PDFの内容(英語)を翻訳する
最近、論文を読む事も大事なインプットになると思い始めた。しかし、英語やドイツ語などの母国語以外で書かれている論文はそのまま理解することが難しく、PDF形式だとコピペして検索が出来ない。この問題を解決すべく、PDF形式の論文を翻訳する機能をpythonで実装する事にした。しかし、ただ翻訳するだけでは面白みがないので対話形式で翻訳範囲の指定まで行ってくれるチャットボットをLINEmessagingAPIを使って作成した。
pythonパッケージのgoogletransを実装してGoogle翻訳に文字列をhttpで渡して文章の翻訳を行う。googletransはGoogle Translate APIを実装した無料で無制限の pythonライブラリである。また、チャットボットからの返信はpythonの扱いやすさによって、返信数と返信内容を自在に組み替える仕様を実現した。スクリーンショットにて以下にチャットボットとのコミュニケーションを公開する。
前提事項
googletrans(pythonライブラリ)について
- 単一テキストの最大翻訳文字数は1500字まで
- Google翻訳の制限に依存する
LINEmessagingAPIについて
- LINEmessagingAPIについて、文字数は基本1通2000文字でテキストは一度に5通まで送れる
- フリープラン契約
- URLのエンドポイントは1箇所のみ
その他
- PDFによっては10000文字を超えるものが存在する
- 翻訳するPDFファイルはローカル環境にダウンロードしたものを使用する
翻訳フロー
-
チャットボットにPDFファイルのパスを渡すと全体のページ数に応じてページを指定して翻訳するか、全ページを一気に翻訳するかをチャットボットが判断してくれる。
-
ページ指定の場合は最小(1ページ)ページ数から最大ページ数までをページ番号による指定ができ、指定範囲外のページが指定されたならもう一度ページ範囲の指定を要求してくる。
-
ページの確認を行う。
-
確認後、PDFと同一のディレクトリに"translation_yyyymmdd.txt"の翻訳版のテキストファイルが作成される。
(※論文等の最新の技術を文書にまとめている場合、翻訳しきれない単語が含まれる場合があるのでその場合にコピペをしてネットで調べる対応が取れるようにテキスト形式に保存する事にした。)
DEMO
- PDFのファイルパスを入力すると頃から始まる
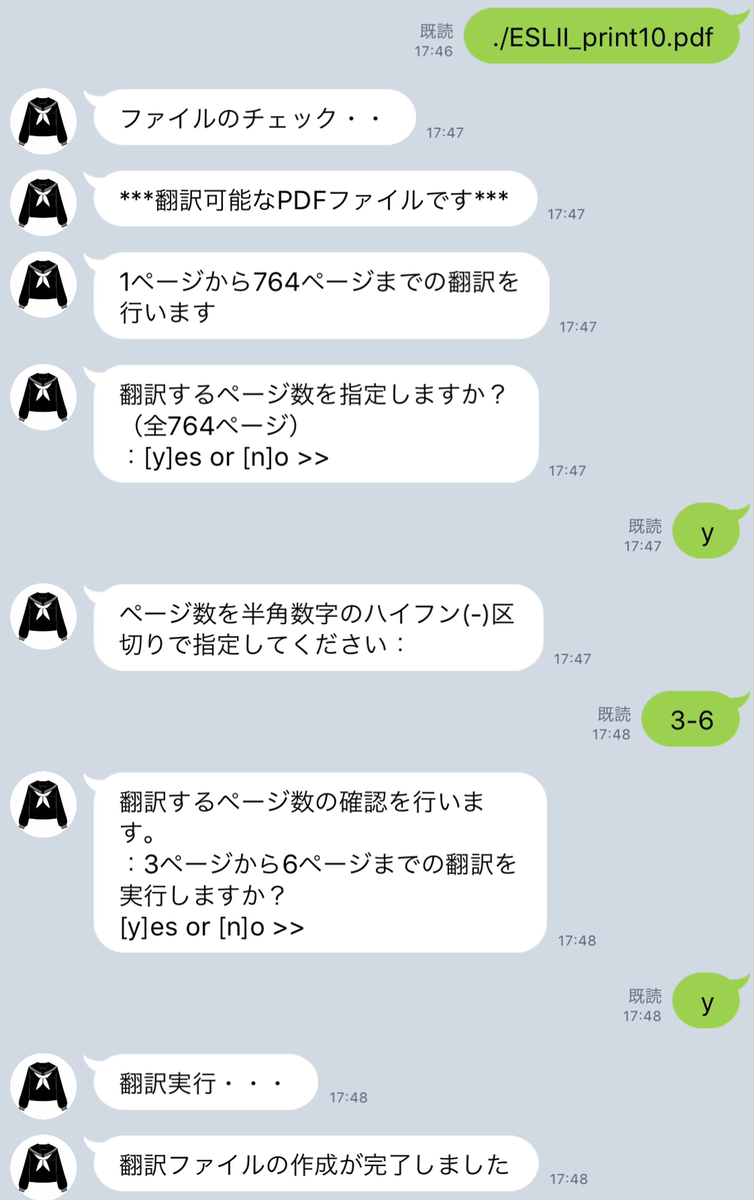
- ファイルの作成が完了するとローカルのPDFと同じディレクトリに翻訳済みのテキストファイルが生成される。
pythonでの処理で苦労した点
-
LINEmessagingAPIを使用して返信を分けて送信する際の値(text)の持ち方と処理に対する返信内容の変更
処理ごとに異なる数のメッセージを送信したかったので、メッセージをlist型の変数に格納してそのリストの長さによって出力するメッセージの数を分岐させる処理をpythonで実装する事で解決した。 -
会話の内容(一つ前の処理)を記憶する方法の策定
各処理ごとにハッシュ値を与えて前回の会話の結果をハッシュ値で管理する方法を取る事でセッションごとに処理の流れが切れないようにした。こちらはpython のファイルへの書き込みや読み込みが簡単に行えるopen()関数やwith構文のおかげで楽に実装することが出来た。
改善点
- 生成された翻訳後の文書の中で、翻訳しきれていない新しい言葉や専門的な言葉に対応できるようにpythonで別の翻訳機 (ニューラル機械翻訳を検討)を作成する。
- 翻訳しないときはbotと会話が楽しめるようにMeCabによる形態素解析とpythonでkerasをインストールする事で使えるseq2seqによって対話を生成(ある対話文章に対する応答を自動的に生成する)し、簡単なコミュニケーションが取れるようにする。