背景###
ここまで来たら、すでに、Offset情報と信頼度の訓練が行いました。つまり、VGG16層とOffset層とConf層から出力されたOffset情報と信頼度をそのまま使えます。そのまま使って、目標物体の枠と目標物体のカテゴリーを描きます。
しかし、そのまま使うことではなく、データを処理する必要があります。
目的###
SSDモデルから出力されたOffset情報と信頼度情報を使って、目標物体の枠と目標物体のカテゴリーを描きます。
推論###
SSDモデルからの出力####
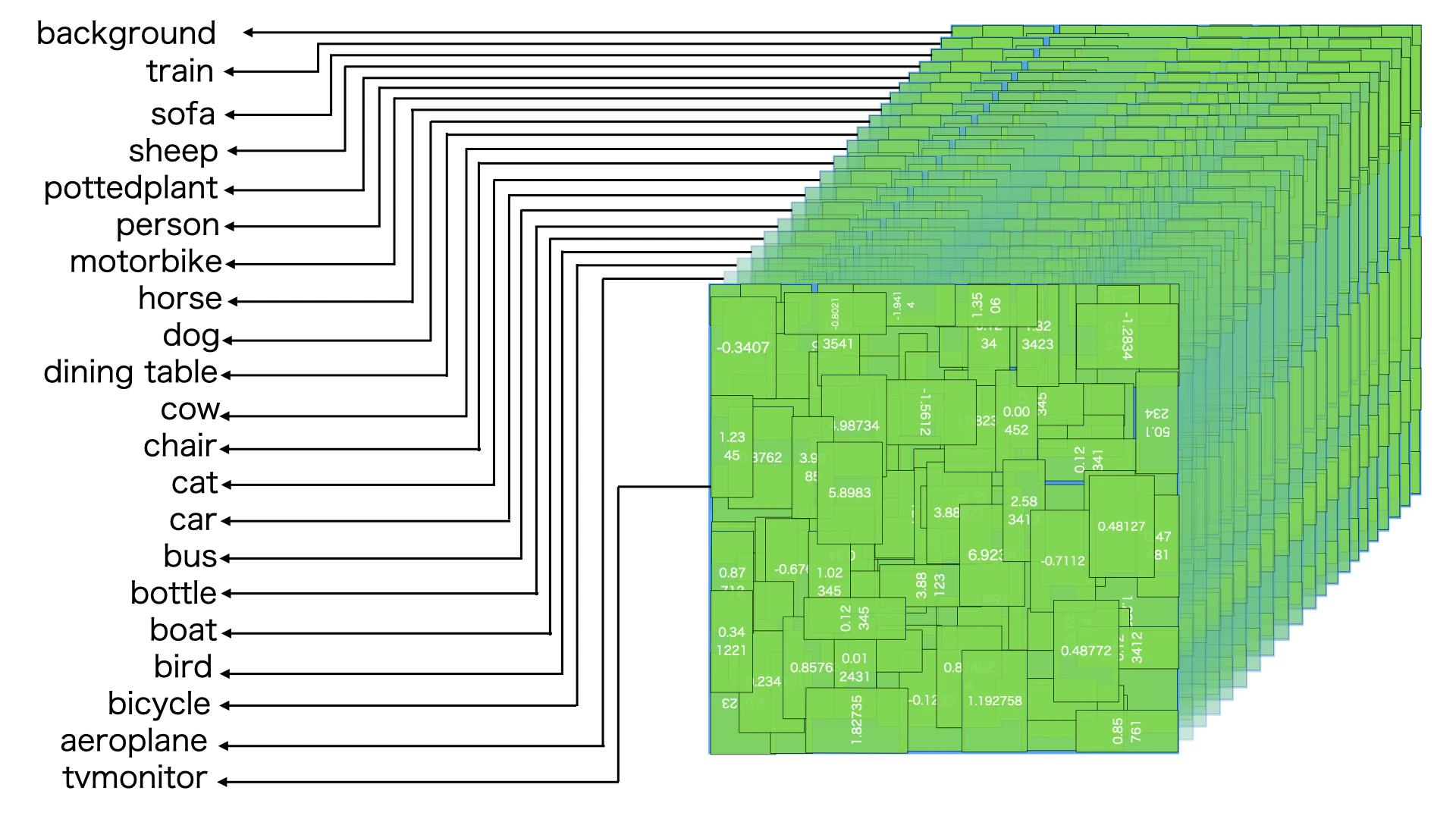
図のように、SSDモデルは21カテゴリーにて、それぞれのカテゴリーに8732このデフォルトボックス(事前に用意するもの、毎回同じ)に対して、Offset情報を提供しています。それぞれのデフォルトボックスにたいして、21カテゴリーのなかにある信頼度情報も提供しています。
Offset情報#####
一つのデフォルトボックスは21個の複数の同じものがあります。SSDモデルからそれぞれのデフォルトボックスに提供するOffset情報(△cx,△cy,△w,△h)も21個の同じものがあります。
信頼度情報#####
一つのデフォルトボックスは21個の複数の同じものがありますが、SSDモデルからそれぞれのデフォルトボックスに提供する信頼度情報はお互いに異なります。
流れ####
以下のバイディングボックスはOffset情報を使って、デフォルトボックスから変形したものです。
信頼度情報Softmax#####
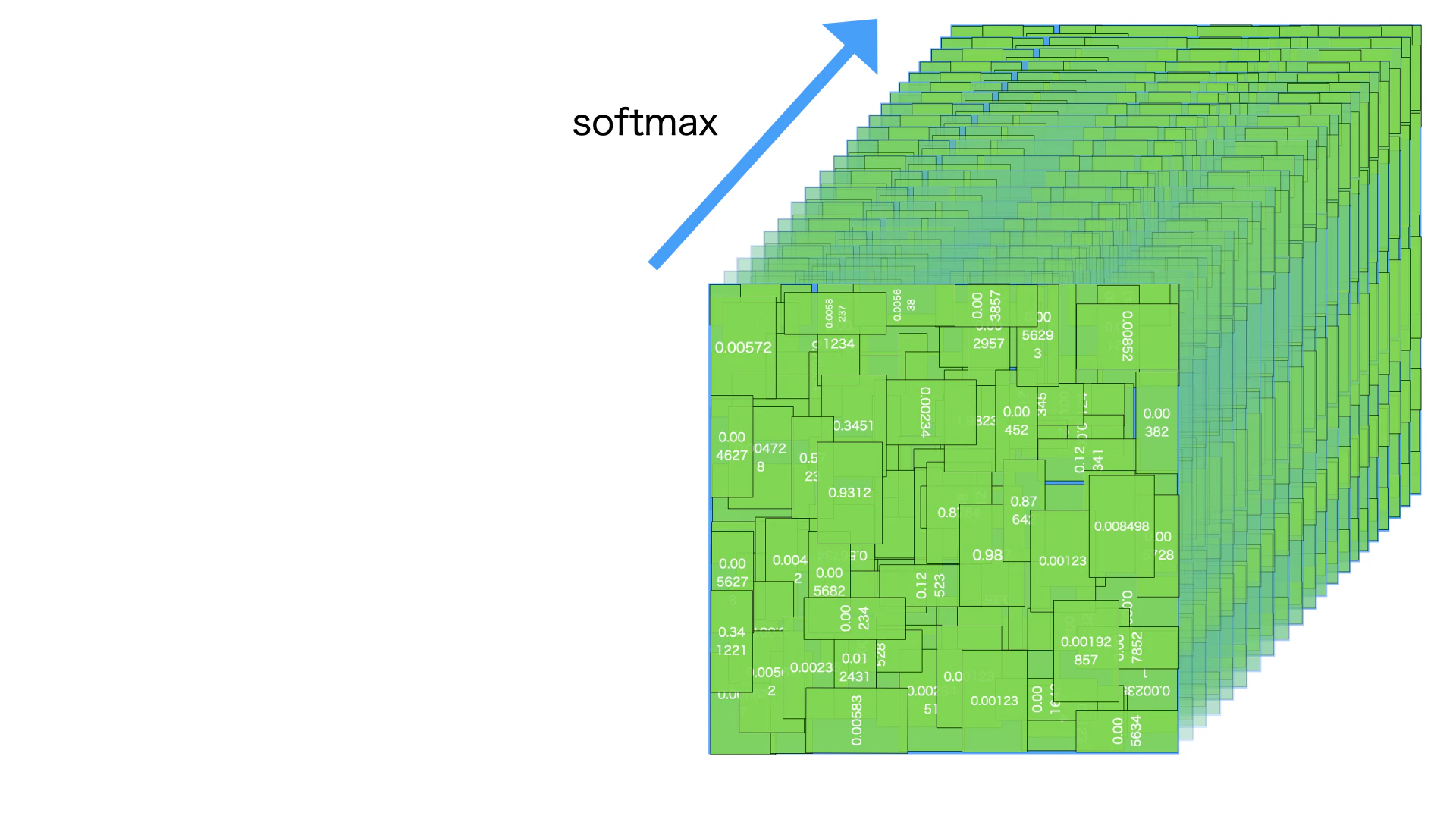
図のように、まず各バイディングボックスに対して、カテゴリー軸にsoftmax計算を行わせます。
つまり、このバイディングボックスに対して、それぞれのカテゴリーの信頼度を0-1の数値を表せます
nm_supression#####
次はnm_suppresion処理をかけます
これからの例は一つのカテゴリーを例にして説明いたします。
実際はnm_supressionがカテゴリーごとに行われてます。これからの処理を21回行われました。
ステップ1. 信頼度から洗い出す######
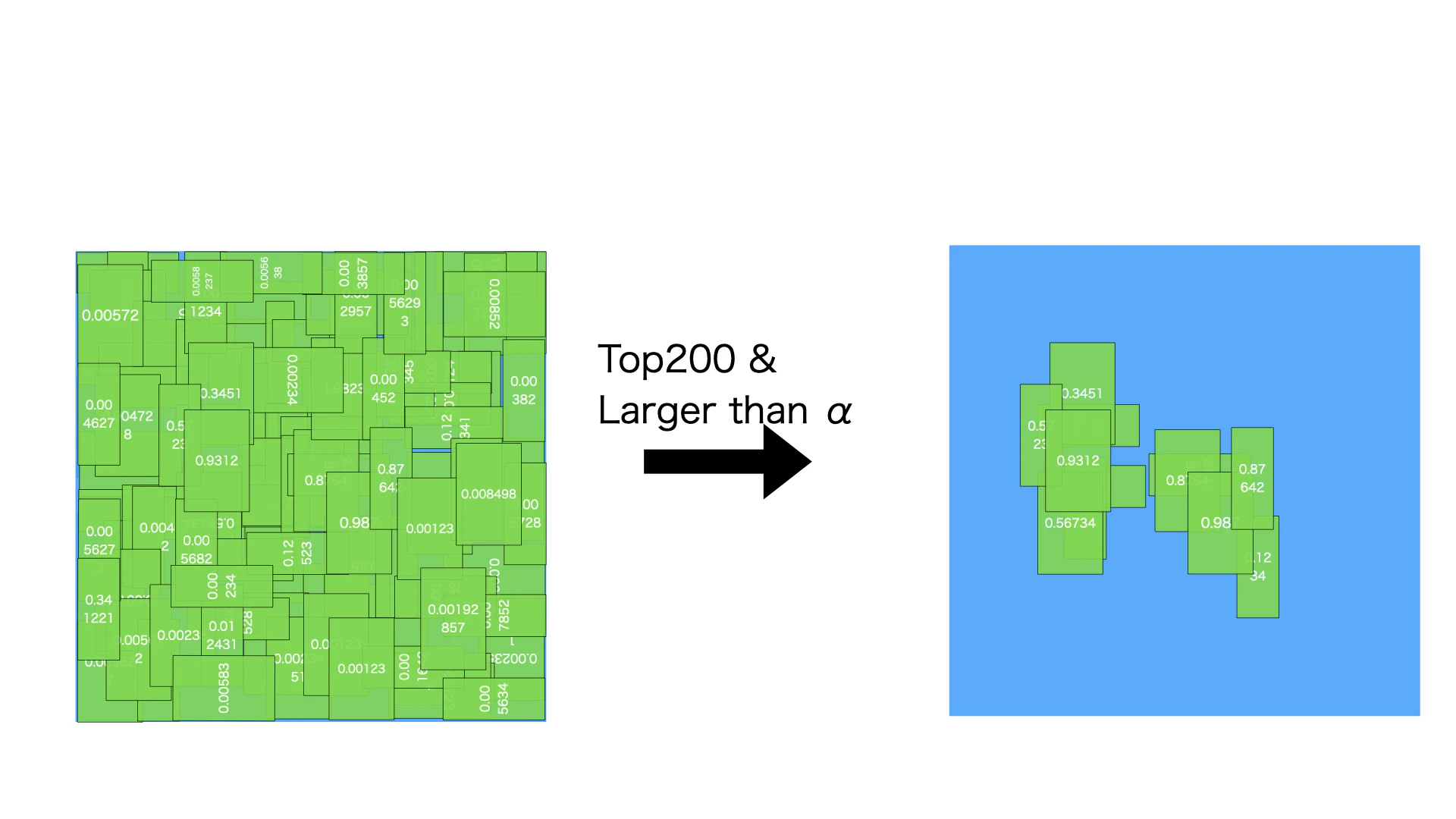
図のように、まず信頼度が上位の200 プラス条件 信頼度がαより大きいバイディングボックスを洗い出します
ここのαが0.01にしています。ずのように、洗い出されたバイディングボックスはわずか少しだけです。
ステップ2. 信頼度一番大きいバイディングボックスを特定
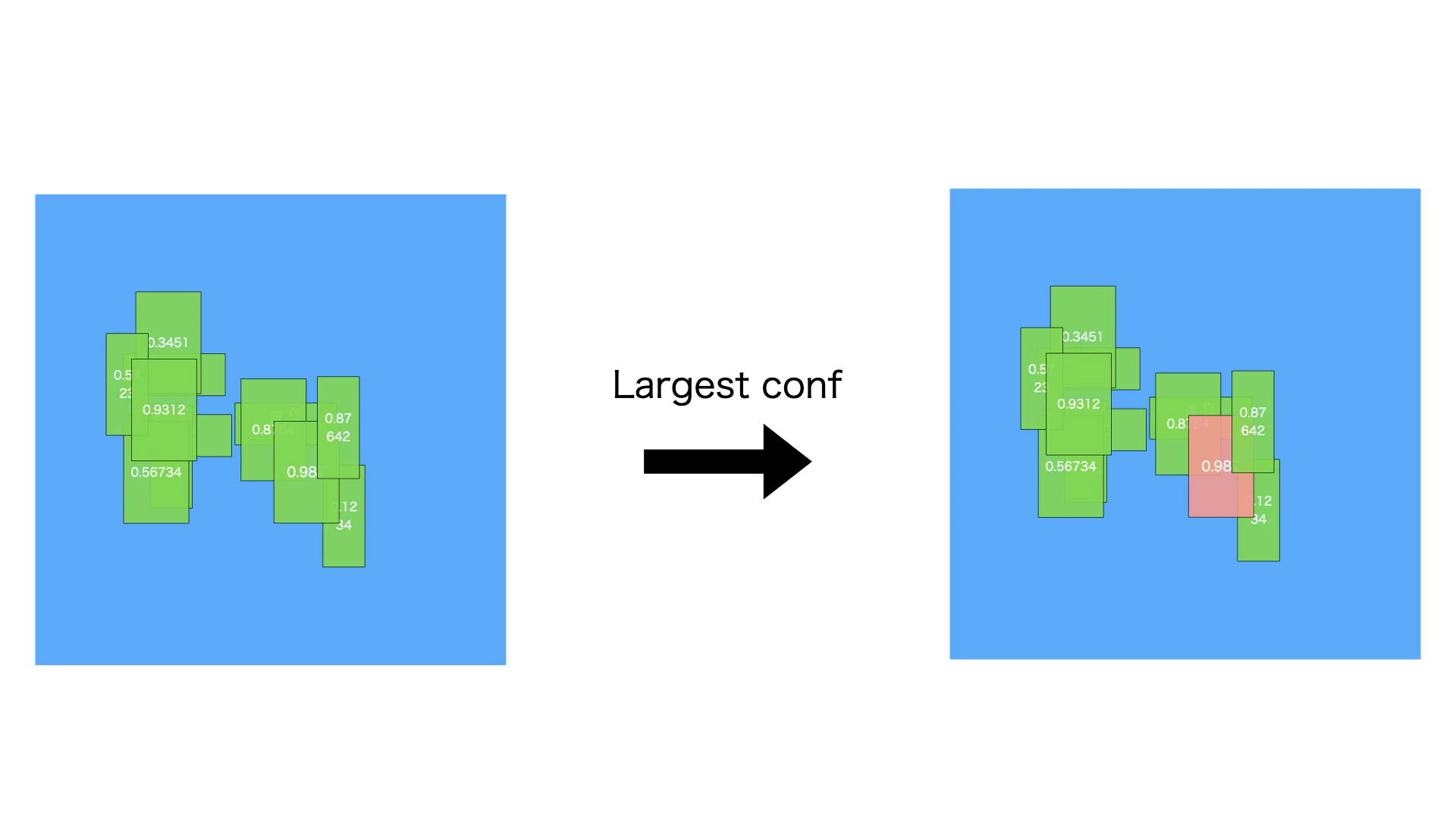
図のように、ピンクのバイディングボックスの信頼度は0.987、これは一番大きい信頼度です
ステップ3. IOU計算

図のように、ピンク以外なバイディングボックスとピンクをIOU計算をします。それぞれのIOUを数値で表しています。
※PS(Offset情報を訓練するときにもIOUの計算も行いました、それは各バイディングボックスの教師データGround Truthを特定するためです)
ステップ4. 重複バイディングボックスの除外######
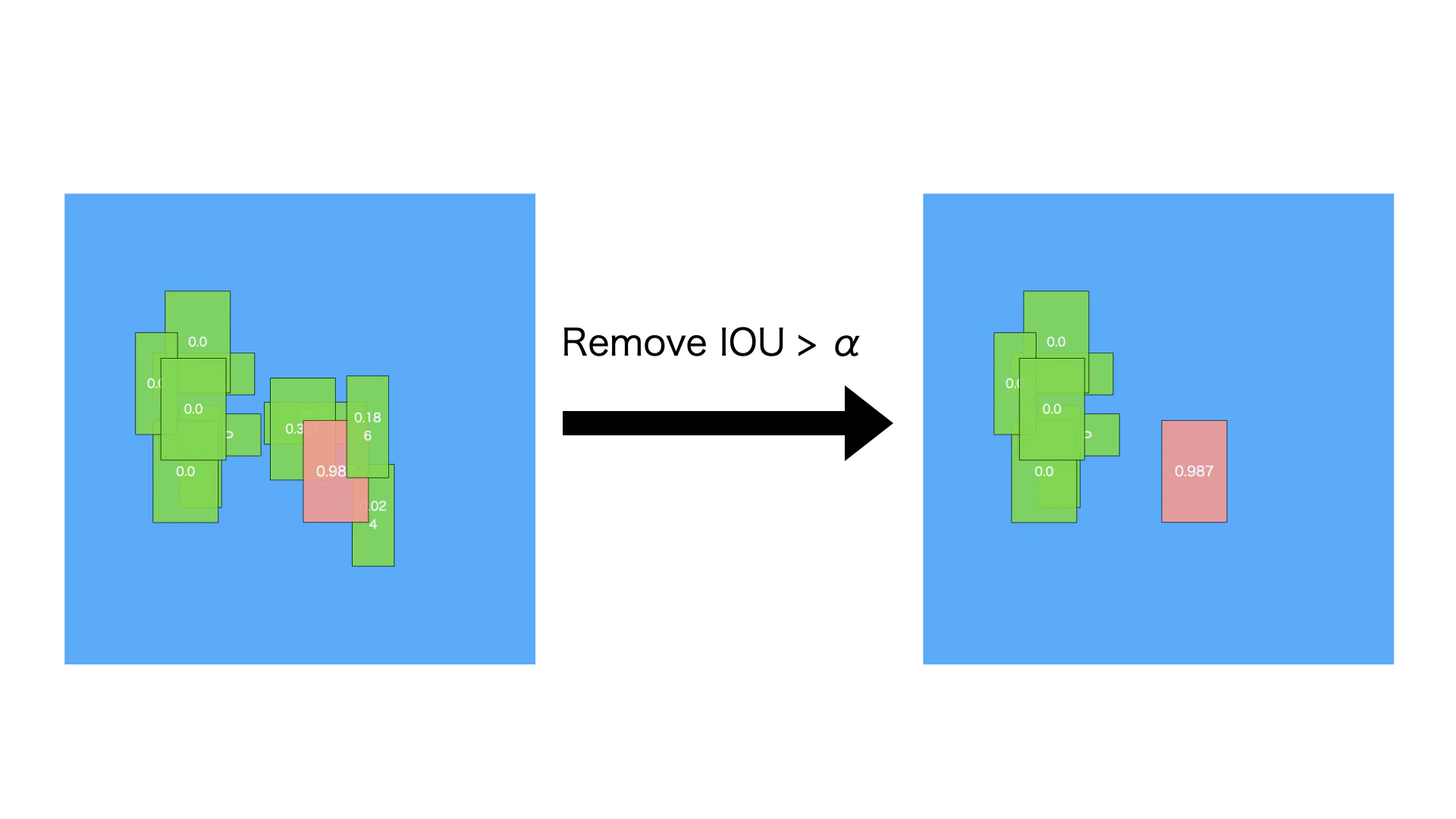
図のようにIOUがαより大きいバイディングボックスを重複バイディングボックスとして除外します。ここのαは通常0.45です
ステップ5. ステップ2の繰り返す
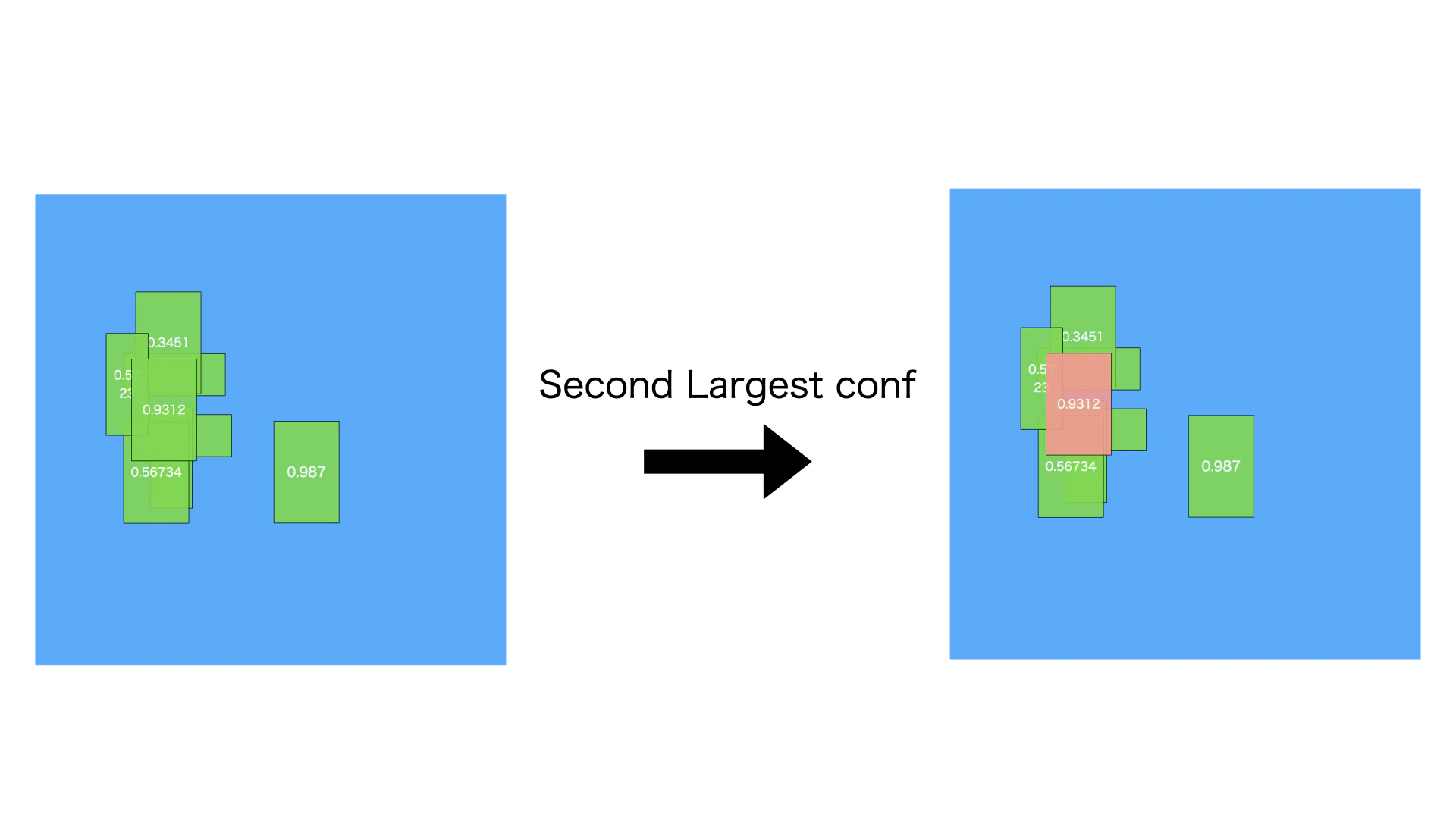
ずのように、ステップ4の除外処理後、もしピンク以外バイディングボックスがまたある場合は、二番目信頼度が大きいバイディングボックスを特定します
ステップ6. ステップ3の繰り返す
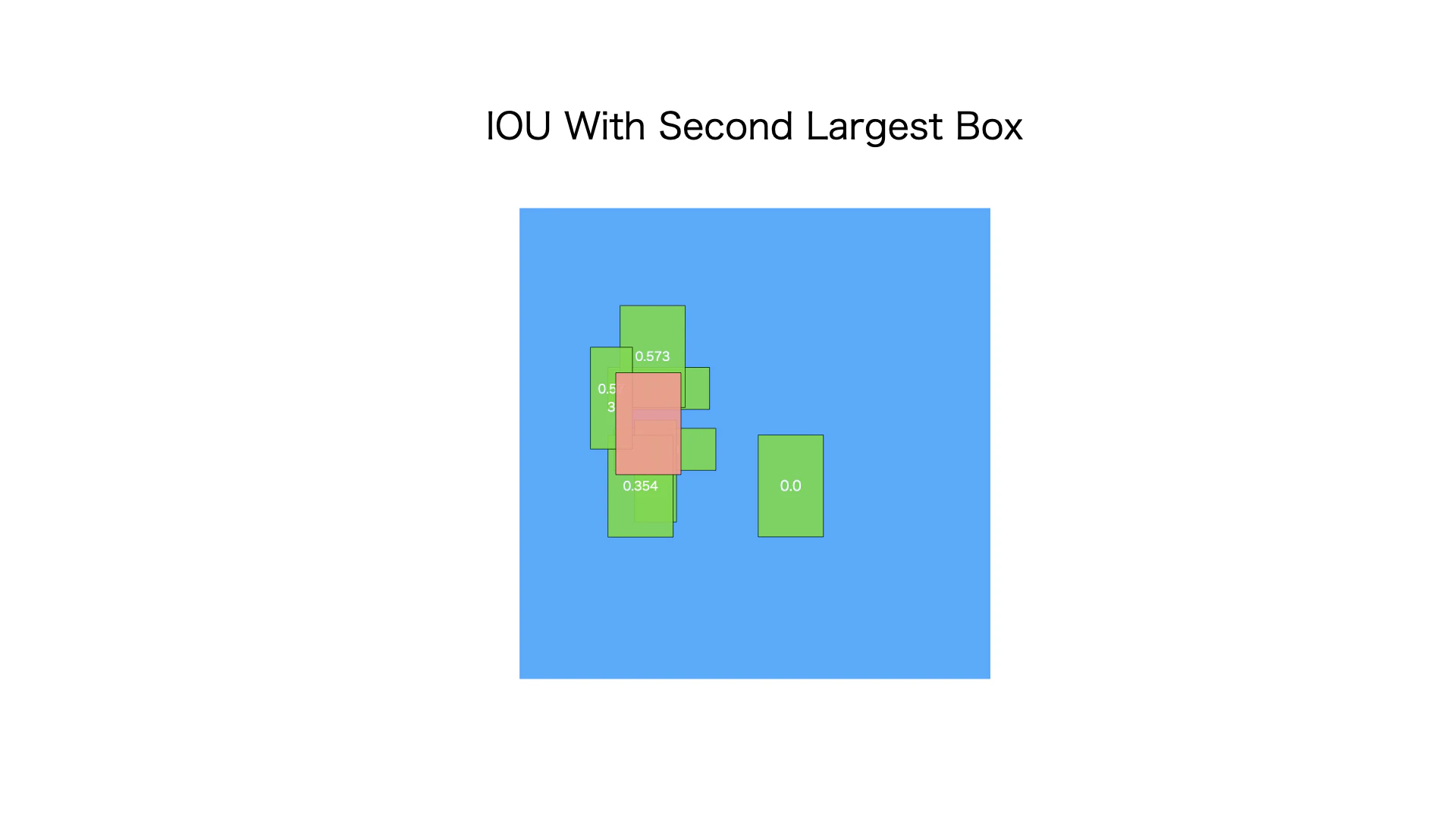
ずのように、ピンク以外なバイディングボックスと二番目信頼度が高いバイディングボックスとIOU計算をします
ステップ7. ステップ4の繰り返す
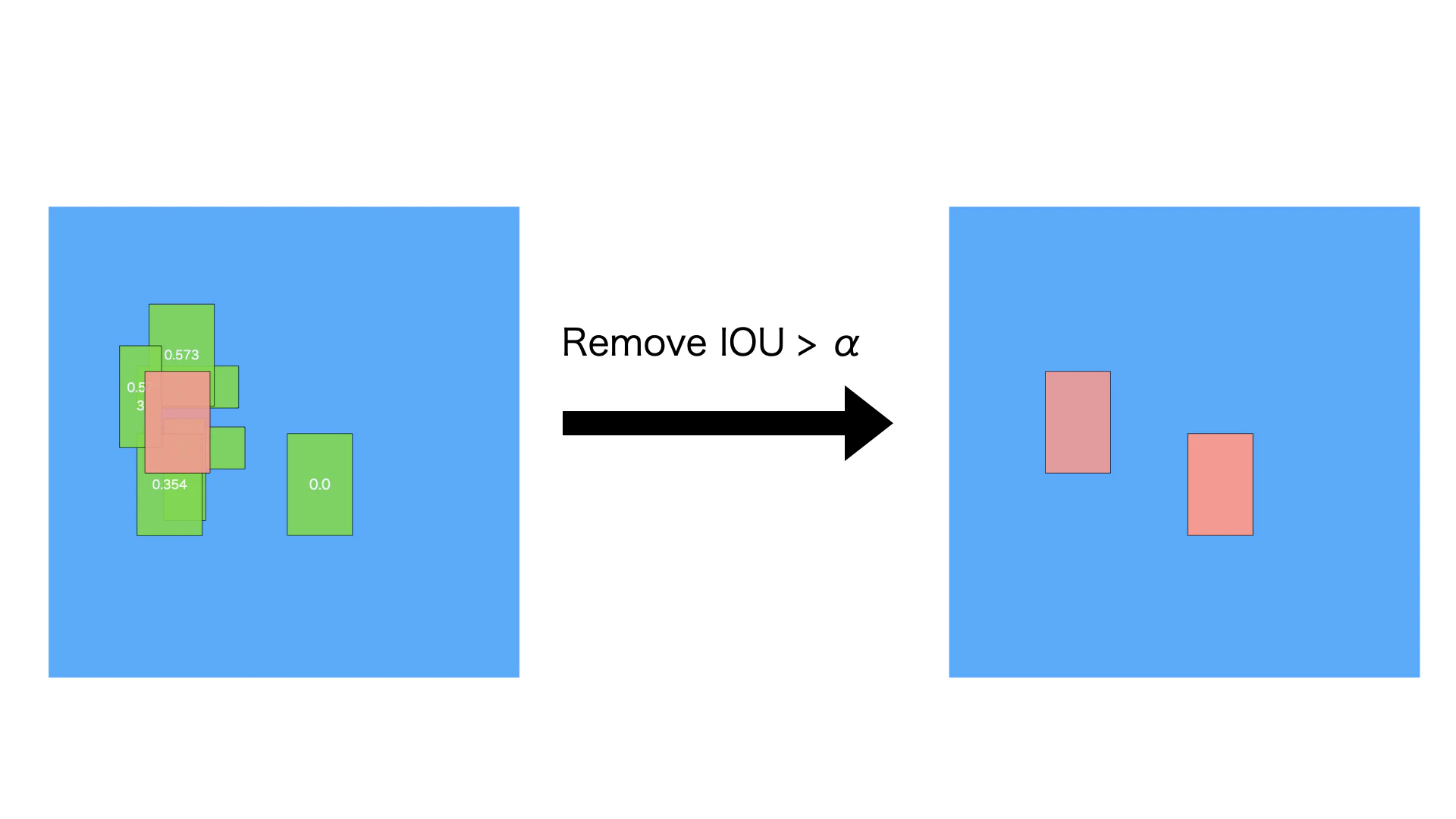
図のように、IOUがαより大きいバイディングボックスを除外します。通常αが0.45です
ステップ8. 結果生成
 残りのバイディングボックスが0になるまで、ステップ2からステップ4を繰り返して処理を行わせます。最後に残ったピンクのバイディングボックスは推論のバイディングボックス
残りのバイディングボックスが0になるまで、ステップ2からステップ4を繰り返して処理を行わせます。最後に残ったピンクのバイディングボックスは推論のバイディングボックス
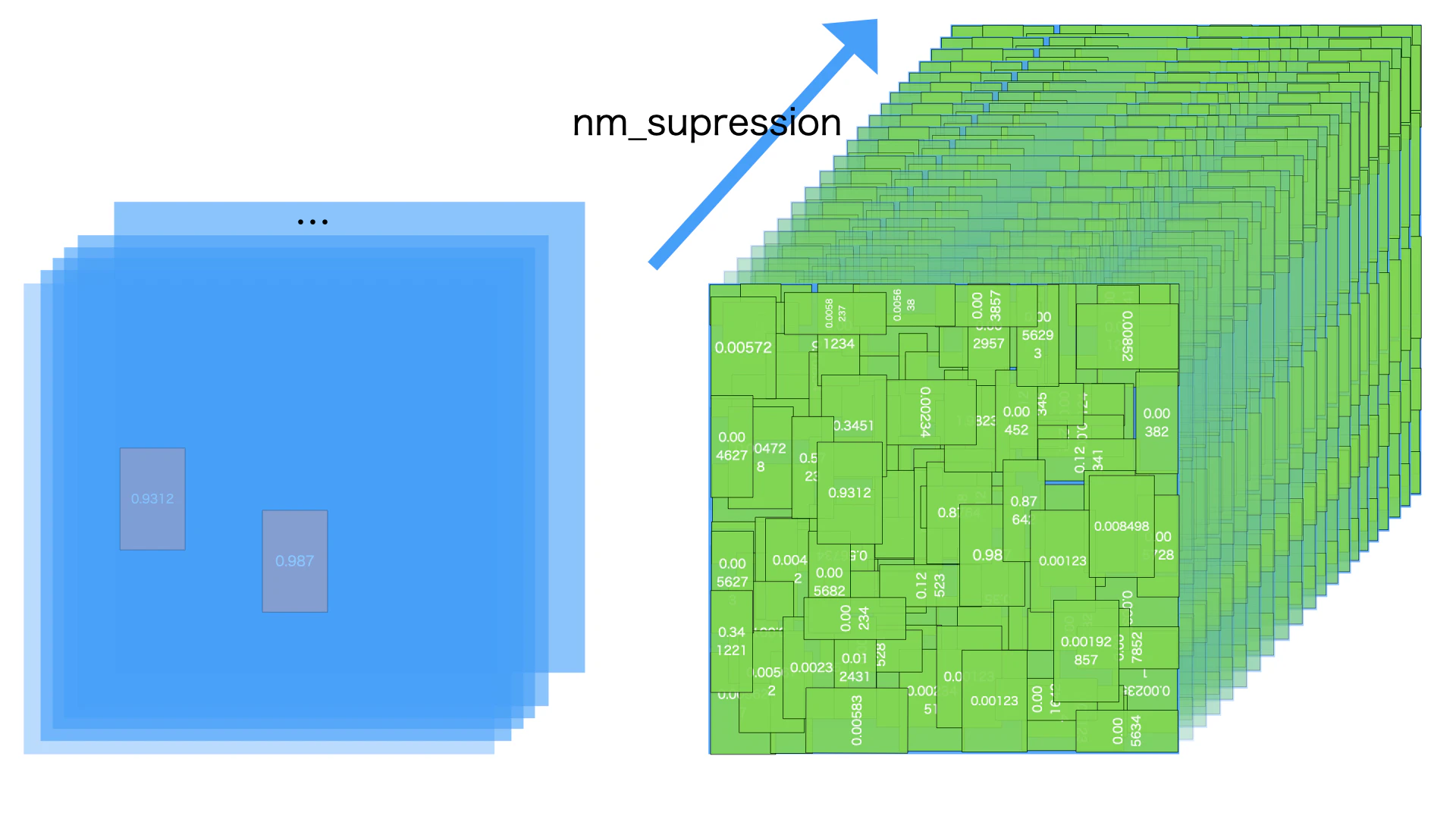
図のように、nm_suppresionはカテゴリーごとに行っています。ステップ1からステップ8の処理がそれぞれのカテゴリーにて、21回行いました。
ソースコード###
このコードは「PyTorchによる発展ディープラーニング」という本からさんこうにしました。
detect###
class Detect(Function):
def __init__(self, conf_thresh=0.01, top_k=200, nms_thresh=0.45):
self.softmax = nn.Softmax(dim=-1) # confをソフトマックス関数で正規化するために用意
self.conf_thresh = conf_thresh # confがconf_thresh=0.01より高いDBoxのみを扱う
self.top_k = top_k # nm_supressionでconfの高いtop_k個を計算に使用する, top_k = 200
self.nms_thresh = nms_thresh # nm_supressionでIOUがnms_thresh=0.45より大きいと、同一物体へのBBoxとみなす
def forward(self, loc_data, conf_data, dbox_list):
"""
順伝搬の計算を実行する。
Parameters
----------
loc_data: [batch_num,8732,4]
オフセット情報。
conf_data: [batch_num, 8732,num_classes]
検出の確信度。
dbox_list: [8732,4]
DBoxの情報
Returns
-------
output : torch.Size([batch_num, 21, 200, 5])
(batch_num、クラス、confのtop200、BBoxの情報)
"""
# 各サイズを取得
num_batch = loc_data.size(0) # ミニバッチのサイズ
num_dbox = loc_data.size(1) # DBoxの数 = 8732
num_classes = conf_data.size(2) # クラス数 = 21
# confはソフトマックスを適用して正規化する
conf_data = self.softmax(conf_data)
tmp = conf_data[0]
# 出力の型を作成する。テンソルサイズは[minibatch数, 21, 200, 5]
output = torch.zeros(num_batch, num_classes, self.top_k, 5)
# cof_dataを[batch_num,8732,num_classes]から[batch_num, num_classes,8732]に順番変更
conf_preds = conf_data.transpose(2, 1)
# ミニバッチごとのループ
for i in range(num_batch):
# 1. locとDBoxから修正したBBox [xmin, ymin, xmax, ymax] を求める
decoded_boxes = decode(loc_data[i], dbox_list)
# confのコピーを作成
conf_scores = conf_preds[i].clone()
# 画像クラスごとのループ(背景クラスのindexである0は計算せず、index=1から)
for cl in range(1, num_classes):
# 2.confの閾値を超えたBBoxを取り出す
# confの閾値を超えているかのマスクを作成し、
# 閾値を超えたconfのインデックスをc_maskとして取得
c_mask = conf_scores[cl].gt(self.conf_thresh)
# gtはGreater thanのこと。gtにより閾値を超えたものが1に、以下が0になる
# conf_scores:torch.Size([21, 8732])
# c_mask:torch.Size([8732])
# scoresはtorch.Size([閾値を超えたBBox数])
scores = conf_scores[cl][c_mask]
# 閾値を超えたconfがない場合、つまりscores=[]のときは、何もしない
if scores.nelement() == 0: # nelementで要素数の合計を求める
continue
# c_maskを、decoded_boxesに適用できるようにサイズを変更します
l_mask = c_mask.unsqueeze(1).expand_as(decoded_boxes)
# l_mask:torch.Size([8732, 4])
# l_maskをdecoded_boxesに適応します
boxes = decoded_boxes[l_mask].view(-1, 4)
# decoded_boxes[l_mask]で1次元になってしまうので、
# viewで(閾値を超えたBBox数, 4)サイズに変形しなおす
# 3. Non-Maximum Suppressionを実施し、被っているBBoxを取り除く
ids, count = nm_suppression(
boxes, scores, self.nms_thresh, self.top_k)
# ids:confの降順にNon-Maximum Suppressionを通過したindexが格納
# count:Non-Maximum Suppressionを通過したBBoxの数
# outputにNon-Maximum Suppressionを抜けた結果を格納
output[i, cl, :count] = torch.cat((scores[ids[:count]].unsqueeze(1),
boxes[ids[:count]]), 1)
return output # torch.Size([1, 21, 200, 5])
nm_supression####
def nm_suppression(boxes, scores, overlap=0.45, top_k=200):
"""
Non-Maximum Suppressionを行う関数。
boxesのうち被り過ぎ(overlap以上)のBBoxを削除する。
Parameters
----------
boxes : [確信度閾値(0.01)を超えたBBox数,4]
BBox情報。
scores :[確信度閾値(0.01)を超えたBBox数]
confの情報
Returns
-------
keep : リスト
confの降順にnmsを通過したindexが格納
count:int
nmsを通過したBBoxの数
"""
# returnのひな形を作成
count = 0
keep = scores.new(scores.size(0)).zero_().long()
# keep:torch.Size([確信度閾値を超えたBBox数])、要素は全部0
# 各BBoxの面積areaを計算
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
area = torch.mul(x2 - x1, y2 - y1)
# boxesをコピーする。後で、BBoxの被り度合いIOUの計算に使用する際のひな形として用意
tmp_x1 = boxes.new()
tmp_y1 = boxes.new()
tmp_x2 = boxes.new()
tmp_y2 = boxes.new()
tmp_w = boxes.new()
tmp_h = boxes.new()
# socreを昇順に並び変える
v, idx = scores.sort(0)
# 上位top_k個(200個)のBBoxのindexを取り出す(200個存在しない場合もある)
idx = idx[-top_k:]
# idxの要素数が0でない限りループする
while idx.numel() > 0:
i = idx[-1] # 現在のconf最大のindexをiに
# keepの現在の最後にconf最大のindexを格納する
# このindexのBBoxと被りが大きいBBoxをこれから消去する
keep[count] = i
count += 1
# 最後のBBoxになった場合は、ループを抜ける
if idx.size(0) == 1:
break
# 現在のconf最大のindexをkeepに格納したので、idxをひとつ減らす
idx = idx[:-1]
# -------------------
# これからkeepに格納したBBoxと被りの大きいBBoxを抽出して除去する
# -------------------
# ひとつ減らしたidxまでのBBoxを、outに指定した変数として作成する
torch.index_select(x1, 0, idx, out=tmp_x1)
torch.index_select(y1, 0, idx, out=tmp_y1)
torch.index_select(x2, 0, idx, out=tmp_x2)
torch.index_select(y2, 0, idx, out=tmp_y2)
# すべてのBBoxに対して、現在のBBox=indexがiと被っている値までに設定(clamp)
tmp_x1 = torch.clamp(tmp_x1, min=x1[i])
