音楽情報処理に関する国際学術会議ISMIR2024に参加するため、サンフランシスコに来ております。
正式な論文は出していませんが、手ぶらで行くのも何なので、Late Breaking Demosセッション(未完成のアイデアを紹介する、閉会直前のゆるいセッション)でちょっとした小ネタを披露する予定です。
タイトルは「A DBN-Based Regularization Approach for Training Postprocessing-free Joint Beat and Downbeat Estimator」。以下のリンクから原稿・ポスター・紹介動画が見れます。
共著は山本さん(AlphaTheta)と石川さん(電気通信大学)です。
本記事はこのネタの背景や知見を軽く紹介したいと思います。まだ理論も実験も未熟な小ネタなので、疑問・指摘・提案をぶつけるつもりで読んでいただけると幸いです。
背景
タイトルの通り、取り扱う問題は音楽のビート・ダウンビート自動推定です。
標準的な手法
DNNベースのビート・ダウンビート推定は、以下のような手順で行うのが標準的とされています。

(ISMIR2021チュートリアル「Tempo, Beat, and Downbeat Estimation」より)
- 音響信号の特徴量(Feature extraction)をDNNに入力し、フレームごとの「確率値(このフレームがビート/ダウンビート位置である確率)」を求める(Likelihood estimation)
- 確率値の系列に対して後処理を行い(Post-processing)、ビート・ダウンビート位置を決定する
DNNは、特徴量系列とビート位置ラベルのペアデータを使い、(ダウン)ビート位置でのみ数値が高い確率値系列を出力するよう、教師あり学習されたものです。
音楽のビート・ダウンビートは通常、一定の法則(それぞれ等間隔である、ダウンビート位置はビート位置と重なる、など)に従います。しかし、DNNが出力する確率値系列(下図の青線)は総じてノイジーである上、音楽的な法則に従うことも保証しません。推定した確率値からピーク検出だけで正しい結果が得られるのは稀です。
要は、ビート・ダウンビート位置の事例を沢山学習させても、その背後にある法則をDNN様はあんまり覚えてくれないんです。なので、DNN様の答えをなるべく尊重しつつも、我々の常識に従ってビート・ダウンビート位置を事後的に決めるしかありません。これが「後処理(Post-processing)」の役目です。
よく使われる後処理手法の一つが「Dynamic Bayesian Network(DBN)」を用いた後処理。Networkと言ってもDNN系ではなく、各フレームのビート・ダウンビート位相を隠れ状態で表す隠れマルコフモデルです。ビート・ダウンビートの法則は隠れ状態間の遷移確率に反映されており、DNNが出力した確率値をDBN隠れ状態の観測確率と見なせば、Viterbi探索で最適な(=対数尤度が最大になる)状態遷移系列を求めることができ、それによってビート・ダウンビート位置が決定されます。
ここらへんの話は、こちらの記事で解説しています。
「後処理不要」な賢いDNN
そうは言っても、最近は賢いDNNがどんどん発明されてるし、「そろそろ後処理不要な賢いDNNも作れるんじゃない?」と考えるのは自然でしょう。いわゆる「Postprocessing-free」なビート・ダウンビート推定に挑んだ研究は以下の2つが挙げられます。
後者は出来たてホヤホヤ、ISMIR2024掲載論文ですね。いずれの手法も従来の教師あり学習の枠組みのもと、損失関数やDNN構造を色々工夫することで性能を上げるアプローチをとっており、実際にDNN出力からのピーク検出だけで高いビート・ダウンビート推定精度を達成しています。
彼らの素晴らしい頑張りのおかげで、「後処理不要な賢いDNNは作れる!」のは分かりました。ただ少々厳しめに見ると、十分賢くなるまでは結局ラベル付きデータで殴り続けなければならず、決して複雑ではない拍・小節の法則を憶えさせるにしては、あまり効率の良いやり方とは思えません。
大量の事例を見て空気を読んでもらうのではなく、直接ビート・ダウンビートの法則をDNNに「教え込む」ことはできないでしょうか?
