「統計WEB Step1. 基礎編」のまとめ
※高校数学の内容は一部省略する。
1. 統計ことはじめ
変数の尺度
- 質的データ(ディメンジョン)
文字で表現する。
(例)住所、血液型、好きな食べ物 - 量的データ(メジャー)
数値で表現する。
| 尺度 | 説明 | 例 | |
| 質的 データ |
名義尺度 | 区別・分類するためのもの。固有名詞 | 男女、血液型、都道府県、血液型 |
| 順序尺度 | 順序を示す名詞・形容詞 | 1位/2位/...、大中小、好き/普通/嫌い | |
| 量的 データ |
間隔尺度 | 目盛が等間隔で差に意味がある。負の値を許容する。 | 気温、知能指数 |
| 比例尺度 | 0が原点とした間隔・比率に意味がある。負の値を許容しない。 | 身長、体重、速度 |
説明変数と目的変数
説明変数(x)
何かの原因となっている変数
(予測変数、独立変数)
目的変数(y)
その原因を受けて発生した結果となっている変数
(応答変数、反応変数、結果変数、従属変数、基準変数、被説明変数)
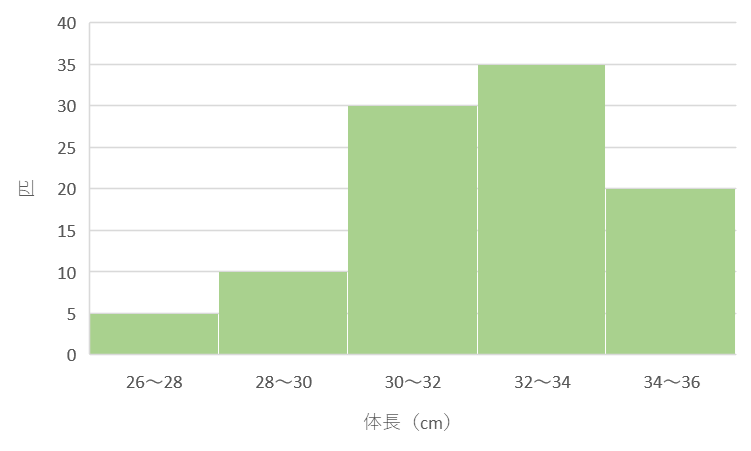
2. 度数分布とヒストグラム
度数分布表
データの大まかな分布を知るために、データをある幅ごとに区切ってその中に含まれるデータの個数を見る。
- 階級:度数を集計するための区間
- 階級値:階級の真ん中の値
- 度数:各階級に含まれるデータ数
- 相対度数:各階級の度数が全体に占める割合
- 累積相対度数:相対度数の累計
| 階級(cm以上~cm未満) | 階級値(cm) | 度数 | 相対度数 | 累積相対度数 |
|---|---|---|---|---|
| 26~28 | 27 | 5 | 5% | 5% |
| 28~30 | 29 | 10 | 10% | 15% |
| 30~32 | 31 | 30 | 30% | 45% |
| 32~34 | 33 | 35 | 35% | 80% |
| 34~36 | 35 | 20 | 20% | 100% |
ヒストグラム
横軸:階級(度数分布表の例の場合、体長の階級)
縦軸:度数
パレート図
ヒストグラムの各階級の棒を度数が大きい順に左から並べ替え、その上に累積相対度数の折れ線グラフを重ねたグラフ図。
ヒストグラムと累積相対度数の折れ線グラフがある状態。
- 左から右へ度数が小さくなる
⇒「右裾が長い」or「右に歪んだ」or「左に偏った」分布のヒストグラム - 左から右へ度数が大きくなる
⇒「左裾が長い」or「左に歪んだ」or「右に偏った」分布のヒストグラム
棒グラフとヒストグラムの使い分け
- 棒グラフ…質的データの可視化に使う
- ヒストグラム…量的データの可視化に使う
階級幅の決め方
階級幅:度数を集計するための区間の大きさ
グラフを一目見て分布の特徴が捉えられるようにすることが推奨される。
階級幅を決められない場合、「スタージェスの公式」を使うことができる。
\displaylines{
階級の数=1+\log_2 n
}
※$n$:データ数
度数分布表の例の場合、猫100匹のデータ
⇒$1+\log_2 100 =7.64... \fallingdotseq 8 $
ローレンツ曲線
分布 の「偏り=不均等さ」を表すための曲線。
ローレンツ曲線を作るためには2つの累積相対度数が必要となる。
- 各階級の度数の累積相対度数
- 各階級に属する値の合計の累積相対度数
横軸:各階級の度数の累積相対度数(1)
縦軸:各階級に属する値の合計の累積相対度数(2)
にとった折れ線グラフをローレンツ曲線という。
- 直線でなく、曲線であればあるほど分布は不均等といえる
- 完全平等線に対して下側凸か上側凸になる。跨ぐことはない
ジニ係数
- 完全平等線
座標(0,0)と(1,1)を結ぶ線 - ジニ係数
「偏り」や「不均等さ」を数値で表したもの。
完全平等線とローレンツ曲線で囲んだ面積(下図の橙色部分)を2倍にした値。
0から1までの値をとり、1に近いほど偏りが大きく、0に近いほど偏りが小さい(完全平等線に近くなる)。
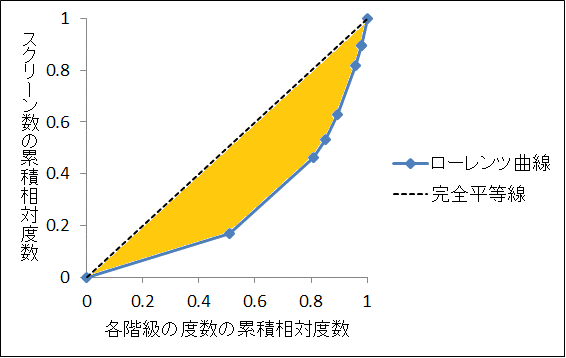
画像参照:2-5. ジニ係数
https://bellcurve.jp/statistics/course/3798.html
- ジニ係数の求め方
(完全平等線とx軸で囲まれた部分の面積
-ローレンツ曲線をとx軸で囲まれた部分の面積※)×2
※三角形や台形に分解して、それぞれの面積を求める
3. さまざまな代表値
-
平均
全てのデータの合計値 ÷ データ数※n個の階級を持つ度数分布表の場合、階級値$\upsilon_i$と度数$f_i$(i=1,2,...,n)を使っておよその平均を算出できる。
\displaylines{
\bar{X}=
\frac{(f_1 \upsilon_1+f_2 \upsilon_2+ \cdots +f_n \upsilon_n)}
{(f_1+f_2+ \cdots +f_n)}
}
- 中央値
データを小さい順に並べたとき、真ん中の順番のデータの値のこと。
データ数が偶数個ある場合、中央に最も近い2つの値の平均値を中央値とする。
- 最頻値(モード)
出現頻度が最も多い値。データによってはモードが2つある場合がある。
平均・中央値・モードの関係
- 左右対称の山型の分布の場合(正規分布の場合)
平均=中央値=モード
全て同じ度数の値になる。 - 度数が左に偏っている(右に裾を引いている)分布の場合
モード>中央値>平均
となることが多い。(必ずそうなるとは限らない)
ヒストグラムの山が複数ある場合
- 多峰性 (multimodal)
分布の山が複数あること - 二峰性 (bimodal)
分布の山が2つのもの。
二峰性のデータの場合、異なる性質の集団が混ざっている可能性がある。 - 単峰性 (unimodal)
分布の山が1つのもの
いろいろな平均
算術平均
全てのデータの合計値 ÷ データ数
幾何平均
比率や割合で変化するものに対してその平均を求めるときに使う。
(例)過去3年間で家賃が20%、10%、15%上昇したときに、1年で平均何%上昇したかを算出する
\displaylines{
\bar{x}_G=
\sqrt[n]{x_1 \times x_2 \times \cdots \times x_n}
}
調和平均
時速の平均などを求めるときに使う。
\displaylines{
\bar{x}_H
=
\frac{n}
{\frac{1}{x_1}+\frac{1}{x_2}+ \cdots +\frac{1}{x_n}}
}
刈込み平均 (トリム平均)
データを小さい順に並べたとき、小さい側と大きい側からそれぞれ指定した個数の値を除き、残ったデータのみから求める平均。
\displaylines{
\bar{x}_k=
\frac{1}{n-2k}
\sum_{i=1+k}^{n-k}x_i
}
歪度と尖度
歪度(わいど)
分布が正規分布からどれだけ歪んでいるかを表す統計量。左右対称性を示す指標。
\displaylines{
\frac{n}{(n-1)(n-2)}
\sum_{i=1}^{n}
(\frac{x_i - \bar{x}}{s})^3
}
※$n$:データ数。$x_i(i:1,2, \cdots ,n)$:各データの値
※$\bar{x}$:データの平均値。$s$:標準偏差
- 左右対称の山型の分布の場合(正規分布の場合)
歪度 = 0 - 度数が左に偏っている(右裾が長い、右に歪んだ)分布の場合
歪度 > 0(正の値) - 度数が右に偏っている(左裾が長い、左に歪んだ)分布の場合
歪度 < 0(負の値)
尖度(せんど)
分布が正規分布からどれだけ尖っているかを表す統計量。山の尖り度と裾の広がり度を示す。
\displaylines{
\frac{n(n+1)}{(n-1)(n-2)(n-3)}
\sum_{i=1}^{n}
\frac{(x_i - \bar{x})^4}{s^4}-
\frac{3(n-1)^2}{(n-2)(n-3)}
}
※$n$:データ数。$x_i(i:1,2, \cdots ,n)$:各データの値
※$\bar{x}$:データの平均値。$s$:標準偏差
- 左右対称の山型の分布の場合(正規分布の場合)
尖度 = 0 - 正規分布より尖った分布の場合(データが平均付近に集中し、分布の裾が重い)
尖度 > 0(正の値) - 正規分布より扁平な分布の場合(データが平均付近から散らばり、分布の裾が軽い)
尖度 < 0(負の値)
4. 箱ひげ図と幹葉表示
- 箱ひげ図
データの分布を「箱」と「ひげ」で表したグラフ。データがどの値に集中しているかを表すことができる。
例:ひげの上端と下端が最大値や最小値の箱ひげ図
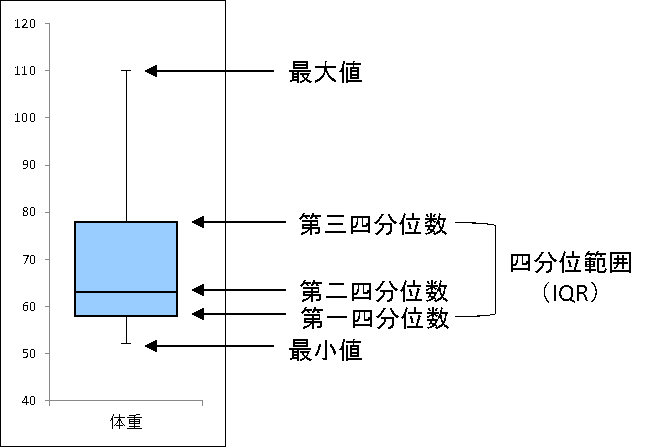
画像参照:4-2. 箱ひげ図の見方
https://bellcurve.jp/statistics/course/5220.html
箱ひげ図の見方
パーセンタイル
データを小さい順で並べたとき、ある数値が最小値(0パーセントタイル)から見て何%の位置にあるかを表すもの
四分位数
データを小さい順に並べたとき、データ数で4等分した時の区切り値。
小さい順に
- 25パーセンタイル(第一四分位数) ※全体の1/4の部分
- 50パーセンタイル(第二四分位数=中央値) ※全体の2/4=1/2の部分
- 75パをーセンタイル(第三四分位数) ※全体の3/4の部分
と呼ばれる。
四分位範囲=第三四分位数 - 第一四分位数
四分位数の求め方
- 小さい順にデータを並べ、最小値・最大値・中央値を求める
⇒第二四分位数(中央値)が分かる - 中央値より小さい値、大きい値の2グループに分ける
※データ数が偶数個ある場合、小さい方の中央値を小さい値のグループに、大きい方の中央値を大きい値のグループに入れる。 - 小さい値のグループ、大きい値のグループそれぞれの中央値を求める
⇒第一四分位数、第三四分位数が分かる - 第三四分位数 - 第一四分位数で四分位範囲を求める
5数要約
下記5つの値のこと
- 最小値(ひげの下端)
- 第一四分位数
- 中央値(第二四分位数)
- 第三四分位数
- 最大値(ひげの上端)
※範囲 = 最大値 - 最小値
外れ値検出のある箱ひげ図
ひげの長さを四分位範囲(第三四分位数 - 第一四分位数)の1.5倍を上下限とするもの。
ひげの下限 = 第一四分位数 - 1.5 × 四分位範囲
ひげの上限 = 第三四分位数 + 1.5 × 四分位範囲
外れ値
データの分布において、他の観測値から大きく外れた値。
測定ミスによる場合や実際に何か異常があって観測された場合など、様々な原因によって起こりうる。
ひげの下端より小さい値や、ひげの上端より大きい値。
箱ひげ図では「×」印で表示する。
幹葉表示(幹葉図)
データの値そのものを用いて作成するヒストグラムに似た図のこと。
「幹」と「葉」から構成され、個々のデータは縦向きに並ぶ「幹」に対応した1桁の数字が「葉」のように幹の横に並ぶ。
(例)「27, 30, 33, 33, 37, 41, 45」というデータがあった場合
| 幹 | 葉 |
|---|---|
| 2 | 7 |
| 3 | 0 3 3 7 |
| 4 | 1 5 |
5. データの集計と表現
手元にあるデータを見て、データの分布や特徴をつかめるようにする。
質的データの場合
まずデータを「集計」する。
⇒項目ごとにデータを数えたり合計したりした結果をまとめる。
⇒集計したデータを用いて棒グラフや円グラフなどを作成する。
量的データの場合
まず平均値、最小値・最大値などの「基本統計量」を求める。
⇒箱ひげ図、ヒストグラムを作成し、分布を確認する。
棒グラフ・円グラフ・折れ線グラフ
- 棒グラフ
データの大きさを棒の高さで表したグラフ。 - 円グラフ
データの大きさを全体の円に対する割合で表したもの。
ドーナツグラフにして合計値を中央に書くタイプもある。 - 折れ線グラフ
グラフにプロットされたデータの点を時間の経過に従って直線で結んだもの。
クロス集計表
2つのカテゴリに属するデータをそれぞれのカテゴリで同時に分類し、その度数を集計したもの。
| サッカー | 野球 | テニス | 水泳 | 合計 | |
|---|---|---|---|---|---|
| 男子 | 7 | 5 | 2 | 1 | 15 |
| 女子 | 5 | 3 | 5 | 2 | 15 |
| 合計 | 12 | 8 | 7 | 3 | 30 |
表側(ひょうそく):左側の項目(性別のヘッダ部分)
表頭(ひょうとう):上側の項目(スポーツのヘッダ部分)
クロス集計表から各セルの割合を求めると、各項目の割合を比較しやすくなる。
- 行パーセント(横パーセント)
行方向の値の合計を100%と見なしたときの各セルの割合。
上表の場合、行ごとの比率を入れる。(男子行のスポーツ人数比と女子行のスポーツ人数比を各セルに入れる。) - 列パーセント(縦パーセント)
列方向の値の合計を100%と見なしたときの各セルの割合。
上表の場合、列ごとの比率を入れる。(サッカー・野球・テニスの各行の男女比を各セルに入れる。) - 総パーセント
すべての値の合計を100%と見なしたときの各セルの割合
上表の場合、合計人数に対する比率を各セルに入れる。
帯グラフ・モザイク図
帯グラフ
クロス集計表において群ごとの割合を比較するためのもの。
積み上げ棒グラフを横向きにした形状で、横の幅がすべて「100%」で固定している。
帯全体に対して、データの大きさを割合で表す。
(円グラフの帯バージョン)
モザイク図
表側のカテゴリーごとに積み上げ100%の縦棒グラフを作成し、横幅を表側の各カテゴリーの度数の合計に比例するグラフ。
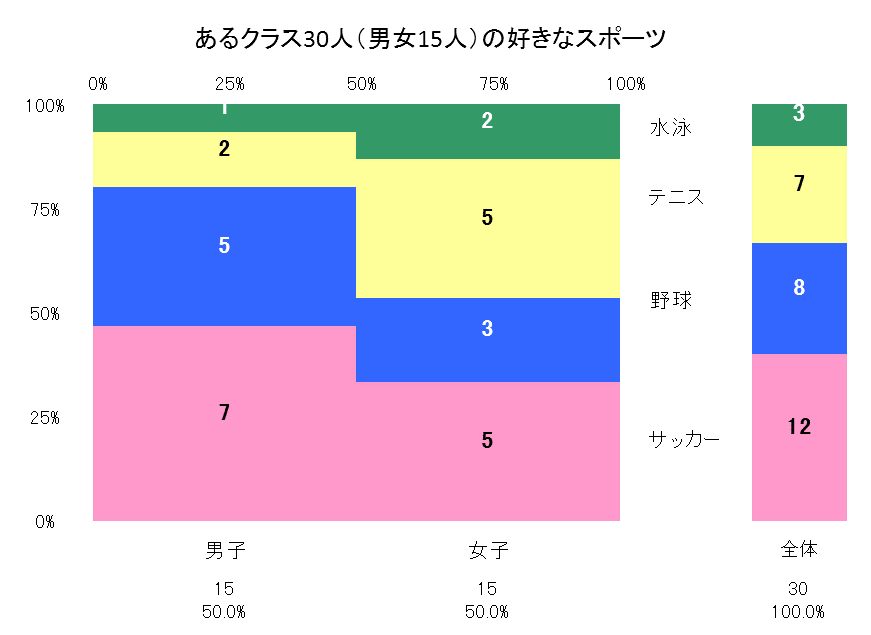
画像参照:5-5. 帯グラフ・モザイク図
https://bellcurve.jp/statistics/course/5416.html
三角グラフ
3つの要素で構成されるデータにおいて、その構成比を表す際に用いられるグラフ。
グラフにプロットされたデータの点から三角形の各辺と平行な直線を引いたとき、辺との交点の値が3要素の構成比を表す。
(例)世界の主な国の産業別人口構成(%)を、「第1次産業」、「第2次産業」、「第3次産業」ごとにまとめたもの
| 国名 | 第1次産業 | 第2次産業 | 第3次産業 |
|---|---|---|---|
| 日本 | 3.8 | 24.9 | 70.0 |
| インド | 47.2 | 24.7 | 28.1 |
| 中国 | 33.6 | 30.3 | 36.1 |
| イギリス | 1.1 | 18.7 | 79.3 |
| アメリカ | 1.5 | 18.3 | 80.2 |
| メキシコ | 13.6 | 23.8 | 62.0 |
出典:地理 統計要覧2015年版 二宮書店
http://www.ninomiyashoten.co.jp/item-cat/databook
表より、インドのデータを三角グラフに表す。
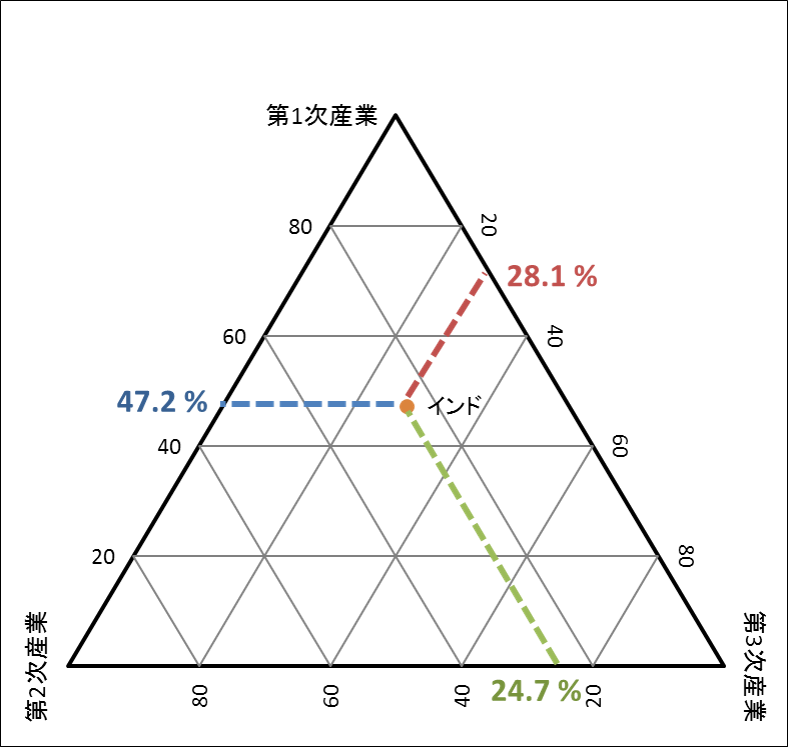
画像参照:5-6. 三角グラフ
https://bellcurve.jp/statistics/course/5418.html
6. 分散と標準偏差
分散(V)
「データがどの程度平均値の周りにばらついているか」を表す指標。
それぞれのデータと平均値の差(偏差)を2乗したものの平均。値は必ず0以上になる。
\displaylines{
V=
\frac{1}{n}
\sum_{i=1}^{n}
(x_i - \bar{x})^2
}
※$n$:データ数。$x_i(i:1,2, \cdots ,n)$:各データの値
※$\bar{x}$:データの平均値。
標準偏差
分散の正の平方根。小文字のシグマ$\sigma$で表す。
\displaylines{
\sigma = \sqrt{\frac{1}{n} \sum_{i=1}^{N} (x_i - \bar{x})^2}
}
※$n$:データ数。$x_i(i:1,2, \cdots ,n)$:各データの値
※$\bar{x}$:データの平均値。
標準偏差同士を比較する際は、単位をそろえる必要がある。
変動係数(CV)
変動係数=標準偏差÷平均値
単位の異なるデータのばらつきや、平均値に対するデータとばらつきの関係を相対的に評価する際に用いる単位を持たない(=無次元の)数値。
\displaylines{
CV=
\frac{\sigma}{\bar{x}}
}
変動係数を使うコツ
平均値に対して標準偏差が比例関係にあるものに対して適用すること。
比例尺度の場合に有効な指標だが、間隔尺度では参考にならない。階乗
7. 場合の数
!(階乗)
ある正の整数から1までの整数の積。
$\prod$(パイ)を使った数式もある。
\begin{align}
n! &= n \times (n-1) \times (n-2) \times \ldots \times 2 \times 1 \\
&= \prod_{i=1}^{n} i
\end{align}
P(順列 Permutation)
異なるn個からk個を取り出した順に1列に並べること。
(例)6人のグループから4人を選び、選ばれた順番に左から1列に並べる。
\displaylines{
{}_nP_k = \frac{n!}{(n-k)!}
}
C(組み合わせ Combination)
異なるn個のものからk個を取り出すこと。
\displaylines{
{}_nC_k = \frac{{}_nP_k}{k!} = \frac{n!}{k!(n-k)!}
}
8. さまざまな事象
-
試行
結果が予想通りになるかどうかを、実験や観察を行い試すこと -
事象
試行によって起こった結果 -
全事象$\Omega$、$U$
ある試行について、起こりうる全ての事象をまとめたもの -
複合事象
分解が可能な事象。複数の事象が含まれている -
根元事象
これ以上分解することのできない事象 -
余事象
「“ある場合”以外」の事象
事象$A$と余事象$A^c$($\bar{A}$)があるとき、全事象$\Omega=A+A^c$となる。 -
空事象(くうじしょう)$\phi$
存在しない事象
(例)さいころで7の目が出る事象 -
排反事象(はいはんじしょう)
同時に起こらない事象
(例)さいころで「偶数の目が出る事象」と「奇数の目が出る事象」は同時に起こらない
和事象
2つの事象ABのうちAまたはBが起こる事象。
$A \cup B$
※AカップBと読む。
積事象
2つの事象ABのうちAとBが同時に起こる事象。
$A \cap B$
※AハットBと読む。
9. 確率と期待値
確率
物事の「起こりやすさ」を定量的に表す指標。
$P(A)$、$P(A)$:事象Aが起こる確率
確率の3つの約束ごと(公理)
- どのような事象についての確率も、0以上1以下となる
- 全事象$\Omega$の起こる確率$P(\Omega)$は1となる
- 互いに排反な事象の和集合の確率は、それぞれの事象の確率の和となる
確率の計算(余事象)
$P(A^c)=1-P(A)$
確率と独立
2つの事象が独立(互いの結果が影響しない)の場合
$P(A \cap B)=P(A) \times P(B)$
加法定理
- 事象Aと事象Bが互いに排反(同時に起こらない事象)である場合
$P(A \cup B)=P(A) + P(B)$ - 事象Aと事象Bが互いに排反ではない場合
$P(A \cup B)=P(A) + P(B)-P(A \cap B)$
期待値
1回の試行で得られる値の平均値。
n通りの結果$x_i (i=1,2, \cdots ,n)$があり、それぞれの起こる確率が$p_i$の場合、
\displaylines{
\sum_{i=1}^{n}p_i x_i
}
10. 条件付き確率とベイズの定理
条件付き確率(≒事後確率)
ある事象が起こるという条件のもとで、別のある事象が起こる確率。
事象Bが起こるという条件のもとで事象Aが起こる場合、
\displaylines{
P(A|B) = \frac{P(A \cap B)}{P(B)}
}
- 事象Aの起こる確率が事象Bの影響を受けない(独立の)場合
\displaylines{
P(A|B) = P(A)
}
- 事象Aと事象Bが互いに排反(同時に起こらない事象)である場合
\displaylines{
P(A|B) = 0
}
乗法定理
条件付き確率の数式を加工する。
\displaylines{
P(A \cap B) = P(B) \times P(A|B) = P(A) \times P(B|A)
}
ベイズの定理
$P(B|A)$:事象Aが起きた後で事象Bが起きる確率(事後確率)
\displaylines{
P(B|A) = \frac{P(B)\cdot P(A|B)}{P(A)}
}
(例)事象Aが起こるという条件のもとで、k種類の事象B($B_1,B_2, \cdots ,B_k$:互いに排反とする)があるとする。
事象Aが起こるという条件のもとで、事象$B_i$が起こる条件付き確率$P(B_i|A)$は以下のようになる。
※条件確率の数式を当てはめただけ
ここに乗法定理を当てはめると
\displaylines{
P(B_i|A) = \frac{P(A \cap B_i)}{P(A)} = \frac{P(B_i)\cdot P(A|B_i)}{P(A)}
=\frac{P(B_i)\cdot P(A|B_i)}{\sum_{j=1}^{k}P(B_j)P(A|B_j)}
}
- 事前確率
「事象Aが起こる前」の、事象Bの確率 - 事後確率
「事象Aが起きた後」の、事象Bの確率
11. 確率変数と確率分布
- 確率変数$X$
ある変数の値をとる確率が存在する変数
(例)さいころの出る目の場合、確率変数は1から6までの整数の値を取る。 - 確率分布
確率変数がとる値とその値をとる確率の対応の様子
(例)さいころの出る目の確率分布
| さいころの出る目 | 1 | 2 | 3 | 4 | 5 | 6 |
| 確率 | $\frac{1}{6}$ | $\frac{1}{6}$ | $\frac{1}{6}$ | $\frac{1}{6}$ | $\frac{1}{6}$ | $\frac{1}{6}$ |
離散型確率分布と確率質量関数
-
離散型変数
とびとびの値をとる変数。隣り合う数字の間には小数などの値が存在しない。
(さいころの出る目や人数など) -
離散型確率変数
離散型変数の取りうる値に対応する確率の変数($p$) -
離散型確率分布(離散型分布)
確率変数が離散型である場合の確率分布
確率質量関数
離散型確率変数$X$がある値$x$をとる確率を関数にしたもの。
\displaylines{
f(x)=P(X=x)
}
全事象が起こる確率は1なので、以下の式が成り立つ。
\displaylines{
\sum_{i=1}^{n}P(X=x_i)=1
}
連続型確率分布
-
連続型変数
重さや温度などのように連続した値。 -
連続型確率変数
連続型変数の取りうる値に対応する確率の変数($p$) -
連続型確率分布(連続型分布)
確率変数が連続型である場合の確率分布。
確率変数の値をある一点に定めた場合、その値をとる確率は「0」になる。
\displaylines{
f(x)=P(X=x)=\frac{1}{\infty}=0
}
確率密度と確率密度関数
確率密度
確率密度は定義域内での確率変数$X$の値の「相対的な出やすさ」を表す。
確率分布のグラフを作るとき、連続型確率変数の場合、確率変数がある一点の値をとる確率は0になることから、縦軸は確率ではなく「確率密度」を使う。
横軸は確率変数$X$を使う。
確率密度関数
連続型確率変数$X$がある値$x$をとる確率密度を関数$f(x)$にしたもの。
確率とは異なり、$f(x)\geq 1$になる場合がある。
連続型確率分布と確率
確率変数$X$の確率密度関数$f(x)$において、$a\geq X\geq b$となる確率は、積分の計算で求められる。
\displaylines{
P(a\geq X\geq b)=\int_{a}^{b}f(x)dx
}
全事象が起こる確率は1なので、以下の式が成り立つ。
\displaylines{
\int_{-\infty}^{\infty}f(x)dx=1
}
離散型分布と連続型分布の種類
| 離散型分布 | 連続型分布 |
| 一様分布 二項分布 多項分布 ポアソン分布 幾何分布 (超幾何分布) |
連続一様分布 正規分布 指数分布 t分布 F分布 カイ二乗分布 |
12. 累積分布関数と確率変数の期待値・分散
累積分布関数
「確率変数$X$がある値$x$以下の値となる確率」を表す関数。
(例)さいころの出る目が4以下となる確率
\displaylines{
F(x)=P(X\leq x)
}
- 確率変数が離散型の場合
\displaylines{
F(x)=P(X\leq x)=\sum_{X\leq x}P(X)
}
- 確率変数が連続型の場合
確率密度関数$f(x)$を積分することで求められる。
\displaylines{
F(x)=P(X\leq x)=\int_{-\infty}^{x}f(t)dt
}
累積分布関数の性質
- $F(\infty)=1$
- $F(- \infty)=0$
- $X\leq Y$である場合、$F(X)\leq F(Y)$
確率変数の期待値
確率変数の平均値を表す。
- 離散型確率変数の場合
\displaylines{
E(X) = \sum_{i=1}^{n} x_i p_i
}
- 連続型確率変数の場合
\displaylines{
