画像系でよくある医用画像に対して、非常に良いデータ拡張手法MedAugmentを共有したいと思います。
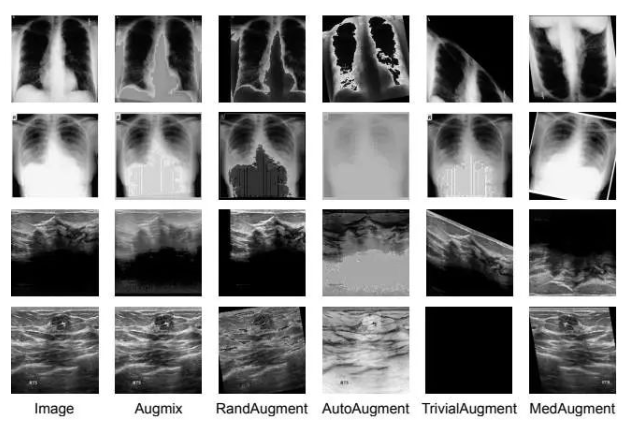
通常のデータ拡張手法、例えばAugmixやAutoAugmentは、一般的な画像処理には適していますが、
医用画像の分類やセグメンテーションにおいては性能が高くないことが多く、単純な回転や拡大の方が効果的な場合もよくあります。
MedAugmentは、医用画像に特化した手法です。
中身は少し複雑ですが、簡単に説明します。
開発者は、APとASの2つのデータ拡張操作グループを定義し、2つ合わせて14個の拡張手法を含む形で設計しました。
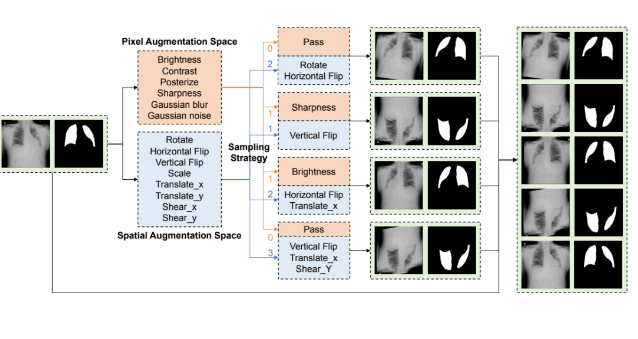
これに基づき、特定の組み合わせを持つ「サンプリング戦略」が導入されています。さらに、独自の「マッピング戦略」もあります。
*APはピクセル(PIXEL)に関連する手法で、例えば、輝度、コントラスト、ポスタライズなどです。
*ASは空間(Spatial)に関連する手法で、例えば、回転、拡大、平行移動などです。
①サンプリング戦略:
医用データは輝度に非常に敏感で、連続的にAP操作を行うと、出力画像が実物とかけ離れ、モデルの学習に悪影響が生じます。
そのために、開発者は「モデルをまずM回のAS操作を行い、その中にランダムなAP操作を1回含むようにする。AP操作は1回以下で、Mは2回~3回」を条件として設定しました。
②マッピング戦略:
MedAugmentに単一のハイパーパラメータを使用するため、開発者はiという単位を追加しました。このiは、各操作の強さをコントロールするために使用されます。
例えば、ポスタライズは学習の精度に大きな影響を与えるため、iはポスタライズのコントロールをより厳しくにし、結果としては学習がより良くなるといいます。