tmp_y1 = torch.clamp(tmp_y1, min=y1[i])
tmp_x2 = torch.clamp(tmp_x2, max=x2[i])
tmp_y2 = torch.clamp(tmp_y2, max=y2[i])
# wとhのテンソルサイズをindexを1つ減らしたものにする
tmp_w.resize_as_(tmp_x2)
tmp_h.resize_as_(tmp_y2)
# clampした状態でのBBoxの幅と高さを求める
tmp_w = tmp_x2 - tmp_x1
tmp_h = tmp_y2 - tmp_y1
# 幅や高さが負になっているものは0にする
tmp_w = torch.clamp(tmp_w, min=0.0)
tmp_h = torch.clamp(tmp_h, min=0.0)
# clampされた状態での面積を求める
inter = tmp_w*tmp_h
# IoU = intersect部分 / (area(a) + area(b) - intersect部分)の計算
rem_areas = torch.index_select(area, 0, idx) # 各BBoxの元の面積
union = (rem_areas - inter) + area[i] # 2つのエリアのANDの面積
IoU = inter/union
# IoUがoverlapより小さいidxのみを残す
idx = idx[IoU.le(overlap)] # leはLess than or Equal toの処理をする演算です
# IoUがoverlapより大きいidxは、最初に選んでkeepに格納したidxと同じ物体に対してBBoxを囲んでいるため消去
# whileのループが抜けたら終了
return keep, count
まとめ###
SSDモデルから出力したOffset情報と信頼度情報を使って、推論する流れを紹介しました。
ここでSSDモデルの紹介が終わります。また記事を修正するところがありますが、ご指摘などをいただきたいとおもいます。