前回に引き続き、ISMIR2024論文をピックアップします。
今回は「エフェクトスタイル転移」 に関するものです。
Diff-MST: Differentiable Mixing Style Transfer
DDSP(Differentiable Digital Signal Processing)の力で賢いミキシングコンソールを作る研究です。
ある楽曲のステムデータが与えられたとき、指定した「リファレンス音源」とミックスバランスが一致するよう、各トラックのエフェクトパラメーターを自動的に推定し、適切なミックスを出力する「ミックススタイル転移」を実現することが目標です。
DDSPの基本的な考え方は、微分可能(=損失の逆伝播可能)な信号処理アルゴリズムを利用し、信号処理パラメーター(EQの増益やカットオフ周波数、コンプの閾値や圧縮値、リバーブの長さなど)を推定するDNNをEnd-to-endに学習させることです。本研究の著者らは既に、DDSPを使った音声のスタイル転移の手法を発表しているので、今回はその手法をミキシングコンソールに発展させた形です。
微分可能なミキシングコンソール
Diff-MSTも標準的なDDSPの枠組み通り、微分可能なDSP処理と、パラメーター推定DNNからなるシステムです。
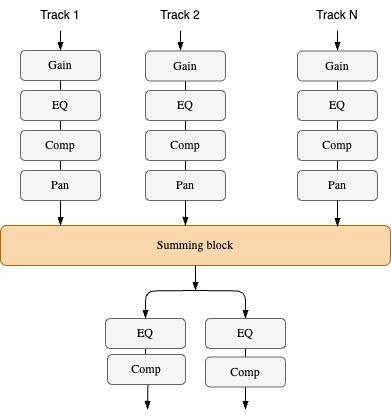
上の図のように、ミキシングコンソールは、ゲイン・イコライザ・コンプ・パンの組み合わせで構成されます。それぞれの処理は微分可能なので、End-to-endな学習に組み込むことができます。
パラメーター推定
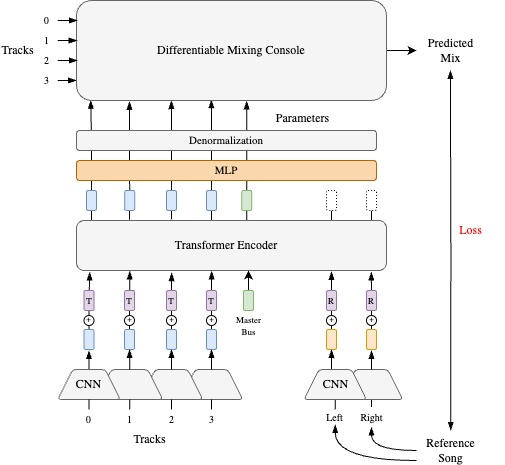
各エフェクトのパラメーター推定の流れは以下の通りです。
- ミックス対象のステム音源(モノ)と、リファレンス音源(ステレオ)の振幅スペクトログラムをCNNエンコーダーに入力し、各トラックごとの特徴量を抽出する。ここではステム音源とミックス音源に対して別々のCNNエンコーダーが使われています
- ステムとリファレンスの特徴量に、それぞれ学習可能な埋め込みベクトルを加算し(上の図の$\mathbf{T}$と$\mathbf{R}$のブロック)、加算された埋め込みベクトルを連結する
- 連結されたベクトル列の後に、更に学習可能なベクトルを連結する。マスターバスのエフェクトを制御する埋め込みベクトルらしいです(図には描かれていませんが、ソースコードを見ると更に「FXバス」のベクトルが連結されています)
- 連結されたベクトル列をTransformerエンコーダーに入力する。Transformerの出力はMLPを経て、ミキシングコンソールの各エフェクトのパラメーターになる
- ステム音源をミキシングコンソールに入力し、ミックス結果を出力する
学習手法
エフェクトパラメーター推定モデルは、MedleyDBなどの楽曲ステムデータセットから、自己教師あり学習的な手法で学習されます。
各学習イテレーションでは、以下の手順で目標関数を計算します。
- ランダムなエフェクトパラメーターをサンプルする
- ステム音源にエフェクトを通してミックス音源を作り、これを「リファレンスミックス音源」と見なす
- ステム音源とリファレンス音源をエフェクトパラメーター推定モデルに入力し、パラメーターを推定する
- ステム音源に推定されたエフェクトを通してミックス音源を作り、これを「推定ミックス音源」と見なす
- 推定・リファレンス音源の差分を損失とする
損失を最小化すれば、エフェクトパラメーターを正しく推定する推定モデルが学習されます。
損失の計算方法は以下の3通りを挙げています。
