概要
Walmart LabsがWSDM2020で発表した論文
ECの場合はノイズやスパース性が高く、通常のKnowledge Graphではdawnstream taskで高い性能を出すことができない。著者らはword2vec, Transformerを模した構造や、Poincare Embeddingを用いたECに特化したKnowledge Graph Embeddingの手法を提案し、ECの実データにおいて既存手法よりも高い性能が出ることを示した。
論文はこちら:arXiv
新規性・差分
- product relation(complementやsubstituteなど)と、Product Knowledge Graph(PKG)を組み合わせた手法を提案した
- self-attention-based representationを採用し、検索行動などのユーザ行動とdescriptionなどの製品情報の両方から学習を行うend-to-endの方式を提案した。
- 現実のEC(grocery.walmart.comのデータ)のデータセットでknowledge completion, search ranking, recommendationのタスクを行い、提案手法の有用性を示した
手法
以下のrelationをKnowledge Graphで表現したものを、Product Knowledge Graphと呼んでいる。
| relation | 内容 |
|---|---|
| IsA | 商品が所属するカテゴリ |
| substitute | 商品Bが商品Aの代用品になること |
| complement | 商品Cが商品Aの付属品になること |
| co-view | 商品Aと商品Cが同じセッションで閲覧されること |
| search | 検索クエリの単語(図中だとLED、TV)が検索後に、商品を閲覧すること |
| describe | ある単語(図中だと4kやFULL HD)が商品のdesctiptionに記載されていること |
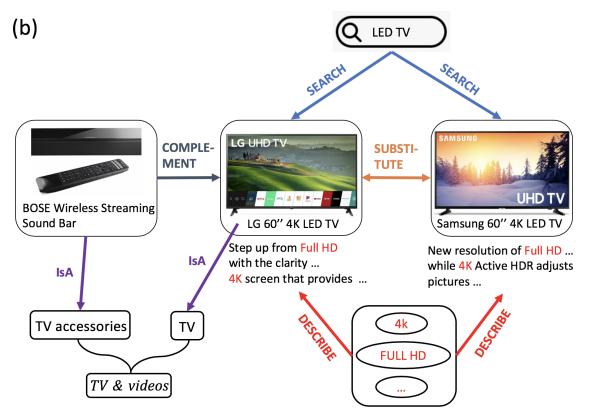
※Product Knowledge Graph Embedding for E-commerce より
Product Knowledge Graphも通常のKnowledge Graphと同じ様に(head entity, relation, tail entity)のtripletで表現できる。
例えば上記の図の内容は、以下の様に表せる。
| head entity | relation | tail entity |
|---|---|---|
| BOSE Wireless Streaming Sound Bar | IsA | TV accessories |
| LG 60" 4K LED TV | IsA | TV |
| LG 60" 4K LED TV | substitute | Sausung 60" 4K LED TV |
| BOSE Wireless Streaming Sound Bar | complement | LG 60" 4K LED TV |
| "LED", "TV" | search | LG 60" 4K LED TV |
| "LED", "TV" | search | Sausung 60" 4K LED TV |
| "4K", "FULL HD" | describe | LG 60" 4K LED TV |
| "4K", "FULL HD" | describe | Sausung 60" 4K LED TV |
また、提案手法ではcomplementの関係を複雑に分けていないため、アクセサリーも付属品も拡張もアドオンも全てcomplementになる。
- (Remote control, complement, TV): accessory
- (TV mount frame, complement, TV): structural attachment
- (Audio speaker, complement, TV): enhancement
- (HDMI Cable switcher, complement, TV): add-on
モデル構造
基本的にはword2vecのアナロジーとして考える。
word2vec(skip gram)の場合は、ある単語を入力し、その周辺単語の予測確率が高くなるように学習を行う。
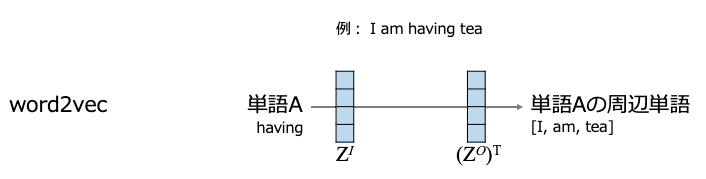
提案手法では6つのrelationをタスクとして扱う。
商品の入力ベクトルを各タスクで共有し、この入力ベクトルをMultitask Trainingで更新する。
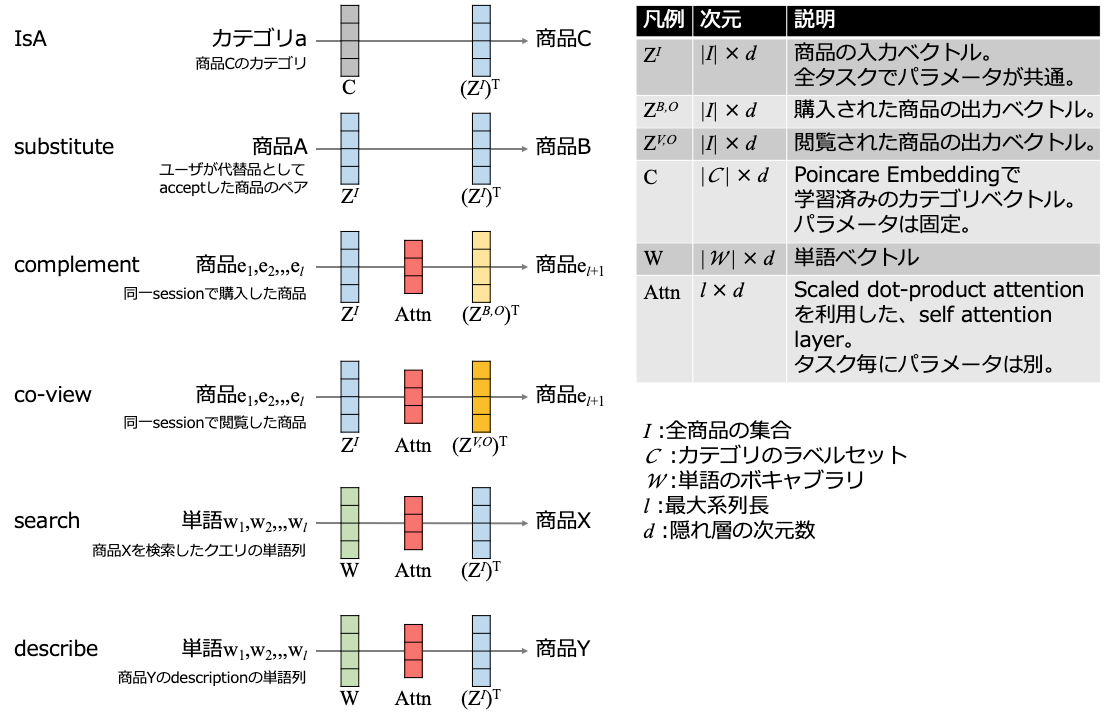
AttnはTransformerを模した構造になっており、Position EmbeddingとScaled dot-product attentionを利用している。そのため、Attnの入力となるsequenceの順序やアテンションが考慮されることになる。詳しい数式は論文を参照。
学習方法
Multitask Trainingを行う。
各学習エポックの後にタスクをランダムで選択し、そのタスク用の学習データのサンプリングしてバッチを作成する。タスクの選択は、各タスクのデータセットのサイズに比例した確率になるように行う。
このサンプリングと学習の繰り返しを、validationデータセットのhitting rateが上がらなくなるまで行う。
学習データはnegative samplingを用いる。
self attention layerの系列長は事前に分析した結果、それぞれ $l_{buy}=20, l_{view}=50, l_{describe}=200, l_{search}=10$ とした。
隠れ層のサイズは全て100。
実験&結果
grocery.walmart.comのデータを利用。
実験では、Knowledge completion、search ranking、recommendationの3つのタスクで評価を行う。
データセット
カテゴリ
カテゴリ構造は以下の通り。
9 super-departments → 28 departments → 228 categories → 1,198 subcategories
セッションデータ
views, purchases, search query(クエリ経由で商品がクリックされた場合のもの)をセッションとし、合計〜4千万セッションを用いる。
substitution(代用品データ)
商品が在庫切れの場合にユーザに代用品の推薦が行われ、ユーザはaccept or denyを選択する。データセットにはacceptされた約70,000商品が含まれている。
前処理
purchase, view, searched, substitutionの合計頻度が10以下のデータを削除する。削除後の商品は100,000商品以下になった。
description, search queryで合計頻度が10以下の単語も削除した。
Knowledge completion
Knowledge completionのテストでは、complement, co-view, substitute、IsAのタスクを対象に行う。
complement, co-view, substituteのテストはhead entityとrelationが与えられた場合に、tail entityを予測した結果を評価する。評価にはtop-10 hitting rate(HIT@10)とnormalized discounted cumulative gain(NDCG@10)を用いる。
IsA のテストは、商品の10%のcategoryとdepartmentをマスクし、マスクした内容を予測した結果を評価する。こちらはマルチクラス分類になるので、micro-F1とmacro-F1を用いて評価する。
下の表は3試行の平均を取ったもの。提案手法の性能が最も良いことが示されている。
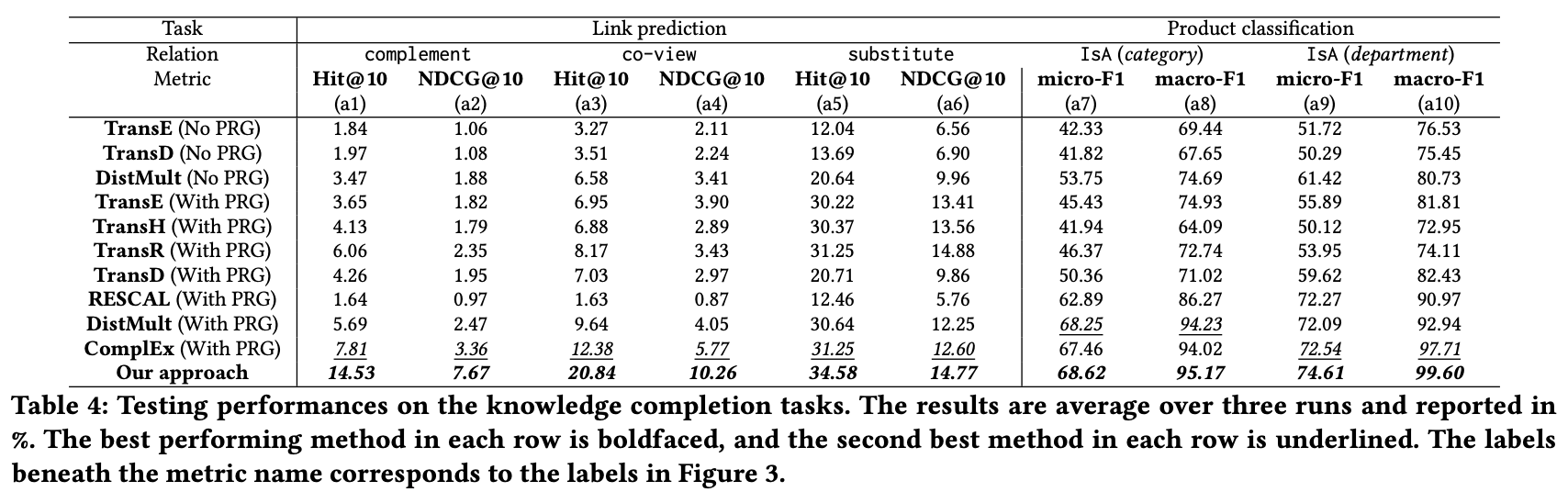
※Product Knowledge Graph Embedding for E-commerce より
baselineの手法にはProduct Relation Graph(PRG)を利用していないもの(No PRG)と利用しているもの(With PRG)を比較し、PRGの効果も併せて検証している。
No PRGは2商品間のrelation(complement, co-view, substitute)の頻度をエッジの重みとしたものを隣接行列とし、これをnormalizeしたものを用いる。
With PRGではnormalized隣接行列をbiased random walkで学習し、その後で各商品からtop-K=20のノードのみ残したグラフを用いる。
PRGの構築方法は"Inferring networks of substitutable and complementary products"を参照。
上記の表でNo PRGとWith PRGを比較すると、PRGを利用しているWith PRGの方が精度が高く、PRGはECのデータを対象にした際に精度向上に貢献している。しかし、PRGがあったとしても提案手法には及ばない。
transEなどのbaselineの手法についてはこちらが詳しかった。
Search ranking
Search rankingのテストは、searchのタスクを対象に行う。
テストはクエリを与えた時に、次にimpressionする商品を予測して実施する。評価に用いるクエリは、学習データに存在するクエリ(encountered queries)と、学習データに存在しないクエリ(new queries)の2パターンで行う。baseline手法の入力クエリは、各クエリ単語の埋め込みベクトルの平均を用いる。
評価指標はtop-10 recall(R@10)とmean average precision(MAP@10)
下の表は3試行の平均を取ったもの。提案手法の性能が最も良いことが示されている。
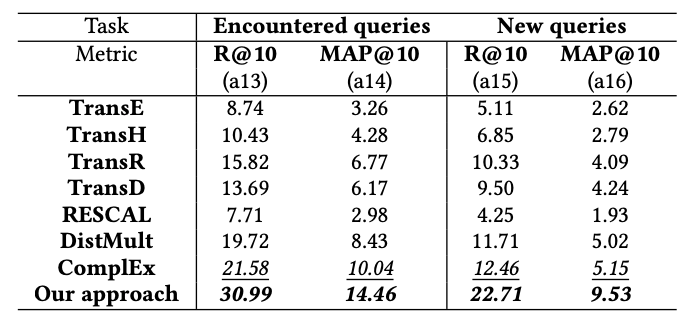
※Product Knowledge Graph Embedding for E-commerce より
recommendation
recommendationのテストは、$exp((Z^{B,O}_{t}+Z^{V,O}_{t})^TAttn)$ でスコアリングを行い評価を行う。complementとco-viewを足した様なモデルで学習と予測を行うことになる。
提案手法と、既存の手法(Factorication Machine(FM), Bayesian Personalized Ranking(BPR), Prod2Vec, Triple2Vec)を比較。
下の表は3試行の平均を取ったもの。提案手法の性能が最も良いことが示されている。

※Product Knowledge Graph Embedding for E-commerce より
Multitask Learningの効果
実験1
Multitask Learningの効果を確認するために2つの実験を実施。