E(X) = \int_{-\infty}^{\infty}xf(x)dx
}
期待値の性質
定数$C$とする。
- $E(C)=C$ ※定数の期待値は定数になる
- $E(X+C)=E(X)+E(C)=E(X)+C$
- $E(kX)=kE(X)$
- $E(X+Y)=E(X)+E(Y)$
確率変数の分散
「確率変数のとり得る値と期待値(平均値)の差の2乗」と「確率」との積を、全て足し合わせたもの。
- 離散型確率変数の場合
$\mu$:離散型確率変数$X$の期待値$E(X)$
\displaylines{
V(X) = \sum_{i=1}^{n}(x_i-\mu)^2 p_i
}
- 連続型確率変数の場合
$\mu$:離散型確率変数$X$の期待値$E(X)$
\displaylines{
V(X) = \int_{-\infty}^{\infty}(x_i-\mu)^2 f(x)dx
}
分散は以下のようにも求められる。
$V(X) = E(X^2)-
\bigl(
E(X)
\bigr)^2$
分散の性質
定数$C$とする。
- $V(C)=0$
- $V(X+C)=V(X)$
- $V(kX)=k^2 V(X)$
- $V(X+Y)=V(X)+V(Y)$ ※XとYが独立である場合
13. いろいろな確率分布1
二項分布
ベルヌーイ試行
何かを行ったときに起こる結果が2つしかない試行のこと。
- 確率変数$X$=1
結果「成功」とする。 - 確率変数$X$=0
結果「失敗」とする。
\displaylines{
P(X=1) =p \\
P(X=0) =1-p \\
}
二項分布
ベルヌーイ試行を$n$回行って、$X$回成功する確率の分布。
「$B(n,p)$」と書く。($n$:試行回数。$p$:確率)
\displaylines{
P(X = k) = {}_nC_k p^k (1-p)^{n-k}\\
(k=1,2, \cdots ,n)
}
二項分布の期待値と分散
\displaylines{
期待値E(X)=np\\
分散V(X)=np(1-p)
}
ポアソン分布
二項分布について、$np=λ$(ラムダ)とおき
n→$\infty$、p→0に近づけると、ポアソン分布に近似できる。
\displaylines{
P(X = k) = \frac{e^{-\lambda} \lambda^k}{k!}\\
(k=1,2, \cdots )
}
※$e$:自然対数の底(ネイピア数)という定数。
ポアソン分布の期待値と分散
\displaylines{
期待値E(X)=λ\\
分散V(X)=λ
}
ポアソン分布は試行回数nが非常に大きく、確率pが非常に小さいときに使われる。
二項分布との最大の違いは「n」と「p」が分からなくても使えること。
幾何分布
独立なベルヌーイ試行を繰り返す時、初めて成功するまでの試行回数$X$が従う確率分布。
\displaylines{
P(X = k) = (1-p)^{k-1} p\\
(k=1,2, \cdots)
}
幾何分布の期待値と分散
\displaylines{
期待値E(X)=\frac{1}{p}\\
分散V(X)=\frac{1-p}{p^2}
}
超幾何分布
AとBで構成されるN個からなる集団があり、AがM個、BがN-M個とする。この集団から取り出されたn個の中に含まれるAの個数が従う確率分布。
取り出されたAがk個である確率は以下のようになる。
\displaylines{
P(X = k) = \frac{{{}_M C_k \times {}_{N-M} C_{n-k}}}
{{{}_N C_n}}
\\
※max(0, n-(N-M)) \leq k \leq min(n,M)
}
超幾何分布の期待値と分散
\displaylines{
期待値E(X)=n \cdot \frac{M}{N}=np\\
分散V(X)=n \cdot \frac{M(N-M)}{N^2} \cdot \frac{N-n}{N-1}
=np(1-p) \cdot \frac{N-n}{N-1}
}
$N→\infty$の場合、超幾何分布は二項分布に近似する。
\displaylines{
分散V(X)=np(1-p)
}
負の二項分布
成功確率がpである独立なベルヌーイ試行を繰り返す時、
定義1
k回成功するまでの失敗回数Xが従う確率分布。
k回成功するまでにx回失敗する確率は以下のようになる。
\displaylines{
P(X = k) = {}_{k+x-1} C_{x} p^k(1-p)^x\\
(k=1,2, \cdots)
}
定義2
k回成功するまでの試行回数Xが従う確率分布。
k回成功するまでにx回試行する確率は以下のようになる。
k=1の場合、幾何分布と等しくなる。
\displaylines{
P(X = k) = {}_{x-1} C_{k-1} p^k(1-p)^{x-k}\\
(k=1,2, \cdots)
}
負の二項分布の期待値と分散
- 定義1
\displaylines{
期待値E(X)=k \frac{1-p}{p}\\
分散V(X)=k \frac{1-p}{p^2}
}
- 定義2
\displaylines{