(こちらについての具体的な実現方法は私もよく理解していません。。)

MedAugmentはマッピング用のハイパーパラメータを一つだけにまとめて、それを「i」として表現しています。
この「i」は操作の強さを調整するためのものです。例として、ポスタライズは学習の精度に影響を及ぼすため、
「i」はポスタライズのコントロールをより厳しくにし、結果としては学習がより良くなるといいます。
(こちらについての具体的な実現方法は私もよく理解していません。。)
数年前Kaggleで行われた人間のタンパク質を分類するコンペのデータを使って、MedAugmentの効果をテストしました。
既存のコードはそのままで、データ拡張部分だけをMedAugmentにして、どれだけ精度が上がったのかを確認しました。
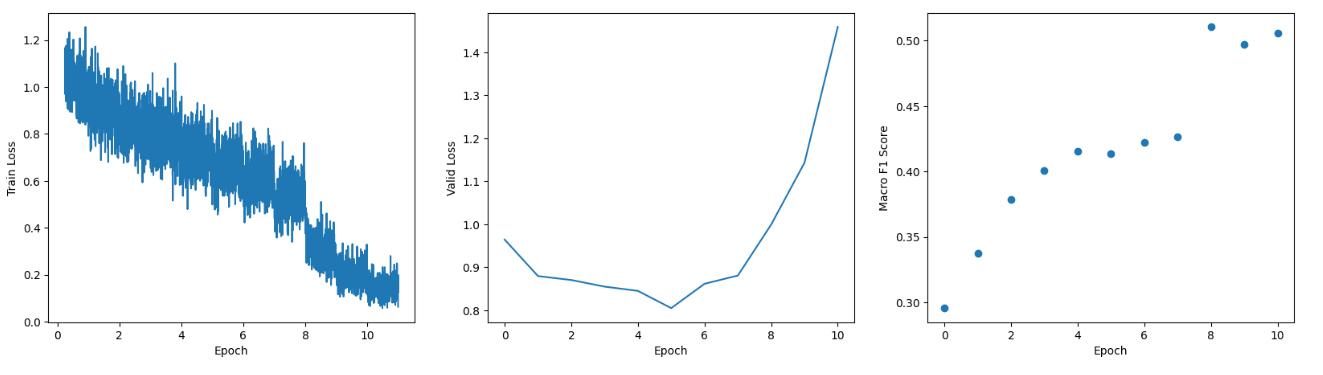
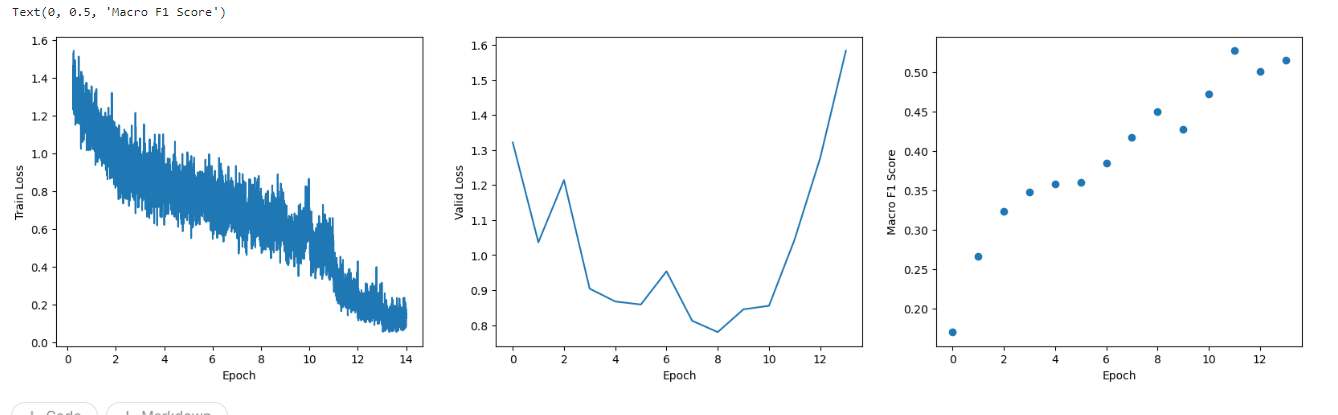
結果としては、精度自体(f1score)は約1.5%弱上がりました。(51.5%から53%)、全体的な学習過程もより安定にしています。
ただ、Valid lossを見ると、最後の振動が若干大きくなって、そちらをもっと収束すれば、さらに高い精度が得られるではないかと思います。
また、元のデータは約30,000件でなので、このデータ量でこのくらい性能出すのは結構良い手法だなと思いました。データ件数が少ない場合なら、更なる性能向上が期待できると考えています。
コードと論文は以下となります。興味あるは試してみてください。
コード:https://github.com/NUS-Tim/MedAugment
論文:https://arxiv.org/abs/2306.17466