1つ目の実験は、あるタスクの学習実施後に、学習が行われていないものも含めて各タスクのvalidationの精度の変化を確認。例えば、substituteのタスクの学習実施後に、complement, co-view, subsititute, IsA, searchの精度が学習前後でどの様に変化したのかを計測している。
これらを相関で表したものが下の表(行と列のどちらが学習前でどちらが学習後かは論文を読んでも分からず…)。
著者らは、a5(substitute)が他のタスクとの相関が高いため、substituteがMultitask Learningでも重要であると述べている。
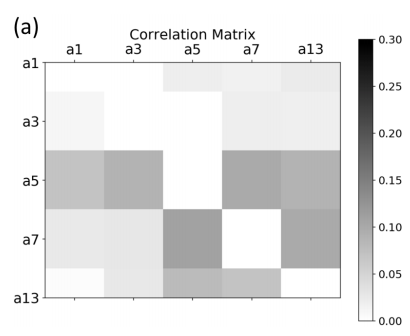
※Product Knowledge Graph Embedding for E-commerce より
| 凡例 | task | metric |
|---|---|---|
| a1 | complement | Hit@10 |
| a3 | co-view | Hit@10 |
| a5 | substitute | Hit@10 |
| a7 | IsA(category) | micro-F1 |
| a13 | search(encountered queries) | R@10 |
実験2
2つ目の実験は、以下の3つの学習タスク選択方法を比較する
| 凡例 | 内容 |
|---|---|
| proportion-sampling | 提案手法。タスクの選択確率はデータセットのサイズに比例する。 |
| single-task | テストを行うタスクでしか学習しない |
| uniform-sampling | Multitask learningを行うが、タスクの選択確率は一様分布で行う。 |
提案手法は全タスクにおいて精度が最も高い。
面白いのは、タスクによってsingle-taskとuniform-samplingで精度が良いものが変わる。
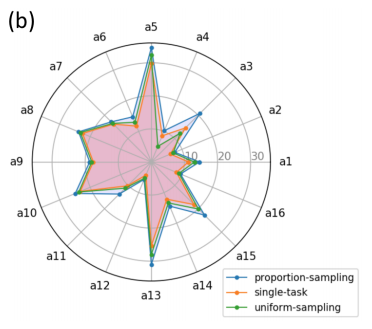
※Product Knowledge Graph Embedding for E-commerce より
| 凡例 | task | metric |
|---|---|---|
| a1 | complement | Hit@10 |
| a2 | complement | NDCG@10 |
| a3 | co-view | Hit@10 |
| a4 | co-view | NDCG@10 |
| a5 | substitute | Hit@10 |
| a6 | substitute | NDCG@10 |
| a7 | IsA(category) | micro-F1 |
| a8 | IsA(category) | macro-F1 |
| a9 | IsA(department) | micro-F1 |
| a10 | IsA(department) | macro-F1 |
| a11 | recommendation | Hit@10 |
| a12 | recommendation | NDCG@10 |
| a13 | search(encountered queries) | R@10 |
| a14 | search(encountered queries) | MAP@10 |
| a15 | search(new queries) | R@10 |
| a16 | search(new queries) | MAP@10 |
コメント
substituteのデータをユーザに確認する手順を挟んで集めているのでノイズは少ないが、実際に試そうとするとデータを集めるのが大変。
knowledge completionの定性評価を知りたかった。
実際に○○TVのcomplementやsubstituteの関係にある製品が直感的に納得感があるものが予測されるのか気になる。