色々あって「DNNでリアルタイム音声処理をしたい」という需要が出てきたため、IRCAMが開発したMax用モジュール「nn~(nn_tilde)」を使い始めています。

ほぼ自力で調べて使い方を把握したのですが、普段使い慣れたメジャーなOSSと違ってドキュメントがあまり整備されておらず、公開されている応用例も(RAVE以外)ほぼ見つからないので、基本を押さえるまでかなり苦労しました。
このモジュール自体はそこそこ需要があると思うので、今後使う人のためにインストール手順からPyTorchモデルの作り方、エクスポートのやり方までおさらいしたいと思います。
最近ではQosmoが「VST版HuggingFace」という位置付けの素敵なプロジェクト「neutone」を発表しており、そちらも今後色々活躍しそうです。
インストール
nn~のGitHubリポジトリで説明されている通りですが、少し罠もあります。
ビルド済みバイナリ
macOSの場合は、バイナリが提供されているみたいです。バイナリを~/Documents/Max 8/Packages/nn_tilde/externals/に置けばOK。
ソースからビルド
Windowsの場合はソースからビルドする必要があります。macOSでもこっちを選択できます。
手順は以下の通りです。
1. LibTorch(PyTorchのC++用ライブラリ)をダウンロードし、libtorchフォルダをどこかに解凍する。
現時点の公式リポジトリではLibTorch 1.10のダウンロードリンクが貼られていますが、最新バージョンのPyTorch(現時点では1.11)でモデルを作る場合はLibTorchのバージョンも合わせる必要があります。PyTorch公式サイトからダウンロードしましょう。
2. Windowsの場合、C++コンパイラ付きのVisual Studioをインストールする。
3. 以下のコマンドを、ターミナルで実行する。Windowsの場合は、Visual Studioの開発用ターミナルで実行するといいです。
git clone https://github.com/acids-ircam/nn_tilde --recursive
cd nn_tilde
mkdir build
cd build
cmake ../src/ -DCMAKE_PREFIX_PATH=/path/to/libtorch -DCMAKE_BUILD_TYPE=Release
make
git clone https://github.com/acids-ircam/nn_tilde --recurse-submodules
cd nn_tilde
mkdir build
cd build
cmake . -S ..\src -DCMAKE_BUILD_TYPE:STRING=Release -G "<generator name of your Visual Studio version>" -A x64 -DTorch_DIR="<unzipped libtorch directory>\share\cmake\Torch"
cmake --build . --config Release
cmakeコマンドの引数はlibtorchのパスに置き換えましょう。また、Windows版の<generator name of your Visual Studio version>に入れるべき名前は、cmake --helpコマンドで確認することができます。
4. Windows版の場合、解凍したlibtorchフォルダ内のlibフォルダにあるDLLファイルを、Maxのインストールディレクトリ(Max.exeがあるところ)にコピーします。
5. コンパイル済みのバイナリはnn_tilde\src\externalsに置いてあります。
macの場合は~/Documents/Max 8/Packages/nn_tilde/externals/、Windowsの場合はDocuments\Max 8\Libraryにフォルダにコピーします。
6. nn_tilde\src\frontend\maxmsp\nn_tildeフォルダ内にnn~.maxhelpというファイルがあります。nn~モジュールの使い方を教えてくれるヘルプファイルなので、バイナリと同じ場所にコピーします。
厳密には、Options->File Preferences...で表示されているサーチパスに入っていれば、バイナリやモデルファイルはどこに置いてもOK。
ただし、パスに日本語が入っているとモデルをロードできなくなる場合があります。日本語が無いパスにフォルダを作り、File Preferences...の設定画面でパスを追加しましょう。

