コード進行自動認識技術においては、認識するコードラベルの種類をメジャートライアド+マイナートライアド+No Chordの計25種類に限定するのが一つの基準とされてきました。前の記事では、ビートルズ楽曲においてこの基準で正答率約82%を記録することができました。
この基準でもまだまだ伸びしろがありそうですが、コード認識のもう一つの課題はさらに複雑なコードです。トライアドはコード体系の基本中の基本ですが、その他に7th、dim、susやaugみたいなタイプがあり、分数コード(転置など)もあります。それらを全て別クラスとみなすとクラス数は数百に膨れ上がるので、トライアドと混同せずに正確に識別するのも耳コピの一大チャレンジです。
何が問題なのか
24種のトライアドは、数も少ないしお互い全く独立したクラスとみなしても大丈夫でした。しかし種類が増えるとかならずしもそうとは限りません。例えばC7,Cmaj7,C6などは、Cの構成音を含んでおり、一定のヒエラルキーが存在すると言えます。これらのクラスを単純に数百クラスの多クラス分類問題として解かせる(NNの出力層ユニット数を数百にするなど)と問題が生じます。
1.全ての間違いに課せられるコストが同一。例えばCをDmに間違えるようなエラーと、Cmaj7に間違えるエラーが、同程度の損失として計上されるので学習がうまくいかない。
2.トライアドがそれ以外のタイプに比べ圧倒的に多く(トライアドが八割以上を占める)、訓練データの偏りが大きすぎる。
この問題は、DeepLearningが流行る以前から、Chroma+HMMの枠組みの中で検討されてきました。VAMPプラグインのChordinoもそうです。しかしDeepLearningの枠組みの中では課題は認識されていながら解決策を提示した研究はほぼありませんでした。
ところでこの前GitHubでふと検索をかけてみたところ、音楽情報処理ライブラリlibrosaの中の人B.McFeeとJ.Bello先生が今年のISMIRに提出したコード認識論文とそのソースコードを公開してたことを発見。まさにDeepLearningの枠組みでこの課題に対処し、そこそこ成果を出せたようです。どんなものなのか見てみましょう。
論文読み
タイトル:Structured Training for Large-Vocabulary Chord Recognition
畳み込みNNを作ってパラメーターを学習させるという大枠は従来と変わらないようですが、NNの出口を工夫するというのが主な考えの模様。
Encoder-decoder model
このNNの構造は論文ではEncoder-decoder modelと呼んでいます。NNは2パートでできていて、Encoderはスペクトラムを特徴量空間に変換して、decoderが特徴量を出力ラベル空間に変換するという。論文では機械翻訳とかに出てくるあのEncoder-decoder modelがベースになっていると言ってますが、ちょっと違うような。
それはともかく、Encoderは2層の畳み込みと1層の双方向GRUを通して、スペクトラム系列を特徴量系列に変換。特徴量のベクトルサイズは変わりますが、系列の長さTは変わらず。
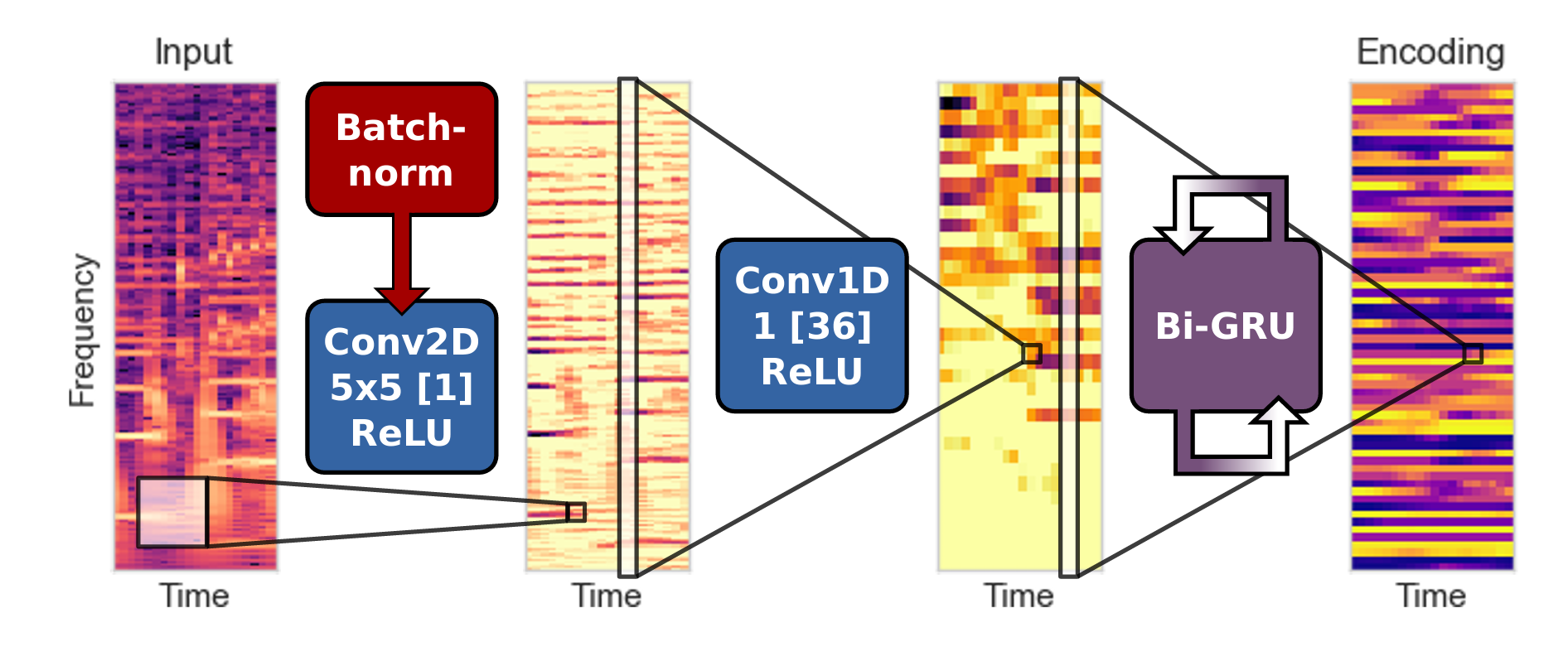
Decoderは、論文では2パターン用意されてました。一つは全連結を通してからSoftmaxをかけて出力するいつものやつ。もう一つは双方向GRUを通して出力に変換するもの。Encoderで得た特徴ベクトルを各箇独立で変換するか、前後文の影響を導入するかの違い。
ターゲットの表示
タイトルにある通りStructured Trainingと呼ばれる部分がここ。コード記号を(ルート、構成音、ベース)の要素に分けて、NNでそれぞれを予測させるというやり方です。特徴量から、コードの三要素を「デコード」させるという事ですね。このような「構造化した」形式を用いることで、エラーに課せられるコストをより合理的にすることができます。データの偏りによる影響もある程度解消されるでしょう。
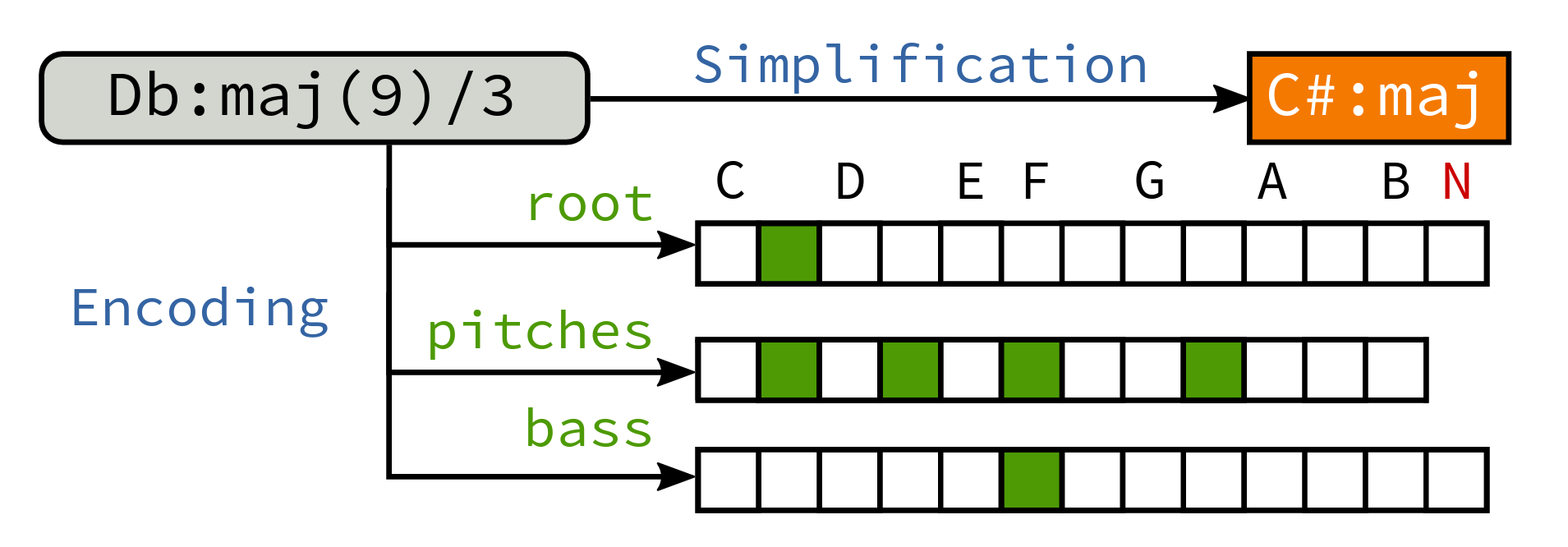
音高クラスを予測させる部分(pitchesの部分)は、ベクトルの複数の値が1になるので、softmaxの代わりにsigmoid関数を通します。
学習の際は、教師データのコードラベルを図のような三つのスパース表示に変換してNNの出力と照らし合わせます。ラベルからスパース表示への変換はmir_evalというライブラリで簡単に行うことができます。
コードタイプの判別
実際にコードを認識してもらう段階では、学習が済んだモデルで三要素を予測してもらったあと、それをコード記号に変換します。変換できない場合は未知のコードということで「X」を出力します。ソースコードでは、pumppという、これまたbmcfee氏が作ったらしきライブラリにやってもらってるようです。
訓練データ
従来の訓練データを使います。1217曲あるようです。訓練データ偏りの問題は克服したのですが、セブンスのデータ量はやはり少なめなので上下6半音ずつピッチシフトを行い、12倍水増し(data augmentation)します。
結論
実験では「Encoderの出口は全連結層か、双方向GRUか」「Decoderは従来形式か、Structured形式か」の違いで4パターンのモデルを作って評価実験を行いました。全面的に従来モデルよりも性能が優れていましたが(論文Table1)、4パターン同士を比較すると、Structuredの仕組みで複雑なコードの認識が特によくなっている事はない気もします。
予告
しゃをみん自身が考えたコード認識システムが、今秋のMIREX2017にて披露される予定です。上述の手法にちょっと似てるかもしれません。論文を出し損ねたのでフライング発表みたいな感じになりますがお楽しみに。論文も早く採択に持っていかないとヤバい。