#目次
1.はじめに
2.本記事の概要
3.この成果物を作成しようと思った経緯
4.成果物
5.余談
6.今後の活動について
7.おわりに
1. はじめに
こんにちは。Qiita初投稿・文系出身のIT未経験者からエンジニア転職を目指し
Aidemy様の講座を受講しながら日々勉強中の事務職です。
至らぬ点やつっこみ所が満載かと思いますが、暖かくご指摘・コメントいただければ幸いです。
2. 本記事の概要
※これはプログラミングスクールのAidemy様に提出する為の記事です。
AIアプリ作成の準備から作成(Webスクレイピング、機械学習、アプリ制作)までを書きます。
文系出身でIT未経験者の方がこれからエンジニアを目指す際に、何かしら参考になると幸いです
3. この成果物を作成しようと思った経緯
どんな題材を作成しようか迷ったが、今後のやりたいことを達成するために
スクレイピングと機械学習を実装できるアプリを作成できれば良いと考えた。
AIアプリ開発に欠かせないデータの準備に手がかかるものがいいと考え
遊戯王カードのホームページにはスクレイピングを許可されておらず、
取得が大変そうな遊戯王カードの情報取得及び判別アプリの作成をしようと考えました。
4. 成果物
下記が作成したアプリとなります。
興味がございましたら、試しに遊んでみてください。
遊戯王カードのモンスターカードの判別アプリ
1. 実装環境
M1 Mac
python3.9.5
Visual studio Code
Google Colaboratory
2. 使用している技術
スクレイピング、機械学習、アプリ作成
3. 作成したコード
【スクレイピング】
#pythonライブラリの「icrawler」でBing用モジュールをインポート
from icrawler.builtin import BingImageCrawler
#検索ワードの設定
sarch_dict = {'ブルーアイズ':'ブルーアイズ 青眼の白龍',
'レッドアイズ':'レッドアイズ 真紅眼の黒竜',
'ブラックマジシャン':'ブラックマジシャン',
'究極完全態・グレート・モス':'究極完全態・グレート・モス',
'暗黒騎士ガイア':'暗黒騎士ガイア'
}
#検索ワード毎にダウンロード
for key,value in sarch_dict.items():
#ダウンロードした画像を保存する先のディレクトリを指定
crawler = BingImageCrawler(storage={'root_dir': key})
#検索するキーワードとダウンロード数の指定
crawler.crawl(keyword=value, max_num=400)
・データの選定で苦労した点
取得した画像データの中には、不要なデータも混じって取得されてしまうので、
それを一個一個削除するのが大変でした。
例)ブラックマジシャンと検索ワードに入れた際に、ブラックマジシャンガールも含まれてしまう


また、今回遊戯王カードは同じカードだが、デザインが違うカードがあるため
残すか削除するか迷いました。
※複数のパターンが同じ割合であれば、残す。
割合が均等でない場合には、最も有力な画像パターンを残しそれ以外を削除する


【機械学習】
import os #osモジュール(os機能がpythonで扱えるようにする)
import cv2 #画像や動画を処理するオープンライブラリ
import numpy as np #python拡張モジュール
import matplotlib.pyplot as plt#グラフ可視化
import pandas as pd
import tensorflow
from tensorflow.keras.utils import to_categorical #正解ラベルをone-hotベクトルで求める
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input, Conv2D#全結合層、過学習予防、平滑化、インプット
from tensorflow.keras.applications.vgg16 import VGG16 #学習済モデル
from tensorflow.keras.models import Model, Sequential #線形モデル
from tensorflow.keras import optimizers #最適化関数
#画像の格納
path_BI = [filename for filename in os.listdir('/content/drive/MyDrive/ブルーアイズ') if not filename.startswith('.')]
path_BM = [filename for filename in os.listdir('/content/drive/MyDrive/ブラックマジシャン') if not filename.startswith('.')]
path_RI = [filename for filename in os.listdir('/content/drive/MyDrive/レッドアイズ') if not filename.startswith('.')]
path_GIA =[filename for filename in os.listdir('/content/drive/MyDrive/暗黒騎士ガイア') if not filename.startswith('.')]
path_MOS = [filename for filename in os.listdir('/content/drive/MyDrive/究極完全態・グレート・モス') if not filename.startswith('.')]
#50x50のサイズに指定
image_size = 50
#画像を格納するリスト作成
img_BI = []
img_BM = []
img_RI = []
img_GIA = []
img_MOS = []
#各リストへ画像を格納
for i in range(len(path_BI)):
img = cv2.imread('/content/drive/MyDrive/ブルーアイズ/' + path_BI[i])
img = cv2.resize(img,(image_size, image_size))
img_BI.append(img)
for i in range(len(path_BM)):
img = cv2.imread('/content/drive/MyDrive/ブラックマジシャン/' + path_BM[i])
img = cv2.resize(img,(image_size, image_size))
img_BM.append(img)
for i in range(len(path_RI)):
img = cv2.imread('/content/drive/MyDrive/レッドアイズ/' + path_RI[i])
img = cv2.resize(img,(image_size, image_size))
img_RI.append(img)
for i in range(len(path_GIA)):
img = cv2.imread('/content/drive/MyDrive/暗黒騎士ガイア/' + path_GIA[i])
img = cv2.resize(img,(image_size, image_size))
img_GIA.append(img)
for i in range(len(path_MOS)):
img = cv2.imread('/content/drive/MyDrive/究極完全態・グレート・モス/' + path_MOS[i])
img = cv2.resize(img,(image_size, image_size))
img_MOS.append(img)
#np.arrayでXに学習画像、yに正解ラベルを代入
X = np.array(img_BI + img_BM + img_RI + img_GIA + img_MOS)
#正解ラベルの作成
y = np.array([0]*len(img_BI) + [1]*len(img_BM) + [2]*len(img_RI) + [3]*len(img_GIA) + [4]*len(img_MOS))
#配列のラベルをシャッフルする
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
#学習データと検証データを用意
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
#正解ラベルをone-hotベクトルで求める
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
#モデルの入力画像として用いるためのテンソールのオプション
input_tensor = Input(shape=(image_size, image_size, 3))
#転移学習のモデルとしてVGG16を使用
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
#学習データに対しての水増し
params = {
'rotation_range': 15,
'vertical_flip': True,
'channel_shift_range': 15,
'zoom_range': [0.95, 1.05]
}
generator = tensorflow.keras.preprocessing.image.ImageDataGenerator(**params)
train_iter = generator.flow(X_train, y_train)
#モデルの定義 *活性化関数relu
#転移学習の自作モデル
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(5, activation='softmax'))
#入力はvgg.input, 出力はtop_modelにvgg16の出力を入れたもの
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
#vgg16による特徴抽出部分の重みを固定(以降に新しい層(top_model)が追加)
for layer in model.layers[:19]:
layer.trainable = False
#コンパイル
model.compile(loss='categorical_crossentropy',
optimizer="adam",
metrics=['accuracy'])
# 学習の実行
history01 = model.fit(X_train, y_train, batch_size=32, epochs=80, verbose=1, validation_data=(X_test, y_test))
#acc, val_accのプロット
plt.plot(history01.history["accuracy"], label="accuracy", ls="-", marker=".")
plt.plot(history01.history["val_accuracy"], label="val_accuracy", ls="-", marker=".")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
#loss, val_lossのプロット
plt.plot(history01.history["loss"], label="loss", ls="-", marker=".")
plt.plot(history01.history["val_loss"], label="val_loss", ls="-", marker=".")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
# 学習の実行
history02 = model.fit(train_iter, batch_size=32, epochs=80, verbose=1, validation_data=(X_test, y_test))
#acc, val_accのプロット
plt.plot(history02.history["accuracy"], label="accuracy", ls="-", marker=".")
plt.plot(history02.history["val_accuracy"], label="val_accuracy", ls="-", marker=".")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
#loss, val_lossのプロット
plt.plot(history02.history["loss"], label="loss", ls="-", marker=".")
plt.plot(history02.history["val_loss"], label="val_loss", ls="-", marker=".")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
#精度の評価
score = model.evaluate(X_test, y_test, batch_size=32, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
#モデルを保存
model.save("my_model.h5")
・学習モデルの構築において苦労した点
精度がなかなか上がらなかった点です。
対策として行ったこととしては、下記になります。
①モデル層の変更
Dropout層の増減、ユニット数の調整、活性化関数の変更
#転移学習の自作モデル
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu')) #256の他に128や512などを試した
top_model.add(Dropout(0.5)) #Dropout層の増減や減らす割合を0.5から0.3に変更などを試した
top_model.add(Dense(5, activation='softmax'))
②学習データと訓練データの割合の調整
0.7・0.8・0.9での調整
#割合を0.7,0.8,0.9と値を変更し試した
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
③batch_sizeの調整
2の階乗で試すのがいいと聞いたので、32の他に64,128,256,512などを試した
# 学習の実行
history01 = model.fit(X_train, y_train, batch_size=32, epochs=80, verbose=1, validation_data=(X_test, y_test))
# 学習の実行
history02 = model.fit(train_iter, batch_size=32, epochs=80, verbose=1, validation_data=(X_test, y_test))
#精度の評価
score = model.evaluate(X_test, y_test, batch_size=32, verbose=0)
④epochsの調整
100で設定していたが、80ぐらいから徐々にaccuracyが下がってきたため、80に設定

