こんにちは。Treasure Dataの斉藤です。出張中に時間ができたのでシアトル空港でこの記事を書いています。日本語でブログを書くのはものすごく久しぶりなのですが、Treasure Dataの列志向(columnar)圧縮ストレージであるPlazmaDBについて紹介していきたいと思います。
Treasure Dataでは2014年現在まで5兆(trillion)件を超えるレコードが取り込まれており、一秒あたりでは40万以上(!)のレコードを処理しています。
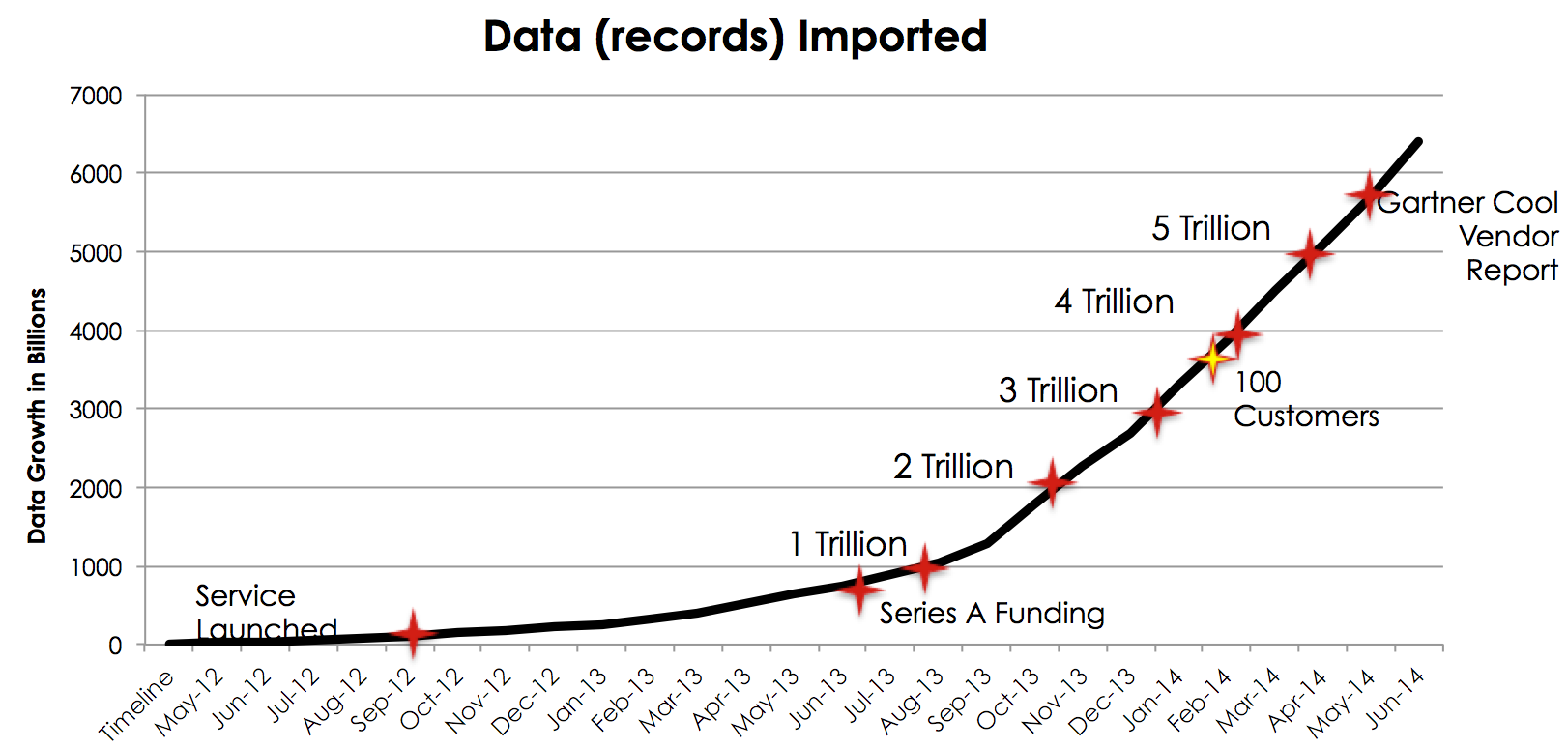
2013年のTwitterでは1秒あたり5,700 tweets処理していたとのことなので、その処理量の大きさが実感できるのではないでしょうか。この量のレコードをそのまま蓄積するのではストレージ量が膨大になってしまいますので、Treasure Dataではレコードを列分解し、MessagePack形式に変換+圧縮処理を施すことでデータサイズを約10分の1に抑えています。
PlazmaDB
PlazmaDBの特徴を挙げると、
・レコードを列分解(MessagePack形式のデータ列に変換)して圧縮
・スキーマは自動的に付与されるため (implicit schema)、
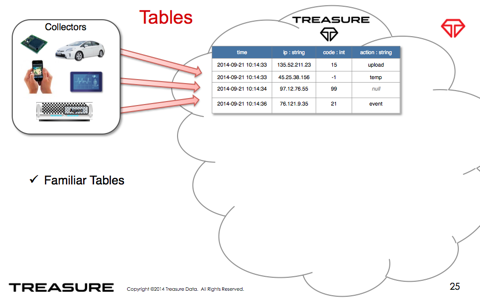
列の追加が容易です。
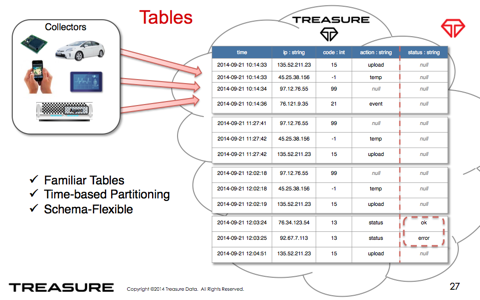
スキーマの再設計に伴うDBの再構築などのコストが全くありません。
・1時間ごとのまとまりでパーティションが作成されるため、直近のデータの検索が高速になります。
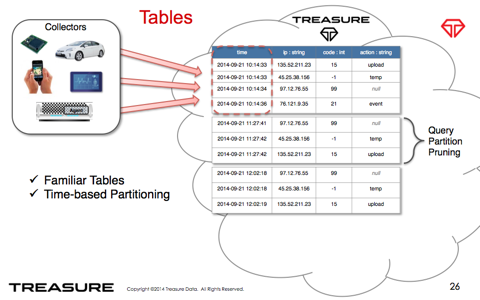
・また、列内に複数の型のデータを混在させることができ、クエリ実行時に要求される型に合わせて変換されます。
PlazmaDBではMessagePack形式のデータを内部的に使っているのが肝で、fluentdとの親和性もさることながら、各要素が型情報(int, string, arrayなどなど)を自ら持っているデータ(self-describing format)なので、例えば、最初はint型でidを表現していたが後からstring型のA001, A002などの文字列に変更したくなった場合でも柔軟に対応できます。
明示的にスキーマを指定することで(explicit schema)、string型で保存されているデータをint型のデータとして見せることもできます。型が指示通りに変換できない場合にはNULLとして出力されますが、実際のデータが消えているわけではありません。

implicit/explicit schemaを活用した業務フローについてはこちらの記事も参考にしてください: データ解析を簡単に 〜 スキーマ管理の権限移譲
PlazmaDBではArray型などのデータも列中に保存できるため、Treasure DataのPrestoによる検索サービスでも利用できます。このようにテーブルの要素にネストしたデータを保存する形式は、第1正規形(1st Normal Form:1NF。要素は必ず1つのデータを持つ)ではなくなるため、Non-First Normal Form (NF^2)という呼び方をすることもあります。
JSONやXMLでもこのようなNF^2のデータを表現できるのですが、JSONは要素を1つ読み終えるまで型の判定ができないため読み込みの性能が悪くなりますし、XMLデータでは要素以外に空白などの情報も含まれるためMessagePack形式ほど高速にデータを処理することはできません。PlazmaDB内部では、旧v06より性能を2倍改善したmsgpack-java v07を利用しており、非常に高速に列データの読み出しが可能となっています。XMLの研究が普及してきた1997年頃にMessagePackがあれば、XMLの仕様に由来するあらゆる問題(parsing, text、空白の扱い、XMLスキーマなどの複雑な外部スキーマ定義など)に苦しむ必要はなかったのではないかと思います。
GiSTによる時間軸検索の高速化
PlazmaDBで1時間単位で作成されたpartitionを高速に見つけるために、PostgreSQLのGiST indexが利用されています。(data set id, (partition start_time, end_time)) の複合keyでindexが作成されており、ユーザーデータのID、時系列の範囲の組で素早く検索することができます。もしGiSTを用いずに、data set id, start/end timeの各々にindexを作成してしまうと、PostgreSQLのオプティマイザが各indexを独立に検索してしまうためディスクI/O量が多くなってしまいます。
このGiST indexは、TD_TIME_RANGE(time, start_time, last_time)という、現在TDで唯一indexを使うUDFの裏側で利用されています。例えば2014-12-14以降のデータを取得するにはwhere文中にTD_TIME_RANGE(time, ‘2014-12-14 JST’) のように条件を指定するとレコードのスキャン量を減らし、高速に検索結果が得られるようになります。
GiST indexはVLDB95でHellersteinらが発表した研究でPostgreSQLには古くから取り込まれている機能です。Hellersterinは、データベース研究の歴史を整理したReadings in Database Systems(通称Redbook)の著者でもあり、最近ではRAMPトランザクション P. Bailisとの共著. SIGMOD2014など、レプリカがあるデータベースで一貫性の制御が必要ない更新をうまく抜き出すセマンティクスを導入することでTPC-Cのトランザクションを大幅に高速化するなど、トランザクション研究でも活躍している先生です。参考までに。
データベース研究と実世界のDB
PlazmaDBは、JSON, XMLデータが持つ良い性質を抽出し、GiSTインデックスなど過去の研究の成果も上手に使ったデータベースになっています。僕も長らくXMLDBを研究してきましたが、この理想形とも言えるDBがTreasure Dataで実装され、多くの人に便利に使っていただいているというのは感慨深いものがあります。PlazmaDBの機能を抽出したオープンソースの簡易版も用意できると良いですが、作ってみたいという方はぜひこちらまでご応募ください。