はじめに
近年、深層学習を用いた自然言語処理技術の進展が目覚ましいです。
その中でも、GPT-3をはじめとする大規模言語モデル(LLM)には大きな可能性を感じています。
最近ですと、AI技術者以外にも大きなインパクトを与えたChatGPTが記憶に新しいでしょう。
今後もLLMの進化は止まらないと予想されており、私たちもどうやって活用するかを具体的に検討すべきフェーズに入ったのではないでしょうか。
しかし、LLMを実業務に適用するとなると、越えなければならない課題がいくつも出てきます。
今回は、以下にあげた第2・第3のハードルを越えるために役立つlangchainというライブラリをご紹介します。
第1のハードル:機密データの扱い
LLMはOpenAPIのGPT-3等、モデル自体は公開されておらずWebAPIだけが提供されているというパターンが多いです。
そのため、機密データを社外に送信するとなると、各企業のセキュリティルールという大きな壁が立ち塞がるかもしれません。
できれば社内環境や既に利用しているパブリッククラウド上にホストすれば上記の問題は多少緩和されるでしょう。
ただ、LLMは文字通りとても巨大なモデルです。
例えば、公開されているLLMのひとつであるBLOOMは176Bのパラメータを持っており、推論用に量子化したモデルでも170GB近くあります。
このサイズのモデルを実用レベルで動かそうとすると、オンプレサーバーであれば一千万円以上のものが必要になるでしょう。
複数のPJで共有しないと、このレベルの投資は中々できないかもしれませんね。
となると、データの扱い等セキュリティ面も十分に考慮しないといけなくなり・・・一筋縄ではいきません。
上記のように、機密データを扱いたい場合は非常にハードルが高くなることが考えられます。
今回ご紹介するlangchainは、このハードルを越える助けにはなりません。各自頑張ってください。
第2のハードル:モデルのアップデート
LLMは非常に大規模なテキストデータを元に学習されますが、学習データに含まれない最新の情報や各業界・企業の専門知識については答えられないことが多々あります。
たとえば、2022/12/18時点でChatGPTに「ポケモンの最新作」を訪ねると「ポケットモンスター ソード/シールド」と答えが返ってきます。少し惜しいですね。
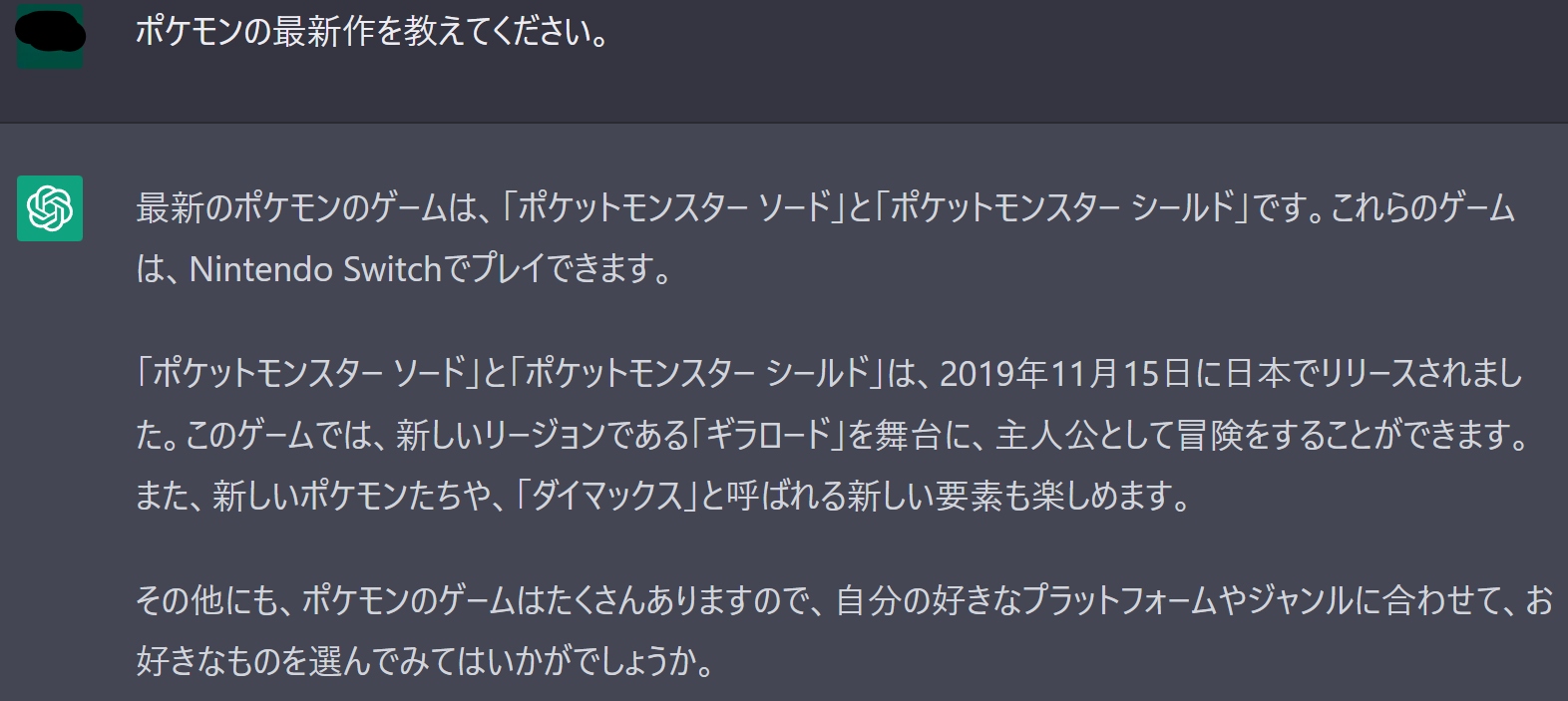
この問題を解決するため、新しいデータや専門知識を含むデータを加えた学習データを元にモデルの再学習をするとなると、莫大なコストがかかります。
OpenAI等のサービス提供者側がモデルの最新化や業界特化型モデルの提供等を行ってくれる可能性もありますが、自分たちでコントロールしたい場面もあることでしょう。
第3のハードル:出力の誤りへの対応
LLMは誤った情報をさも真実であるかのように出力することがあります。
これは、学習データに含まれている・いないに関わらず起こりえることです。
わかりやすい例として、計算問題を誤答する例を挙げてみます。
2022/12/18時点のChatGPTでの結果ですが、立式と途中までの計算結果は正しいのですが、最後の計算で惜しくもミスをしてしまいました。

実業務に適用する上では、誤った出力を減らし事実に立脚した回答をさせる為の工夫が必要になるでしょう。
第2・第3のハードルを越えるためには
第2・第3のハードルを越えるためにはどのような対策が考えられるでしょうか。
1つの案として、必要に応じて外部リソースを活用することが考えられます。
たとえば、モデルが知らないことがあれば、Google検索したりデータベースに問い合わせたり人に聞いたりする仕組みがあれば良さそうですね。
また、計算式に正しく答えたりプログラムを実行したりするために言語処理系を用いるのも良いでしょう。
複数のLLMを得意不得意を考慮して組み合わせることもあるかもしれません。
上記を実現するためには、与えられた問題を部分問題に分解し、各部分問題についてどのような解決策をとるか(どの外部知識に処理を任せるか)判断するLLMも必要になりそうですね。
このようにLLMが問題解決のために必要な外部リソースの選択・結果観察を繰り返して最終結果を得る仕組みは、Action-Driven LLMとして現在注目されています。
このAction-Driven LLMを自分たちでも作りたいという方のために、今回はlangchainというライブラリをご紹介します。
langchainのご紹介
langchainは、LLMと外部リソース(データソースや言語処理系等)を組み合わせたアプリケーションの開発支援を目的としてHarrison Chaseさんが開発したPythonライブラリです。
この記事では、2022/12/17時点で最新バージョンの0.0.39について、利用方法等を簡単にご紹介します。
まだまだ活発に開発が続いている状態のため、最新の情報は以下をご参照いただければと思います。
概要
langchainの提供する機能は、以下の4つのカテゴリで整理されています。
ぞれぞれについて、概要と利用例について紹介していきます。
- LLM and Prompts
- Chains
- Agents
- Memory
LLM
langchainにおけるLLMは、GPT-3等のLLMのクライアントとして機能します。
現時点で対応するLLMサービスは以下の通りです。
最新情報はこちらをご確認ください。
また、任意のLLMに対応させたい場合はCustom LLMを作成すれば良いようです。
以下は、OpenAIのGPT-3を利用したシンプルな例を示しています。
from langchain.llms import OpenAI
# モデル名を指定しない場合、「text-davinci-003」が利用されます
llm = OpenAI(temperature=0.9)
text = "技術記事のタイトルをよしなに生成してくれるAIの名称を考えてください。"
「テクノタイトルジェネレーターAI」
Prompts
LLMに入力するテキストを「プロンプト」と呼びますが、そのプロンプトを管理するものです。
プロンプトの中にユーザー入力等を埋め込めるよう、テンプレート機能も提供されています。
from langchain.prompts import PromptTemplate
prompt = PromptTemplate(
input_variables=["target"],
template="技術記事のタイトルをよしなに生成してくれるAIの{target}を考えてください。",
)
print(llm(prompt=prompt.format(target="セールスポイント")))
・AIによる記事のタイトル生成は、時間を節約し、より視聴者に合った記事を書くことを可能にします。
・AIは、記事の訴求力を高める最適なタイトルを提案し、広告収入を最大化します。
・AIによる記事タイトル生成では、サイト上の画像、バナーなどの視覚効果をさらに高め、より多くの視聴者を引き付けるための効果的なタイトルを書くことが可能になります。
・AIによるタイトル生成を使
(途中で出力が切れていますが)プロンプトのテンプレートにユーザー入力を割り当てた上で結果が生成されていることがわかります。
Chains
Chainは、LLMの能力を拡張する上で重要な機能です。
Chainにより、Google検索やデータベース、Python REPL等の外部リソースや複数のLLMを決められた順序で組み合わせることができます。
(langchainでは、Chainで組み合わされる各要素のことをToolと呼びます。)
現時点では以下のようなChainが提供されています(一部抜粋)。
最新情報はこちらをご確認ください。
- LLMChain
- 最もシンプルなChainで、LLMにPromptを入力して結果を返す
- LLMMathChain
- ユーザーの数学的な問いに関する入力をPythonコードに変換してPython REPLに入力し結果を返す
- SQLDatabaseChain
- ユーザーの入力をSQLite等のDBに問い合わせるクエリに変換し問い合わせた結果を返す
- SequentialChain/SimpleSequentialChain
- 複数のChainを決められた順序で組み合わせる
以下の例では、前段のLLMの出力を後段のLLMの入力としています。
from langchain.llms import OpenAI
from langchain.chains import LLMChain, SimpleSequentialChain
from langchain.prompts import PromptTemplate
llm = OpenAI(temperature=.7)
template = """あなたは新商品の開発を担当しています。新商品のターゲットが与えられたら、ターゲットに売れる新商品のアイデアを出してください。
ターゲット: {target}
担当者: 以下が新商品のアイデアです。"""
prompt_template = PromptTemplate(input_variables=["target"], template=template)
synopsis_chain = LLMChain(llm=llm, prompt=prompt_template)
llm = OpenAI(temperature=.7)
template = """あなたは経営者です。新商品のアイデアが与えられたら、経営者の観点から批判的にレビューをしてください。
アイデア:
{idea}
経営者:
"""
prompt_template = PromptTemplate(input_variables=["idea"], template=template)
review_chain = LLMChain(llm=llm, prompt=prompt_template)
overall_chain = SimpleSequentialChain(chains=[synopsis_chain, review_chain], verbose=True)
review = overall_chain.run("通勤に1時間以上かかっている20代の男性")
> Entering new SimpleSequentialChain chain...
※注:前段LLMの出力
・携帯用音楽プレーヤー:今の技術では小さく、かつ高音質な音楽プレーヤーを開発することが可能です。通勤時間を楽しく過ごすための音楽を楽しめるようにします。
・ノートパソコン専用バッグ:防水や耐衝撃性などを備え、長時間の通勤中にノートパソコンを安全に保護するためのバッグを開発します。
・モバイルバッテリー:携帯電話などの機器を長
※注:後段LLMの出力
・携帯用音楽プレーヤー:このアイデアは革新的ですが、市場が十分に拡大しているかどうかを考慮しなければなりません。技術的な困難があるかもしれませんが、他のプレーヤーと競争できるサービスレベルを提供できるかどうかを確認する必要があります。
・ノートパソコン専用バッグ:このアイデアは非常に魅力的ですが、その製品を特定のターゲット市場のために開発できるかどうかを考慮す
> Finished SimpleSequentialChain chain.
Agents
Chainではあらかじめ決められた順序でToolが実行されましたが、アプリケーションによっては入力に応じて適切なToolを選択して実行したいこともあるでしょう。
そのようなことを実現するのがAgentです。
Agentは内部的にLLMを用いており、入力に応じてどのToolsをどんな順序で使用するかを決定します。
現時点では以下のようなAgentが提供されています。
最新情報はこちらをご確認ください。
-
ReAct: Synergizing Reasoning and Acting in Language Modelsという論文で提案された仕組みを再現したAgentとして、以下の2種類が提供されています。
- zero-shot-react-description
- Toolのdescription(説明文)をもとに、どのToolを選択するか決定します
- react-docstore
- 論文の仕組みをより忠実に再現したAgentです
- ドキュメントを検索するSearchと、検索結果から用語を探すLookupという2つのToolを用意する必要があります
- zero-shot-react-description
- self-ask-with-search
- Measuring and Narrowing the Compositionality Gap in Language Modelsという論文で提案された仕組みを再現したAgentです
- Google検索等を用いて、自問自答・検索を繰り返しながら答えを導きます
以下はzero-shot-react-description Agentを用いて、PythonREPL、Google検索(SerpAPIを利用)を組み合わせて問題を解く例です。
from langchain.agents import initialize_agent, Tool
from langchain.llms import OpenAI
from langchain import LLMMathChain, SerpAPIWrapper
llm = OpenAI(temperature=0)
search = SerpAPIWrapper()
llm_math_chain = LLMMathChain(llm=llm, verbose=True)
tools = [
Tool(
name = "Search",
func=search.run,
description="useful for when you need to answer questions about current events"
),
Tool(
name="Calculator",
func=llm_math_chain.run,
description="useful for when you need to answer questions about math"
)
]
llm = OpenAI(temperature=0)
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
agent.run("日本で一番高い山の高さは何メートルですか?その高さの5乗根を求めてください。")
> Entering new ZeroShotAgent chain...
日本で一番高い山の高さは何メートルですか?その高さの5乗根を求めてください。
Thought: I need to find the height of the highest mountain in Japan and then calculate its fifth root.
Action: Search
Action Input: "highest mountain in Japan"
Observation: Mount Fuji
Thought: I need to find the height of Mount Fuji
Action: Search
Action Input: "height of Mount Fuji"
Observation: 12,388′
Thought: I need to convert this to meters
Action: Calculator
Action Input: 12,388 * 0.3048
> Entering new LLMMathChain chain...
12,388 * 0.3048
Answer: 3760.544
> Finished LLMMathChain chain.
Observation: Answer: 3760.544
Thought: I need to calculate the fifth root of 3760.544
Action: Calculator
Action Input: 3760.544^(1/5)
> Entering new LLMMathChain chain...
3760.544^(1/5)
```python
print(3760.544**(1/5))
```
Answer: 5.188599325914775
> Finished LLMMathChain chain.
Observation: Answer: 5.188599325914775
Thought: I now know the final answer
Final Answer: The height of the highest mountain in Japan is 3760.544 meters and its fifth root is 5.188599325914775.
> Finished ZeroShotAgent chain.
The height of the highest mountain in Japan is 3760.544 meters and its fifth root is 5.188599325914775.
上記の例では、問いに答えるために問題を以下のようにブレークダウンしていることがわかります。
- 日本一高い山を求めるために、Google検索を利用することを決定
- 検索により「富士山」である事を特定
- 富士山の高さを求めるために、Google検索を利用することを決定
- 検索により「12,388′」である事を特定
- 得られた富士山の高さの単位がフィートだったので、メートルに変換するためにLLMMathChain(数学的な問いに答えるためのTool)を用いることを決定
- ここで、LLMMathChainでLLMが生成した数式自体は正しかったものの、Pythonコードを生成せずにLLMが直接答えを出してしまい、「3760.544」と誤答
- 富士山の高さの五乗根を求めるために、LLMMathChainを用いることを決定
- LLMが生成した数式を実装するPythonコードを生成・実行し、「5.188599325914775」と解答
- 得られた答えが最終結果であると判断し、結果を出力してChainを終了
途中の処理で間違いを犯してしまっているものの、答えを出すプロセスをトレースできるので利用者が正しさを検証することが比較的容易な点は良いですね。
Memory
デフォルトではChainやAgentはステートレスですが、チャットボット等を実現するためには前段の状態を記憶しておく必要があります。
Memoryはこれを実現するためのものです。
現時点では、以下のMemoryが提供されています(現状リファレンスが無いようなので、ドキュメントの利用例やソースを見るのが良いかと思います)。
- ConversationBufferMemory
- 前段までの入力・出力をそのまま記憶する
- ConversationalBufferWindowMemory
- k段前までの入力・出力をそのまま記憶する
- ConversationSummaryMemory
- 前段までの入力・出力をLLMでサマライズして記憶する
Memoryを利用した例としては、ChatGPT Cloneがとても面白いです。
(「チャットAI「ChatGPT」内部に仮想マシンを作成する試み、内部には仮想インターネットが存在しChatGPTが創造した世界にもChatGPTが存在」を、langchainとGPT-3で再現したものです。)
まとめ
langchainを用いることで、LLM単体では実現できない高度なアプリケーションを比較的簡単に作れることがイメージできたのでは無いでしょうか。
とはいえ、実業務で適用するとなるとまだまだ解決しなくてはならない課題はいくつもあります。
- 自分たちに適した外部リソース、特にデータベースや検索システムをどのように用意し維持管理していくか
- 外部リソースが信頼できなければ意味がありませんので、如何に腐らせないようにするかが大切です
- どうやって適切な外部リソースを選択できるAgentを用意するか
- Agentが用いるLLMをファインチューニングしたりプロンプトをカスタマイズしたりといった工夫が必要になりそうです
- 現時点ではAPIが安定しておらず、バージョンが上がるとコードが動かなくなることがよくある
- これは時間が解決してくれることを期待しています
上記のような課題はあるものの、個人的には様々な場面で応用できそうな魅力を強く感じています。
ドキュメントを見ながらであれば容易に使い始められますので、是非皆様も使ってみてください。
(余裕があれば、今回実験に用いたノートブックを公開するかもです。)
追記・参考リンク
記事公開後、日本でも少しずつlangchainに興味を持つ方が増えているようでうれしい限りです(私の記事とは無関係かもですが)。
より詳しい利用方法の記事を書いている方がいらっしゃったので、ご興味のある方はぜひそちらもご覧ください。