前回までのあらすじ
pythonのpillowを使って画面のスクショを持ってこようとするも、マルチスクリーンへの対応に四苦八苦。
win32gui等色々触るも結局もとのpillowのパラメータを変更することで解決。
雀魂画面のスクリーンショットを持ってくることに成功!
今回やること
いよいよこのシリーズの本題の一つ、画像認識で雀魂の画面から牌姿情報を持ってくることに着手します。
具体的には
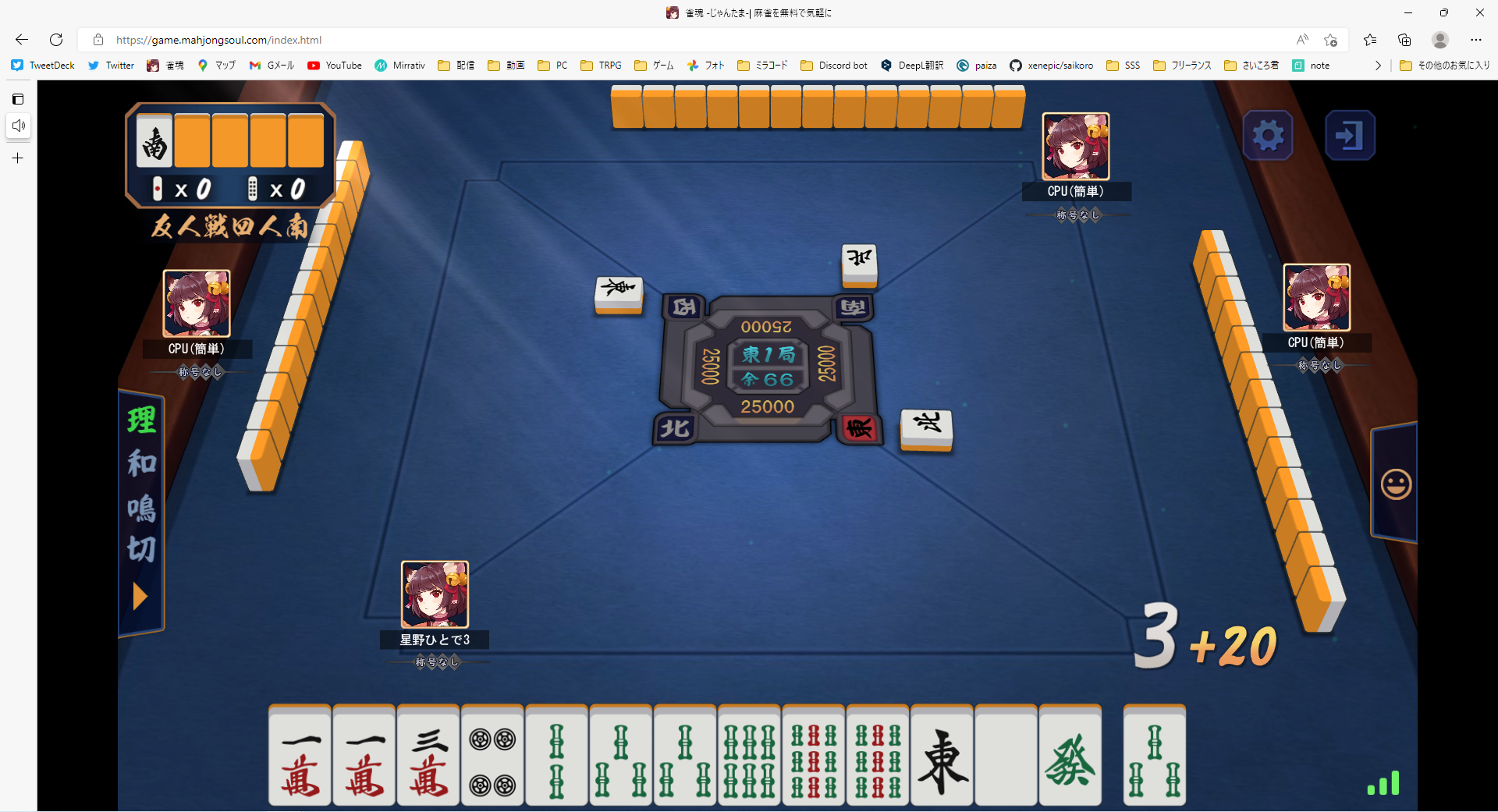
この画面から
paiList = ['m1', 'm1', 'm3', 'p4', 's2', 's3', 's3', 's6', 's9', 's9', 'j1', 'j5', 'j7', 's3']
のような配列を生成することを目指します。
手順
- ウィンドウのスクリーンショットから雀魂の画面だけを切り出す
- 雀魂の画面から手牌の部分だけを切り出す
- 手牌の画像を、牌一つ一つに分けて切り出す
- 牌が何なのかを識別する
- 13個(+ツモ牌)分繰り返し、手牌の牌姿情報を出力する
と、こんな感じです。
ウィンドウのスクリーンショットから雀魂の画面だけを切り出す
前回のコードで切り出した画像は、ブラウザ本体の部分だったり、雀魂画面の外に黒い枠がついていたりします。
黒い枠は雀魂本体の画面とブラウザの大きさのアスペクト比を調整するためについているものなので、ブラウザの大きさによって上下に付いていたり左右に付いていたりします。


この部分はユーザの環境によってそれぞれ違うので、そこを排除しようというのが、ここでやりたいことになります。
それさえ排除してしまえば、雀魂の部分から牌姿情報を取り出すのは簡単やりやすそうですしね。
その手法ですが、例によってvol.0でも紹介したこちらの記事の手法を真似させていただきます。
ネット麻雀(雀魂)をopenCVと機械学習で自動化した話 - Qiita
https://qiita.com/hiro0156/items/51ab267f4f47f2f8fe76
雀魂のメイン画面の大きさを誤差を抑えて推定するために、画面上のなるべく離れた二点をテンプレートマッチングでマッチさせます。
上記記事では左上の点棒マークと右下の電波状況マークをマッチさせていましたが、大会の観戦画面などでは電波状況マークが表示されないため、今回は右上の歯車マークをマッチさせます。上下間の距離が近いのでちょっと心配。
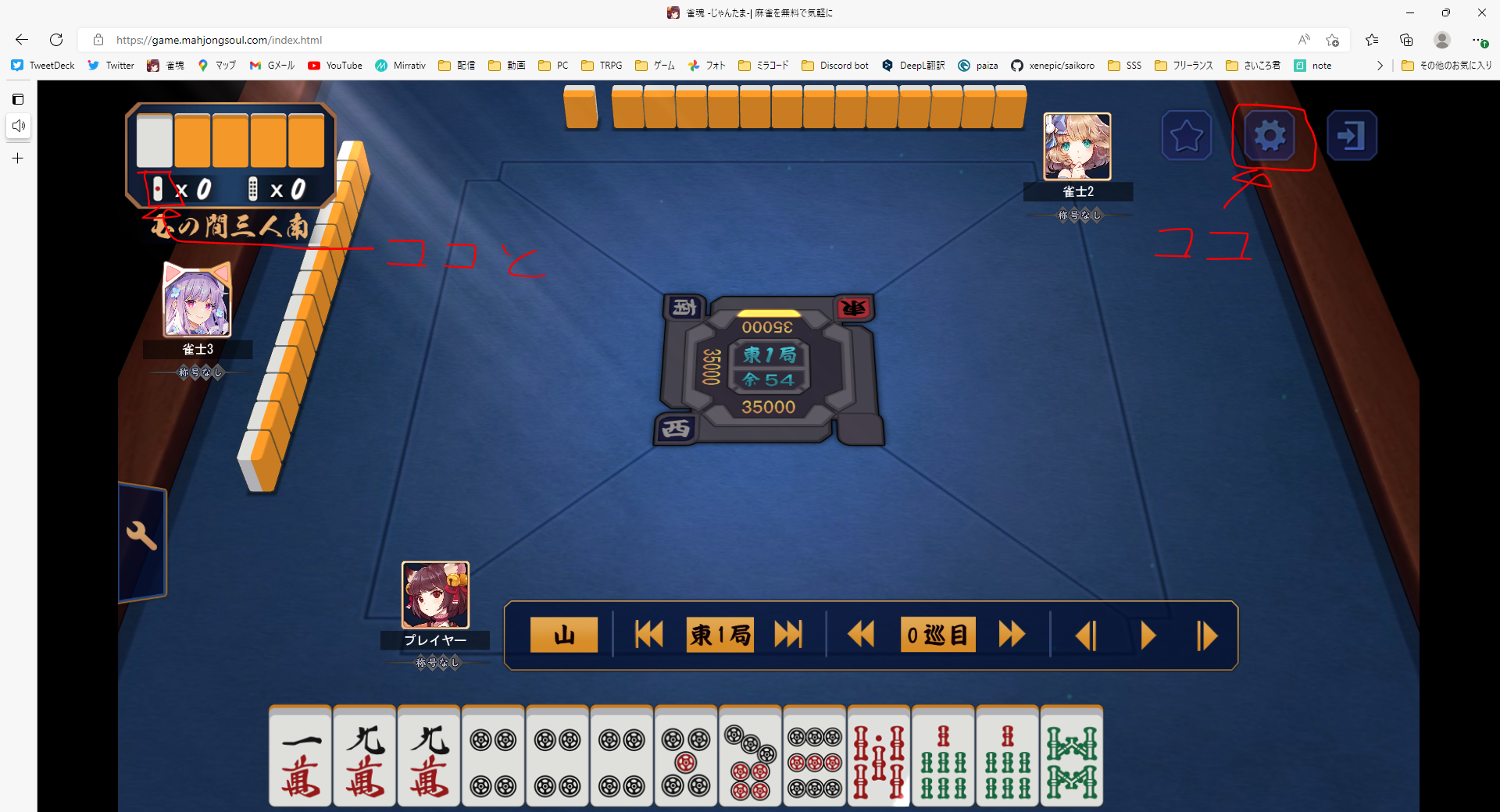
歯車マーク、うっすら透明になってるから背景の卓の画像が変わったら嫌な予感がしますが...
OpenCV でテンプレートマッチングする
https://shikaku-mafia.com/opencv-template-match/
テンプレートマッチングは上記サイトのコードをそのまま拝借してテストします。
テンプレート画像は次の2つ


類似度90%でマッチングさせると、次のようになります。

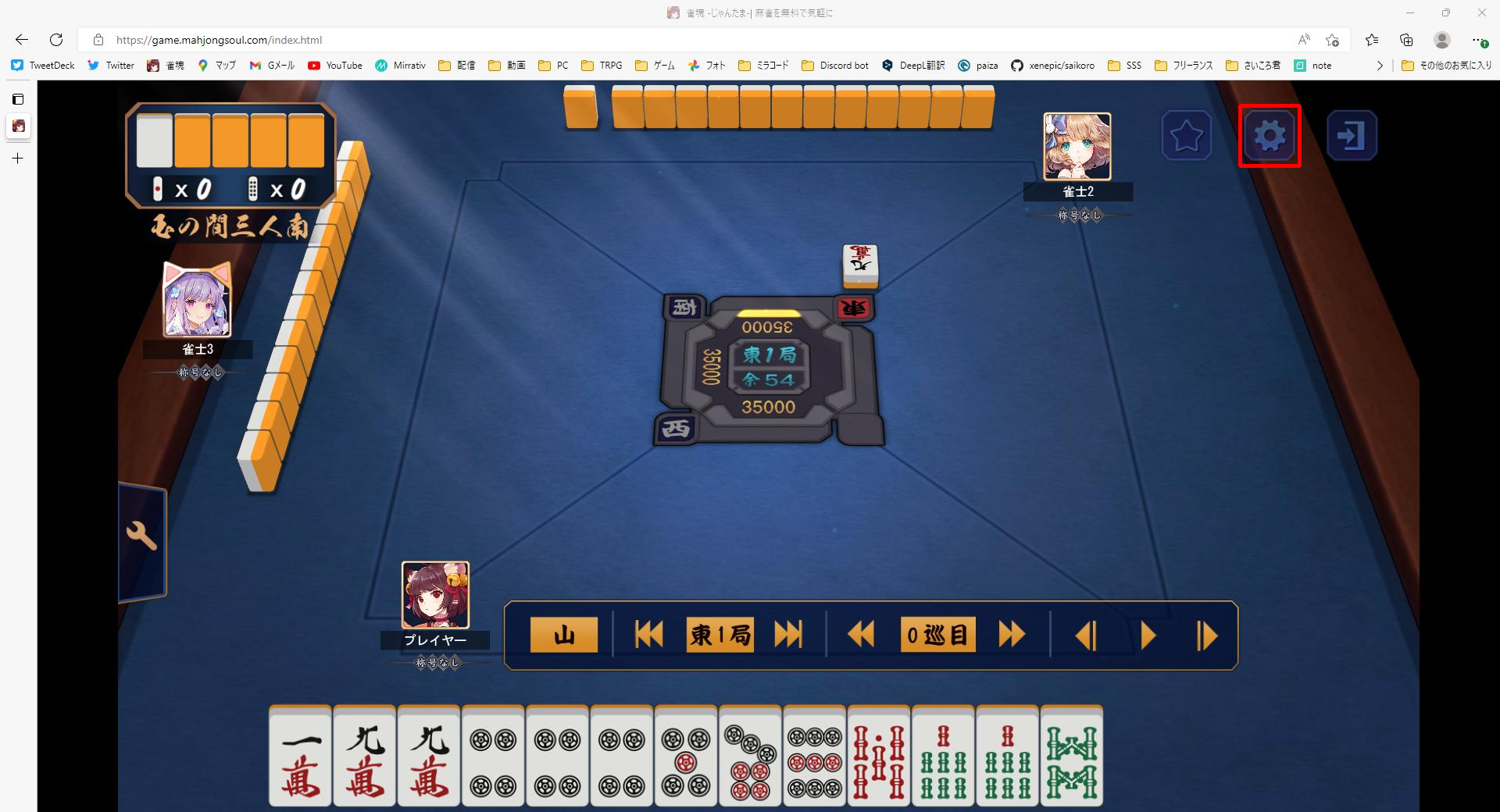
うまくマッチングできてますね!
私の彼女探しもこれくらいキレイにマッチングできればいいのに
ここでマッチした座標を元に、雀魂の本体画面の座標のtop, bottom, left, rightを算出します。
top = int(gear_loc[0]-(tenbo_loc[0]-gear_loc[0])*11/29)
bottom = int(tenbo_loc[0]+(tenbo_loc[0]-gear_loc[0])*830/87)
left = int(tenbo_loc[1]-(gear_loc[1]-tenbo_loc[1])*39/1397)
right = int(gear_loc[1]+(gear_loc[1]-tenbo_loc[1])*229/1397)
数値は後で色々修正するかも知れませんが、とりあえずこれで座標を算出した後、
img[top:bottom, left:right]
で雀魂の画面部分だけを切り抜きできます。
これでテストしてみると、いい感じに抜き出せてる模様!
やったぜ!
と思ったの束の間、雀魂のブラウザを縮小してテストすると動きません。
それもそのはず、実はテンプレートマッチングは拡大縮小・回転にはめっぽう弱く、少し違うだけで類似度が大きく下がってしまう性質があります。
今回は拡大縮小にだけ対応させれば良いので、例えば大きさの異なるテンプレート画像をいくつも用意しておいて、それらをすべてマッチングさせると言った原始的な方法もあります。
が、一旦ここは特徴量マッチングを試してみましょう。
- 特徴量マッチングとは
比較する画像からまず特徴点の抽出を行い、全ての特徴点同士の距離を元に類似度を算出するマッチング方法です。
特徴点としては、角や輝度の勾配などがよく用いられます。
特徴量マッチングでは、テンプレート画像の拡大縮小・回転に対応できるメリットがあります。
デメリットとしては、計算時間でしょうか。
テンプレートマッチングと比べて、特徴点の算出という工程を挟むので、そこに時間がかかります。
まぁどれくらい掛かるかまだ分からないので、とりあえず試してみましょう!
Python+OpenCVを利用したマッチング処理
https://dronebiz.net/tech/opencv/matching
こちらの記事のからサンプルコードをお借りして動かしてみたのですが、結果としては全然上手く動きませんでした。
歯車の画像の特徴量マッチング結果が以下となります。
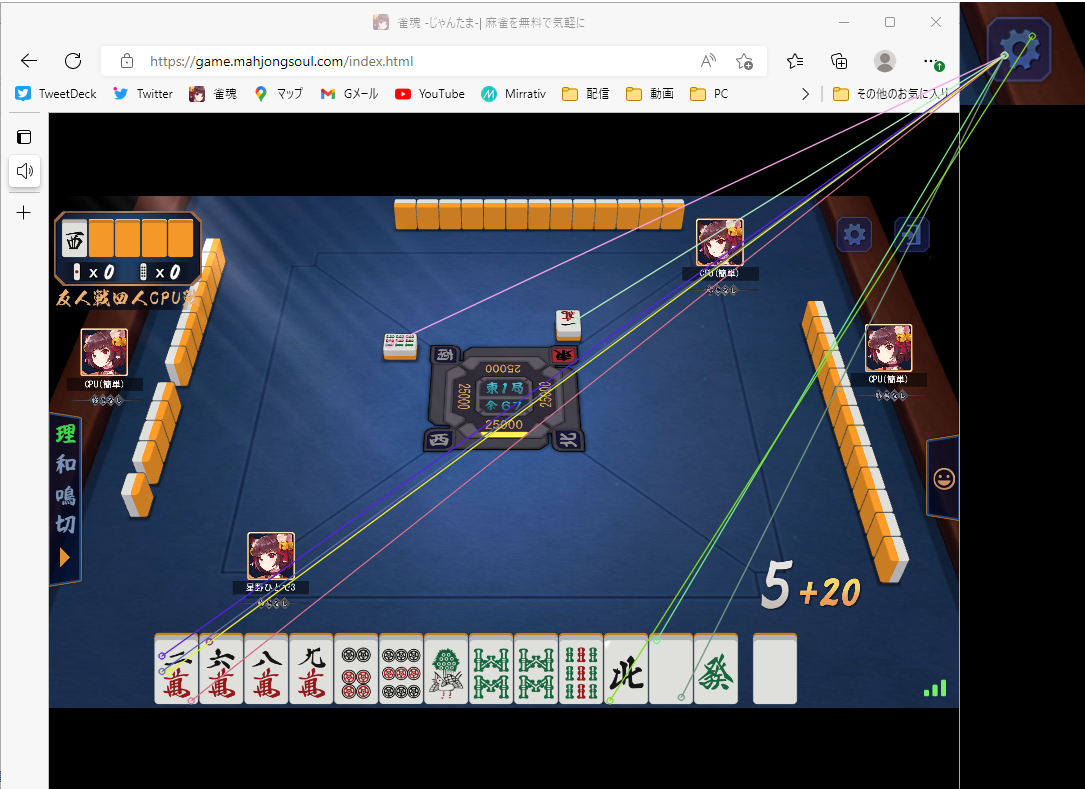
うーん、これはひどい。特徴量とは??
knn近傍法のマッチ等も試してみましたが、特に改善は見られませんでした。
特徴量マッチングは難しそうかなぁ。
というわけで、原始的な堅実なアプローチを試しましょう。
cv2のriseze関数を使って、マッチするまでテンプレート画像を100%から順番に小さくしていきます。
import cv2
import numpy as np
def cropJantamaMainImage(captureImagePath: str, templateImagePathList: list):
if len(templateImagePathList) <= 1:
print('テンプレート画像の個数が足りません。')
return
# キャプチャ画像の読み込み + グレースケール化
try:
img = cv2.imread(captureImagePath)
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
except Exception as e:
print('キャプチャ画像の読み込みエラーです。')
print(e)
return
# テンプレート画像の読み込み
try:
template_images = [cv2.imread(templateImagePathList[0]), cv2.imread(templateImagePathList[1])]
except Exception as e:
print('テンプレート画像の読み込みエラーです。')
print(e)
return
# テンプレート画像のサイズを100%から5%ずつ小さくしてマッチング
for i in range(0, 20):
loc = []
# 点棒と歯車、2つのテンプレートのマッチング位置を求める
for template_it in template_images:
# テンプレート画像を縮小してグレースケール化
rate = 1 - 0.05*i
template = template_it
height = template.shape[0]
width = template.shape[1]
template = cv2.resize(template, dsize = None, fx = rate, fy = rate)
template_gray = cv2.cvtColor(template, cv2.COLOR_BGR2GRAY)
# キャプチャ画像に対して、テンプレート画像との類似度を算出する
res = cv2.matchTemplate(img_gray, template_gray, cv2.TM_CCOEFF_NORMED)
# 類似度の高い部分を検出する
threshold = 0.9
loc_candidate = np.where(res >= threshold)
# 点棒と歯車、どちらかでもマッチしなければ次のテンプレートサイズへ
if len(loc_candidate[0])==0 or len(loc_candidate[0])==0:
break
# マッチング座標の中で最頻値を求める
mode = []
for loc_it in loc_candidate:
unique, freq = np.unique(loc_it, return_counts=True)
mode.append(unique[np.argmax(freq)])
loc.append(mode)
# 点棒と歯車、両方とも座標が求まっていればマッチ終了
if len(loc) == 2:
break
if len(loc) <= 1:
print('マッチが見つかりませんでした')
return
else:
# マッチしたテンプレートの位置から、雀魂の画面の端の位置を算出する
tenbo_loc = loc[0]
gear_loc = loc[1]
top = int(gear_loc[0]-(tenbo_loc[0]-gear_loc[0])*11/29)
bottom = int(tenbo_loc[0]+(tenbo_loc[0]-gear_loc[0])*830/87)
left = int(tenbo_loc[1]-(gear_loc[1]-tenbo_loc[1])*39/1397)
right = int(gear_loc[1]+(gear_loc[1]-tenbo_loc[1])*229/1397)
return img[top:bottom, left:right]
ソースはこんな感じになりました。
点棒と歯車の上下の位置が近いのでbottomの位置とかズレそうだなーと思ってたんですが、
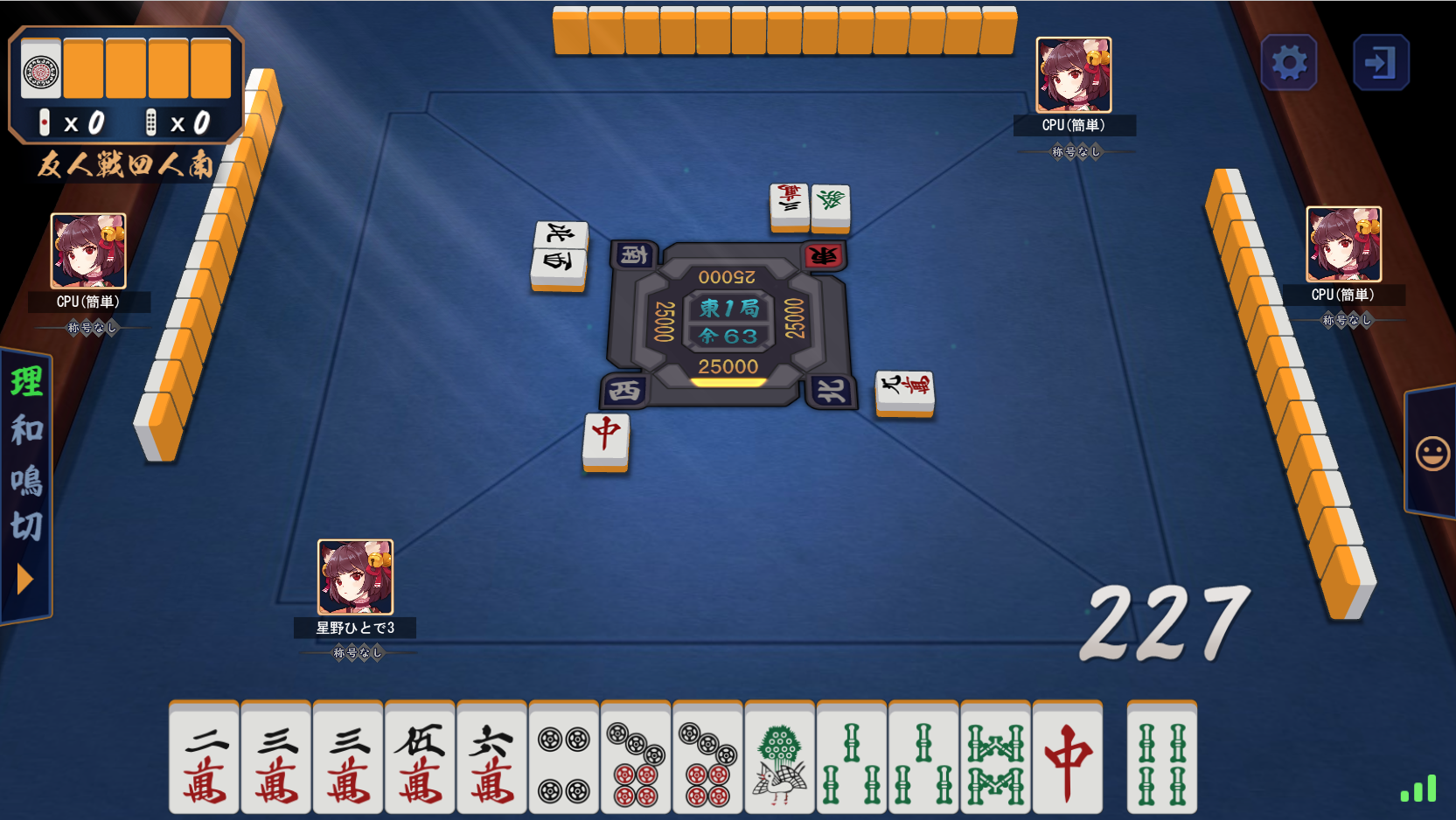
雀魂のブラウザを拡大縮小してもちゃんと本体画面だけ抜き出せておりました!
雀魂の画面から手牌の部分だけを切り出す
切り出すだけです。
def cropMyHandImage(jantamaMainImage):
height, width = jantamaMainImage.shape[:2]
myHandLeft = int(width*193/1665)
myHandRight = int(width*1261/1665)
myHandTop = int(height*800/938)
myHandBottom = int(height*931/938)
tsumoLeft = int(width*1289/1665)
tsumoRight = int(width*1368/1665)
myHandImage = jantamaMainImage[myHandTop:myHandBottom, myHandLeft:myHandRight]
myTsumoImage = jantamaMainImage[myHandTop:myHandBottom, tsumoLeft:tsumoRight]
myHandImage = cv2.resize(myHandImage, dsize = (1068,131))
myTsumoImage = cv2.resize(myTsumoImage, dsize = (81,131))
return [myHandImage, myTsumoImage]
後で牌の種類を識別させる時のテンプレートマッチングをやりやすくするために、画像のサイズは一定にしてあります。


手牌とツモがキレイに抜き出せてますね!
最大化ではなく小さくしたブラウザのサイズでも試してみます。


拡大しているせいで多少ぼやけていたり、手牌の左に若干空間があったりしますが、まぁ許容範囲でしょう。
手牌の画像を、牌一つ一つに分けて切り出す
def divideMyHandImage(myHandImage):
width = myHandImage.shape[1]
myHandImageList = []
for i in range(2,1068,82):
myHandImageList.append(myHandImage[:,i:i+81])
return myHandImageList
特に説明は不要ですね。
81ピクセル間隔で切り分けてます。


手牌の最初と最後の牌。
最後の牌は少しズレがありますが、まぁこれも許容範囲でしょう。後々影響が出れば修正します!
牌が何なのかを識別する
さぁ問題はここからですね!
まずは雀魂で使われている牌の画像34種の画像が必要になります!

これを作るために、CPU相手にひたすら一通を作り続けました。
正確には赤ドラを含めた37種ですが、テンプレートマッチングで5と赤5を区別するのは難しいため、ごちゃまぜにしています。1
余談ですが、雀魂の牌で完全の上下対称なのは、白と2pだけだそうです。
4pや2sも、よーく見ると微妙に対称ではありません。
後は持ってきた牌の画像とこの牌表の画像でテンプレートマッチングを行い、求まった座標から牌の種類を特定するだけです。
def recogPaiImage(paiImage, paiListImagePath):
# 雀牌表画像の読み込み + グレースケール化
try:
paiListImage = cv2.imread(paiListImagePath)
paiListImage_gray = cv2.cvtColor(paiListImage, cv2.COLOR_BGR2GRAY)
except Exception as e:
print('雀牌表画像の読み込みエラーです。')
print(e)
return
# 識別する雀牌画像のグレースケール化
paiImage_gray = cv2.cvtColor(paiImage, cv2.COLOR_BGR2GRAY)
# キャプチャ画像に対して、テンプレート画像との類似度を算出する
res = cv2.matchTemplate(paiListImage_gray, paiImage_gray, cv2.TM_CCOEFF_NORMED)
# 類似度の高い部分を検出する
threshold = 0.8
loc_candidate = np.where(res >= threshold)
# マッチング座標の中で最頻値座標を求める
mode = []
for loc_it in loc_candidate:
unique, freq = np.unique(loc_it, return_counts=True)
mode.append(unique[np.argmax(freq)])
# 座標を元に牌の種類を識別する
paiList = (
('m1','m2','m3','m4','m5','m6','m7','m8','m9'),
('p1','p2','p3','p4','p5','p6','p7','p8','p9'),
('s1','s2','s3','s4','s5','s6','s7','s8','s9'),
('j1','j2','j3','j4','j5','j6','j7')
)
listHeight, listWidth = paiListImage.shape[:2]
paiKind = int((mode[0]+listHeight/8)/(listHeight/4))
paiNum = int((mode[1]+listWidth/18)/(listWidth/9))
return paiList[paiKind][paiNum]
13個(+ツモ牌)分繰り返し、手牌の牌姿情報を出力する
jantamaMainImage = cropJantamaMainImage('./sample.png', ['./templ_tenbo.PNG', './templ_gear.PNG'])
myHandImage, myTsumoImage = cropMyHandImage(jantamaMainImage)
myHandImageList = divideMyHandImage(myHandImage)
paiList = []
for i in range(13):
paiList.append(recogPaiImage(myHandImageList[i], './paiList.png'))
paiList.append(recogPaiImage(myTsumoImage, './paiList.png'))
print(paiList)
今まで作った関数を順番に動かします。
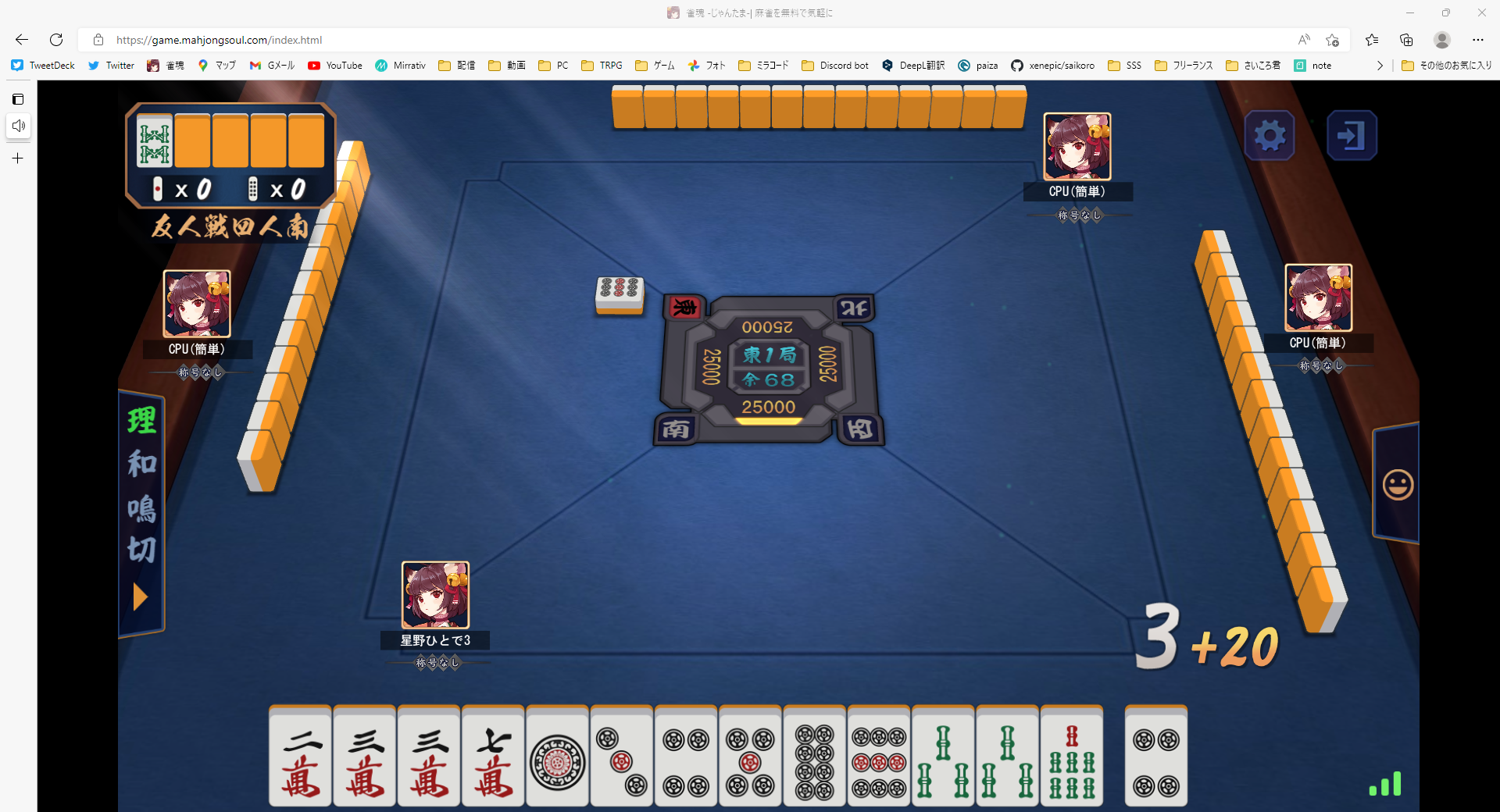
上の画像を読み込んで、出力は以下の通り。
project> python templateMatch.py
['m2', 'm3', 'm3', 'm7', 'p1', 'p3', 'p4', 'p5', 'p8', 'p9', 's3', 's3', 's7', 'p4']
うん!ちゃんと認識できてますね!!!
ブラウザのサイズを変えてもう一度、、、
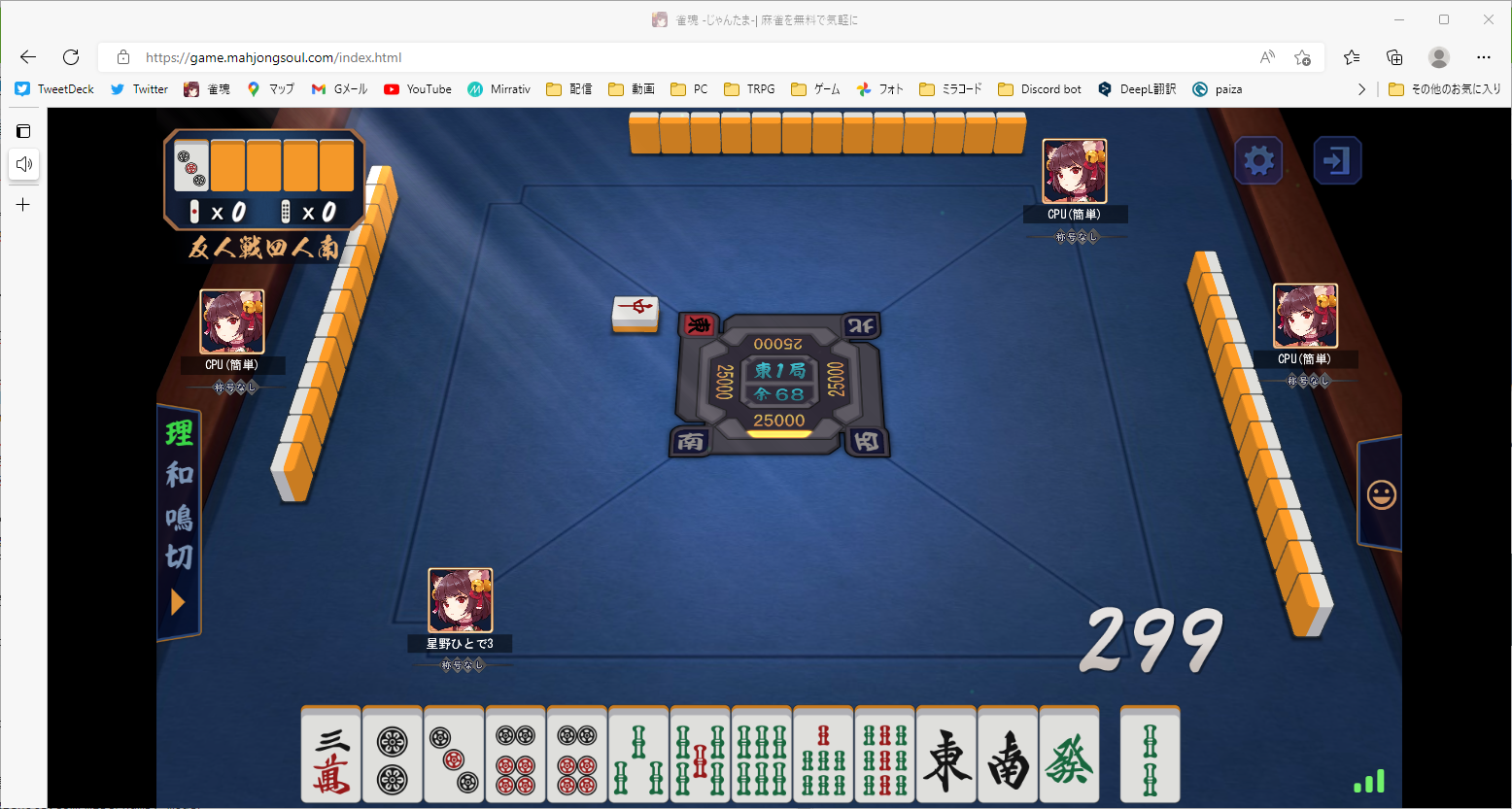
project1> python templateMatch.py
['m3', 'p2', 'p3', 'p6', 'p6', 's3', 's5', 's6', 's7', 's9', 'j1', 'j2', 'j6', 's2']
問題なさそう!
まとめ
随分長くなってしまいましたが、画像から手牌を認識して持ってくることが出来ました。
ただ、このプログラムだと赤ドラを認識できないんですよね。
これはまた次回の課題としたいと思います。
他にも、
- 鳴いた場合の牌
- 自分以外のプレイヤーの手牌
- プレイヤー名
- 点棒、本場
- 点数状況
- 自風
- ドラ
等の認識も、次回以降順を追って対応していきたいと思います。
それでは!
参考
numpyで最頻値を求める
https://kagglenote.com/misc/numpy-mode/
-
テンプレートマッチングは最初にグレースケール化してしまうため5と赤5を色で区別することが出来ず、また雀魂のドラ牌は「光る」ため、ある程度マッチ精度を低くしておく必要があるため、赤5の点の有無を区別するまで精度を上げることが出来ないため。 ↩