はじめに
最新のSSMS(v17.4)と、SQLServer2016の組み合わせでクエリ推定実行プランを使ってみる。最新機能の紹介ではなく自分自身の確認が主目的なので「そんなの前から搭載されてるよ」的なものもいっぱいあると思うが許して欲しい。
インデックスの作成をsuggestしてくれた
ヒープテーブル同士をjoinして結果を見てみた。同じテーブルでテーブル件数を変えてコストの変化も見てみた。
使用テーブル
CREATE TABLE [dbo].[qlab1](
[c1] [int] NOT NULL,
[c2] [nvarchar](50) NULL,
[c3] [nvarchar](100) NULL,
[c4] [bit] NOT NULL,
[c5] [nchar](10) NULL,
[c6] [smallint] NULL
) ON [PRIMARY]
実行クエリ
Select T1.*, T2.*
From (
Select *
From dbo.qlab1
) T1
Inner join (
Select *
From dbo.qlab1
) T2
On T1.c1 = T2.c1;
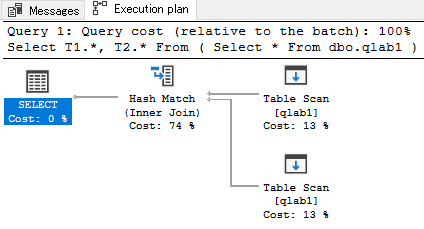
投入データ 5行の場合
cost total = 0.0248171
投入データ 4096行の場合
cost total = 0.481369
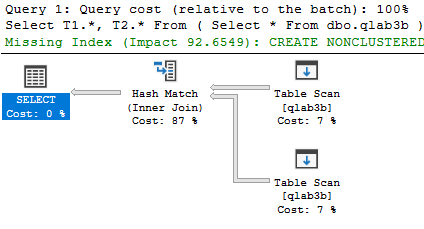
緑字で、Indexを作成するといいことありますよ~(impact 92.6549) と示唆してくれた。
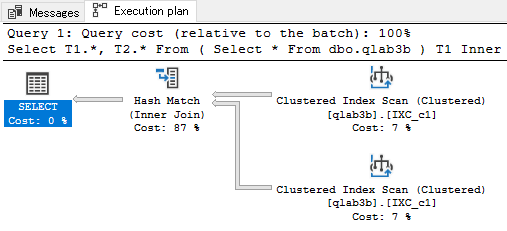
インデックスを貼ってみた :clustered index
仰せのとおりindexを作成してみようではないか。
まずindexを列c1に貼った結果。
total cost = 0.482851
テーブルスキャンよりコストが若干UPしてしまった。
オンメモリで処理できる範囲で4096件程度ならindexを作るまでもないということか。
インデックスを貼ってみた :non clustered index
今度は列c1に貼るインデックスをnon-clusteredにしてみた。
total cost = 0.482851
コストは変わらず。
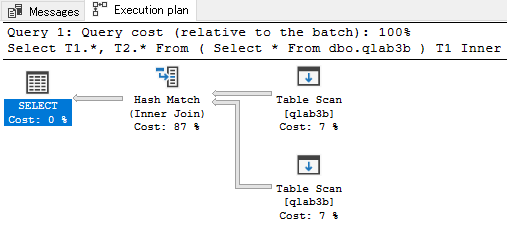
やはりこの程度の件数だとテーブルスキャンになってしまうようだ。
件数を増やしてみた
65,536件で再度トライ。
その1 ヒープテーブルの場合
total cost = 6.35656
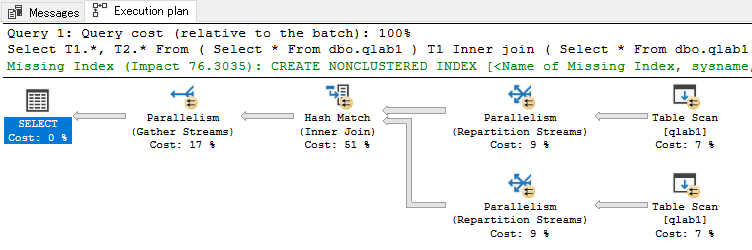
実は今回の実験から、ゲストOSの割り当てをCPUコアx2, メモリ8GBに増やしている。
そしたら並列クエリが発動。
テーブルからのデータ読み込み、そしてハッシュ結合の処理が並列になった。
ではあえて直列処理にしたらどうなるだろう。
下記のようにOptionとしてMAXDOPを1に指定してやってみた。
Select T1.*, T2.*
From (
Select *
From dbo.qlab1
) T1
Inner join (
Select *
From dbo.qlab1
) T2
On T1.c1 = T2.c1
Option (MAXDOP 1);
結果は...
total cost 7.34901
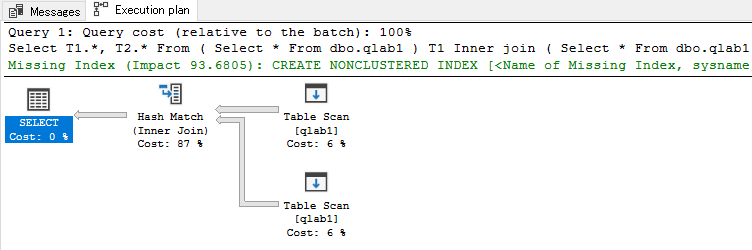
Parallelismはなくなり、コストは増加。この処理の場合は並列が効いているようだ。
その2 クラスター化インデックスの場合
total cost = 6.38167
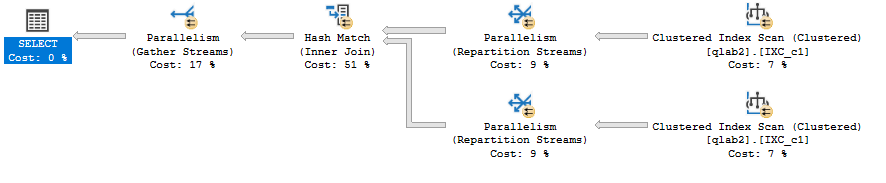
ヒープの時より若干コストが上がってしまった。
その3 列c1をプライマリキーにした場合
total cost = 1.20852
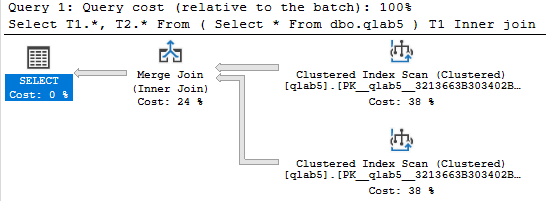
ダントツに速い。
PKによるユニーク制約が効いているのであろうか。ならばクラスターインデックス+ユニーク制約というパターンとも比較してみよう。
その4 列c1にクラスター化インデックスとユニーク制約を付けた場合
total cost = 1.21
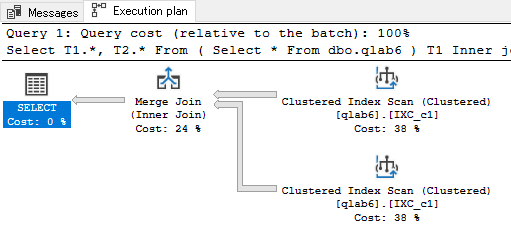
PK指定した場合と、ほぼ同速度になった。構造的に同じはずだからそうに違いない。
付加列インデックスなど試してみたいが、いったんPart1は終わり。