解決策
「後処理不要」とはどういうことか、確率の言語で定式化してみましょう。ここでは、DBNによる後処理を念頭に置いています。
音響特徴量を$\mathbf{X}$、ビート・ダウンビートラベル系列を$\mathbf{S}$、DNNが推定したビート・ダウンビート確率の分布を$P(\mathbf{S}|\mathbf{X})$とします。さらに、推定ビート・ダウンビート確率を隠れ状態の観測確率と見なしたDBNの分布を$\hat{P}(\mathbf{S}|\mathbf{X})$とします。
いかなる$\mathbf{X}$でも、分布$P(\mathbf{S}|\mathbf{X})$と$\hat{P}(\mathbf{S}|\mathbf{X})$が等しければ、当然「後処理不要」になるでしょう。そうでなくても、分布同士が近ければ近いほど、「後処理不要」であるチャンスは多くなるはずです。
分布を近付けると言ったら色んな尺度がありますが、ここでは交差エントロピーを基準にします。
\mathbb{E}_{P(\mathbf{S}|\mathbf{X})}\left[-\log\hat{P}(\mathbf{S}|\mathbf{X})\right]
交差エントロピー最小化は、言い換えれば対数尤度の(期待値の)最大化です。前述のように、そもそも後処理とはDBNの対数尤度が最大になる状態列を求める処理です。DNNの出力分布に従うビート列が、既に$\hat{P}$に対する尤度も高ければ、後処理は不要になるでしょう。その意味でも、交差エントロピー最小化は確かに「後処理不要」の目標に一致すると解釈できると思います。
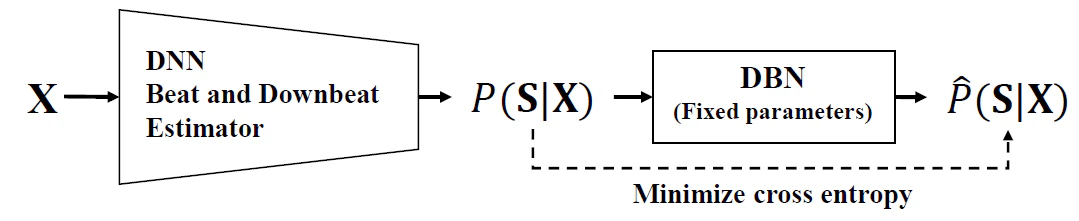
分布を近付けると言えば、交差エントロピーから$P(\mathbf{S}|\mathbf{X})$のエントロピーを引いたKL Divergenceの最小化も考えられますが、$P(\mathbf{S}|\mathbf{X})$のエントロピーを最大化する意味がないので却下しました。
というわけで、この交差エントロピーを最小化(対数尤度最大化)させるための損失関数を考えてみます。
提案手法
先ほどの対数尤度は普通に計算できるので、これを直接損失関数にして逆伝播すれば良いように見えますが…DBNの尤度計算には前向き・後ろ向きアルゴリズムという再帰的な計算が含まれるので、逆伝播で勾配を求めるのは流石に辛いです。
DBN (HMM) は普通、EM法でパラメーター推定をします。今回のパラメーター推定対象はDNNですが、「DBNに対する尤度を最大化する」という目標は同じなので、EM法は参考になるかもしれません。
ということで、以下のように損失関数を計算します(教師ありor教師なし、どちらの場合でも計算できます)。
- DNNが推定したビート・ダウンビート確率を、DBN隠れ状態の観測確率に変換
- 教師ありの場合、ラベルをDBN隠れ状態の観測確率に変換し、ステップ1の確率に乗算する
- 観測確率&状態遷移確率&ラベルから、前向き・後ろ向きアルゴリズムを使い隠れ状態の対数尤度を求める
- 各フレームごとに隠れ状態の対数尤度をsoftmax関数で正規化
- 正規化された対数尤度を重みとし、隠れ状態観測確率の重み付き和を求める
前向き・後ろ向きアルゴリズムや、対数尤度の正規化は計算グラフから外し、勾配計算には関わりません。
直観的には、前向き・後ろ向きアルゴリズムで対数尤度を求めた後(Eステップ)、尤度が高い隠れ状態により高い観測確率が付与されるようにDNNを更新させる(M?ステップ)という仕組みです。ステップ3のsoftmax正規化された対数尤度は、まさに「どの状態の観測確率を上げるか」を制御するための係数です(確率分布を表しているわけではありません)。
この損失関数で更新を繰り返すことで、DBNの尤度も最大化されます。
検証実験
初歩的な検証として、ランダムに初期化した系列を上述のDBN損失関数で最適化する実験を行いました。
こちらのGoogle Colabに実験結果を掲載しています。
ランダム値で初期化した$2\times N$サイズの行列を用意し、ビート・ダウンビート確率系列と見なします。さらに、疑似的に生成した$2\times N$サイズのラベル系列もいくつか用意しました。そして確率系列とラベル系列から損失値を計算し、勾配降下法で確率系列を更新していく、それだけです。
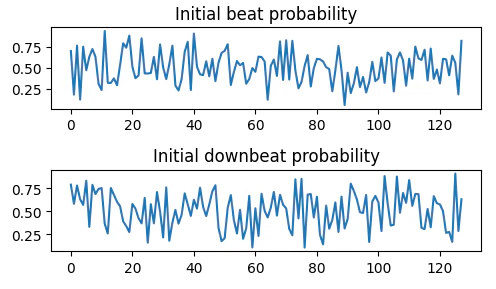
(ランダムに初期化した確率系列)
この確率系列が期待通りの形に収束したならば、この損失関数はDNNの学習に使うときも「望ましい方向に作用してくれる」と期待できます。
実験結果を見てみましょう。
まずは教師なし条件下の最適化。ランダム行列をDBN損失関数で最適化すると、ラベルを与えていないにもかかわらず、下の図のような周期的な、且つ拍と小節の法則に従うような系列になりました。
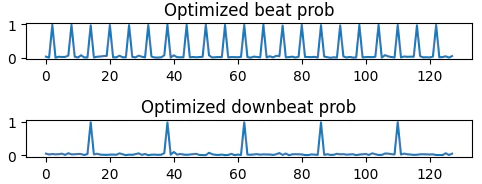
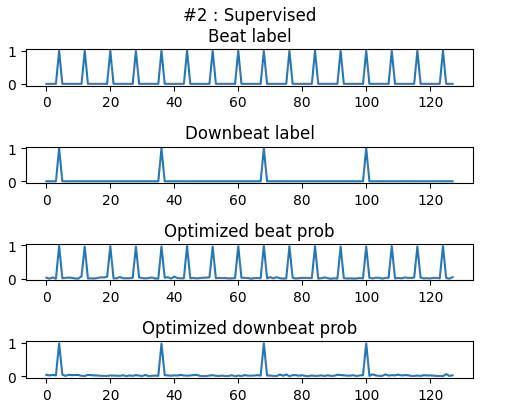
ビート・ダウンビートのラベルを与え、教師あり条件で最適化すると、ちゃんとラベル通りの系列に収束しました。
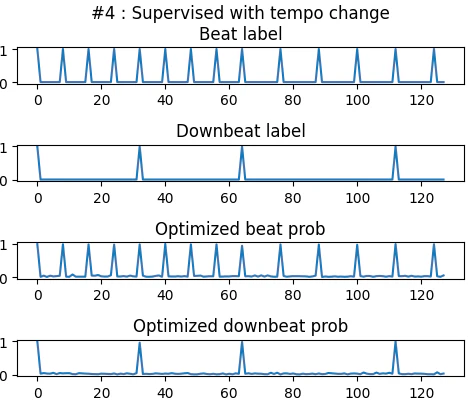
途中でテンポ変動が起きても問題ありません。
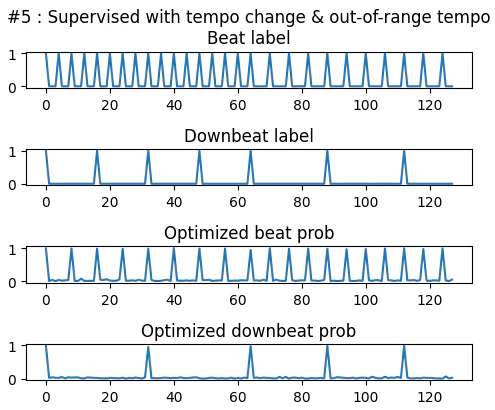
DBNが想定するテンポの範囲を超えるようなラベルを与えると、DBNのテンポ範囲内に収まるようなビート・ダウンビート系列に収束しました。
メチャクチャなラベルを与えても、ラベルに近い、且つ正常なビート系列に収束しました。
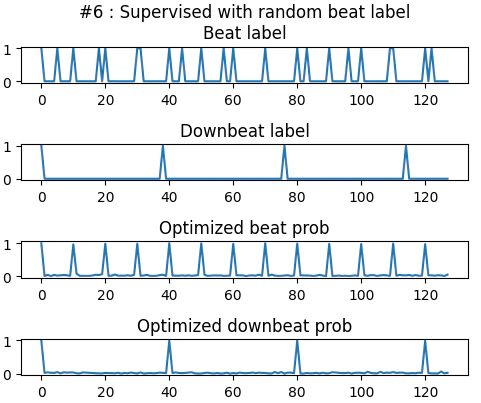
これらの実験結果から、このDBN損失関数は与えられた確率系列に対し「拍・小節の法則に従うことを促す」力が働いていることが分かります。
ビート・ダウンビート推定実験
実際にビート・ダウンビート推定DNNを鍛える際、提案した損失関数の使い方は、以下の3通りが考えられます。
- 教師あり条件のDBN損失関数を最適化する(S-DBN)。ラベルの$\hat{P}$に対する対数尤度を最大化する、直接的な使い方です
- 教師なし条件のDBN損失関数を、従来の教師あり損失関数と組み合わせる(BCE & U-DBN)。ラベルはあくまで$P$に対する対数尤度の最大化に使い、DBN損失は正則化損失みたいな役割を担います
- 教師あり条件のDBN損失関数を、従来の教師あり損失関数と組み合わせる(BCE & S-DBN)。教師あり損失を2重に計算してるようにも見えますが、異なる基準による最適化の組み合わせになります
従来の教師あり損失関数は、DNN出力確率のラベルに対する二値交差エントロピー(Binary Cross Entropy, BCE)です。既存手法ではlabel wideningなど学習をし易くするための色んなテクニックが存在しますが、そういう工夫はしていません。
評価実験では、同じDNNと訓練データセットに対し、異なる損失関数で最適化し、評価セット上のビート・ダウンビート推定精度を測りました。いずれの条件下でも推定に後処理を用いず、DNNが出力した確率列からのピーク検出で直接ビート・ダウンビート位置を決定しました。
今回のLBD発表では、1と3の結果をまとめ、ベースライン(BCEのみで学習)と比較しました(2はまだちょっと上手くいってません)。
実験結果は以下の表の通りです。

指標の詳しい定義はここでは省きますが、ベースラインと比べてダウンビートの正解率が大きくに向上しているのが分かると思います。F1指標に関しては、従来法に後処理を加えた結果(BCE w/DBN-PP)をも上回りました。
一方ビート推定に関してはベースラインとあまり差が無かったり、逆にスコアを落としたりもしましたが、全体的に見てS-DBN損失の効果は示せていると思います。
ビフォーアフター
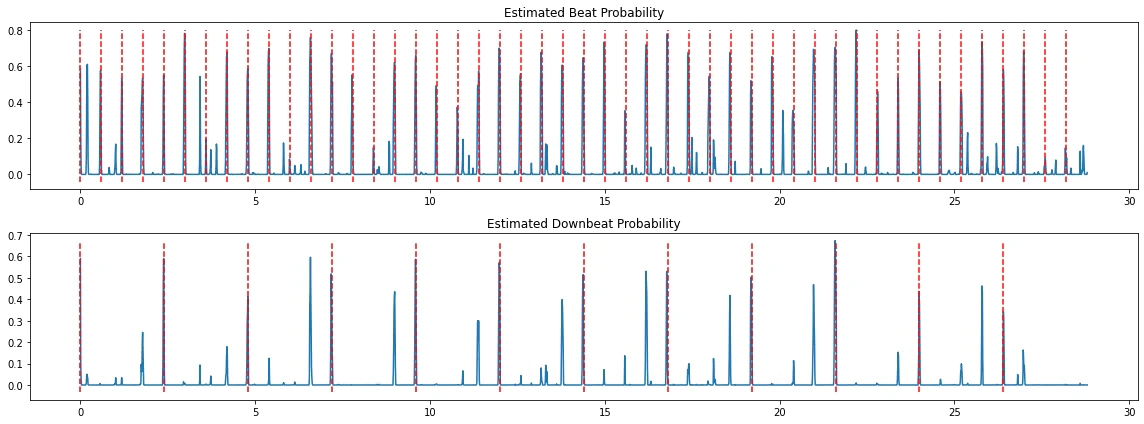
提案法と従来法で学習したDNNが出力した、推定ビート・ダウンビート確率の例です。
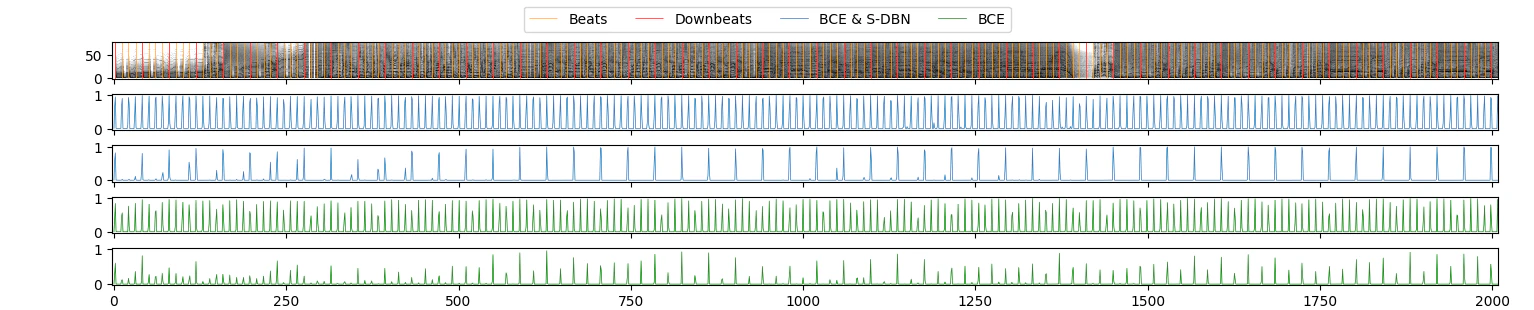
緑色の線(従来法)は、特にダウンビートに関しては、後処理無しでは正しい位置が分かりにくい形になっています。単純なピーク検出では多くのビート・ダウンビート位置を見落としてしまいます。
一方青い線(提案法)のほうはビート・ダウンビート確率のピークが綺麗に立っており、ピーク検出だけでほぼ全てのビート・ダウンビート位置を拾えそうです。さっきの実験でダウンビート推定の精度が大きく向上したのも、このおかげでしょう。
まとめ
本提案手法は「後処理不要」とは即ち「後処理前・後の分布が近い」状態であると定義し、交差エントロピー最小化を目標としたEMライクな学習メカニズムによって問題解決を試みました。定式化がされてる分、既存研究より少なくとも理屈は通るアプローチではないかと思います。
直感的には、「DBNを損失関数に変身させることで、音楽的法則をDNNに直接教え込む」手法とも言えるでしょう。そういう意味も込めて原稿では「正則化(regularization)」という言葉を使っています。ビート・ダウンビート推定に限らず、「DNN-DBN(あるいはDNN-HMM)」の枠組みが使われているタスク(コード進行推定とか)ならだいたい適用できるのではないでしょうか。
まだ思い付きレベルのアイデアですが、いまのところ期待通りの効果を示しているので、今後は様々なタイプのDNNモデルで試したり、ちゃんと既存手法と厳密な比較を行い、正式な論文にまとめ上げたいです。
DBN損失は筆者が作りましたが、実験は山本さんが全部やってくれました。石川さんにも原稿チェックや図表設計を手伝って頂きました。ありがとうございます。