期待値E(X)=\frac{k}{p}\\
分散V(X)=k \frac{1-p}{p^2}
}
14. いろいろな確率分布2
正規分布
統計学における検定や推定、モデルの作成など様々な場面で活用される連続型確率分布。正規分布は平均を中心に左右対称。
正規分布に従う確率変数Xの確率密度関数は以下のようになる。
\displaylines{
f(x) = \frac{1}{\sqrt{2\pi}\sigma} e^{-\frac{(x-\mu)^2}{2\sigma^2}}\\
(-\infty < x < \infty)
}
期待値と分散は以下のようになる。
\displaylines{
E(X)=\mu \\
V(X)=\sigma^2
}
正規分布の再生性
同じ確率分布を持つ2つの独立な確率変数の和は同じ確率分布を持つ。
正規分布$N(\mu_1,\sigma_1 ^2)$に従うあるデータと、別の独立な正規分布$N(\mu_2,\sigma_2 ^2)$に従うデータを足したデータは、正規分布$N(\mu_1 + \mu_2,\sigma_1 ^2 + \sigma_2 ^2)$に従う。
標準正規分布
正規分布の中で、特に「平均$\mu=0$、分散$\sigma^2=1$」である正規分布。
N(0,1)と書く。
()
標準化
ある正規分布を平均0・分散1の標準正規分布に変換するために、確率変数Xを確率変数zに変換させること。
標準化した値を「値」、「標準化得点」と呼ぶ。
\displaylines{
z=\frac{X-\mu}{\sigma}
}
偏差値
「平均が50点、標準偏差が10点」となるように、標準化した値zに10かけてを50足したもの。
\displaylines{
z \times 10+50
}
- 偏差値が高いほど成績が良いことを、低いほど成績が悪いことを表す
- 平均点と同じ点数だった場合、偏差値は50になる
- 偏差値は100以上の値やマイナスの値をとる場合がある
標準正規分布表
標準正規分布におけるx軸上の値z以上もしくは以下となる確率がまとめられている表。
(例)下画像の場合、表の値は水色部分の面積を表す。
「標準正規分布に従うZがとる値がz以上となる確率$P(Z \geq z)$」を意味する。
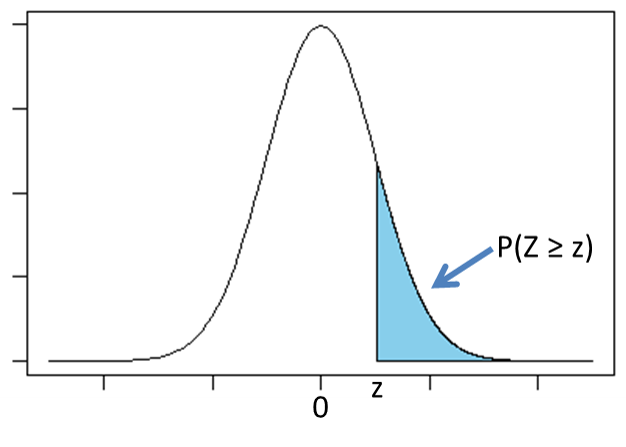
画像参照:14-5. 標準正規分布表の使い方1
https://bellcurve.jp/statistics/course/7805.html
15. いろいろな確率分布3
指数分布
連続型確率分布の一つで、次に何かが起こるまでの期間が従う分布。(機械の故障、災害など)
ある期間に平均してλ回起こる現象が、次に起こるまでの期間Xが指数分布に従うとき、X=xとなる確率密度関数は以下のようになる。
\displaylines{
f(x) = \left\{
\begin{array}{ll}
\lambda e^{-\lambda x} & (x \geq 0) \\
0 & (x \lt 0)
\end{array}
\right.
}
期待値と分散は以下のようになる。
\displaylines{
E(X)=\frac{1}{λ} \\
V(X)=\frac{1}{λ^2}
}
指数分布の使い方
ある期間に平均してλ回起こる現象が次に起こるまでの期間をXとしたとき、
「期間Xがx以下となる確率」、すなわち「xまでの累積分布関数F(x)」は以下のようになる。
\displaylines{
\begin{align}
F(x)&=P(X\leq x)=\int_{-\infty}^{x}f(t)dt\\
&= \int_{0}^{x}\lambda e^{-\lambda t}dt\\
&= 1- e^{-\lambda x}
\end{align}
}
指数分布とポアソン分布の違い
ある期間に平均してλ回起こる現象について
- 指数分布:次に起こるまでの期間に関する分布
- ポアソン分布:ある期間に起こる回数に関する分布
離散一様分布
-
一様分布
離散型、および連続型確率分布の一つで、確率密度関数が常に一定の値をとる分布のこと。
確率変数が離散型だと、離散一様分布。
確率変数が連続型だと、連続一様分布。 -
離散一様分布
すべての事象の起こる確率が等しい分布。
X=kとなる確率P(X=k)は、Nを確率変数Xの取りうる個数とすると、以下のようになる。
\displaylines{
P(X=k) = \frac{1}{N}\\
(k=1,2, \cdots ,N)
}
期待値と分散は以下のようになる。
\displaylines{
E(X)=\frac{N+1}{2} \\
V(X)=\frac{N^2-1}{12}
}
また、確率変数の範囲が$a \leq X \leq b$の場合、
\displaylines{
P(X=k) = \frac{1}{b-a+1}\\
(k=a,a+1, \cdots ,b)
}
期待値と分散は以下のようになる。
\displaylines{
E(X)=\frac{a+b}{2} \\
V(X)=\frac{(b-a+1)^2-1}{12}
}
連続一様分布
