先日LLMのマージ(複数のLLMを一つに結合して精度を向上するテクニック)を試してみました。mergekitというフレームワークを使って行いました。
mergekitの使い方はとてもシンプルで、マージしたいモデルと評価指標を設定し、必要なパラメータを調整するだけで、マージがスタートできます。
1. 評価指標について
私が使用した評価指標は、現在日本語モデルの評価でよく使われている”elyza-100”と”JGLUE”
です。イメージとしては以下の感じです。(複雑な指示・タスクを含む日本語データです)

2. 利用モデル
今回、私は中国語と日本語のモデルのマージを試しました。使用したモデルはqwen-1.5-7bとrinna-7bで、それぞれ選んだ理由もあります。
qwenは現在中国語で最も性能の高いモデルであり、rinnaはqwenをベースに継続学習で開発されたモデルなので、モデルの構成やレイヤーのベクトルサイズなども似ってますので、マージしやすいです。(もし他の日本語モデルを使いたいなら、レイヤー変換のコードを別途作成する必要があります。)
マージ処理はA100上で10時間くらいでできました。(⇩マージ際のスクリーンショット)

マージ後のモデルを実際に試してみた感想としては、初級レベルの日本語能力を得る代わりに、その分中国語能力も高から中に低下したように感じました。(モデルサイズが小さいのが原因かもしれません。)
⇩はマージ後のモデルが日本語の質問に対して日本語で回答している例です。デフォルトのqwenなら同じ質問に対して中国語で回答してしまいます)
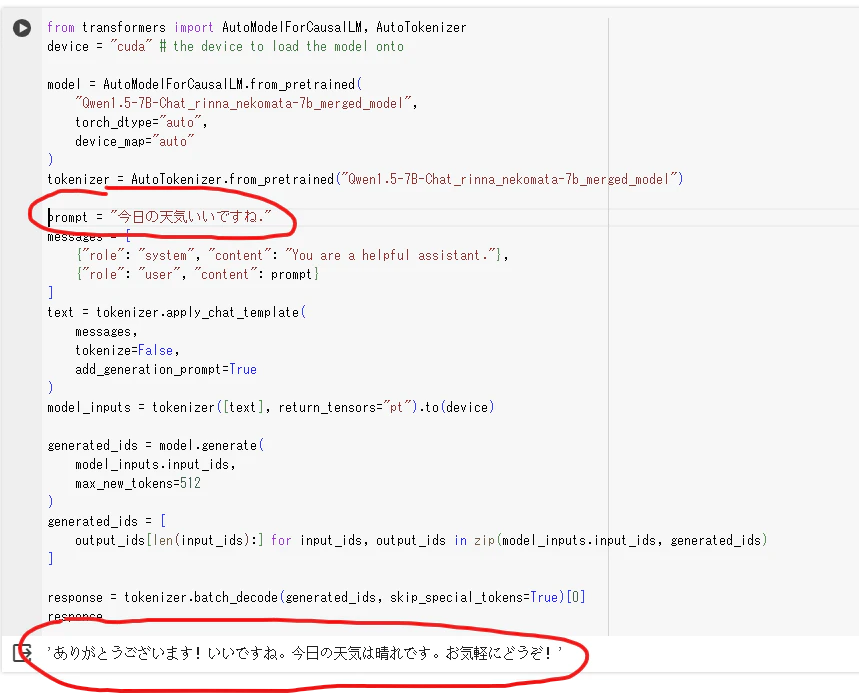
今度マージ後モデルのベンチマークテストも試してみたいと思います。
参考: