はじめに
乃木坂46ブログの画像保存をPythonによるスクレイピングで行いました。
秋元真夏の最初の1ページをスクレイピングしました。
コード
scraping.py
import requests
import urllib.request
import os
from bs4 import BeautifulSoup
def scraping():
# メンバーURL
member_name = "manatsu.akimoto"
url = "http://blog.nogizaka46.com/" + member_name + "/"
# フォルダ作成
if not os.path.isdir(member_name): # ”member_name”のフォルダがない場合
print("フォルダ作成")
os.mkdir(member_name)
# 保存枚数カウント用
cnt = 0
# BeautifulSoupオブジェクト生成
headers = {"User-Agent": "Mozilla/5.0"}
soup = BeautifulSoup(requests.get(
url, headers=headers).content, 'html.parser')
# 画像が置かれているhtmlを見つける
for entry in soup.find_all("div", class_="entrybody"): # 全てのentrybodyを取得
for img in entry.find_all("img"): # 全てのimgを取得
cnt += 1
urllib.request.urlretrieve(
img.attrs["src"], "./" + member_name + "/" + member_name + "-" + str(cnt) + ".jpeg")
print("画像を" + str(cnt) + "枚保存しました。")
if __name__ == '__main__':
scraping()
メンバーURL
メンバーの名前がURLとして使用されているので、取得したいメンバーの名前をmember_nameに入れています。
member_name = "manatsu.akimoto"
url = "http://blog.nogizaka46.com/" + member_name + "/"
BeautifulSoupオブジェクト生成
以下のサイトに分かりやすく説明があります。