確率密度関数f(x)が一定の値をとる分布。
確率変数の範囲が$a \leq X \leq b$における連続一様分布に従う場合、
\displaylines{
f(x) = \frac{1}{b-a} \quad (a \leq X \leq b)\\
f(x) = 0 \quad (X<a,X>b)
}
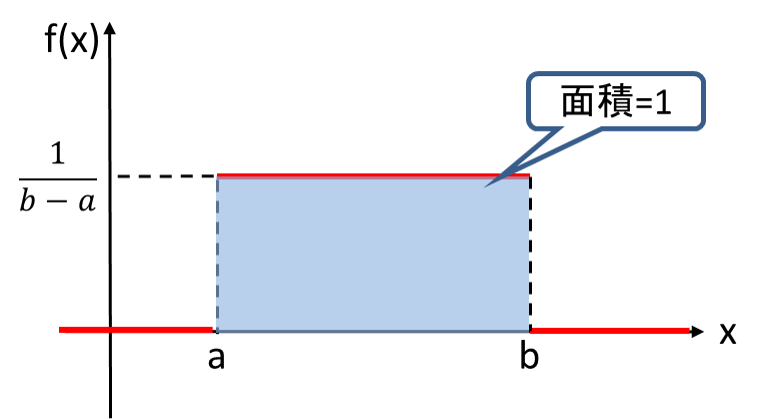
画像参照:15-3. 連続一様分布1
https://bellcurve.jp/statistics/course/8013.html
期待値と分散は以下のようになる。
\displaylines{
E(X)=\frac{a+b}{2} \\
V(X)=\frac{(b-a)^2}{12}
}
累積分布関数F(x)
-
x < aの場合
F(x)=0 -
$a \leq x < b$の場合
\displaylines{
\begin{align}
F(x)&=P(-\infty \leq X\leq x)=P(a \leq X\leq x)=\int_{a}^{x}f(t)dt\\
&= \int_{a}^{x}\frac{1}{b-a}dt\\
&= \frac{1}{b-a} \times (x-a)=\frac{x-a}{b-a}
\end{align}
}
- $ x \geq b$の場合
\displaylines{
\begin{align}
F(x)&=P(-\infty \leq X\leq x)=P(a \leq X\leq b)=\int_{a}^{b}f(t)dt\\
&= \int_{a}^{b}\frac{1}{b-a}dt\\
&= \frac{1}{b-a} \times (b-a)=1
\end{align}
}
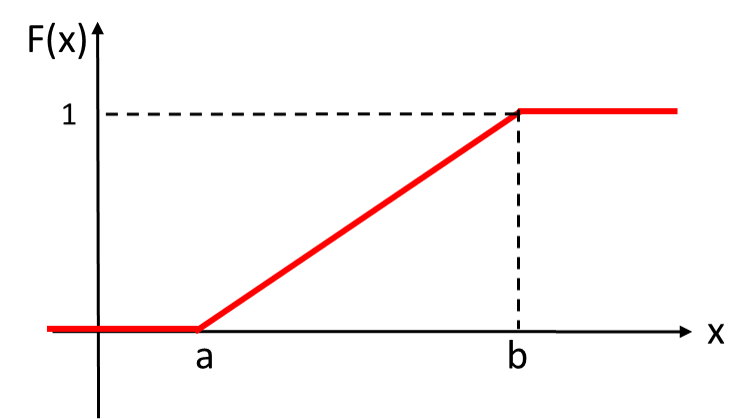
画像参照:15-3. 連続一様分布1
https://bellcurve.jp/statistics/course/8013.html
2変数の確率分布
確率変数が2つある場合に、それぞれの確率変数がとる値とその確率の分布を表す「同時確率分布」
離散型同時確率分布
確率変数が離散型。
(例)男女別の血液型を集計したとき、クロス集計表の各セルに割合(確率)を書いたとき、確率の総和は必ず1になる。
\displaylines{
\sum_{i}\sum_{j}f(x_i,y_j)=1
}
- 周辺確率分布
ある1つの確率変数を抜き出して(それ以外の確率変数は無視して)、その確率の総和を求めたもの。
Xが$x_i$を、Yが$y_i$をとるときの周辺確率分布は、以下のようになる。
以下の関数はそれぞれXとYの周辺確率関数と呼ぶ。
\displaylines{
f_x(x_i)=\sum_{j}f(x_i,y_j)=P(X=x_i) \quad (i=1,2, \cdots)\\
f_y(y_j)=\sum_{i}f(x_i,y_j)=P(X=y_j) \quad (j=1,2, \cdots)
}
連続型同時確率分布
- 同時確率密度関数$f(x,y)$
XとYがそれぞれ連続型確率変数である場合、XとYの同時確率分布を表す関数。
$a \leq X \leq b,c \leq Y \leq d$となる確率Pを求める場合、以下のようになる。
\displaylines{
P(a \leq X \leq b,c \leq Y \leq d)=\int_{a}^{b}\int_{c}^{d}f(x,y)dxdy
}
確率の総和は必ず1になるので、同時確率密度関数に関して次の式が成り立つ。
\displaylines{
\int_{-\infty}^{\infty}\int_{-\infty}^{\infty}f(x,y)dxdy=1
}
XとYの周辺確率関数は以下のようになる。
\displaylines{
f_x(x)=\int_{-\infty}^{\infty}f(x,y)dy\\
f_y(y)=\int_{-\infty}^{\infty}f(x,y)dx
}
2つの確率変数の期待値
\displaylines{
E(X+Y)=E(X)+E(Y)\\
E(X-Y)=E(X)-E(Y)\\
E(XY)=E(X)E(Y)
}
2つの確率変数の分散
\displaylines{
V(X+Y) = V(X) + V(Y) + 2Cov(X, Y)\\
V(X-Y) = V(X) + V(Y) - 2Cov(X, Y)
}
※$Cov(X, Y)$:共分散
2つの確率変数の共分散
確率変数X,Yの期待値をそれぞれ$\mu_x ,\mu_y$とする。
\displaylines{
Cov(X, Y) = E[(X-\mu_x)(Y-\mu_y)] = E(XY)-\mu_x \mu_y
}
- 相関係数$\rho$
2つのデータ(xとy)の関係性がどれだけ強いかを表す。
共分散を使うと2つの確率変数X,Yとの相関係数を計算できる。
\displaylines{
\rho =\frac{xとyの共分散}{(xの標準偏差)(yの標準偏差)}= \frac{Cov(X, Y)}{\sqrt{V(X)V(Y)}}
}