動作確認
Maxの新規パッチで、nn~オブジェクトを作成します。エラーが出なかったらOK。

オブジェクトを右クリックし、メニューからnn~モジュールのヘルプを開きます。
丸ボタンを押すと、IRCAMが作った学習済みモデルがダウンロードされます。クリックしてもすぐには反応しないので、何回もクリックしないように。
ダウンロードされた学習済みモデルwheel.tsをフォルダ内にコピーすると、ヘルプファイル内のプログラムを動かせるようになります。
PyTorchモデルの作成
PythonでPyTorchモジュールを定義し、nn~がロード可能なTorchScript形式に書き出します。
PyTorchモジュールの一例を書いてみます。(cached_convのリポジトリを参考しました)
import torch
import torch.nn as nn
class AutoEncoder(nn.Module):
def __init__(self):
super().__init__()
self.encoder =nn.Sequential(
nn.Conv1d(1, 16, 3, stride=2, padding=1),
nn.ReLU(),
nn.Conv1d(16, 16, 3, stride=2, padding=1),
nn.ReLU(),
nn.Conv1d(16, 16, 3, stride=2, padding=1),
)
self.decoder = nn.Sequential(
nn.ConvTranspose1d(16, 16, 4, stride=2, padding=1),
nn.ReLU(),
nn.ConvTranspose1d(16, 16, 4, stride=2, padding=1),
nn.ReLU(),
nn.ConvTranspose1d(16, 1, 4, stride=2, padding=1),
)
# メソッド設定ベクトル
self.register_buffer("forward_params", torch.tensor([1,1,1,1]))
self.register_buffer("encode_params", torch.tensor([1,1,16,8]))
self.register_buffer("decode_params", torch.tensor([16,8,1,1]))
def forward(self, x):
# 入力:(batch, 1, samples)
# 出力:(batch, 1, samples)
return self.decoder(self.encoder(x))
@torch.jit.export
def encode(self, x):
# 入力:(batch, 1, samples)
# 出力:(batch, 16, samples / 8)
return self.encoder(x)
@torch.jit.export
def decode(self, z):
# 入力:(batch, 16, samples / 8)
# 出力:(batch, 1, samples)
return self.decoder(z)
nn.ModuleのメソッドをMaxで使いたい場合、**_paramsという名前の4次元整数ベクトルをモジュールのメンバに加えます(**はメソッド名)。4つの値はそれぞれ
- 入力のチャンネル数
- 入力サンプルレートの倍数(例えば、1の場合は音声のサンプルレートと同じ、8の場合は音声サンプルレートの1/8の頻度でデータが入力される。圧縮された潜在特徴を入力する場合に使う。)
- 出力のチャンネル数
- 出力サンプルレートの倍数(潜在特徴を出力する場合に使う。)
をあらわしています。forwardメソッドの([1,1,1,1])の場合、入力・出力はともにチャンネル数1の音声波形である、という設定になります。encodeメソッドの場合、出力のチャンネル数が16で、時間軸の長さが音声波形の1/8倍なので、設定値は([1,1,16,8])です。関数の入力・出力テンソルの形が設定の値に合致するように書きましょう。
forward以外のメソッドを使いたい場合、@torch.jit.exportデコレーターを付ける必要があります。
続いて、モデルをTorchScript形式にエクスポートします。
model = Autoencoder()
... # 学習済みパラメータをmodelにロードするなど
traced = torch.jit.script(model) # モデルをTorchScriptにコンパイル
torch.jit.save(traced, "autoencoder.ts") # autoencoder.tsに保存
出力された.tsファイルをnn~モジュールのパスにコピーすればMaxでロードできるようになります。Autoencoderクラスではforward、encode、decodeの3つの関数を定義したため、Maxでは以下のような3つのオブジェクトを使うことができます。
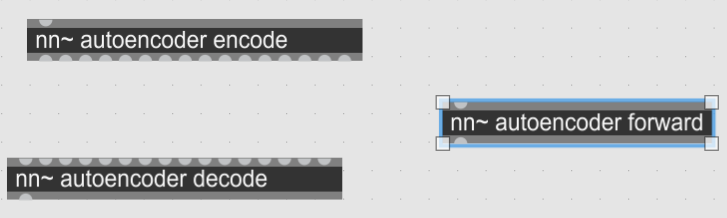
クラス定義に書いた通り、encodeメソッドは16チャンネルの出力、decodeメソッドは16チャンネルの入力を受け付けるようになっています。潜在特徴の次元数が大きい場合はreshapeで時間軸に展開するなどの工夫をしたほうが良さそうです。
おまけ:cached_conv
cached_convとは、RAVEを作った人が、RAVEをリアルタイム化するために考えた改造版Convolution層の実装です。nn~用のモデルを作るのにかなり有用なライブラリです(ただし、1D Convolutionのみ対応)。
論文:http://arxiv.org/abs/2204.07064
実装:https://github.com/acids-ircam/cached_conv
先ほどのAutoencoderクラスもそうですが、RAVEやMelGAN、HifiGANなどのディープ音声合成モデルで頻繁に使われる普通のConvolution層はNon-causal、つまり出力地点の前の入力だけでなく後の入力も「先読み」する仕組みになっているので、リアルタイム処理が不可能、あるいは大きな遅延を導入せざるを得ません。
そこで、推論時にConvolution層をCausalな形(入力の前のみにパディングを加える)にすると同時に、「入力値をキャッシュして次の入力のパディング値として使う」という仕組みを導入することで、学習済みのNon-causalなConvolution層のパラメータを変えずに、リアルタイム処理に利用できるようになります。
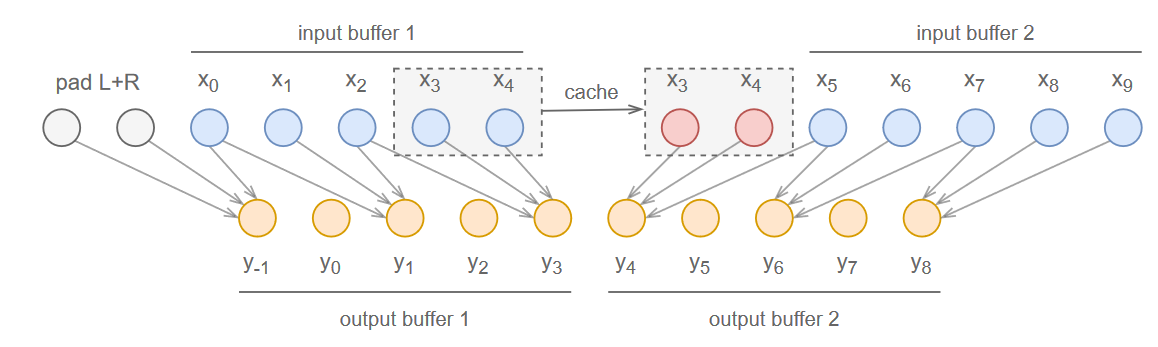
公式リポジトリに書いてある例の通り、改造版Convolution層を普通のそれと同じようにDNNに組み込んで実装・学習した後、推論時(.tsにエクスポートするとき)にuse_cached_conv(True)というおまじないを唱えれば、リアルタイム処理ができるモデルに早変わりするという仕様になっています。
ただし、入力のサイズを倍々で減らすようなStrided convolutionの場合、cached_convは一致性を保つために入力を一定数ディレイさせています。層を重ねるごとにディレイも蓄積されていくので、場合によってはcumulative_delayパラメータを利用して累計ディレイ量を記録する必要があります。やり方はRAVEの実装が参考になります。
DNN内に並行したブランチが存在する場合(例:スキップコネクションを持つResidual構造)、各ブランチの累計ディレイ量をもとに合流地点で追加ディレイを加え、時間軸を揃えます。cached_convライブラリでは、正しくディレイを加えるためにAlignBranchesクラスが用意されています。
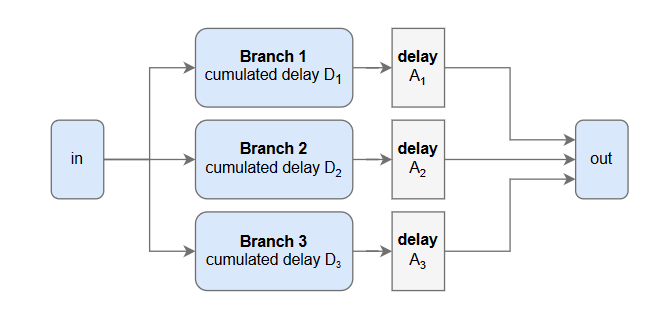
RAVEの実装にはResidual構造の実装例が書かれています。改造版Convolution層でできたmodule(累計ディレイ=module.cumulative_delay)と、スキップコネクションであるnn.Identity()(累計ディレイ=0)を合体させています。
class Residual(nn.Module):
def __init__(self, module, cumulative_delay=0):
super().__init__()
additional_delay = module.cumulative_delay
self.aligned = cc.AlignBranches(
module,
nn.Identity(),
delays=[additional_delay, 0],
)
self.cumulative_delay = additional_delay + cumulative_delay
def forward(self, x):
x_net, x_res = self.aligned(x)
return x_net + x_res