最近、Googleが「LangExtract」という情報抽出ライブラリを公開しました。GitHubでも話題になっていて、非構造化データをハイクオリティで構造化データに変換できるのが大きな特徴です。変換自体はLLMを使って行われるため、自然言語での指示だけで柔軟に情報を抽出できます。
特にユニークなのが「出典の追跡(ソーストレーシング)」の高精度です。従来の埋め込み検索ではなく、キーワードからコサイン類似度まで多層的にマッチングをし、どの部分から抽出された情報かを正確に示してくれます。そのため抽出結果が実際の本文に存在するのかをきちんと確認できるのです。
実際に使ってみる
今回はサンプルとして、トヨタ財団の2025年度事業計画書を入力にしてみました。⇩
抽出したい項目は以下のとおりです。
・計画(文書タイトル、章・節の見出し)
・目的/方針(本文の原文)
・プログラム(名称/概要)
・期間(開始日・終了日/年数)
・予算(金額と単位)
・関係者(組織/担当者/役割)
・募集期間/助成期間
・対象地域・対象分野
・KPI/目標値(数字があれば)
プロンプトは自然言語で書けるので、例えば以下のように指示を与えます。
prompt = textwrap.dedent("""\
本文書はトヨタ財団の2025年度事業計画です。以下の項目を出現順に抽出してください。
- 計画(文書タイトル、章・節の見出し)
- 目的/方針(本文の原文)
- プログラム(名称/概要)
- 期間(開始日・終了日/年数)
- 予算(金額と単位)
- 関係者(組織/担当者/役割)
- 募集期間/助成期間
- 対象地域・対象分野
- KPI/目標値(数字があれば)
重要:抽出は本文の原文テキストをそのまま使用し、言い換えないこと。各抽出には文脈を示す属性を付与してください。
例:{"type": "項目種別", "year": "2025", "unit": "千円", "role": "担当者", "start_date": "YYYY-MM-DD"}
""")
ちなみに、LangExtract公式のサンプルでは以下のようにシンプルに指示を渡します。

あとはfew-shotの例も与える必要があります。⇩
examples = [
lx.data.ExampleData(
text=(
"2025年度 事業計画書\n"
"目的:人々の幸せの実現\n"
"プログラム:国内助成プログラム\n"
"予算:90,000千円\n"
"募集期間:2025年4月〜6月\n"
"期間:2025年11月1日から3年間\n"
"担当:事務局長 田中太郎"
),
extractions=[
lx.data.Extraction(
extraction_class="計画",
extraction_text="2025年度 事業計画書",
attributes={"type": "文書タイトル", "year": "2025"}
),
lx.data.Extraction(
extraction_class="目的",
extraction_text="人々の幸せの実現",
attributes={"種別": "方針/目的"}
),
lx.data.Extraction(
extraction_class="プログラム",
extraction_text="国内助成プログラム",
attributes={"種別": "助成", "概要": "国内向けの助成プログラム"}
),
lx.data.Extraction(
extraction_class="予算",
extraction_text="90,000千円",
attributes={"単位": "千円"}
),
lx.data.Extraction(
extraction_class="募集期間",
extraction_text="2025年4月〜6月",
attributes={}
),
lx.data.Extraction(
extraction_class="期間",
extraction_text="2025年11月1日から3年間",
attributes={"開始": "2025年11月1日", "長さ": "3年間"}
),
lx.data.Extraction(
extraction_class="担当者",
extraction_text="事務局長 田中太郎",
attributes={"役割": "事務局長"}
),
]
)
]
実行結果
モデルにはGPT-4.1を使用しました。
結果はJSON形式で出力され、以下のとおり概ね期待どおりでした。
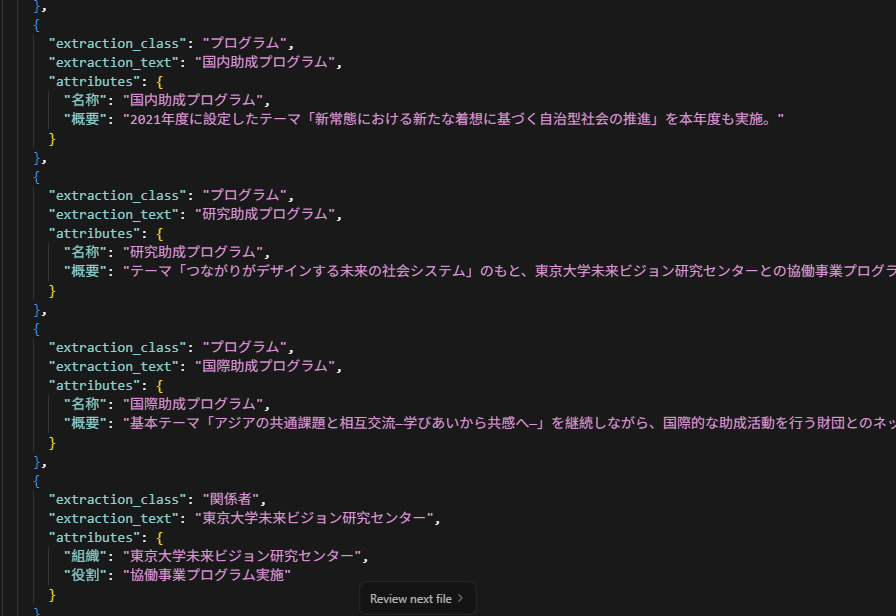
さらに、抽出結果を可視化するHTMLも自動生成されます。この画面から抽出元の本文がどこかを辿れるようになっていて、非常に便利です。

興味ある方: