背景###
前回はRetinaNetモデルに投げるデータの前処理段階を紹介いたしました。
画像のサイズの画像だとしても、以下の条件に準じて変形します。
短い辺の長さを608、もしくは長い辺の長さを1024にします。
短い辺の長さを最長608、長い辺の長さを最長1024のサイズに変形します。
入力された画像が複数サイズの囲碁の碁盤に分割りされます
分割りされた各マスが9個のanchorboxが生成されます
このモデルの目的は以下のことです。
各マスのoffset情報を生成します
各マスの分類情報を生成します
モデルの流れ###
画像サイズが(2,3,620,832)(batch,color,width,height)の入力データを入力例としてをあげます。
レイヤー####
layer0#####
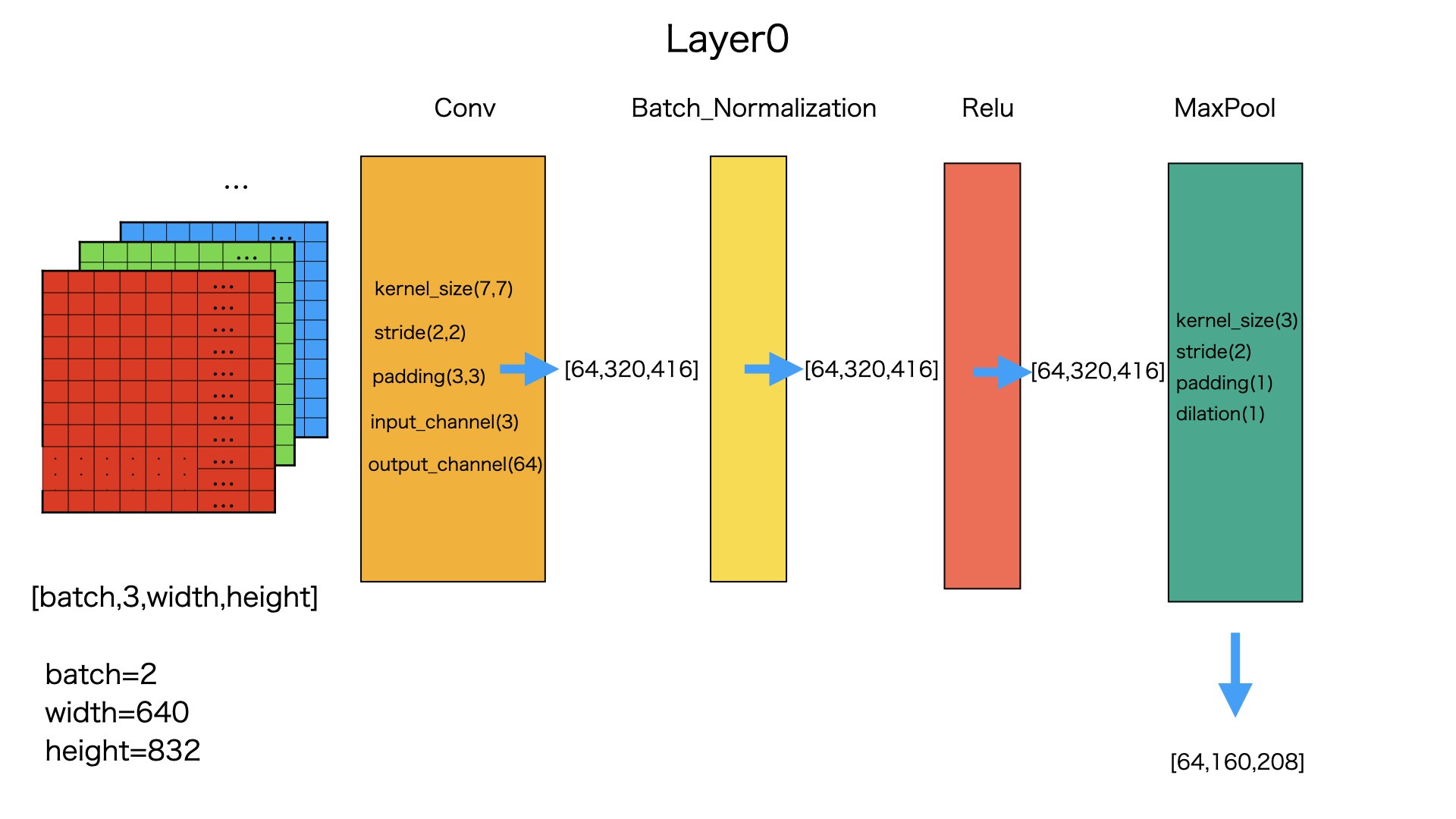
図のように、入力された画像データがまずlayer0を経由します。
画像データが(2,3,620,832)から(2,64,160,208)になります。
layer1#####
次はlayer1を経由します。layer1はresnetの基本ベースになるBottleNetから組み立てられる。
BottleNetは1つの入力に対して、2つの経路に分けて処理します。最後に分けられた経路の結果を一つの出力に合わせます。
BottleNetは二番目の経路の種類ごとに分けられています。
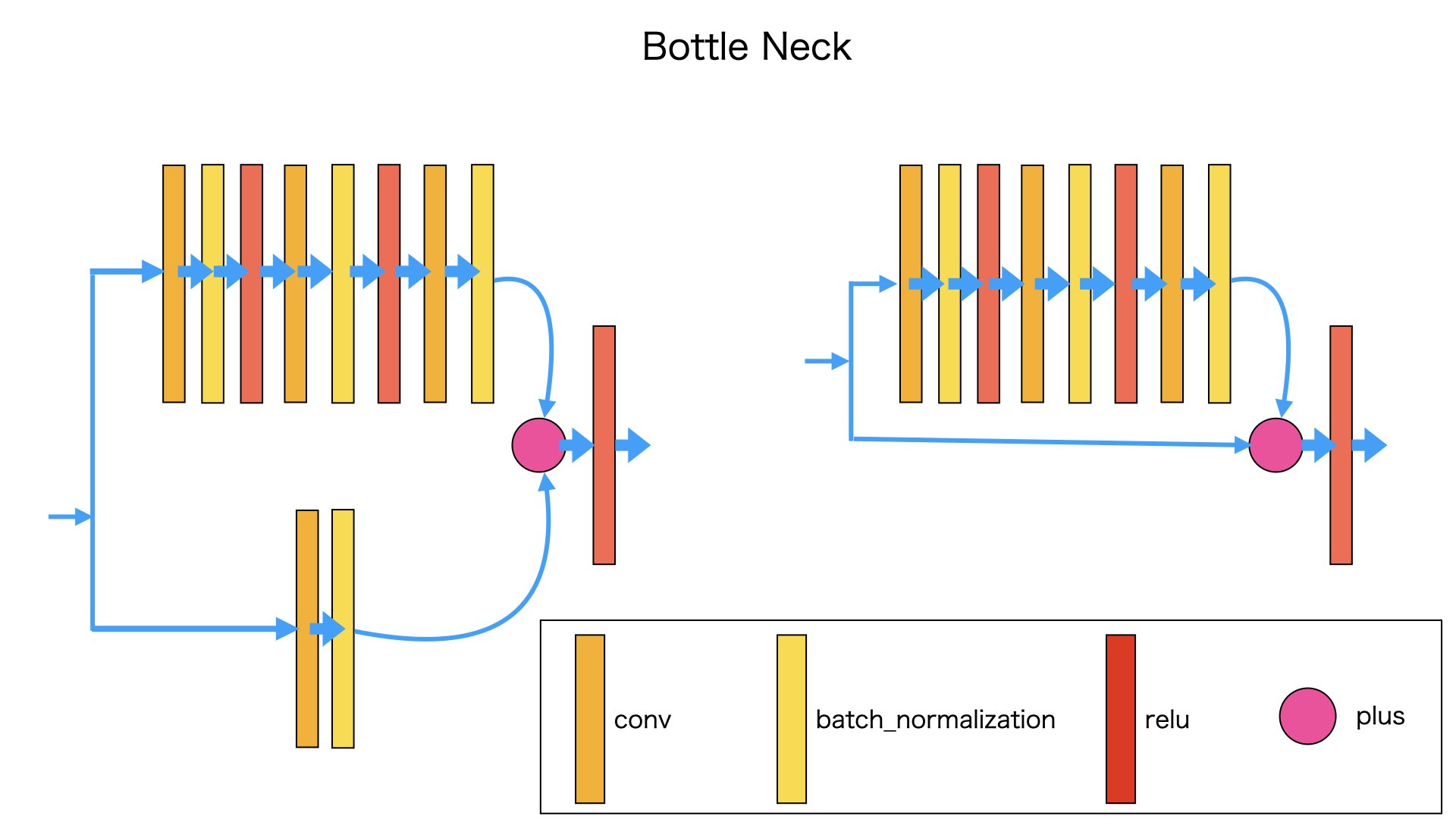
図のように
左側のBottleNetでは、下の経路では入力データがConvとbatch_normalizationのレイヤーを経由します。
右側のBottleNetでは、下の経路では、入力データがなにも経由せず、そのまま運搬されます。
左側のBottleNetはなぜ、下の経路を設定するかというと、入力をそのまま上の経路の結果と足し算したら、次元とサイズが異なるため、足し算できません。入力データが下の経路を経由して、上の経路と同じ次元、同じサイズに変換されます。そうしたら、入力データが上の経路の結果と足し算できます。
右側のBottleNetはなぜ、したの経路をそのまま運搬するかというと、入力データが上の経路の結果と同じ次元、同じサイズになります。そのため、入力データが上の経路の結果と入力をそのまま足し算できます。
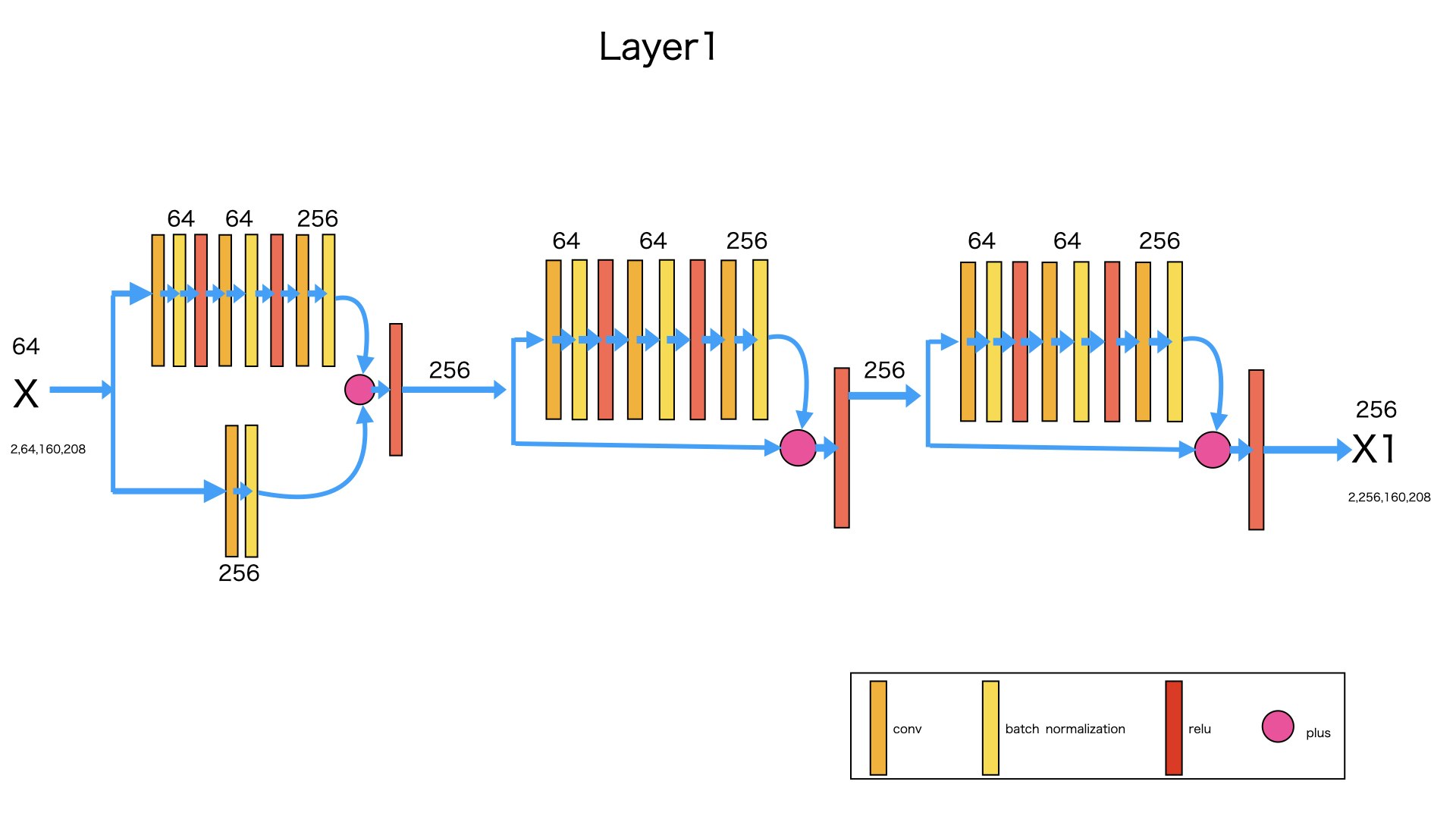
図のように、入力Xは(2,64,160,208)のデータです。3つのBottleNeckレイヤーを経由して、次元とサイズが変わらないです。
入力:X -> (2,64,160,208)
出力:X1 -> (2,64,160,208)
layer2#####
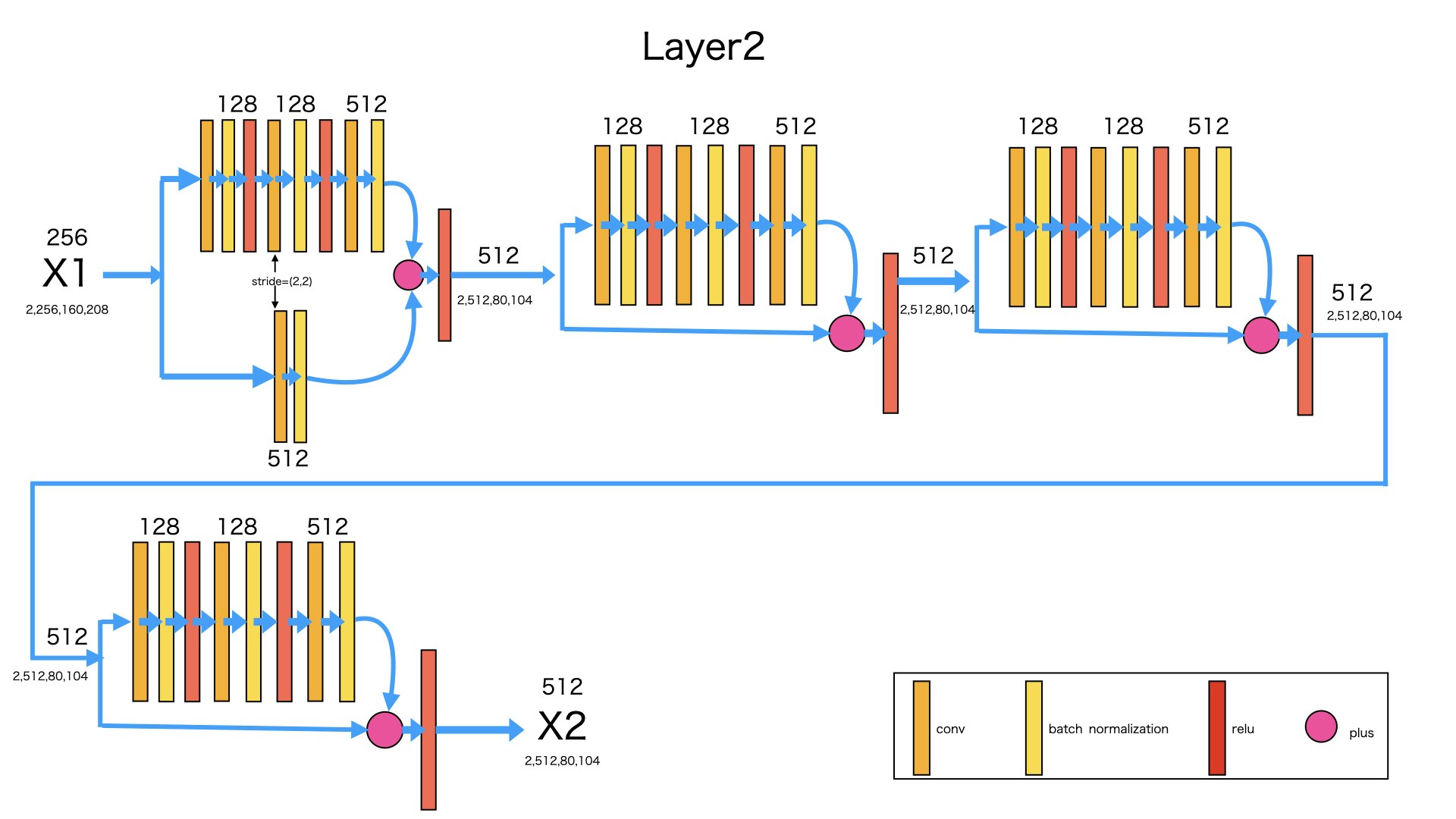
図のように、入力はlayer1の出力X1です。X1が4つのBottleNeckを経由し、次元が256から512になり、サイズが(160,208)から(80,104)になります。
なぜ、サイズが半分になったかというと、1番目のBottleNeckの2番目Convのstrideは(2,2)からです。
入力:X1 -> (2,256,160,208)
出力:X2 -> (2,512,80,104)
layer3#####
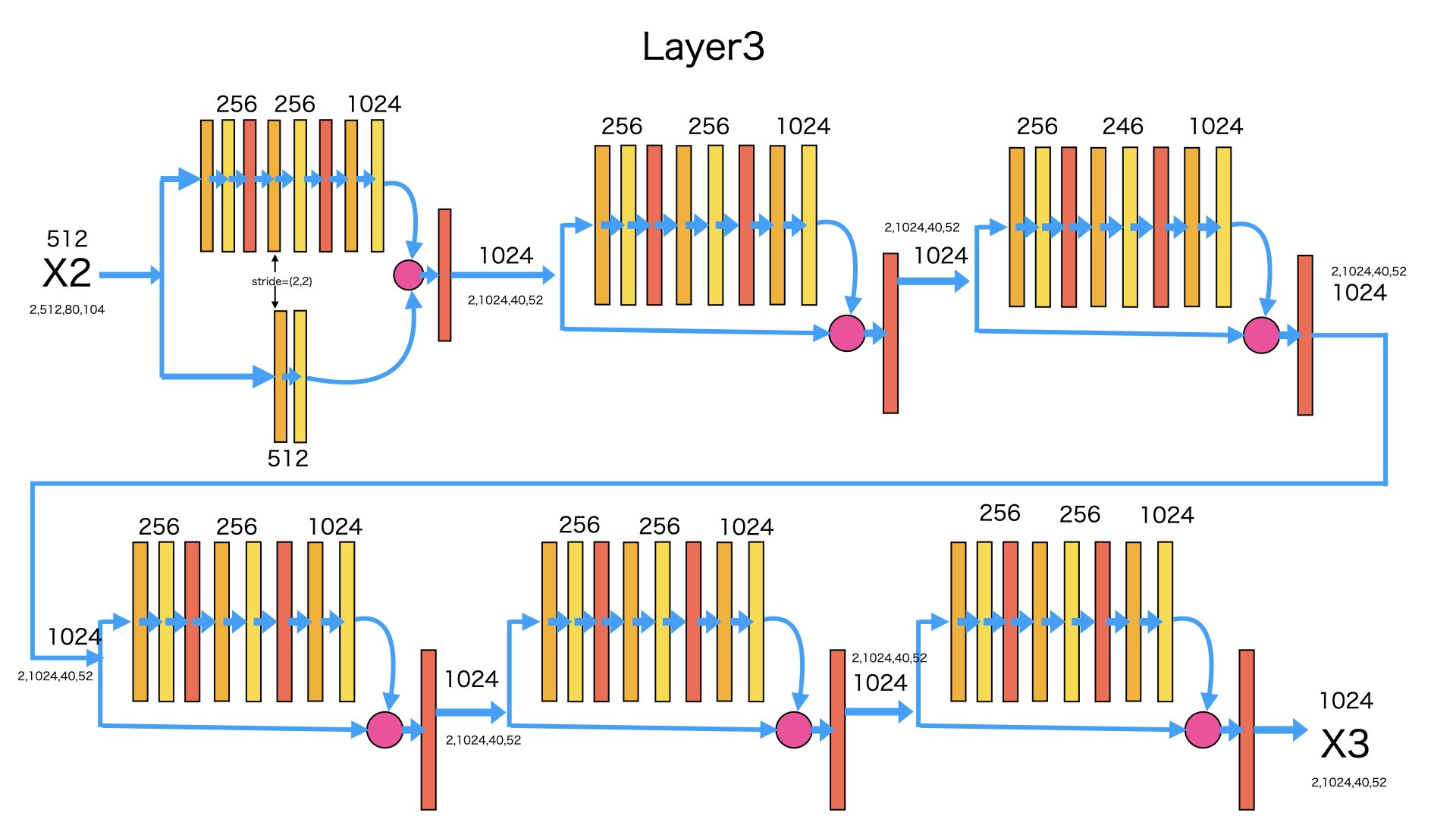
図のように、入力はlayer2の出力X2です。6つのBottleNeckを経由し、次元が512から1024になり、サイズが(80,104)から(40,52)になります。
なぜ、サイズが半分になったかというと、layer2の構造と同じように、1番目のBottleNeckの2番目Convのstrideは(2,2)からです。
入力:X2 -> (2,512,80,104)
出力:X3 -> (2,1024,40,52)
layer4#####
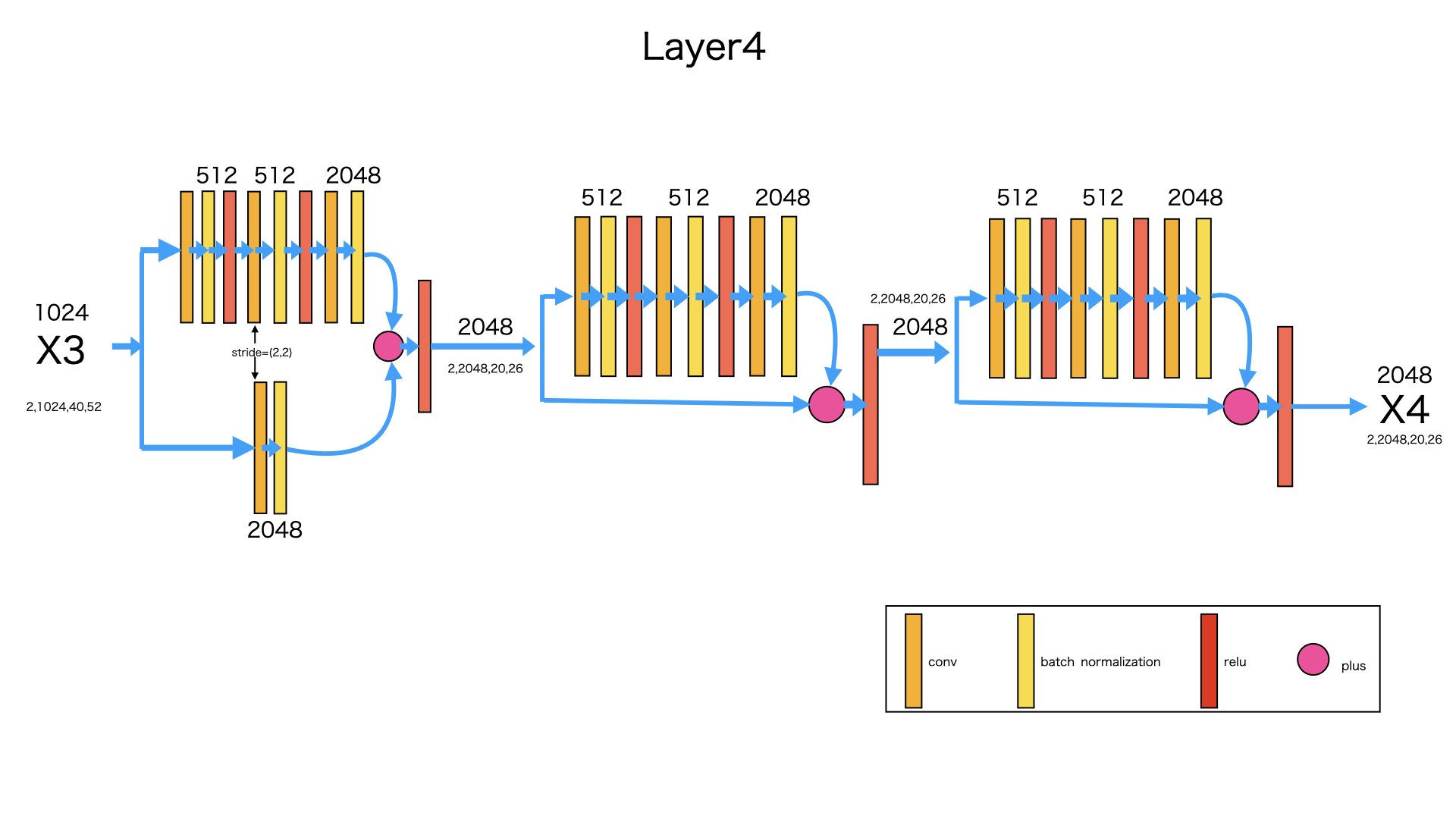
図のように、入力はlayer3の出力X3です。3つのBottleNeckを経由し、次元が1024から2048になり、サイズが(40,52)から(20,26)になります。
なぜ、サイズが半分になったかというと、layer2,lauer3,の構造と同じように、1番目のBottleNeckの2番目Convのstrideは(2,2)からです。
入力:x3 -> (2,1024,40,52)
出力:X4 -> (2,2048,20,26)
feature pyramid layers#####
物体検出のは原理は、画像を囲碁の碁盤のように分割りします。
囲碁の基盤がマスの数ごとに5つ種類に分けられてます。

図のように、画像は5つ種類の基盤に分割りします。
そして、これから処理することは
各マス目にanchorboxを生成して、あたえます。
各マス目に分類情報を生成して、与えます。
feature pyramid layersの目的は
その5つ種類の囲碁の碁盤のサイズを決めます
その5つ種類の囲碁の碁盤に対して、anchorboxと分類情報の生成を準備します。
※5つ種類の囲碁の碁盤の生成については、別件で行われてます、次回紹介します
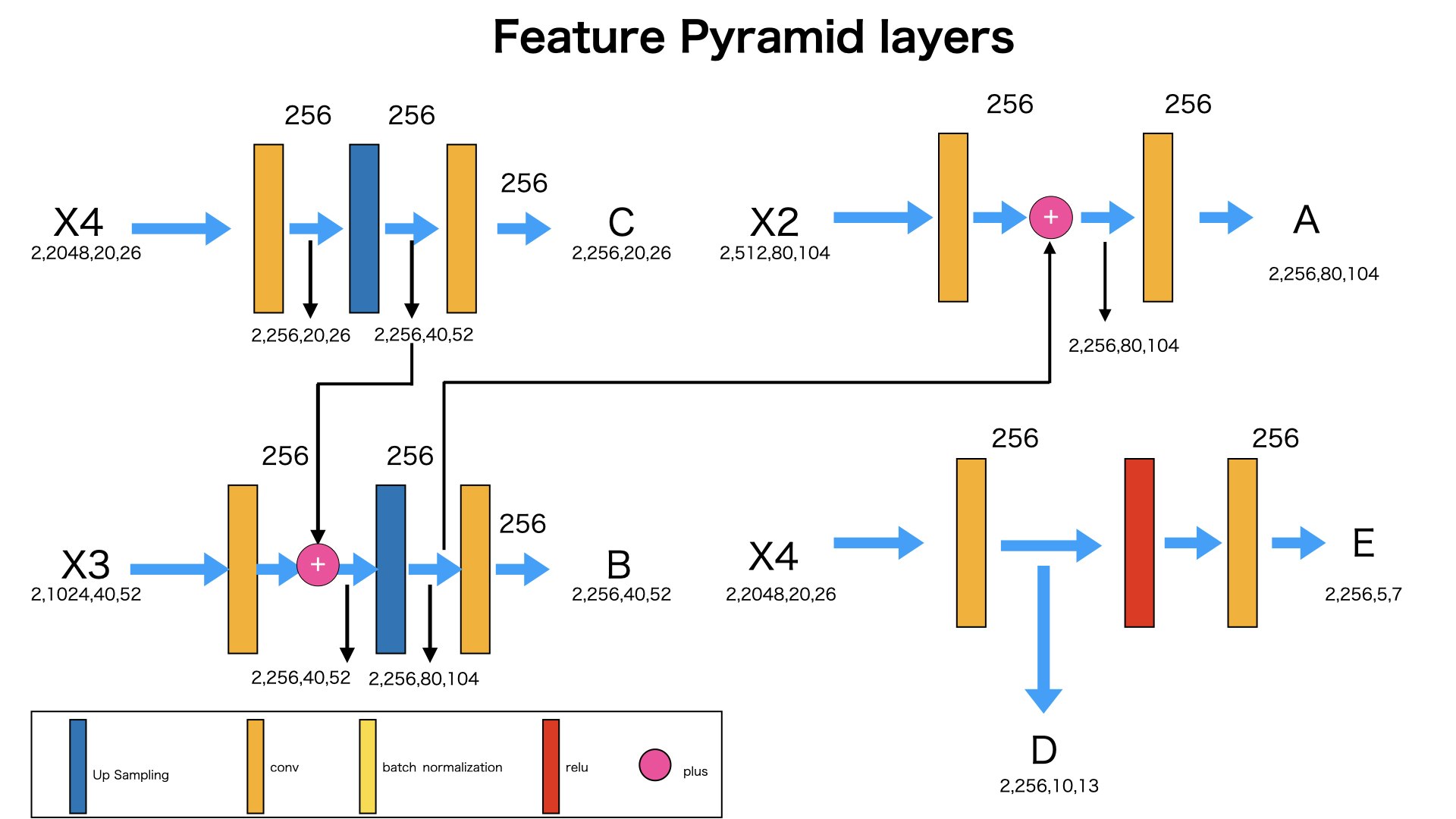
ずのように
layer1からlayer4までの流れでは、X2,X3,X4を得られました。
さらに得られたX2,X3,X4を入力として、feature pyramid layersに入れます。
feature pyramid layersの出力はA,B,C,D,Eになります。
A,B,C,D,Eの最後の2つの次元が、囲碁の碁盤のサイズを表しています。
入力:x2,x3,x4
出力:A,B,C,D,E
A:(2,256,80,104) -> 80X104の碁盤、画像を80X104に分割りします。画像から分割りされたマスに対して、Offset情報と分類情報の生成を準備します
B:(2,256,40,52) -> 40X52の碁盤、画像を40X52に分割りします。画像から分割りされたマスに対して、Offset情報と分類情報の生成を準備します
C:(2,256,20,26) -> 20X26の碁盤、画像を20X26に分割りします。画像から分割りされたマスに対して、Offset情報と分類情報の生成を準備します
D:(2,256,10,13) -> 10X13の碁盤、画像を10X13に分割りします。画像から分割りされたマスに対して、Offset情報と分類情報の生成を準備します
E:(2,256,5,7) -> 5X7の碁盤、画像を5X7に分割りします。画像から分割りされたマスに対して、Offset情報と分類情報の生成を準備します
Regression Layer#####
囲碁各マス目を中心に9個ぞれぞれサイズのanchor boxを生成します。
生成されたanchor boxを教師データであるground truthを目指して、変形します。
変形するためには、offset情報を使います。
一つのマスは9個のanchorboxを生成します。各anchorboxは4つのOffset情報をもって、変形します。
そのため、各マスのoffset情報は9X4=36個です。
Regression Layerの目的は各マスに対して、36個のOffset情報を生成します。
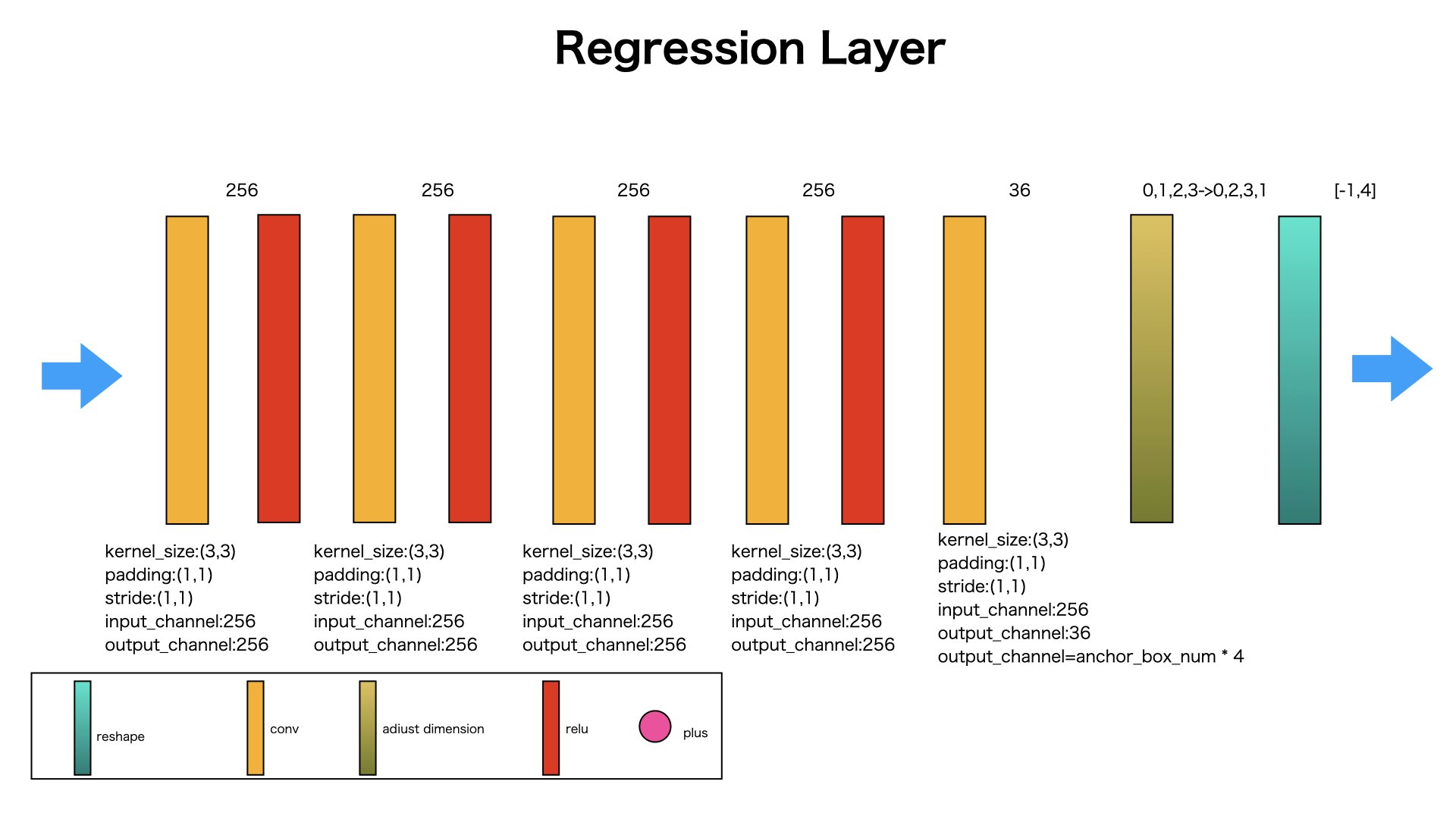
図のように、入力されたデータを最後の次元が4のデータに変換します。
ここの4ということは、一つのマスに対して4つのOffset情報を生成します。
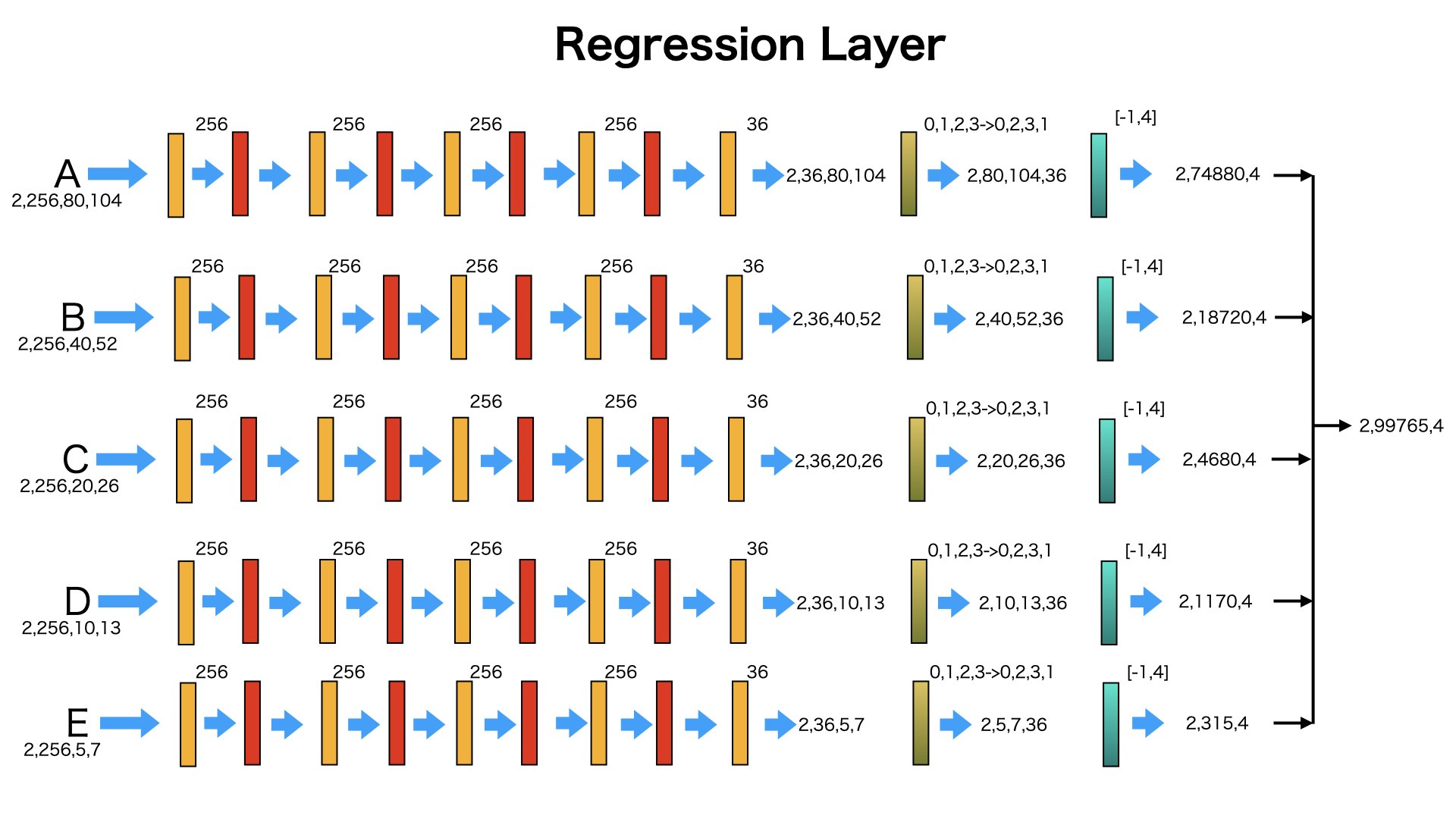
図のように、A,B,C,D,Eを入力データとして、Regression Layerに投げて、データのサイズが変わらず、次元が全部36になりました。
最後に、A,B,C,D,Eの出力を合わせます。これはすべてのanchor boxのoffsetを納めていることです。
Classification Layer#####
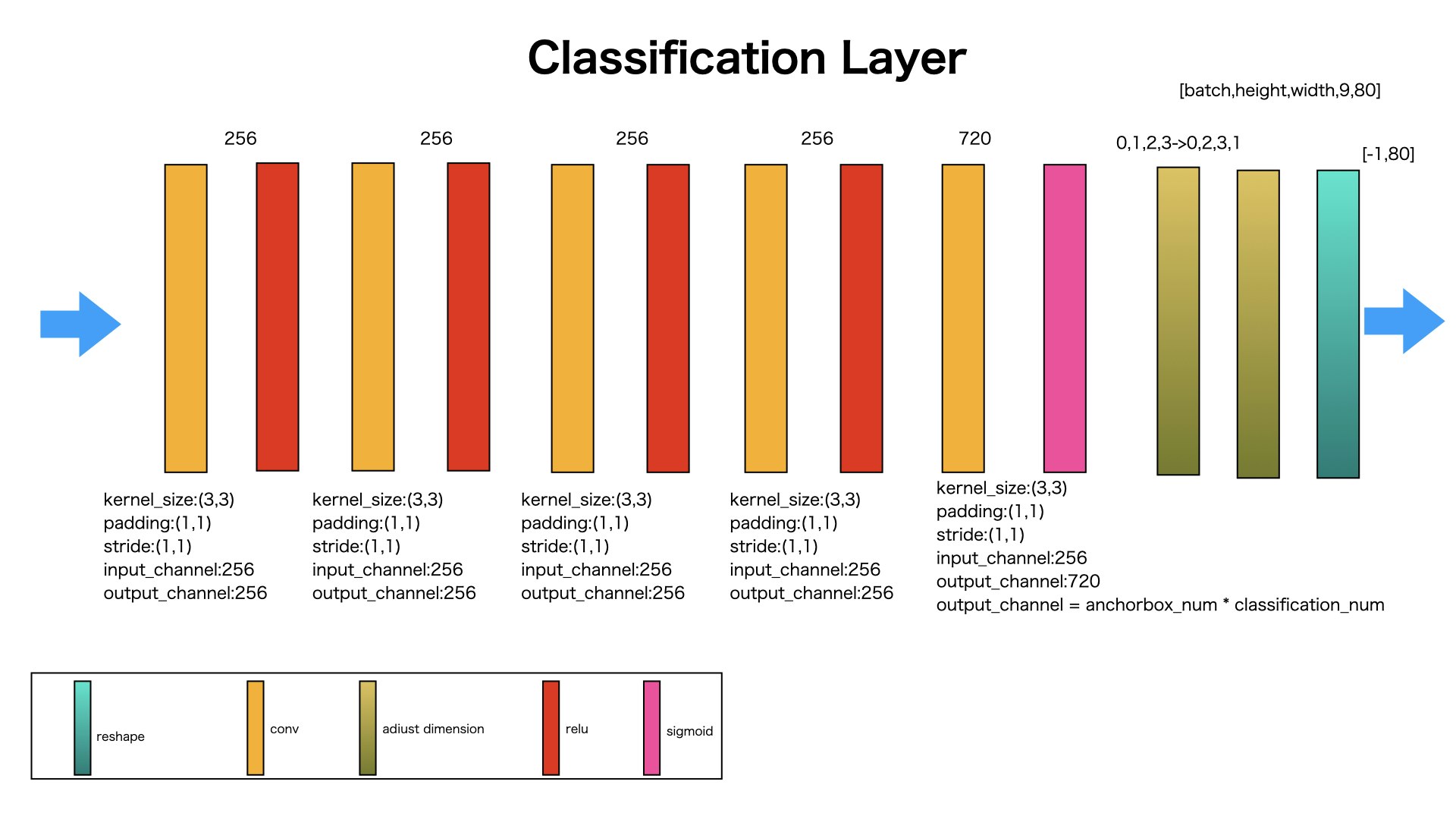
図のように、Regression Layerと同じように、次元だけ変えます。ただ、次元を36に変えることではなく、80に変えることです。それは各Anchor boxにたいいて、80種類の物体の信頼度を表すことです。
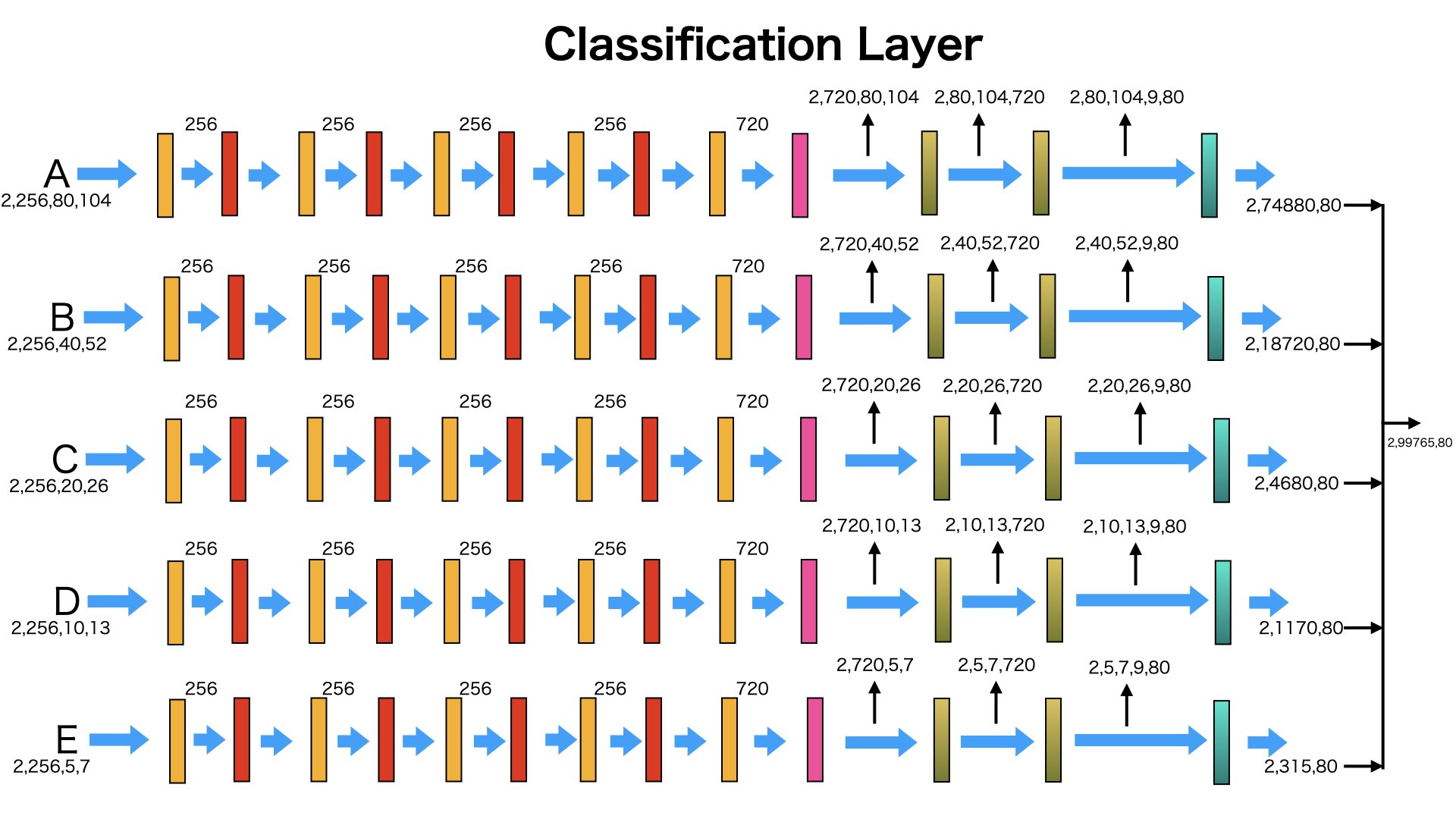
図のように、A,B,C,D,Eを入力データとして、Classification Layerに投げて、データのサイズが変わらず、次元が全部80になりました。
まとめ###
本節は前処理された画像データを入力データとして、ぞれぞれのレイヤーに流します。
layer0~layer4、feature pyramid layersの目的は
複数サイズ碁盤の囲碁に分割りされた画像にたいして、それぞれのマスにたいして、Offset情報と信頼度情報の生成を準備するためです。
Regression Layerの目的は
それぞれのマスに対して、生成された9個のAnchorBoxに対して、Offset情報を生成します。
Classification Layerの目的は
それぞれのマスに対して、80種類の物体にたいして、信頼度を生成します。
次回は画像をどのように複数サイズ碁盤の囲碁にあわせて分割りしますか
各マスを中心に、どのようにAnchor Boxを生成するのかを説明したいと思います。