今日は、自然言語処理において非常に重要な役割を果たすトークナイザについて説明したいと思います。
1.トークナイザとは
自然言語処理を行う際、まず最初に行わなければならない作業が、文章をコンピュータが処理可能な形式に変換することです。つまり、文章を単語や形態素などの基本的な単位であるトークンに分割する必要があります。この作業をトークナイズと呼び、トークナイズを実行するためのモデルが「トークナイザ」です。トークナイズ実行のイメージは以下の通りです。(wikipedia-jpの数百MBのデータを用いて学習したトークナイザによる分割例)
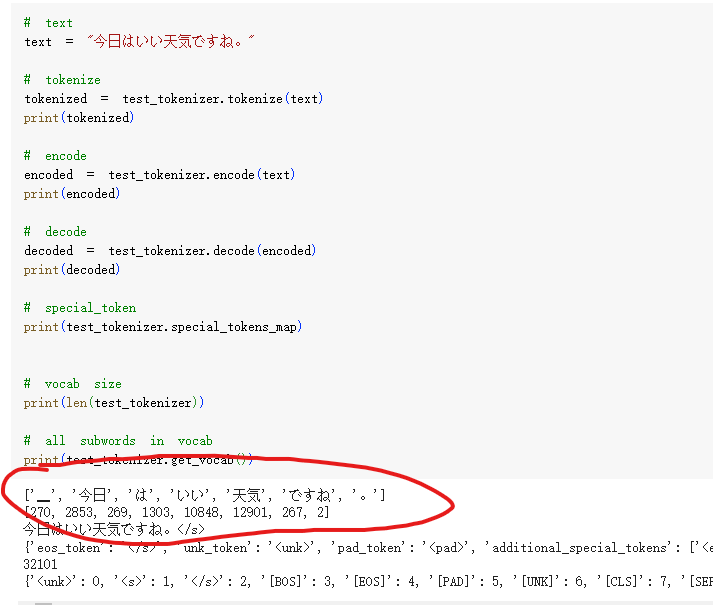
2.トークナイザの分割粒度
トークナイズの際には、主に3つの粒度”word”、”char”、”subword”があります。
Wordは最も自然な言語単位であり、特に英語などのスペースや句読点で単語が区切られている言語では、比較的容易にword単位で分割することができます。しかし、日本語や中国語などの漢字を使用する言語では、単語を分割するための特別なアルゴリズムが必要となります。一般的なvocab(tokenの辞書)のサイズは5万語以下であることが多いです。
Charは、アルファベットやひらがな、カタカナなどの文字単位です。(英語の'a'、'b'、'c'や日本語の'あ'、'い'、'う'など)ただし、charの文字数は限られているため、各文字のEmbeddingベクトルには多くの意味が含まれることになり、学習が非常に困難になるという問題があります。
Subwordは、charとwordの中間的な単位であり、両方の利点を取り入れた方法です。Subwordでは、頻繁に使われる単語はそのまま維持し、まれな単語はさらに分割するという処理を行います。(例えば、'Transformers'という単語を、'Transform'と'ers'の2つのsubwordに分割)文字数と意味の独立性のバランスを取ることができるため、今ほとんどのトークナイザはSubwordで分割します。
3.トークナイザでよく使われているアルゴリズム
最も一般的なトークナイザのアルゴリズムとしては、BPE(Byte-Pair Encoding)とSentencePieceが挙げられます。また、日本語の場合は形態素解析も使われてます。
BPEは、比較的前からあった基本的な手法で、最も頻繁に出現するSubwordペアを順次マージしていき、語彙数が予定のサイズに達するまで続けるという考え方に基づいています。
一方、形態素解析は日本語特有のアルゴリズムです。日本語では単語間にスペースがないため、単語の分割位置を特定するのが難しいという問題があります。そのため、MeCabなどの形態素解析器を用いてテキストを事前に分割し、その後にBPEやWordPieceなどで分割を行います。(中国語も同様の特性を持つため、中国語のトークナイザーでも形態素解析は実施します)
ただ、形態素解析による単語の事前分割は日本語では効果的ですが、他の言語には適用できないため、汎用性からは課題があります。この課題を解決する手法の一つが、SentencePieceです。SentencePieceは、Googleが公開されているオープンソースのトークナイザーであり、テキストを事前に単語で区切るのではなく、分割方法そのものを生の文章から直接学習するというアプローチを取っています。
具体的には以下の4つの処理を行います。
Unicode Normalization:テキストデータを正規処理
Trainer:Subword単位の分割方法を学習
Encoder:テキストをSubword単位に分割
Decoder:分割されたテキストを元のテキストに復元
簡単に言うと、SentencePieceは、Encoderでテキストをsubword単位に分割し、Decoderで元のテキストに復元するトークナイザーだと言えます。
詳細については⇩の論文で説明されています。興味ある方ご覧ください:
こちら⇩も参考になれます: