最近Kaggleで新しい生成AIコンペ:LLM Prompt Recoveryが開催されました。⇩
このコンペで取り組むことは、元の文章とLLMで生成された書き換え文章に基づいて、その書き換え文章を生成するのに用いられたprompt文を復元することです。
実際のデータ例を見ると理解しやすいと思いますが、⇩のように元の文章(original_text)と生成された文章(rewritten_text)があり、それらを使ってプロンプト文を復元するコンペになります。

学習データのイメージは⇩です。(復元するプロンプト文はrewrite_prompt)

(なお、学習データは上記の1行しかないため、自分で用意する必要があります。)
使用されているモデルはGemma-7B-instructで、評価指標は文章間のコサイン類似度であり、sentence-t5-baseモデルで計算されます。
現在、主に2つのアプローチが主流となっています。
1つは最も一般的なアプローチで、文章復元用のモデルをファインチューニングする方法です。しかし、この方法でやると、精度はわずか0.47程度にとどまっています。私もデータ探して、モデルをトレーニングしましたが、精度があまり高くはなくて、何度が改善しても精度は0.5程度です。これからは、Gemmaでトレーニングデータを生成し、MoE(混合エキスパートモデル)を試してみたいと思います。
もう1つのアプローチは、コサイン類似度を逆算するトリッキーな方法です。このコンペでは、文章をより良く書き換え用prompt文を推測するために、testデータにおけるprompt文の多くは"improve the text to this"という文章が含まれています。なので、prompt文を予測せず全部回答をこの"improve the text to this"にしても、なんと類似度が0.58にもなるんです。そのために、今多くの参加者がコサイン類似度の変化から逆算して元の文章内にあるキーワードを見つけ出すことに注力しています。
ただし、この方法でやっても最後精度が高いわけではありません。パブリックスコアで用意されているtestデータは全データの15%しかないため、残りのデータには"improve the text to this"という文章がそれほど多くない可能性もあります。そうすると、最終的には大きなshakeが起きる可能性が非常に高いです。
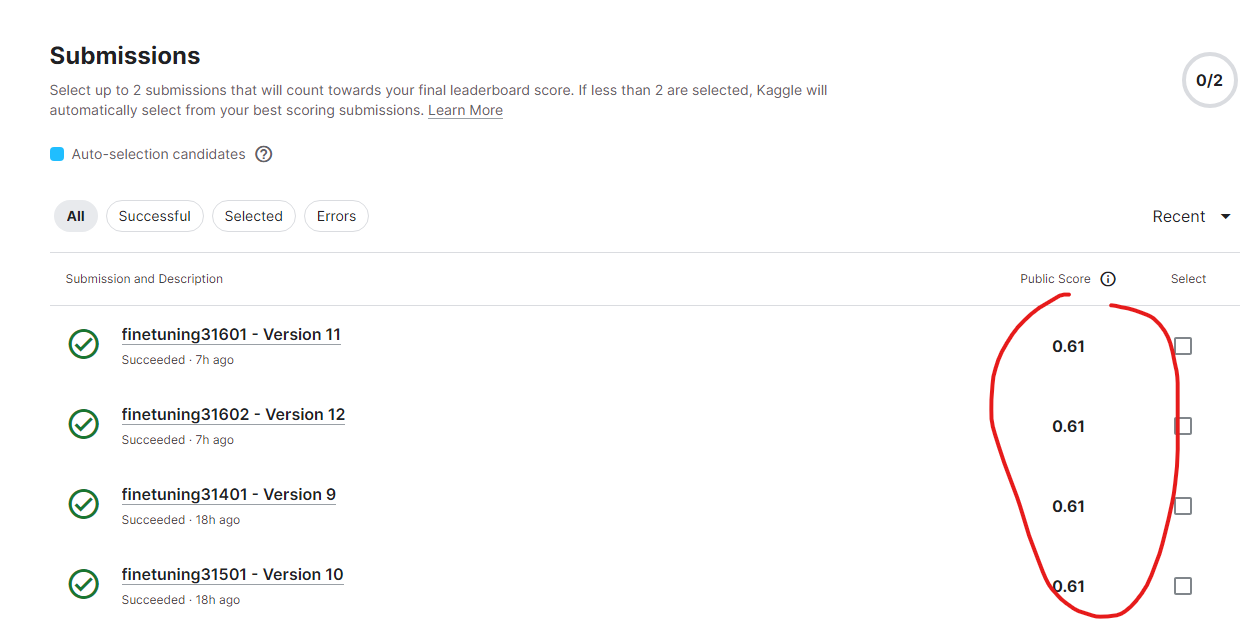
ですので、まだ誰も良い対策が見つかっていないのが現状で、上位者のスコアは非常に近づいています。0.62が銀メダル、0.61が銅メダル、0.63以上が金メダルといった感じです。加えて、このコンペではスコアが小数点以下2桁までしか表示されないため、異なる方法間の優劣を見極めるのも難しいです。私が最近提出した新しいモデルの結果はいずれも0.61で、それらの間には違いがあるはずですが、ランキングは変わってなかったので、どれが良いのかも判断することはできませんでした。(⇩)
興味ある方:
今回のコンペについて