はじめに
こんにちは、株式会社日立製作所の Lumada Data Science Lab. の渡邉です!
株式会社日立製作所(以下、日立)と日本オラクル株式会社(以下、オラクル)で3か月の協創プロジェクトを実施しました。
協創プロジェクトで実施した内容は以下の通りです!
- ユーザーの質問文から次のアクションをLLMに考えさせるAgentアーキテクチャの実装 (本記事Part 1で説明)
- めんどうなベクトル化処理不要!今ある業務DBに活用したいテキストデータを組み合わせるだけのOracle Database構築 (Part 2で説明)
- 自然言語からSQL文へ!便利なSelect AI機能とAI Vector Search機能 (本記事Part 3で説明)
このプロジェクトは以下のメンバーで、若手が中心になって進めました!
本記事もプロジェクトメンバー全員で執筆しています。
- 株式会社日立製作所 3年目データサイエンティスト 渡邉理沙
- 株式会社日立ソリューションズ・クリエイト 2年目データサイエンティスト 山口蓮
- 株式会社日立製作所 7年目オラクル製品担当エンジニア 野中一鴻
- 日本オラクル株式会社 4年目クラウドソリューションエンジニア 出口龍之介
- 日本オラクル株式会社 4年目クラウドソリューションエンジニア 宮本拓弥
LLMでの業務データ活用をテーマに、若手だけで協力してユースケース検討や実装を進め、僅か3カ月でプロジェクトを無事完了しました!
内容は、Part 1、Part 2、Part 3という、3部構成となっています。
この記事では、Part 3として、自然言語からSQL文を生成するためのSelect AI機能とAI Vector Search機能について説明します。
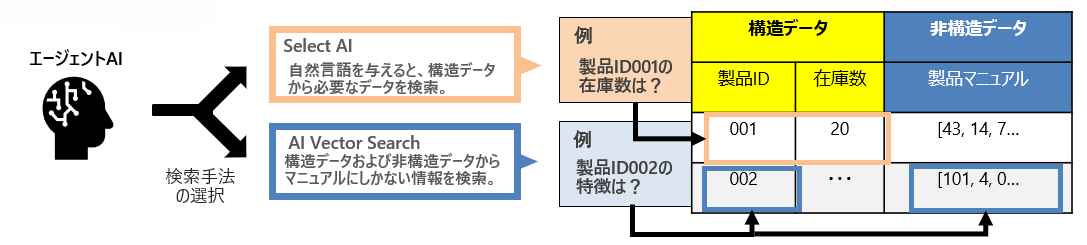
自然言語からSQL文へ!便利なSelect AI機能とAI Vector Search機能
今回の検証では自然言語からSQLを生成するため、Autonomous Databaseに実装されているSelect AIを使用しました。Select AIを簡単に説明すると、「LLMにスキーマのメタデータ(表名や列名)を教えておくことで、それらのデータに関する自然言語の質問に対して、表名や列名を使用したSQLを生成する」いわゆるText-to-SQLの機能です。
Select AIの基本的な使い方に関してはこちらをご参照ください。
Select AIでは使用するLLMにも多少左右されますが、WHERE句による絞り込みや複数表のJOIN、UNIONといった基本的なOracle SQL構文から、それらを組み合わせた複雑なSQLを生成させることができます。
しかしOracle AI Vector Searchでベクトル検索を実行するには、ORDER BY VECTOR_DISTANCE句を使用する必要があります。これは23aiの新機能ということもあり、LLMがまだ学習していないため、Select AIでは生成できませんでした。そこで今回の検証ではいくつか工夫を施すことで生成できるようにしました。
また今回の検証では、構造化データに対する質問と、製品マニュアル(非構造化データ)に関する質問の2つに回答できることをゴールとしていました。
上述のように非構造化データに対する質問では、Select AIに工夫が必要となったため、まずAgentによって質問が構造化データに対する質問なのか、非構造化データに対する質問なのか判断させ、それぞれのパターンによってチューニングを変えています。
構造化データに対する質問(AgentにSelect AIが選択された場合)
ここではAgentによって、Select AIを選択された場合のチューニングについて説明します。
つまり、構造化データに対するSQLクエリを生成し、SQL検索をすべきと判断された場合になります。
例えば、以下のような質問を想定しています。
① 製品CV-SP900_300Lの現在の販売価格はいくらですか?
② 大阪拠点で最も引当可能な在庫が多い製品とその在庫数を教えてください。
①の質問の場合、PRODUCT_NAMEとPRICE列を両方持つPRODUCTS表からクエリすれば良いだけです。生成されるべきSQLは以下のようになります。
SELECT p."PRODUCT_NAME", p."PRICE"
FROM "IM_TEST"."PRODUCTS" p
WHERE p."PRODUCT_NAME" = 'CV-SP900_300L'
一方②の質問の場合、各表は正規化しているため、拠点情報を持つSITE表、製品情報を持つPRODUCTS表、在庫情報を持つSTOCK表の3つをJOINしてクエリする必要があります。実際のSQLは以下のようになります。
SELECT p."PRODUCT_NAME", p."PRODUCT_ID", ST."AVAILABLE_QUANTITY"
FROM "IM_TEST"."PRODUCTS" p
JOIN "IM_TEST"."STOCK" ST ON p."PRODUCT_ID" = ST."PRODUCT_ID"
JOIN "IM_TEST"."SITE" SI ON SI."SITE_ID" = ST."SITE_ID"
WHERE SI."SITE_NAME" = '大阪'
ORDER BY ST."AVAILABLE_QUANTITY" DESC
FETCH FIRST 1 ROWS ONLY;
Select AIではこのような複数表のJOINも生成できますが、似たような表が増えれば増えるほど、その精度は落ちる傾向にあります。そこで今回はあらかじめ各表をJOINした一元的なビューを作成し、そこからクエリするSQLを生成するよう設定しました。ここがチューニングポイントの1つ目です。
以下のようにMASTERビューを作成します。
CREATE VIEW MASTER AS
SELECT
P.PRODUCT_ID AS PRODUCT_ID,
S.SITE_ID AS SITE_ID,
P.CATEGORY_ID AS CATEGORY_ID,
P.PRODUCT_NAME AS PRODUCT_NAME,
S.SITE_NAME AS SITE_NAME,
C.CATEGORY_NAME AS CATEGORY_NAME,
P.PRICE AS PRICE,
ST.STOCK AS STOCK,
ST.RESERVED_QUANTITY AS RESERVED_QUANTITY,
ST.AVAILABLE_QUANTITY AS AVAILABLE_QUANTITY
FROM PRODUCTS P
JOIN STOCK ST ON P.PRODUCT_ID = ST.PRODUCT_ID
JOIN SITE S ON ST.SITE_ID = S.SITE_ID
JOIN CATEGORY C ON P.CATEGORY_ID = C.CATEGORY_ID;
次に、Select AIで使用するモデルについて説明します。これは、精度に最も大きく影響するといっても過言ではありません。
今回の検証では、OCI GenAIで提供されるモデルを使用するため、モデルの候補としては以下がありました。(2024/09時点)
- meta.llama-3-70b-instruct(デフォルト)
- cohere.command-r-16k
- cohere.command-r-plus
- cohere.command
- cohere.command-light
- meta.llama-2-70b-chat
なおSelect AIではその他OpenAI、Azure OpenAI Service、Google Gemini、Anthropic Claude等のモデルも使用できます。
今回OCI GenAIで提供される上記のモデルでいくつか試したところ、SQL生成においてはデフォルトのmeta.llama-3-70b-instructモデルが最も精度が出たため、これを採用しました。
ただしmeta.llama-3-70b-instructモデルは、日本語解釈能力がやや低かったため、後述のコメントによるチューニングは英語で記述しました。
Select AIでは、通常メタデータ(表名、列名)のみLLMに渡し、SQL生成させますが、これだけではどういったデータがその列に含まれているかLLMが解釈できないため、精度が低い傾向にあります。
そのため各表や列にコメントを付与し、その情報もLLMに渡すことで、SQL生成の精度を全体的に向上させることができます。ここがチューニングポイントの2つ目です。
具体的には以下のように、MASTERビューの各列に英語でコメントを付与しています。
COMMENT ON TABLE MASTER IS 'Contains information about products, products_category, site, stock and products_detail. Each product has a unique identifier and name.';
COMMENT ON COLUMN MASTER.PRODUCT_ID IS '製品コード。Example: 1 for CV-SP900_300L product.';
...
Select AIは「どのモデルを使って、どのスキーマの、どのオブジェクトに対するSQLを生成するか」という情報を登録するプロファイルを作成して、それをセットすることで実行できます。
以下のようにプロファイルの作成を行いました。
BEGIN
DBMS_CLOUD_AI.CREATE_PROFILE(
profile_name => 'GENAI_LLAMA3_MASTER',
attributes => '{"provider": "oci",
"credential_name": "Select AI_CRED",
"object_list": [{"owner": "IM_TEST", "name": "MASTER"}],
"model": "meta.llama-3-70b-instruct",
"comments": true,
"temperature": 0
}');
END;
/
なお"comments": "true"とすることで、先ほど付与したコメントもLLMに読み込ませることができます。
また"temperature": 0としていますが、これはLLMの回答のランダム性を制御するパラメータです。今回はSQL生成というタスクなので、できるだけ回答にブレが生じないようにするため、0と設定しています。
ここまでで準備は完了です。先ほどの質問に対するSQLの生成結果は以下のようになります。
質問: 製品CV-SP900_300Lの現在の販売価格はいくらですか?
