去年開催された26th International Conference on Digital Audio Effects (DAFx2023) に単著論文を投稿し、採択されました。
今更ですがそこで発表した研究を紹介します。
どんな手法?
去年、海外のオーディオ技術コミュニティThe Audio Programmerが主催したNeural Audio Plugin Competitionにて、筆者が開発し「HARD」と名付けたオーディオプラグインが3rd Prizeに選ばれました。どんなエフェクトかは動画をご覧ください。
本論文はこのエフェクトを実現するための手法です。
背景:生成モデルのDisentanglement問題
Disentanglementとは、直訳すると「もつれを解く」という意味ですが、機械学習の文脈における一般的な日本語訳は不明です。
(中国語では「解耦」と訳されることがありますが、プログラミングにおいてモジュールの結合度を下げる「デカップリング」の中国語も「解耦」が当てられています)
昨今広がりを見せているの深層学習ベースの生成モデルは、何らかの「潜在変数 (latent variables)」を入力し、画像や音などのデータを出力するという形式になっています。入力する潜在変数を変化させることで、生成されるデータを制御することができます。
しかしDNNはブラックボックスなので、生成結果に意図した変化を起こすのは容易ではありません。潜在変数ベクトルの数値を一ついじるだけで生成データ全体に影響し、何から何まで全く違うものを出力してしまう可能性もあります。
この状態を、潜在変数の次元がEntangledである、と言います。低品質なスパゲッティコードの如く、ちょっとした変化が全体の挙動を影響してしまう状態になっており、手の付けようがありません。
できれば、潜在変数の各次元は、それぞれ生成結果の「いち要素」だけに影響を与えるようにさせたい。そうすれば、生成モデルはより使いやすくなるはずです。
このように、潜在変数各次元の生成データへの影響を分離させる様々な工夫をDisentanglement手法と言います。生成モデルの実用性に関わる、とても重要なテーマです。
提案手法:移調に対する同変性・不変性を利用した潜在特徴分離
本論文で提案した手法は、音楽音響信号の「ハーモニー要素」と「リズム要素」をDisentangleすることを目標とします。音楽の「ハーモニー要素」と「リズム要素」を別々に制御できるようにすれば、上に紹介したHARDプラグインのように、2つの曲の異なる要素を組み合わせるエフェクトが作れるようになります。
「ハーモニー・リズム要素」と言うと抽象的すぎるかもしれません。この2要素の性質を以下のように定義してみましょう。
- ハーモニー:移調した幅と同じくらい変化する
- リズム:移調した幅に関わらず一定である
この2つの性質を、移調に対する「同変性(equivariance)」および「不変性(invariance)」といいます。このような性質を持っていることによりハーモニー・リズム要素を潜在空間上で分離することが可能になります。
やり方を説明します。まず、二つの潜在特徴量を持つVAEを作ります。
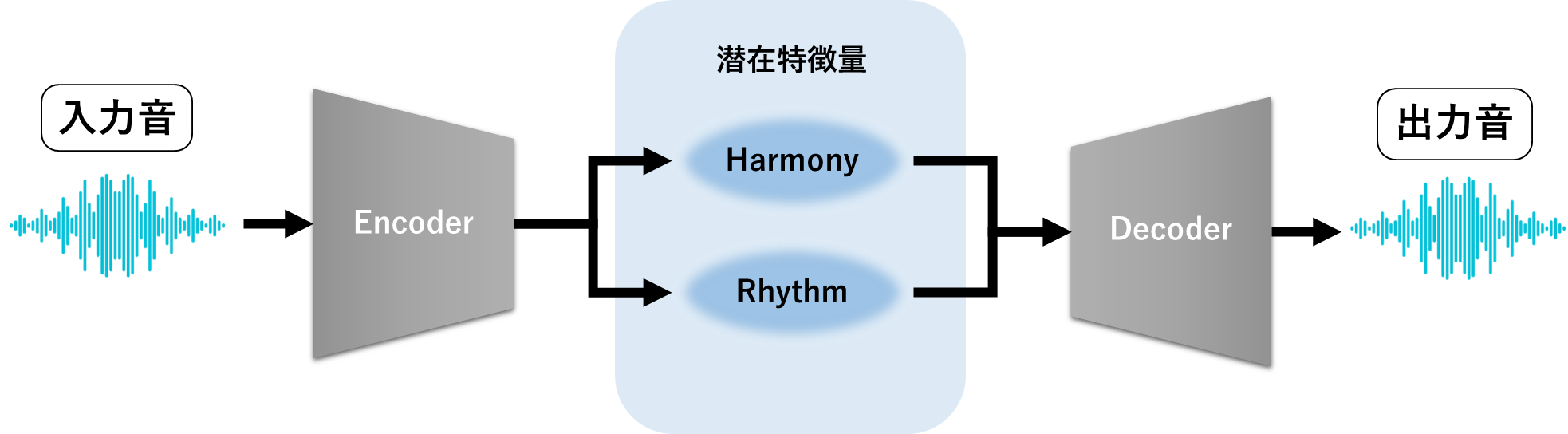
実際のVAE入力・出力はメルスペクトログラムです。
普通のVAEは、入・出力の値の距離を最小化、潜在特徴量の分布と事前分布のKL距離を最小化するようにエンコーダー・デコーダーを最適化していきます。
提案手法もほぼ同じことをしていますが、学習過程でとあるトリックを導入します。それは、VAEが「『未知の音程ぶん』移調された音のスペクトログラムを入力し、移調前のスペクトログラムを出力する」ように学習させるのです。
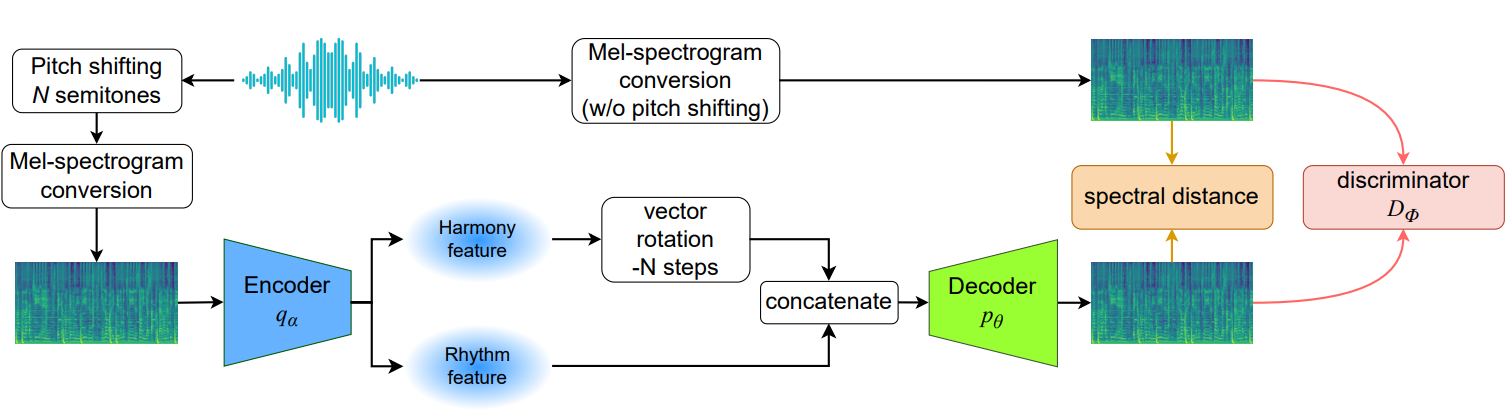
移調の幅が未知(ランダムな半音数でピッチシフトしているため)ので、このままではオートエンコーダーは入力を正しく再構築できません。そこで、ハーモニー要素をあらわす特徴ベクトルを移調した半音数ぶんシフトさせます。
たとえば、入力が原音から2半音下に移調されたものであれば、ハーモニー特徴ベクトルは全体的に2ステップぶんシフトさせます(移調との同変性が保たれればシフトの方向は関係なし)。一方リズム特徴のほうは何も処理せずデコーダーに入力されます。
つまり、ハーモニー特徴は移調に対して同変、リズム特徴は移調に対して不変になるよう振舞わせながら、VAEの学習を回すのです。学習が収束すると、二つの特徴ベクトルはそれぞれ独立した要素の情報をあらわすようになっているはず。
音楽音響データのみを用いる、自己教師あり学習にあたる手法と言えるでしょう。損失関数は以下の要素から構成されます。
- 再構成項:Decoderの出力と、移調前のスペクトログラムとの距離
- 正則化項:ハーモニー・リズム特徴それぞれの推定分布(Encoderの出力)と事前分布のKL距離
- 敵対的学習項:生成品質を高めるため、DecoderをGANと見なして敵対的学習も行う
以上3項を最適化することで、ハーモニー・リズム要素に分離された潜在特徴を持つVAEを得ることができます。
評価実験
実験では、とりあえずFMA(Free Music Archive)Datasetという大規模音楽コーパスを与えて自己教師あり学習を回してみました。
実際にハーモニー・リズム情報が分離されているか確かめるため、2つの特徴量上でコード認識とオンセット認識を行うアルゴリズムを走らせ、認識精度を測りました。参考指標として、音響信号のメルスペクトログラム上でも同じ精度を測りました。
具体的な測り方の説明は論文に委ねるとして、結果は下の表のとおりです。
| 特徴量 | コード認識精度 | オンセット認識精度 |
|---|---|---|
| ハーモニー特徴 | 69.61% | 60.09% |
| リズム特徴 | 24.65% | 66.04 |
| メルスペクトログラム | 51.95% | 65.19% |
リズム特徴はコード認識が全くできていません。つまりリズム特徴はハーモニーに関する情報をほぼ含んでいないことがわかります。
ハーモニー特徴のオンセット認識精度はリズム特徴より低いですが、そんなに悪くありません。ピッチ情報の変化でオンセットの位置が分かってしまうからでしょう。コード認識精度のように、もっと違いの出る指標があればいいのですが、論文執筆時点では思いつきませんでした。
ただ実際にHARDプラグインを使ってみて貰えれば、ハーモニー・リズム情報がきちんと分離できていることが分かると思うので、上の実験結果と合わせてこの手法はDisentangle出来てるね、と結論付けても差し支えないでしょう。
MIR用の事前学習手法としての可能性
ハーモニー特徴もリズム特徴も、それぞれ得意なタスクでメルスペクトログラム上の精度を上回ったのは示唆的じゃないかなと思います。
提案手法で得られる特徴量は音楽音響信号に含まれるハーモニー・リズム情報が強調されたものなので、メルスペクトログラムのような汎用的な音響特徴量よりもMIRタスクで良いパフォーマンスを見せると考えられます。
上の実験結果によって、実際にその仮説をある程度確かめることができました。
近年、MIRタスクの精度を向上させるためのアプローチとして、MERTのような事前学習モデルが提案されています。今回提案したDisentangle手法も、事前学習モデルの性能を上げるのに役立つかもしれません。そこをそのうち確かめてみたいです。