背景
最近機械学習分野の物体検出を初めまして、知っているSSDモデルについて紹介したいとおもいます。ここはSSD300についてしょうかいします。
今回は第一編です、DefaultBoxesについて紹介したいとおもいます
SSDとは
一枚の画像に含まれている複数の物体に対して、物体名と物体の領域を文字と枠から表示するものです
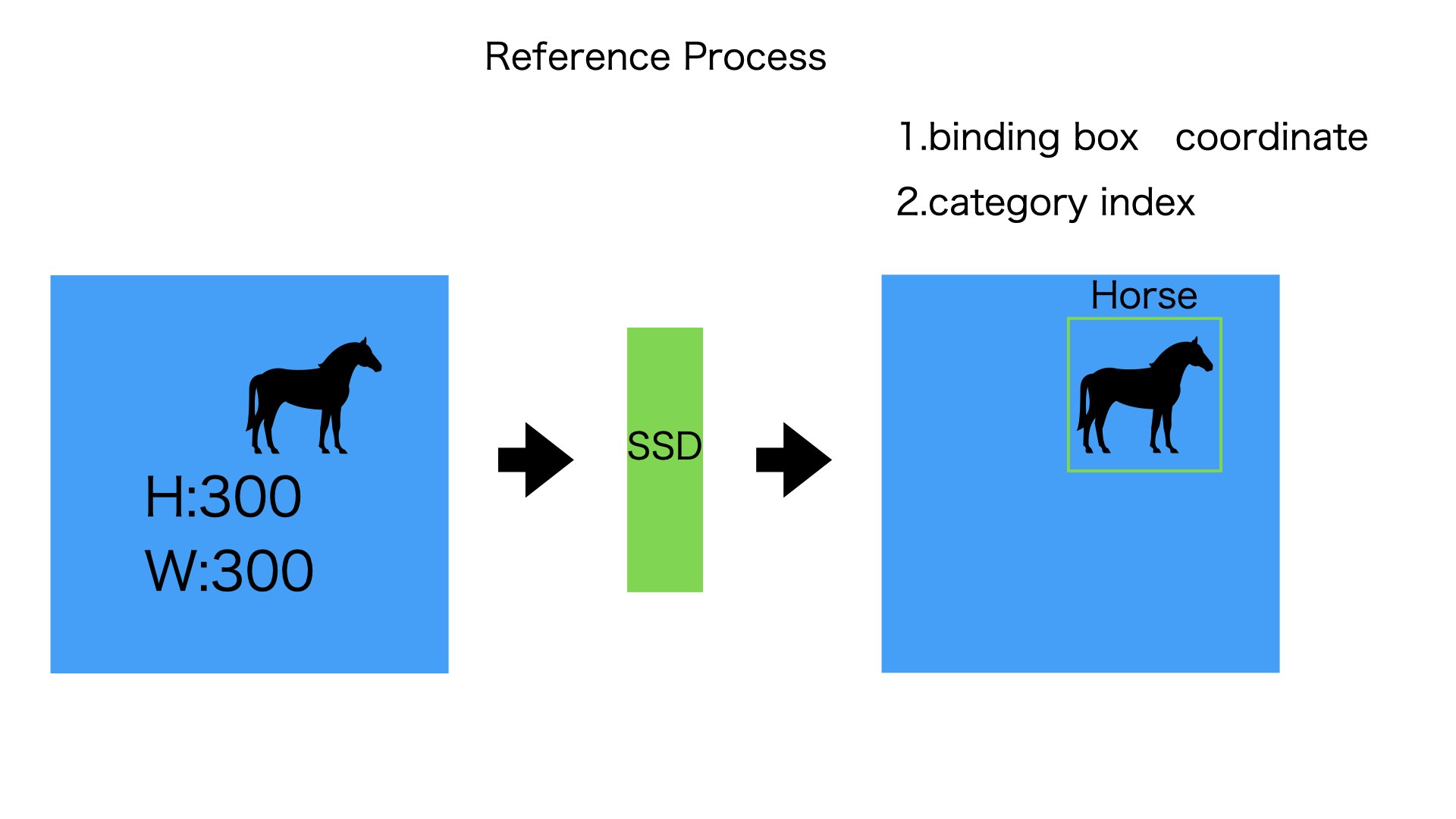
入力:
3003003の画像(3は色のチャンネル)
出力:
- 物体を枠で囲むボックス(バウンディングボックスの座標と横幅、縦幅)
- 物体はなんの種類なのか
流れ
では、入力から出力まで、どのようなものが行われてるか、一言でいいます。
訓練:
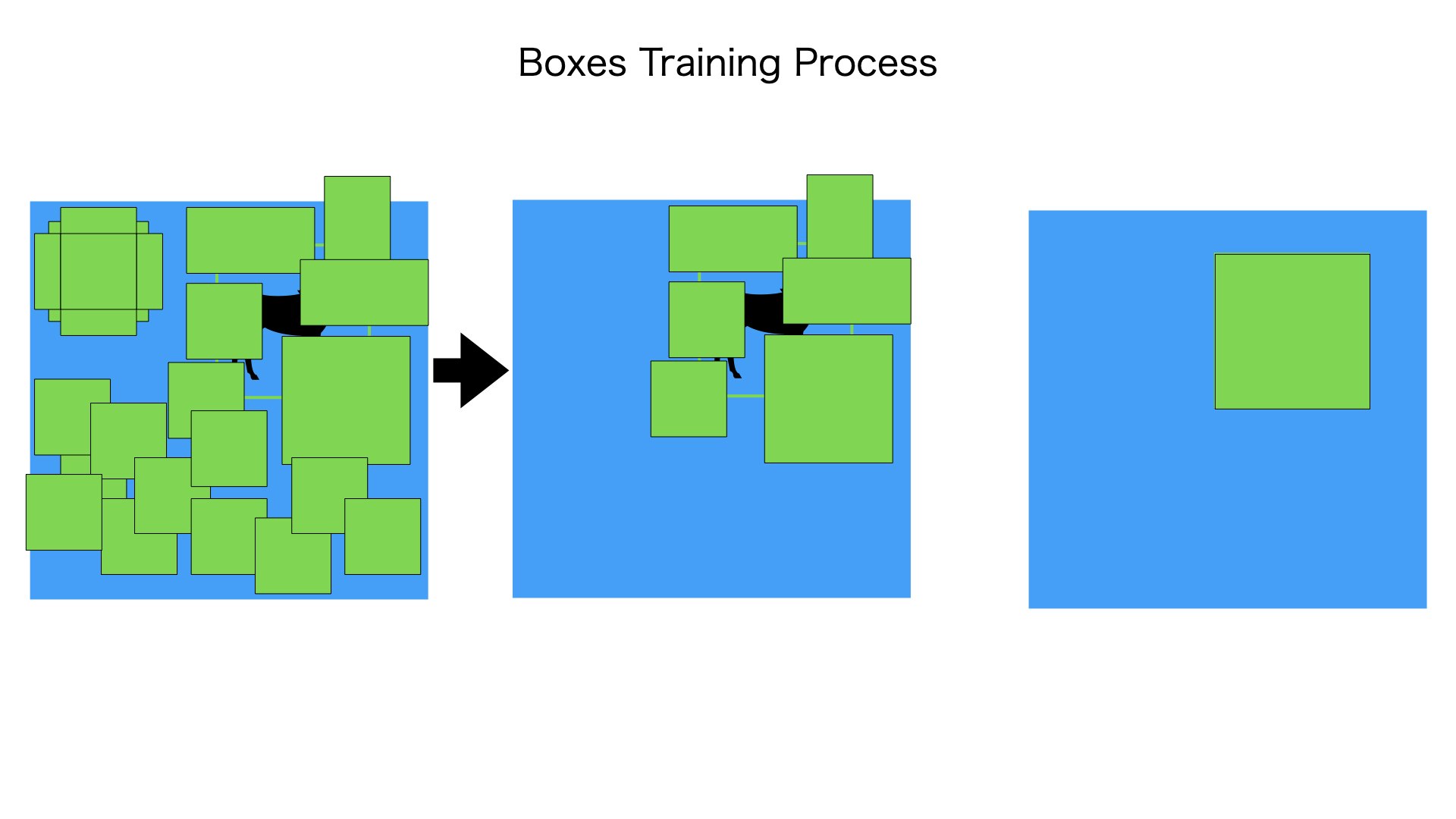
前提:検出したい物体の種類とバウンディングボックスの情報をすでに知っています。
1. 入力の画像(300*300*3)にたくさんのボックス(デフォルトボックス)をつけます
2. 1から用意したたくさんのデフォルトボックスからバウンディングボックスと結構重ねってあるボックスを抽出して残らせます。
3. 残らせたデフォルトボックスからバウンディングボックスへ変形させるためのoffset1情報を計算します
4. SSDモデルからoffset2を出力します
5. offset1情報とoffset2と損失関数で比較して、損失値を計算します。
6. 損失値がある程度小さくなるまで、1-4の流れをきうり返します
詳しくは、別の章で紹介しにいきます。ここはたくさんのデフォルトボックスをつくることが必要があることを見せたいです
推論:
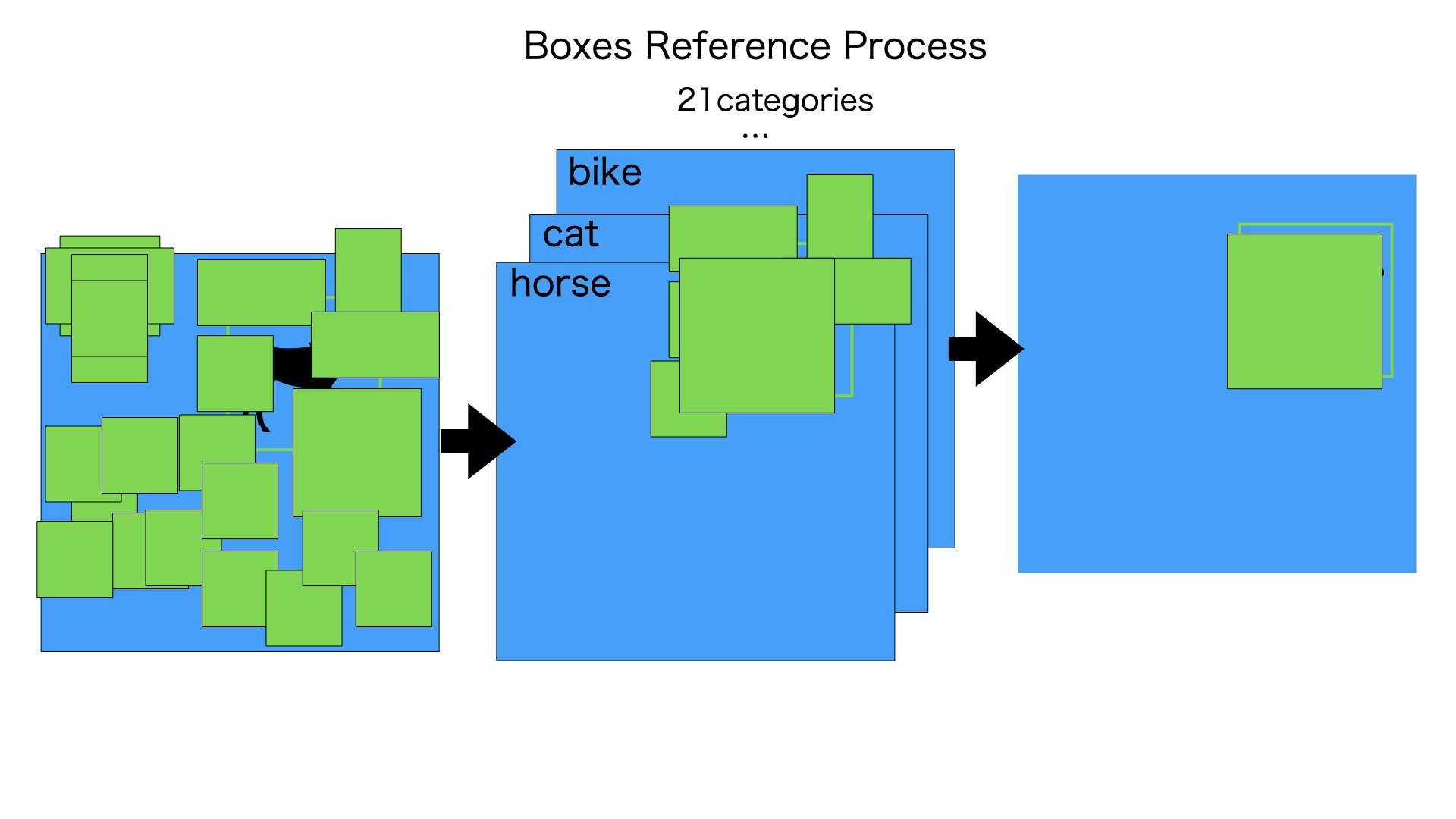
前提:SSDもでるはすでに訓練が終わってます
1. 入力の画像(300*300*3)にたくさんのボックス(デフォルトボックス)をつけます
2. 1から用意したたくさんのデフォルトボックスからバウンディングボックスと結構重ねってあるボックスを抽出して残らせます。
3. SSDモデルから各デフォルトボックスの21カテゴリに対する信頼度category2(8732,21)とOffset2(8732)情報出力します
4. 格カテゴリで、category2[i]の信頼度がある数値以上なデフォルトボックスをのこらせます
5. 各カテゴリで、残らせられたデフォルトボックスを重複チェックします
6. Offset2を使って、デフォルトボックスからバウンディングボックスに変形させます
詳しくは、別の章で紹介しにいきます。ここはたくさんのデフォルトボックスをつくることが必要があることを見せたいです
つまり、SSDは最初にデフォルトボックスを用意します。SSDモデルが出力するのは、Offset情報と信頼度情報のみです。
デフォルトボックスの用意はSSDモデルの出力ではないです
訓練と推論のときに使っているデフォルトボックスが毎回同じものです
デフォルトボックスの生成
38384
まずは300300の入力画像を3838分に均等にわけます、そして各分に4個のデフォルトボックスをつけます
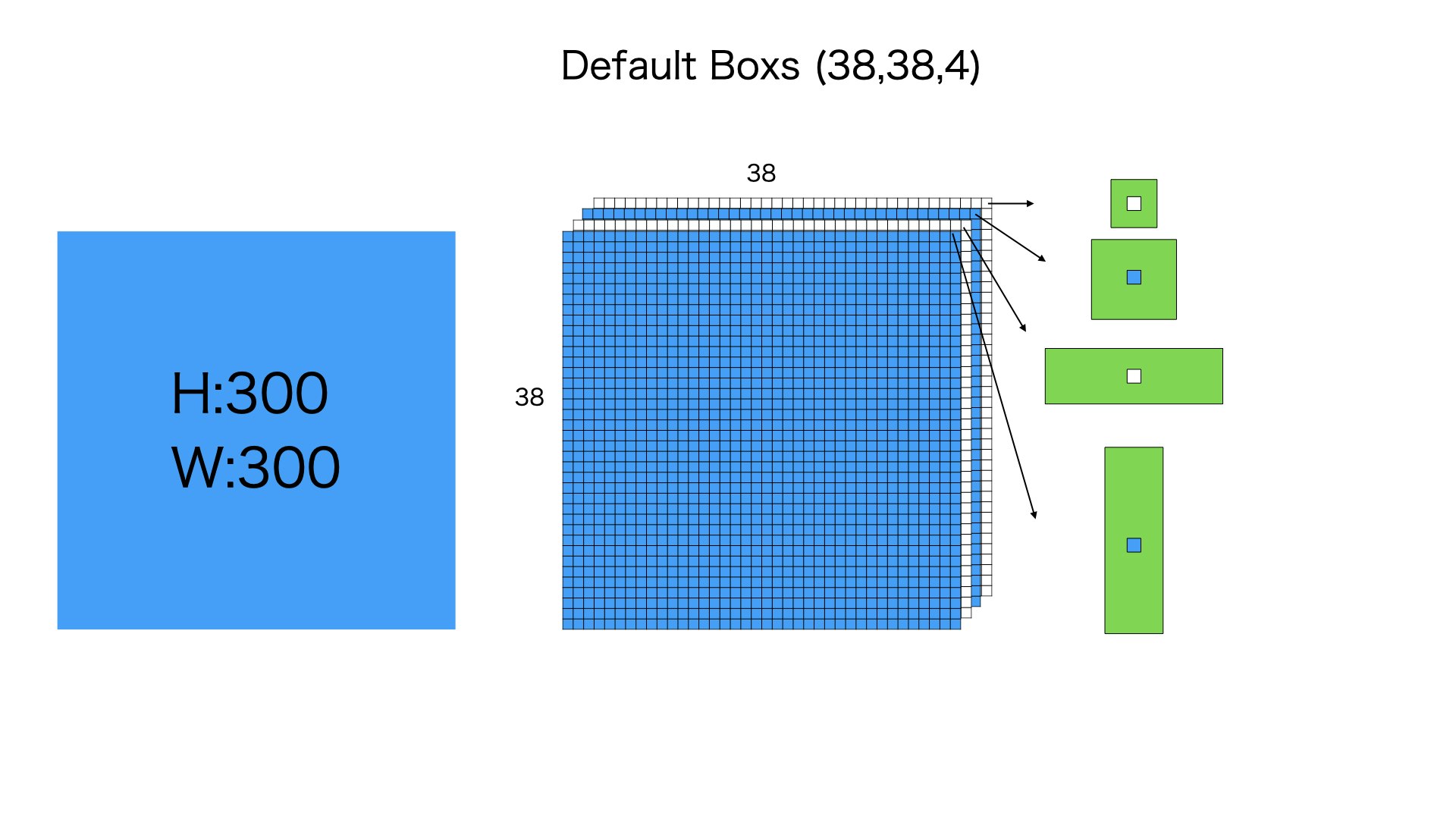
4個のデフォルトボックスのサイズは異なります。それぞれの比例は11 min,11 big, 12,21のように理解していただけれは、大丈夫です。
このステップは38384 = 5776個のデフォルトボックスを用意します
19196
つぎに300300の入力画像を1919分に均等にわけます、そして各分に6個のデフォルトボックスをつけます
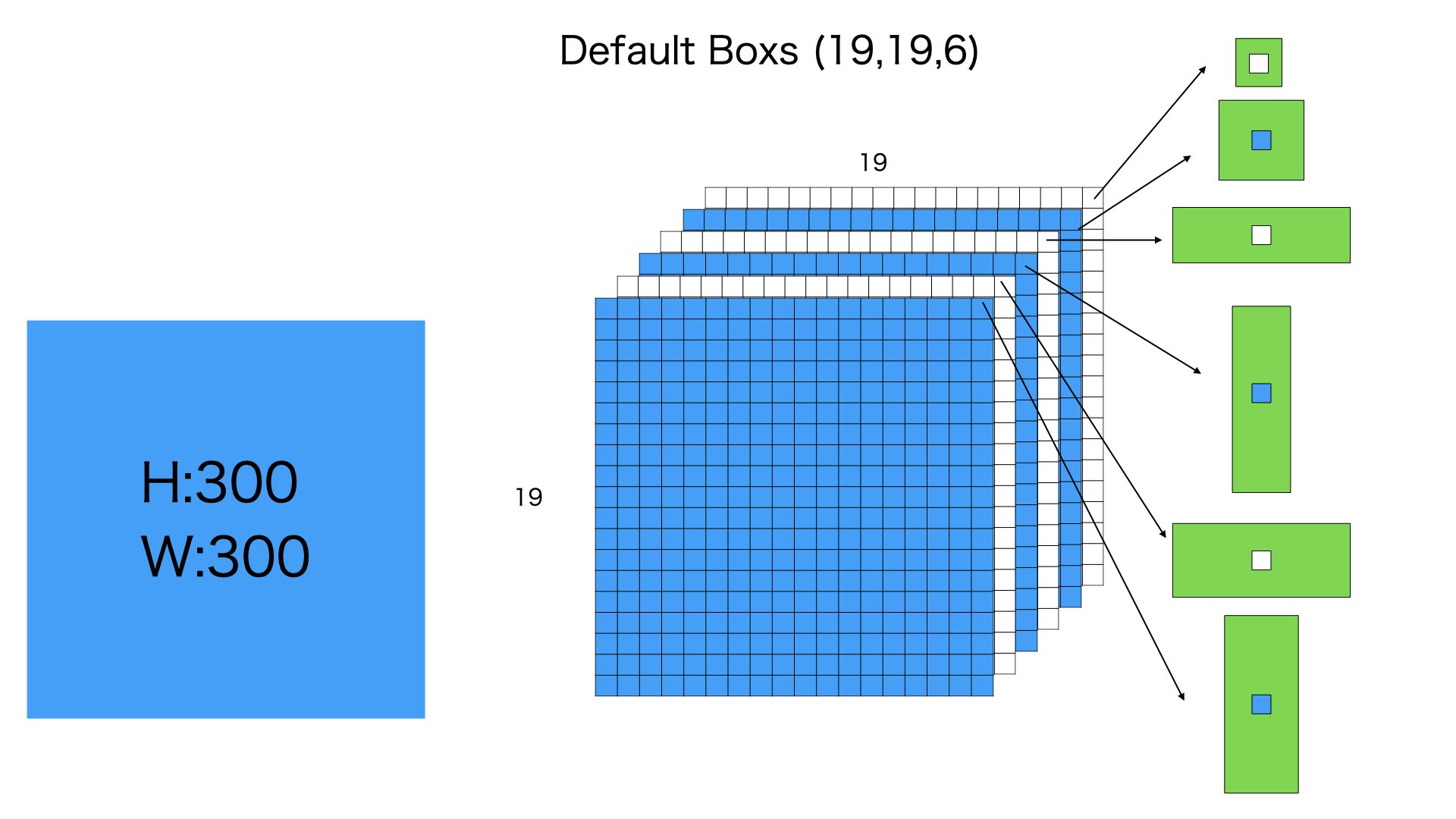
6個のデフォルトボックスのサイズは異なります。それぞれの比例は11 min,11 big, 12,21,13,31のように理解していただけれは、大丈夫です。
このステップは19196 = 2166個のデフォルトボックスを用意します
感覚からみれば、19196のデフォルトボックスは38384デフォルトボックスより大きい、それは38384のデフォルトボックスは小さいものを検出するため、19196のデフォルトボックスはより大きな物体を検出できるわけです
10106
つぎに300300の入力画像を1010分に均等にわけます、そして各分に6個のデフォルトボックスをつけます
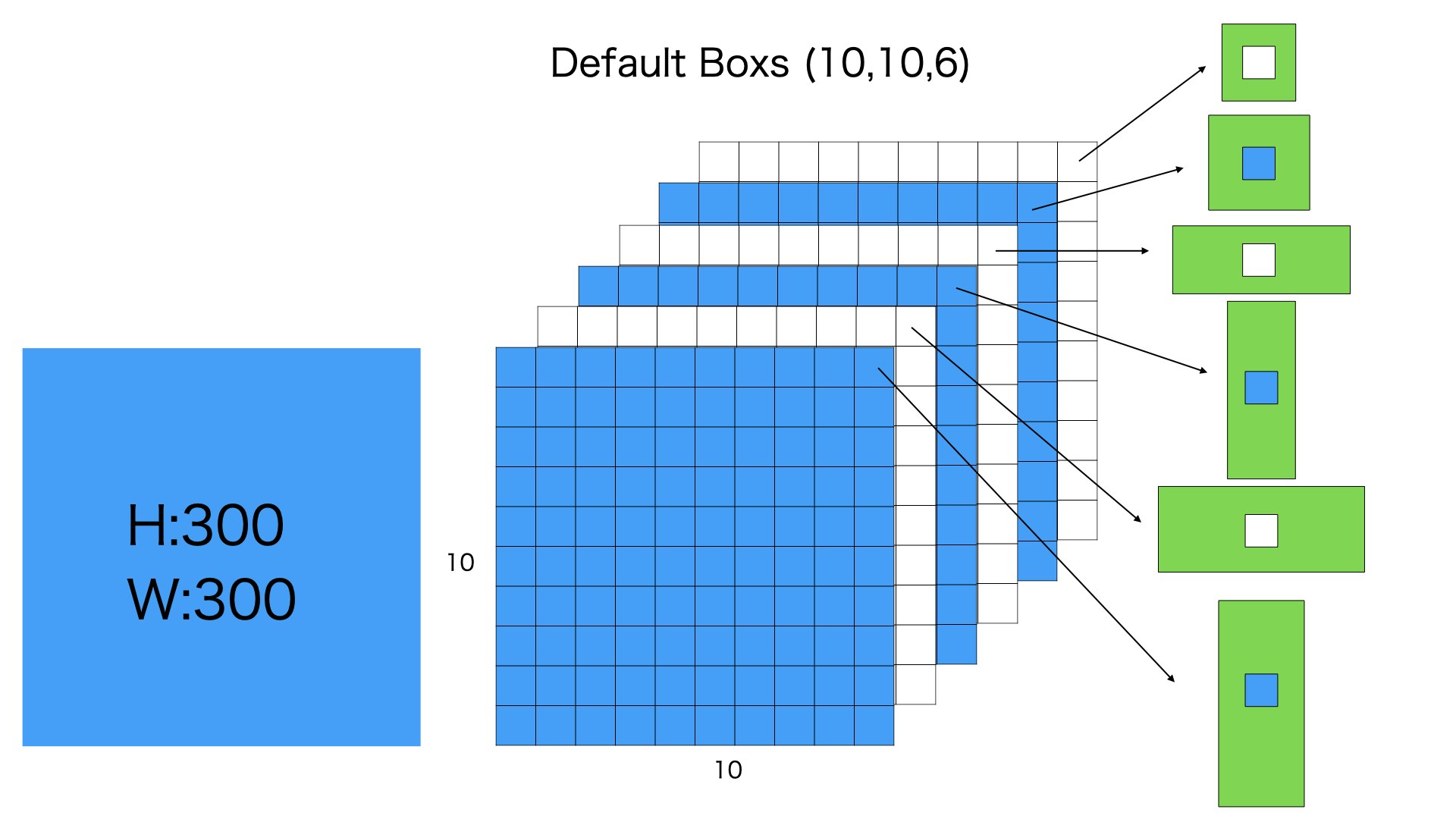
6個のデフォルトボックスのサイズは異なります。それぞれの比例は11 min,11 big, 12,21,13,31のように理解していただけれは、大丈夫です。
このステップは10106 = 600個のデフォルトボックスを用意します
感覚からみれば、10106のデフォルトボックスは38384と19196のデフォルトボックスより大きい、それは38384と19196のデフォルトボックスは小さいものを検出するため、10106のデフォルトボックスはより大きな物体を検出できるわけです
556
つぎに300300の入力画像を55分に均等にわけます、そして各分に6個のデフォルトボックスをつけます
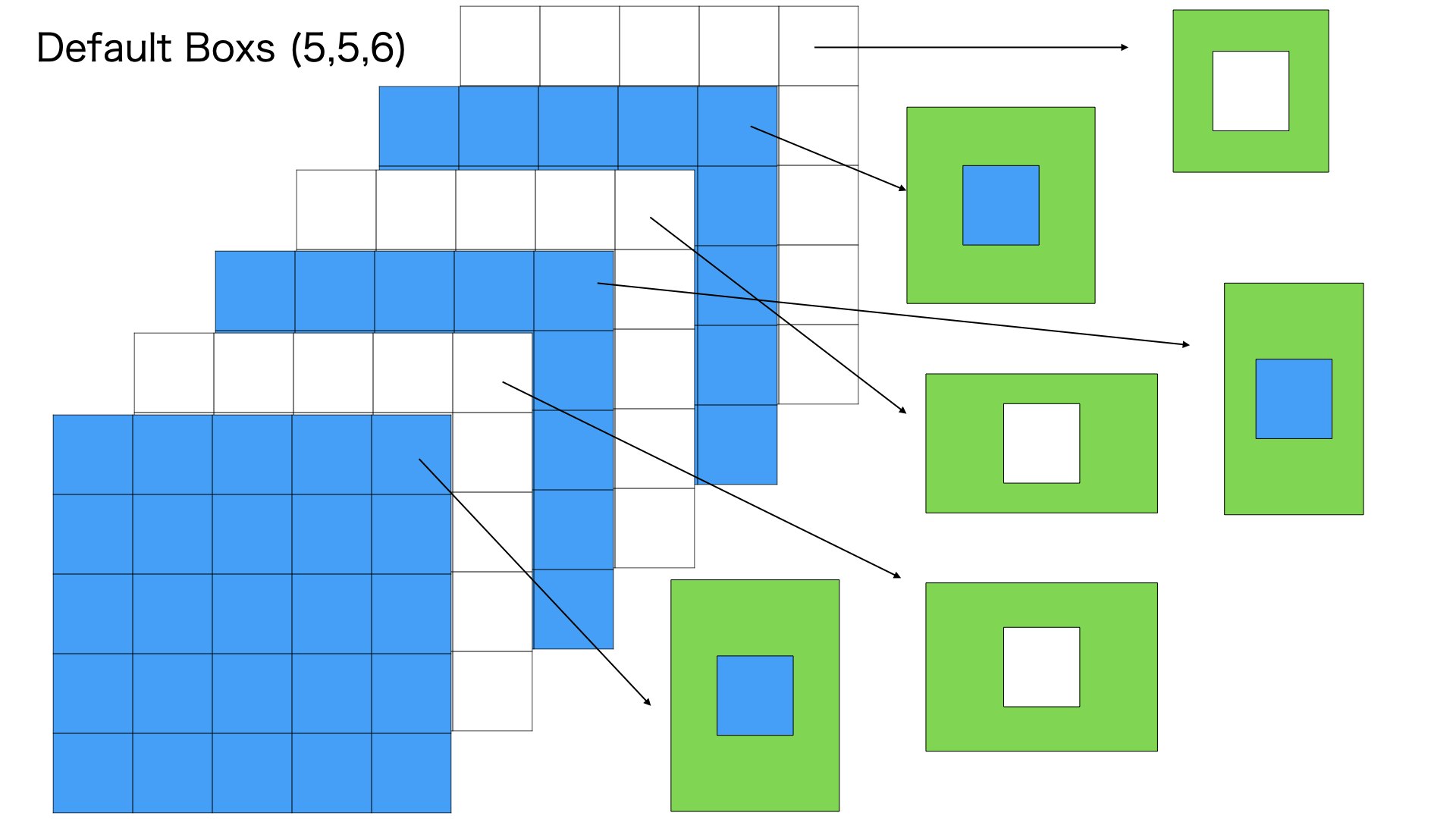
6個のデフォルトボックスのサイズは異なります。それぞれの比例は11 min,11 big, 12,21,13,31のように理解していただけれは、大丈夫です。
このステップは556 = 150個のデフォルトボックスを用意します
さらに、感覚からみれば、556のデフォルトボックスは10106のデフォルトボックスより大きい、10106のデフォルトボックスより、もっと大きいな物体を検出可能なことをわかりました
334
つぎに300300の入力画像を33分に均等にわけます、そして各分に4個のデフォルトボックスをつけます
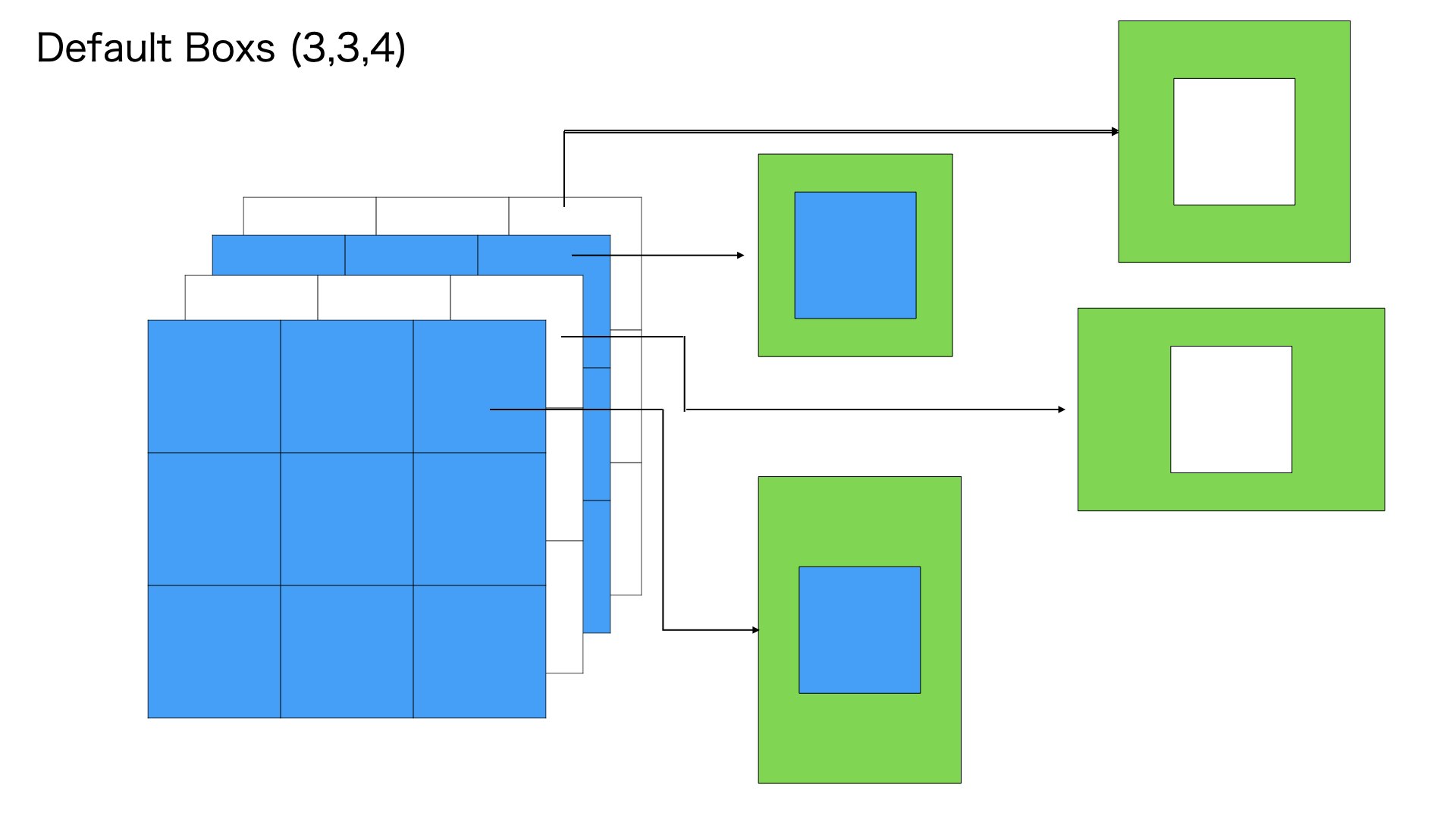
4個のデフォルトボックスのサイズは異なります。それぞれの比例は11 min,11 big, 12,21のように理解していただけれは、大丈夫です。
このステップは334 = 36個のデフォルトボックスを用意します
ここからみれば、デフォルトボックスは相当大きい、相当大きいな物体を検出可能なことをわかりました。
116
つぎに300300の入力画像を11分に均等にわけます、そして唯一な均等分に6個のデフォルトボックスをつけます
6個のデフォルトボックスのサイズは異なります。それぞれの比例は11 min,11 big, 12,21,13,31のように理解していただけれは、大丈夫です。
このステップは116 = 6個のデフォルトボックスを用意します
ここの均等分はもとの画像のサイズと同じです、生成される6個のデフォルトボックスも大きいです。一番おおきいな物体を検出可能なことをわかりました。
以上のように300300の元画像を3838,1919,1010,55,33,1*1に均等に分けて、各分けられた均等分から4個また6個のデフォルトボックスを生成しました
全体的にデフォルトボックスの数は38384 + 19196 + 10106 + 556 + 334 + 116 = 8734個
各デフォルトボックス4の座標情報があります(cx,cy,width,height)
ソースコード
このコードは「PyTorchによる発展ディープラーニング」という本からさんこうにしました。
# デフォルトボックスを出力するクラス
class DBox(object):
def __init__(self, cfg):
super(DBox, self).__init__()
# 初期設定
self.image_size = cfg['input_size'] # 画像サイズの300
# [38, 19, …] 各sourceの特徴量マップのサイズ
self.feature_maps = cfg['feature_maps']
self.num_priors = len(cfg["feature_maps"]) # sourceの個数=6
self.steps = cfg['steps'] # [8, 16, …] DBoxのピクセルサイズ
self.min_sizes = cfg['min_sizes'] # [30, 60, …] 小さい正方形のDBoxのピクセルサイズ
self.max_sizes = cfg['max_sizes'] # [60, 111, …] 大きい正方形のDBoxのピクセルサイズ
self.aspect_ratios = cfg['aspect_ratios'] # 長方形のDBoxのアスペクト比
def make_dbox_list(self):
'''DBoxを作成する'''
mean = []
# 'feature_maps': [38, 19, 10, 5, 3, 1]
for k, f in enumerate(self.feature_maps):
for i, j in product(range(f), repeat=2): # fまでの数で2ペアの組み合わせを作る f_P_2 個
# 特徴量の画像サイズ
# 300 / 'steps': [8, 16, 32, 64, 100, 300],
f_k = self.image_size / self.steps[k]
print(f_k)
# DBoxの中心座標 x,y ただし、0~1で規格化している
cx = (j + 0.5) / f_k
cy = (i + 0.5) / f_k
# アスペクト比1の小さいDBox [cx,cy, width, height]
# 'min_sizes': [30, 60, 111, 162, 213, 264]
s_k = self.min_sizes[k]/self.image_size
mean += [cx, cy, s_k, s_k]
# アスペクト比1の大きいDBox [cx,cy, width, height]
# 'max_sizes': [45, 99, 153, 207, 261, 315],
s_k_prime = sqrt(s_k * (self.max_sizes[k]/self.image_size))
mean += [cx, cy, s_k_prime, s_k_prime]
# その他のアスペクト比のdefBox [cx,cy, width, height]
for ar in self.aspect_ratios[k]:
mean += [cx, cy, s_k*sqrt(ar), s_k/sqrt(ar)]
mean += [cx, cy, s_k/sqrt(ar), s_k*sqrt(ar)]
# DBoxをテンソルに変換 torch.Size([8732, 4])
output = torch.Tensor(mean).view(-1, 4)
# DBoxが画像の外にはみ出るのを防ぐため、大きさを最小0、最大1にする
output.clamp_(max=1, min=0)
return output
# 動作の確認
# SSD300の設定
ssd_cfg = {
'num_classes': 21, # 背景クラスを含めた合計クラス数
'input_size': 300, # 画像の入力サイズ
'bbox_aspect_num': [4, 6, 6, 6, 4, 4], # 出力するDBoxのアスペクト比の種類
'feature_maps': [38, 19, 10, 5, 3, 1], # 各sourceの画像サイズ
'steps': [8, 16, 32, 64, 100, 300], # DBOXの大きさを決める
'min_sizes': [30, 60, 111, 162, 213, 264], # DBOXの大きさを決める
'max_sizes': [60, 111, 162, 213, 264, 315], # DBOXの大きさを決める
'aspect_ratios': [[2], [2, 3], [2, 3], [2, 3], [2], [2]],
}
# DBox作成
dbox = DBox(ssd_cfg)
dbox_list = dbox.make_dbox_list()
# DBoxの出力を確認する
pd.DataFrame(dbox_list.numpy())
出力
0 1 2 3
0 0.013333 0.013333 0.100000 0.100000
1 0.013333 0.013333 0.141421 0.141421
2 0.013333 0.013333 0.141421 0.070711
3 0.013333 0.013333 0.070711 0.141421
4 0.040000 0.013333 0.100000 0.100000
... ... ... ... ...
8727 0.833333 0.833333 0.502046 1.000000
8728 0.500000 0.500000 0.880000 0.880000
8729 0.500000 0.500000 0.961249 0.961249
8730 0.500000 0.500000 1.000000 0.622254
8731 0.500000 0.500000 0.622254 1.000000
8732 rows × 4 columns
デフォルトボックスの範囲は0-1に納めるように処理しました。
まとめ###
物体検出モデルSSD300の訓練と推論ともの材料になる、デフォルトボックスを紹介しました
つぎの文章はデフォルトボックスを変形させるため、SSDモデルの出力offset情報を紹介したいとおもいます。