⑤準備データ量の水増し
準備データの数が少なかったため、水増しで精度向上を狙った。
#学習データに対しての水増し
params = {
'rotation_range': 15,
'vertical_flip': True,
'channel_shift_range': 15,
'zoom_range': [0.95, 1.05]
}
generator = tensorflow.keras.preprocessing.image.ImageDataGenerator(**params)
train_iter = generator.flow(X_train, y_train)
#学習の実行
history02 = model.fit(train_iter, batch_size=32, epochs=80, verbose=1, validation_data=(X_test, y_test))
水増し前・水増し後の精度(accuracy)の比較
約10%程度のaccuracyの上昇が見られた
【水増し前】
Test accuracy: 0.6542056202888489
Test loss: 2.6405889987945557
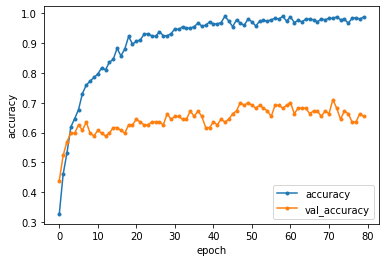

【水増し後】
Test accuracy: 0.7570093274116516
Test loss: 1.1755520105361938


参照サイト
5. 余談
当初、アプリへ投入した遊戯王カードがモンスターカードかを判定するアプリを作成しようと思ったので
大量のモンスターカードのデータが必要だったため、下記サイトにてスクレイピングを行おうと試みたが、
実装に時間がかかり、Aidemy様の受講期間内に作成が困難と判断したため、断念したが、
その際のスクレイピングのコードを参考に掲載する。
※Aidemyのメンター様のコード参照
# 必要なライブラリのインポート
import re
import time
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 各データの初期化
data = []
attbs = []
data_list = {"name":[], "type":[], "rare":[], "attr":[], "magic":[], "atk":[], "def":[], "url":[]}
base = "https://www.ka-nabell.com/"
# Rangeを調整すると良い(範囲広げるとそれだけ実行時間がかかる)
# デフォルトの値 : range(1,469) ※該当ページが469ページあるため
for i in range(1,50):
# ベースとなるURLを定義
base_url = f"https://www.ka-nabell.com/?act=sell_search&type=3&genre=1&page={i}#Contents"
response = requests.get(base_url)
time.sleep(10)
soup = BeautifulSoup(response.text, "html.parser")
# 画像データソースと名前の取得
imgs = soup.find_all("img", width="73")
lis = soup.find_all("p", style="max-width: 150px;")
# カードの属性情報に対する処理
for idx, i in enumerate(lis):
t = i.text
t = t.replace(" ", "").replace("\n", " ").split(" ")
s = [i for i in t if i != '']
attbs.append(s)
# カード情報を辞書型データとして格納
for img, attb in zip(imgs, attbs):
# src, altの情報を辞書型形式として保存
data.append(dict(src=img['src'], alt=img.attrs.get('alt', 'N')))
data_list["name"].append(img.attrs.get('alt', 'N'))
data_list["url"].append(img['src'])
data_list["type"].append(attb[0])
data_list["rare"].append(attb[2])
data_list["attr"].append(attb[3])
data_list["magic"].append(attb[4])
data_list["atk"].append(attb[5])
data_list["def"].append(attb[6])
# データフレーム化
df = pd.DataFrame(data_list)
# 各カード名の情報を辞書型で初期化
# 同じカード名があるとカウントされて連番を付番するために設定
count = dict.fromkeys(df["name"], 0)
# 画像データに名前をつけて取得
for d in data:
for key, value in d.items():
if key == "src":
link = base + value
elif key == "alt":
response = requests.get(link)
time.sleep(10)
image = response.content
count[value] += 1
file_name = f"{value}_{count[value]}.jpg"
with open(f"/content/drive/MyDrive/Image/{file_name}", "wb") as f:
f.write(image)
スクレイピングを行ったサイト
6. 今後の活動について
今回Aidemy様で学んだことを活かして、エンジニアへの転職を視野に入れ
より自分の興味を持ったものをとことん分析したり、社会の役に立つアプリなどを
作成できるように今後も日々精進していきたいと思っております。
7. おわりに
3ヶ月の受講期間でしたが、少しずつ自分のできることが増えていくと同時に
アプリ作成の難しさなどがわかり、自分の成長を感じることができました。
また、今回作成したアプリについては、モデルに読み込ませる準備データを増やしたり
内容を整えたりすることで、精度が上がるのではないかと思いました。
それは、また後日試してみようと思います。
最後まで読んでいただきありがとうございました。