- Audio Feature (AF) loss:RMS、crest factor(CF)、stereo width(SW)、stereo imbalance(SI)、bark spectrum(BS)などの音響特徴量の差分を足し合わせる。波形レベルの近さよりも、聴感的な近さに主眼を置いた損失関数です
- MRSTFT loss:異なる解像度(Multi-Resolution)のSTFTの差分を足し合わせる。聴感だけでなく、音の内容も一致することが求められる損失関数です
- MRSTFT+AF:上の二つを足し合わせる
評価実験
評価実験では、テストデータでパラメーター推定を行わせ、リファレンス・推定音源の音響特徴量(RMS, CF, SW, SI, BS)の差を測ることで、ミックススタイル転移の性能を測っています。
ベースライン手法として、Equal Loudness(リファレンス音源とラウドネスが等しくなるように調整するだけ)と、既存手法であるMST (J. Koo et al.)、更にプロエンジニアによるミックスも評価されました。
結果を見ると提案手法は多くの指標でベースラインを上回っており、プロのミックスに匹敵する数値を示していました。また、MRSTFTよりもAF損失で学習させたほうが全体的に良かったみたいです。
ST-ITO: Controlling audio effects for style transfer with inference-time optimization
推論時最適化によるオーディオスタイル転移手法。 上のDiff-MSTと同じくQMULのメンバーによる研究で、ISMIR2024のBest paperに選ばれました。
既存のオーディオスタイル転移手法(Diff-MSTも含む)は、自己教師あり学習したニューラルネットを使い、入力特徴量からエフェクトパラメーターを推定させることによって、「賢いエフェクト」を実現していました。この手法は「エフェクトはすべて微分可能処理」「エフェクトの繋ぎは固定」であることを前提に成立するので、実用面では若干柔軟さに欠きます。
本研究は、「推論時最適化(ITO=Inference Time Optimization)」によってエフェクトパラメーターを推定する、より柔軟なスタイル転移手法を提案しました。
入力音源とリファレンス音源がある時、推定は以下のような手順で行われます。
- エフェクトパラメーターをランダムに初期化し、入力音源をエフェクトに通す
- 処理後の音とリファレンス音源を、事前学習されたDNN特徴抽出器に入力し、音響特徴量を得る
- 音響特徴量のコサイン類似度を測る
- Covariance Matrix Adaptation Evolution Strategy (CMA-ES) という、勾配不要な最適化アルゴリズムで、コサイン類似度を最大化するようにエフェクトパラメーターを更新する
- 1~4を良いところまで繰り返す
その名の通り、推論時に最適化ループが回っていますね。
CMA-ESのような「ブラックボックス最適化」アルゴリズムで最適化できるため、既存のDDSP系な手法に比べて、「エフェクトの種類を問わない(微分不可・未知なエフェクトでもOK)、繋ぎ方も自由」という柔軟さを得ることができました。
特徴抽出器の事前学習
上述のようなシステムで使う特徴抽出器には「音源にかかったエフェクトの類似度をコサイン類似度で測れる」ようなベクトルを吐いて欲しいです。単純な尺度で測ることができれば、CMA-ESのような最適化アルゴリズムによるエフェクトパラメータ推定が可能になります。
この特徴抽出器を鍛えるために、音楽波形データのデータセットだけでなく、異なるエフェクトチェイン、および各エフェクトチェインのプリセットを沢山用意します。事前学習フェーズでは、波形、エフェクトチェイン、プリセットの中からランダムにサンプルし、特徴抽出器の損失関数を求めます。
損失関数は以下の手順で計算されます。
- エフェクトに通す前・通した後の波形データをそれぞれ特徴抽出器に入力し、2つの特徴ベクトルを得る
- 2つの特徴ベクトルを連結し、MLPに入力する。MLPは「どのエフェクトチェインが使われたか」を予測する分布を出力する
- 特徴ベクトルとエフェクトの予測分布を、更に別のMLPに入力する。今度のMLPは「どのプリセットが選ばれたか」を予測する分布を出力する
- エフェクトチェインとプリセットの予測誤差(多クラス分類の交差エントロピー損失)が損失関数になる
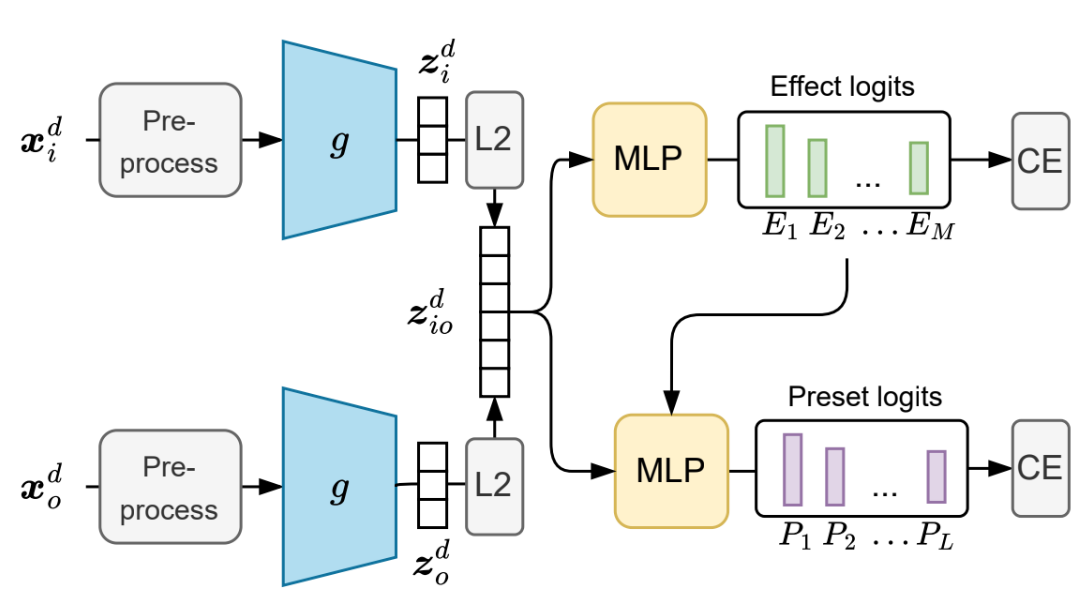
このような損失関数により、音にかかったエフェクトのタイプだけでなく、エフェクトパラメーターのニュアンスにも敏感な特徴抽出DNNが鍛えられる、という理屈です。
「結局コサイン類似度どこいった?」という疑問も浮かぶかもしれません。著者によると、対照学習のように「コサイン類似度で測れる」のが理屈上保障されているわけではないのですが、ちゃんと機能しているのでそうしているとのことでした。
評価実験
実験では、音楽・音声・歌声を問わずありとあらゆる音のデータセットと、63個のオープンソース、あるいは無料のVSTプラグインエフェクトを集めました。各エフェクトごとに、1000個のプリセットがランダムに生成されています。これらを使って特徴抽出器の事前学習が行われました。
エフェクトの適用には、Spotify社が開発したpedalboardというライブラリが使われています。
論文では複数の尺度でこの手法の能力を評価しました。各評価尺度ごとに、異なるベースラインを使っています。
ゼロショットスタイル分類精度:特徴抽出器の出力がミックススタイルの違いを良く表せているか測ります。やり方は、
- 音源データセットからランダムで5個のサンプルを選び、異なるエフェクトを加える
- 更にランダムで5個のサンプルを選び、↑と同じエフェクトを加える
- 特徴抽出器を使い、エフェクトを加えたサンプルを特徴ベクトルに変換する
- 特徴ベクトル同士のコサイン類似度を測り、「同じエフェクトが加えられたペア」を当てる
上の手順を200回繰り返し、正解率を評価尺度とします。結果、提案法の特徴抽出器はベースライン(CLAP、Wav2Vec2、DeepAFX-STなど)に比べて全面的に高い精度で分類できたようです。
パラメーター推定精度。未知のエフェクトパラメーターを正確に推定できているか測ります。EQやコーラス・ディレイ・リバーブ・ディストーションなど様々な種類のエフェクトでパラメーター推定を行い、MSEと相関係数を評価尺度としました。こちらもベースライン(CLAP)と比べて、事前学習に使ったエフェクトに対しても、使ってない(未知の)エフェクトに対しても全面的に推定精度が高かったようです。
リスニングテスト:ミックススタイル転移が上手くできているか、主観評価で測ります。ベースライン手法(ルールベースのフィルタリング処理と、先行研究であるDDSPベースのDeepAFx-ST)は、音源のタイプやエフェクトの種類によって評価が高かったり、極端に低くなったりしましたが、ST-ITOはどの条件下でもそこそこ良い評価を得ており、高い柔軟性を示しました。
これらの実験結果から、ST-ITOは確かに色んなエフェクトに対して高い対応力を持つスタイル転移手法であることが分かります。
この手法は、Diff-MSTで扱ったようなミキシングコンソールにもそのまま適用可能ですが、流石にそこまで大規模なエフェクトチェインだとCMA-ESの手には余るようです。そこを解決する最適化アルゴリズムが見つかれば更に柔軟性が高まるでしょう。