークションの価格を自動で取得
・自動でサイトにログインして、ほしい情報を取得
Webページの情報を取得するため、簡単なHTML、CSSやJavascriptの知識があったほうがよいです。
今回普段よく見るITニュースサイトの見出しをWebスクレイピングで取得します。
注意
各Webサイトには、多くの場合利用規約が掲載されています。
利用規約でWebスクレイピングが禁止されている場合は実施しないでください。
またWebサイトのルート直下に、robots.txtというファイルがある場合、その記述内容に従う必要があります。
※Webサイトによっては、スクレイピングを拒否するように設定しているところもあります。
Webスクレイピングにも様々な方法があるので都度掲載していけたらと思います。掲載するのは基本的なことですが、コードを発展させればいろんなことができます。
Requests,Beautiful Soupを使う
2つのライブラリを使用します。
Requests:HTTPライブラリでWebページを取得するためのもの。
Beautiful Soup:HTMLパーサライブラリ。取得したWebサイトから特定のテキスト情報などを抜き出せる。
そのため事前にインストールをしておきましょう。
# Requestsインストール
pip install requests
# Beautiful Soupインストール
pip install bs4
こちらのOSDN magazineの見出しを抽出します。
※Python 3.6.8でやっています。
# coding: UTF-8
# モジュールインポート
import requests
from bs4 import BeautifulSoup
# OSDN magazineのURLを変数に確認
URL = 'https://mag.osdn.jp/news/'
# requests.get()でHTMLを取得
result = requests.get(URL)
# BeautifulSoupの機能、html.parserでHTMLやXMLをパースできる。
data1 = BeautifulSoup(result.text, 'html.parser')
# find_allでclassを指定し、見出しを取得
data2 = data1.find_all("h2", class_="entry-title")
# URLを出力
print(URL)
# 配列に格納された値をfor文とprint文で出力
for item in data2:
print(item.getText())
上記実行すると以下のように見出しの一覧が出力されると思います。
RequestsでHTMLを取得し、Beautiful Soupで特定のテキスト情報を抜き出しました。
https://mag.osdn.jp/news/
「Rust 1.37」リリース
米Microsoft、JVMのチューニング技術を持つjClarityを買収
「MongoDB 4.2」公開、Wildcard Index導入など
「Git 2.23」リリース、「git switch」や「git restore」コマンドを実験的に導入
VJにも利用できるオープンソースの動画エディタ「LiVES 3.0」リリース
Fedora Rawhideに対応、エンタープライズLinux向け拡張パッケージ「EPEL 8」が公開
米Microsoft、ソースコードエディタ「Visual Studio Code 1.37」をリリース
「GCC 9.2」リリース
…省略
CSSセレクターを使う方法
上記の例は"entry-title"というclass属性の箇所に、見出しが記載されていると決まっていたため、そこを指定して抜き出すだけでした。
しかし見出しをaタグで囲んでいたり、タグの内容が動的に変化することもあります。
その時CSSセレクタを使うと便利です。
CSSセレクタは、CSSにおいてスタイルを適用する要素を選択するための条件式です。
次はセキュリティの分野で著名な徳丸浩さんのブログ記事で一番最近アップロードされた、
記事のタイトルを抜き出します。
Google Chromeでサイトを表示させF12キーで開発者ツールを表示させます。
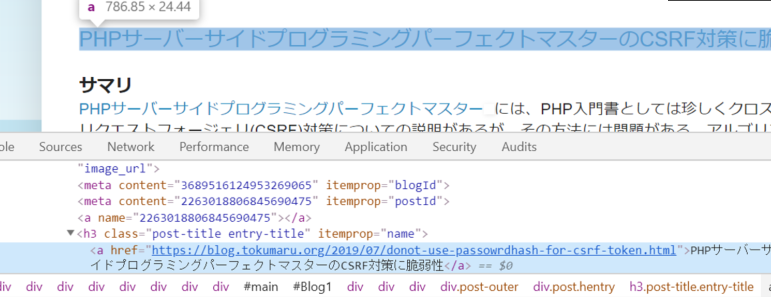
<a href=リンク先URL〜から始まる箇所で右クリックし Copy > Copy selector をクリックします。すると以下コピーされます。これがCSSセレクタです。
# Blog1 > div.blog-posts.hfeed > div:nth-child(1) > div > div.post-outer > div > h3 > a
<a href=リンク先URL〜は表示されず、要素を選択する仕組みのみが表示されています。
こちらを使いコードを作成します。
# coding: UTF-8
# モジュールインポート
import urllib.request, urllib.error
from bs4 import BeautifulSoup
# サイトURLを変数に格納。
URL = "https://blog.tokumaru.org/"
# URLにアクセス。戻り値はアクセスした結果やHTMLを返す。
r = urllib.request.urlopen(URL)
# アクセス結果からHTMLを取り出し、BeautifulSoupの機能でhtmlパースする。
soup = BeautifulSoup(r, "html.parser")
# URLを出力
print(URL)
# CSSセレクタを使って指定した場所を表示。.textでhtmlではなくtext形式となる。
print(soup.select_one("#Blog1 > div.blog-posts.hfeed > div:nth-child(1) > div > div.post-outer > div > h3 > a").text)
すると一番最初の見出しが表示されます。
https://blog.tokumaru.org/
PHPサーバーサイドプログラミングパーフェクトマスターのCSRF対策に脆弱性
ニュース見出しの簡単な取得であれば、Requests,Beautiful SoupにCSSセレクタで、
ほとんど出来ると思います。これをメールやチャットツールで通知すれば、今どんなITニュースがあるのか一目瞭然です。
Webスクレイピングは他にも正規表現を使った抽出方法、Pandasを使った表データの抽出など様々な方法があります。
以下に関連記事がありますので、よろしければご覧になって下さい。
・Pythonで経済ニュースの情報をWebスクレイピング