構築環境の前提
本テーマの前提環境
・Windows
・Python3.11.6
他の方の記事を参考にしましたが自分のパソコンの環境では上手くいかなかったので、自分が上手くいった方法を記事に残しておくことにしました。
1.MeCabのダウンロード
MeCabのインストール方法は以下のサイトに参照してください。
環境変数のPATHに以下のコードを追加することを忘れなく。
PATHを通さないとMeCabは動作しません。
サイト通りに作業しPATHを通しても上手くいかない場合は、コマンドプロンプト(cmd)を再起動してください。
C:\Program Files (x86)\Mecab\bin
2.PythonとMeCabを連携する
python上でMeCabを動作させるために、その2つを連携する必要があります。
連携させるためにcmdに以下のコマンドを入力してください。
pip install mecab-python3
インストールできたら、Pythonで以下のコードを入力し、動作確認してください。
import MeCab
mecab = MeCab.Tagger("-Owakati")
mecab.parse("私は大学生です。").split()
#結果は以下のように表示されます。
#['私', 'は', '大学', '生', 'です', '。']
3.NEologDのダウンロード方法
NEologDの辞書をダウンロードするにあたり、gitと7-zipが必要になります。
gitのインストール
gitは以下のサイトからインストールしてください。
7-zipのインストール
7-zipは以下のサイトからダウンロードしてください。
多くの人は最新のバージョンかつ以下の条件のものをダウンロードすれば大丈夫だと思われます。
Type:.exe
System:64-bit Windows x64
7-zipも環境変数にPATHを通してください。
C:\Program Files\7-Zip
gitでNEologDをダウンロード
上記の作業が完了したら、gitを用いてNEologDをダウンロードします。
まず、以下のコマンドでユーザーフォルダに移動します。
cd %homepath%
つぎに、以下のコマンドでNEologDをダウンロードします。
git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git
ダウンロードを終えたら、C:\Users(ユーザー名)\mecab-ipadic-neologd\seedに移動しファイルを確認する。
エクスプローラーでも確認可能。
cd mecab-ipadic-neologd\seed
dir
ダウンロードしたCSVファイルを7-zipを用いて解凍する。
7z X *.xz
解凍すると、C:\Users(ユーザー名)\mecab-ipadic-neologd\seedのフォルダ内は以下の図のようになります。
4.MeCabとNEologDを連携する
MeCabにNEologDを認識させる必要があります。
まず、「C:\Program Files (x86)\MeCab\dic」のファルダに「NEologD」を作成していきます。
次に、上記の作業パスのまま以下のコマンドを入力します。
NEologD辞書のファイル名はダウンロードしたファイルの名前に合わせてください。
mecab-dict-index -d "c:\Program Files (x86)\MeCab\dic\ipadic" -u NEologd.20200910-u.dic -f utf-8 -t utf-8 mecab-user-dict-seed.20200910.csv
辞書をコンパイルすると、以下の図のように「NEologd.20200910-u.dic」が作成されます。
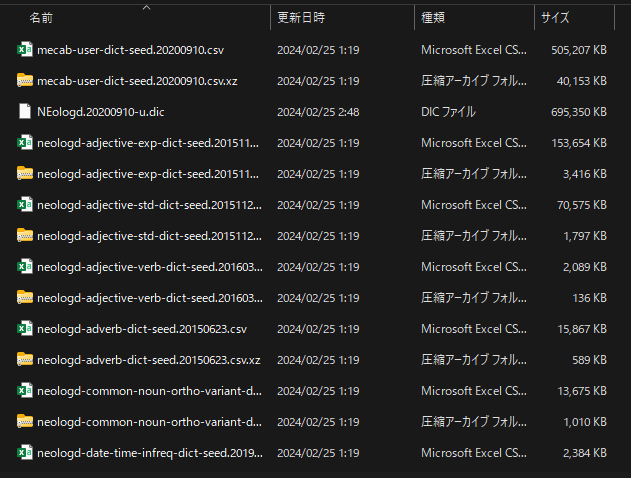
作成した「NEologd.20200910-u.dic」を「C:\Program Files (x86)\MeCab\dic\NEologD」にコピペしてください。
これで環境構築は終わりです。
5.MeCabにおけるNEologDのPATHの書き方
MeCabにNEologDを認識させるためには以下のPATHを書いてください。
import MeCab
tagger = MeCab.Tagger('-Owakati -d "C:/Program Files (x86)/MeCab/dic/ipadic" -u "C:/Program Files (x86)/MeCab/dic/NEologd/NEologd.20200910-u.dic"')
result = tagger.parse('私が最近見た映画は、約束のネバーランドでした。')
print(result)
#結果
#私 が 最近 見 た 映画 は 、 約束のネバーランド でし た 。
NEologDの特徴である固有名詞(約束のネバーランド)がしっかりと認識できていることが分かります。
一方、PATHを記載しないと以下のように約束のネバーランドが認識できていないことが分かります。
import MeCab
tagger = MeCab.Tagger('-Owakati')
result = tagger.parse('私が最近見た映画は、約束のネバーランドでした。')
print(result)
#結果
#私 が 最近 見 た 映画 は 、 約束 の ネバー ランド でし た 。
おまけで
自然言語処理に特化したBERTにおけるNEologDのPATHの通し方を以下に示します。
from transformers import BertJapaneseTokenizer
tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-v3', mecab_kwargs={"mecab_option": '-u "C:/Program Files (x86)/MeCab/dic/NEologd/NEologd.20200910-u.dic"'})
print(tokenizer.tokenize('私が最近見た映画は、約束のネバーランドでした。'))
#結果
#['私', 'が', '最近', '見', 'た', '映画', 'は', '、', '約束', '##の', '##ネ', '##バー', '##ランド', 'でし', 'た', '。']
おわりに
他の方の記事ではmecabrcにusedicを指定してますが、本記事ではmecabrcの編集はおこなっておりません。
以下の記事で上手くいけばその方がいいと思います。
参考にした記事を以下に記載しておきます。