参考サイト: https://python.civic-apps.com/beautifulsoup4-selector/
画像が置かれているhtmlを見つける
ブログを構成しているhtmlを見ると、
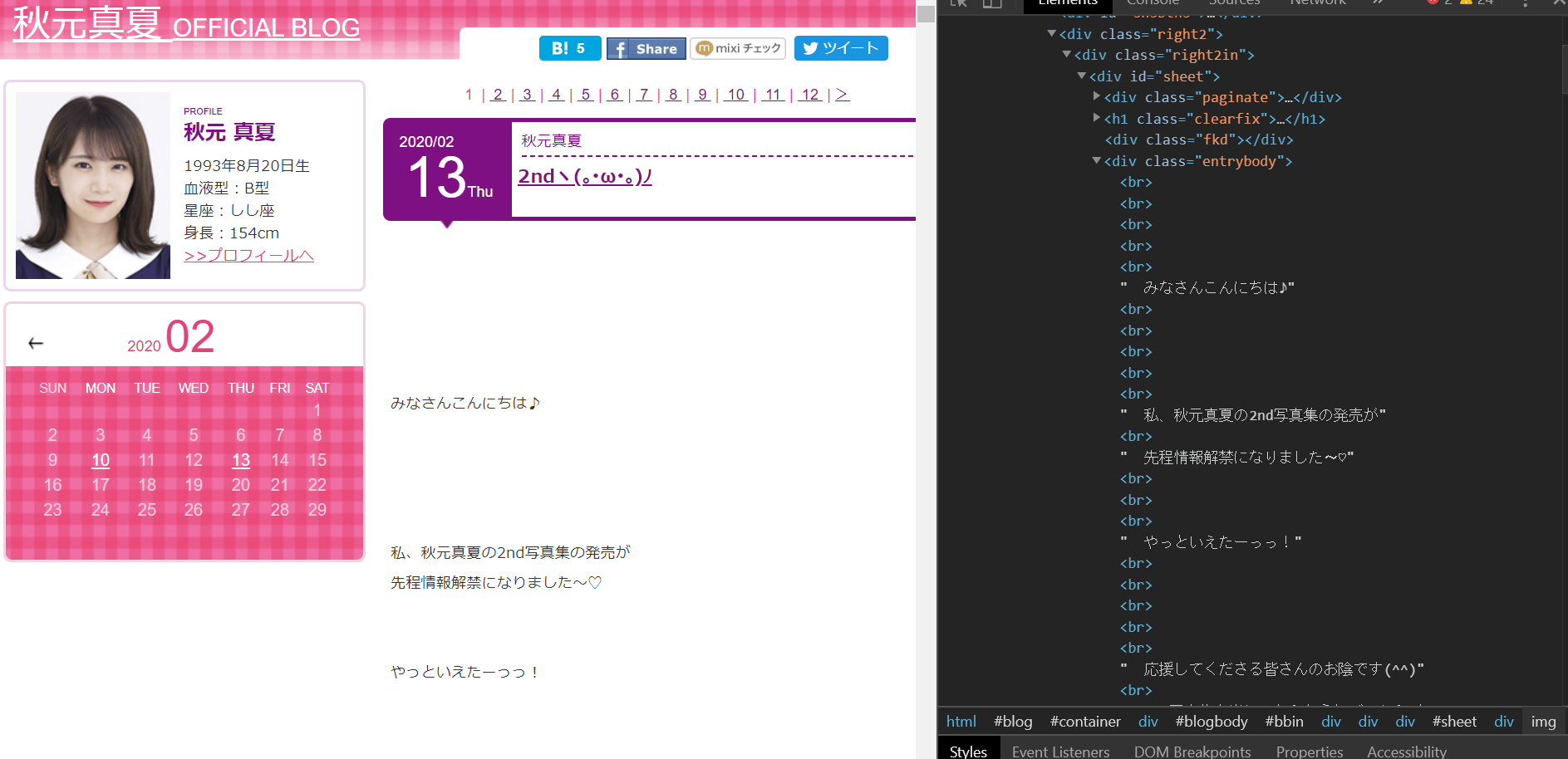
クラス名”entrybody”のdivタグに本文があり、
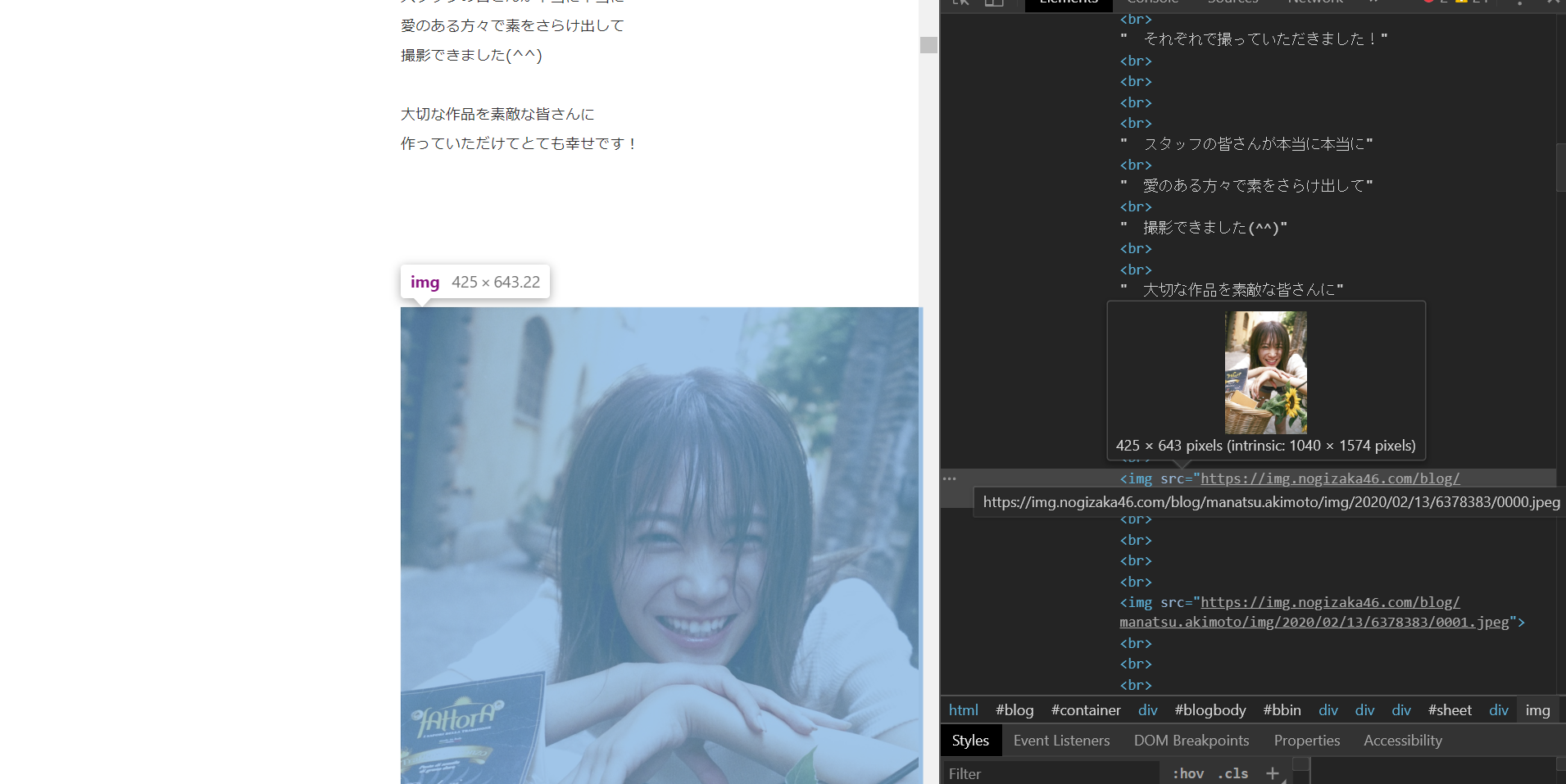
その中のimgタグに画像があるので、見つけ次第フォルダに保存します。
for entry in soup.find_all("div", class_="entrybody"):# 全てのentrybodyを取得
for img in entry.find_all("img"):# 全てのimgを取得
cnt += 1
urllib.request.urlretrieve(img.attrs["src"], "./" + member_name + "/" + member_name + "-" + str(cnt) + ".jpeg")
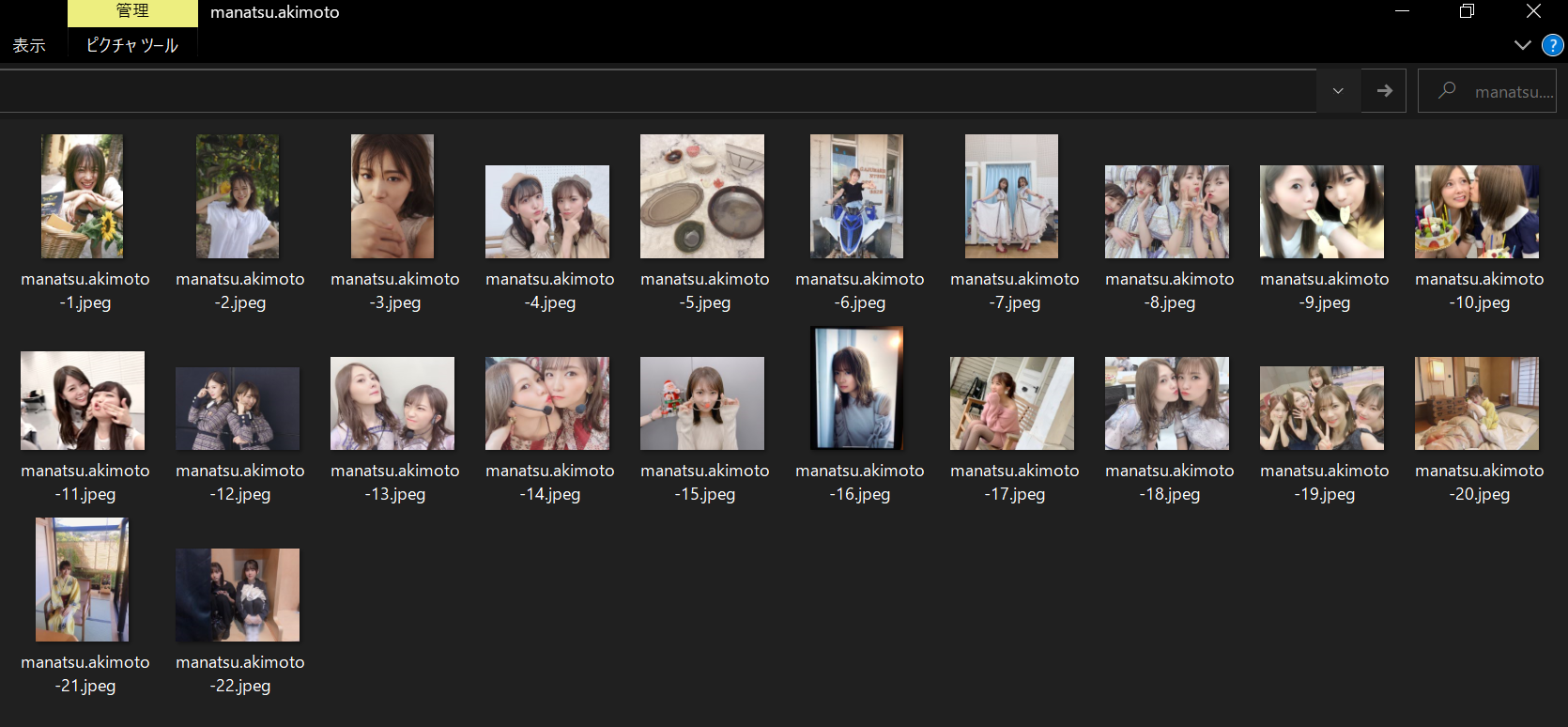
実行結果
実行当時のページ

作成されたフォルダ
コマンドライン表示
フォルダ作成
画像を22枚保存しました。