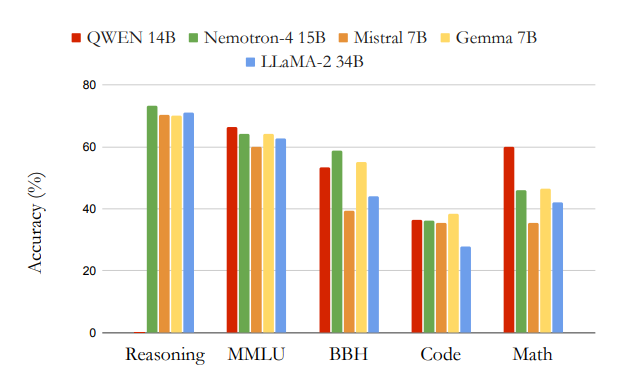
最近Nvidiaが自社のLLM「Nemotron-4」を発表しました。Nemotron-4は15BのLLMです。論文によると、このモデルは一般的なタスクにおいて、Gemma 7BやQwen、Mistralといったモデルを上回る性能を示しています。(⇩)
このモデルは、基本的なTransformerのdecoderアーキテクチャを採用しており、token数は4Kになります。使用された学習データは8Tで、その内訳は英語が70%、多言語が15%、プログラミング関連のデータが15%です。
前処理は、まず重複する内容を削除し、その後LLMを用いてデータクレンジングを行いました。このアプローチはGemmaと非常に似ています。
プレトレーニングは基本的なやり方ですが、継続学習にはGemmaを参考してトレーニングしたようです。トレーニングが完了した後、再学習用データの分布などを調整することで、精度を向上しました。具体的には、最初に8TBのデータを使ってプレトレーニングを行い、その後の継続学習では2つの異なるデータセットを使ってトレーニングを進めました。一つはプレトレーニングに使用されたデータで、高品質なデータの重みを重く設定して再度学習しました。もう一つは、ベンチマーク向けのトレーニングであり、精度評価に関連したデータを用意して、モデルがベンチマークの精度を向上するようにトレーニングしました。
全体的にみると、このモデルはGemmaと非常に似てます。アーキテクチャも似てますし、データクレンジングも似た手法で実施されました。あとは最後の継続学習はベンチマーク向けのトレーニングとなり、ベンチマークのfinetuningみたいな感じです。
最近OSSのLLMが多く公開されていますが、そのアーキテクチャやトレーニング手法、あと性能もほぼ同様で、ほんのわずかにMistralやGemmaを上回る程度であっても、実際の使用において違いはほぼありません。なので、全く異なるアーキテクチャを使用したモデルの公開は楽しみです。
興味ある方: