International Joint Conferences on Artificial Intelligence (IJCAI) 2015でアリババが開いた、再購入者の予測のコンペの話。データはTmall.comの行動ログ、2014年のDouble 11(Double 11 というのは11/11で全て1の日で大規模なプロモーション&セールが行われているらしい)の前後のデータ。Double11当日から過去6ヶ月のデータを学習データとして、Double11で購入を行ったユーザが6ヶ月以内に同一店舗で再購入を行うかどうかの予測を行う。
コンペはStage1とStage2があり、筆者らはこのコンペのStage1で優勝している。
論文の内容としては手法の話よりも、特徴量の作り方にフォーカスしている。
特徴量作成はドメイン知識が重要だけど、ECでの予測なら参考になりそうと思い読んでみた。
図は全てLiu,2016,Repeat Buyer Prediction for E-Commerce,KDD2016からの引用です。
Feature engineering
大きく分けて5種類の特徴量を作成している
- count/ratio
- aggregation
- recent activity
- complex feature
- age/gender related
count/ratioは単純な回数や比率。aggregationはユーザや店舗の単位で集約して平均や分散などにしたもの。complex featureは、あまりとりとめなく色んな物が含まれている。
これらの特徴量を次のID単位で特徴量を作成している。組み合わせで算出するものもあるので、交互作用も含まれている
- ユーザ
- ブランド
- カテゴリ
- 店舗
- アイテム属性
- ユーザ x ブランド
- ユーザ x カテゴリ
- 店舗 x ブランド
- 店舗 x カテゴリ
- ユーザ x 店舗
例えば、ユーザID単位でアイテム閲覧数をcountする、といった様に特徴量を計算しているとイメージしやすいと思う。
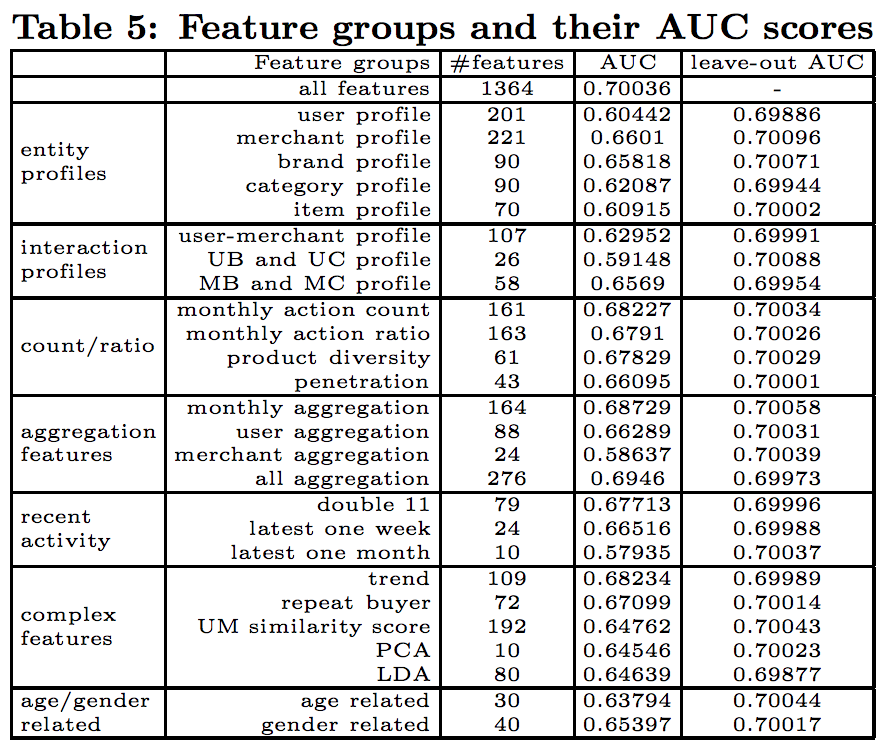
特徴量の種類と、ID単位の組み合わせは、論文中の以下の表で表されている。

本文中にはユーザ x 店舗の交互作用が最も重要だったと書いてあるが、予測タスクがユーザが同一店舗で再購入するかどうかなので、納得感はある。
以下は論文中で述べられている特徴量。
作り方しか述べられていないが、以下の作り方を組み合わせで全て実行すると、1364個の特徴量ができる。
Count/ratio features
Action count
月別の総数と、6ヶ月間の総数。
カウントの対象はクリック、購入、お気に入り登録の3種類。
行動ログとしてはカートへの追加もあるが、データ数が少ないのでクリックとまとめたと書いてある。
Action ratio
クリック/購入/お気に入りの月別の比率と、6ヶ月間トータルでの比率。
(click,purchase,add-to-favorite)=(12,2,2)だったら、clickの比率は12/(12+2+2)=0.75
期間に対する分散ではなく、該当期間の行動の比重がどこが大きいかを表している。
day count
月別と6ヶ月間のアクションが発生した月毎の日数と、6ヶ月間トータルの日数。
日数を使うのは、同じ日に10アイテム購入する顧客と、10日に分けて購入をする顧客は違いがあるからとのこと。
後の検証結果を見ると、日数を使った特徴量の重要度は高めだけど、この単純なカウントではなくて後に出てくる集約した結果の方が重要。
Product diversity features
クリック/購入/お気に入り登録したユニークなアイテム、ブランド、カテゴリを月別、6ヶ月間トータルでそれぞれカウント
検証結果を見ると重要度は高め。特にクリックは重要
Penetration features
アイテム、店舗、ブランド毎に購入したユーザ数
結果を見たところ、そこまで重要な要素では無さそう
Aggregation features
Monthly aggregation features
月ごとのアクション数、日数、商品数の平均、標準偏差、最大値、中央値
User aggregation features
店舗、ブランド、カテゴリ、店舗xブランド、店舗xカテゴリそれぞれに対して特徴量を作成する際に利用。
例えば以下の様な特徴量を作成する。
店舗のuser-purchase-day-aggregation features:対象店舗で購入したユーザ数、もしくは日にちの平均、標準偏差、最大値、中央値
店舗のUser-purchase-item-aggregation features:対象店舗で各ユーザが購入したアイテム数の平均、標準偏差、最大値、中央値
要はgroup byして計算する様な指標。
Merchant aggregation features
例)
merchant-purchase-day-aggregation:1ユーザ以上が購入している店舗に対する、それぞれの店舗で購入を行った日数のカウントし、平均、標準偏差、最大値、中央値
Merchant-purchase-item-aggregation:対象の店舗で購入したユニークなアイテム数の平均、標準偏差、最大値、中央値
Recent activity features
Double 11 features
Double11の日のクリック、購入、お気に入りの数と比率。比率の計算方法は全期間のアクションの内、Double11に発生するアクションの比率を使う。比率が高い場合、バーゲンハンターということになる
Latest one-week features and latest one-month features
1週間前と1ヶ月前のクリック、購入、お気に入りのカウントと比率
Complex features
Trend features
月ごとにカウントした結果を $y=(y_1, y_2,...,y_7)$ として、以下の数式で線形の傾きを求め特徴量とする。
\alpha = \frac{n\sum_{i=1}^{n}(x_iy_i)-\sum_{i=1}^{n}(x_i)\sum_{i=1}^{n}(y_i)}{\sum_{i=1}^{n}(x_i^2)-(\sum_{i=1}^{n}(x_i))^2} \\
n=7, x_i=i
Repeat buyer features
Double11以前にそもそも繰り返し購入を行うユーザかどうかを算出している。
例)
Repeat buyer number:繰り返し購入(2度異なる日に購入)したユーザ数
Repeat buyer ratio:繰り返し購入しないユーザも含めた全ユーザに対する、繰り返し購入したユーザの比率
これをアイテム、ブランド、カテゴリ、店舗毎に算出する。
店舗xブランドなどの繰り返し購入の場合は、店舗・両方の組み合わせが一致する繰り返し購入を対象に計算。
後の検証結果を見たところ、重要度は高い
Market share features
ブランドやカテゴリに対して、各店舗でどれだけ購入が発生しているかの重要度や、店舗に対して、各ブランド/カテゴリがどれ位購入が発生しているか
User-merchant similarity features
ブランド、もしくはカテゴリに基づく類似度。前述のmarket share featuresを使う。
例えば、ブランドを元に類似度を計算する場合、店舗の持つブランドシェアのベクトルと、ユーザの持つクリック/購入/お気に入り登録のベクトルを掛けあわせて類似度とする。
例)
店舗のブランドのマーケットシェアベクトル= (0.1, 0.2, 0.05,0.3, 0.01)
ユーザの各ブランドの購入回数ベクトル=(0, 1, 2, 0, 2)
類似度 = 0.1 × 0 + 0.2 × 1 + 0.05 × 2 + 0.3 × 0 + 0.01 × 2 = 0.32
PCA features
店舗間の類似度を用いて計算。
店舗間の類似度は、両店舗で購入を行ったユーザ数から算出する。
上位10変数を店舗の特徴量としている。
検証結果を見たところ重要度は低そう。
LDA features
ユーザをドキュメント、店舗を単語とみなして実施。ユーザの行動ログに現れる店舗を単語扱い。
トピックの分布をユーザの特徴量にする。
同様に、ユーザと店舗を逆にして店舗の特徴量も作成。
パフォーマンスを見てトピック数は40にした。
こちらも検証結果上は重要度が低そう。
Age/gender related features
count/monthly aggregation/penetration feature/repeat buyerなどのユーザに基づく特徴量を、年代と性別に分けて算出して特徴量としている。
集計単位をユーザ単位から性年代で切り直して集計しているだけ。
結果をみたところ重要そう。特に性別による違いが効いているみたい
モデルによる違い
XGBoostが提供する特徴量ランキングを掲載している。他の手法も試したが、だいたい同じ順位だった
比較手法
- Factorization Machine
- Logistic Regression
- Random Forest
- GBM
- XGBoost
- 上記5つの結果を重み付け平均したblending model $p(u,m)=\sum w_i \times p_i(u,m)$

AUCは単体のモデルならXGBoostがベスト。
blending modelはXGBoostよりも少しAUCが高いが、ほとんど変わらない。
blending modelのアンサンブル学習で使用する各モデルのスコアの重みは、AUCの値に応じて恣意的に割り振ったものと、k個のモデルの重みを説明変数にして最適化した2つの方法を試した。
コンペでは、AUCから恣意的に振ったものの方が成績が良かった。
XGBoostのパラメータ設定も書いてあった
eta=0.04, nrounds=400, max.depth=7, min child weight=200, and subsample=0.8
グループ毎の特徴量の重要度
5-foldのクロスバリデーションで評価。
特徴量のグループ(countとかaggregateとかの単位)で評価。グループ単体で評価した結果(AUC)と、そのグループを除外した場合の結果(leave-out AUC)を出す。AUCは高いほうが良くて、leave-out AUCはall-featuresより下がらない方がいい。
ユーザ毎の特徴量は単体だとAUCが低いが、除いた時のleave-out AUCの下がり幅が大きい。なので重要。
店舗xブランド、店舗xカテゴリも重要。
グループ単体を使う場合だとaggregationが最も良い。1グループで276変数もあるからなのではという気もするけど、後から出てくる特徴量単体の重要度でもaggregationの特徴量は上位に来ているので、実際重要なんだと思う。
LDAはleave-out AUCの下がり幅が最も大きいので、他の属性で代替できていないといえる。
店舗の属性は抜いた方が精度が良いので、入れなくても良さそう・・・。
各特徴量の重要度
こっから先はXGBoostの算出した特徴量のランク。5foldの平均で評価。
なぜか特徴量の種別毎のprofile ranking と、1364変数全体で見た時のglobal rankingがある。
global rankだけでいい気がするけど、profile rankingの必要性が分からない。そのせいでグラフ・表とのにらめっこ・・・。
重要度のTop20を見ると、以下の3つが2/3を占める
- user aggregation (7 features)
- repeat buyer (3 features)
- product diversity (3 features)
対して、以下の特徴量はTop20に入ってこない
- monthly action ratio
- double11
- latest-one-week
- latest-one-month
- penetration
- PCA
- LDA
前述のグループごとの特徴量の評価と多少順位が前後するが、概ね一致しているように見える。
上記はグループ単位での評価なので、個々の特徴量の重要度は以下の表の通り。
論文ではglobal rankの順で完全に並んでいないので、並べ直した。
変数の内容に書いてある対象○○は、特徴量を算出する対象となる属性を表している。profileの項目と一致する。
| global rank | profile | type | 変数の内容 |
|---|---|---|---|
| 1 | merchant | user aggregation & gender related | ある性別のユーザが、対象店舗で購入を行った日数の標準偏差 |
| 2 | user-merchant | product diversity | 対象ユーザが、対象店舗でクリックされたユニークアイテム数 |
| 3 | merchant-brand | user aggregation | 特定の性別のユーザが、対象店舗で対象ブランドの購入を行った日数の標準偏差 |
| 4 | merchant-brand | repeat buyer | 対象店舗で対象ブランドの再購入が行われた日数の比率 |
| 5 | user-merchant | trend | 対象ユーザが対象店舗にてアイテムクリック数の分散 |
| 6 | merchant-brand | user aggregation | 対象店舗で対象ブランドが購入された日数の平均 |
| 7 | user-merchant | overall action count | 対象ユーザが対象店舗から購入した回数 |
| 8 | user-merchant | pdoruct diversity | 対象ユーザが対象店舗でクリックしたカテゴリのユニーク数 |
| 9 | merchant | user aggregation & gender related | 対象店舗でアイテムを購入した日数を性別毎に集約して平均を取る |
| 10 | merchant-category | user aggregation | ユーザが対象店舗から対象カテゴリを購入した平均日数 |
| 11 | merchant | repeat buyer & age related | 対象店舗での特定の年代の再購入の比率 |
| 12 | merchant-category | user aggregation | 対象店舗で対象カテゴリの商品が購入された日数の性別ごとの値の標準偏差 |
| 13 | user | monthly aggregation | 対象ユーザがクリックした店舗数の月毎の値の標準偏差 |
| 14 | user-merchant | similarity score | 対象ユーザの購入ブランドと、対象店舗のブランドシェアから算出した、対象ユーザと対象店舗の類似度 |
| 15 | user-merchant | product diversity | 対象ユーザが対象店舗で購入したユニークアイテム数 |
| 16 | merchant-category | repeat buyer | 対象店舗で対象特定カテゴリを再購入した日数の比率 |
| 17 | category | user aggregation | ユーザが対象カテゴリの商品を購入した平均日数 |
| 18 | user | merchant-aggregation | 対象ユーザが店舗毎にクリックしたユニークアイテム数の平均 |
| 19 | user | merchant aggregation | 対象ユーザが店舗でクリックを行った日数の標準偏差 |
| 20 | user | product diversity | 対象ユーザが購入を行った店舗数÷ユーザが何らかのアクションを行った店舗数 |
和訳してみたけど、意味が分かりにくいので原文がオススメ。ただし、global rankの順に並んで無いから泣ける。