AI Generated SQL:
SELECT DISTINCT m."PRODUCT_NAME", m."PRICE"
FROM "IM_TEST"."MASTER" m
WHERE m."PRODUCT_NAME" = 'CV-SP900_300L'
Output:
------------------------------------------------------------
製品CV-SP900_300Lの現在の販売価格は32,654円です。
質問: 大阪拠点で最も引当可能な在庫が多い製品とその在庫数を教えてください
AI Generated SQL:
SELECT DISTINCT m."PRODUCT_ID", m."PRODUCT_NAME", m."AVAILABLE_QUANTITY"
FROM "IM_TEST"."MASTER" m
WHERE m."SITE_NAME" = '大阪'
ORDER BY m."AVAILABLE_QUANTITY" DESC
FETCH FIRST 1 ROW ONLY
Output:
------------------------------------------------------------
大阪拠点で最も引当可能な在庫が多い製品は『PV-BH900SL』で、その引当可能な在庫数は278です。
なおこれは在庫数などのリアルタイムの更新がされていくような動的なデータに対しても、都度SQLを生成し実行するため、最新のデータを取得することができます。
製品マニュアル(非構造化データ)に関するデータをクエリする質問(AgentにAI Vector Searchが選択された場合)
ここではAgentによって、AI Vector Searchが選択された場合のチューニングについて説明します。
つまり、非構造化データに対するベクトル検索をすべきと判断された場合になります。
例えば以下のような質問を想定しています。
① 製品MRO-S7B_Mで肉や魚を上手に解凍するコツを教えてください
② 東京拠点の引当可能な在庫数が100個以下の冷蔵庫の製品の製品名と在庫数、脱臭機能があればその機能を説明して。
これらの質問に対しては、製品マニュアルのデータを含むPRODUCTS_DESC表からクエリする必要がありますが、PRODUCTS_DESC表には冷蔵庫や電子レンジといった家電製品のカテゴリ情報や、製品の価格情報がありません。SELECT AIでPRODUCTS_DESC表以外にもこれらのPRODUCTS表やCATEGORY表からもクエリできるようにするため、これらの表を結合したPRODUCTS_DETAILビューを作成しました。ここは構造化データに対する質問のときと同様、複数の表を結合させるよりも、大福帳のビューからクエリするよう設定した方が精度が出やすいという評価に基づいています。
また③の質問に関しては、PRODUCTS_DETAILビュー以外にも在庫情報を含むSTOCK表などからもクエリする必要があります。
以下のようにPRODUCTS_DESC表、PRODUCTS表、CATEGORY表を結合したPRODUCTS_DETAILビューを作成します。
CREATE VIEW PRODUCTS_DETAIL AS
SELECT
P.PRODUCT_ID AS PRODUCT_ID,
P.CATEGORY_ID AS CATEGORY_ID,
C.CATEGORY_NAME AS CATEGORY_NAME,
P.PRODUCT_NAME AS PRODUCT_NAME,
P.PRICE AS PRICE,
PD.DESC_CHUNK_ID AS DESC_CHUNK_ID,
PD.DESC_CHUNK AS DESC_CHUNK,
PD.DESC_VEC AS DESC_VEC
FROM PRODUCTS P
JOIN CATEGORY C ON P.CATEGORY_ID = C.CATEGORY_ID
JOIN PRODUCTS_DESC PD ON P.PRODUCT_ID = PD.PRODUCT_ID;
そして構造化データに対する質問のときと同様、このPRODUCTS_DETAILビューの各列にコメント付与していきます。
COMMENT ON TABLE PRODUCTS_DETAIL IS 'Contains information about the feature of each product. If specific product features or ambiguous information is input, this view should be queried.';
COMMENT ON COLUMN PRODUCTS_DETAIL.PRODUCT_ID IS 'Product code(ID). Unique product names for air conditioners, cleaners, and other home appliances.Example: 1 for CV-SP900_300L product. If needed to join with Stock table, join on this column';
...
続いて非構造化データに対する質問の際に使用するプロファイルを作成します。拠点情報を含むSITE表と在庫情報を含むSTOCK表については、PRODUCTS_DETAILビューと結合していないため、object_listに別途登録しています。
BEGIN
DBMS_CLOUD_AI.CREATE_PROFILE(
profile_name => 'GENAI_COHERE_COMMAND_R_VECTOR',
attributes => '{"provider": "oci",
"credential_name": "SELECTAI_CRED",
"object_list": [{"owner": "IM_TEST", "name": "PRODUCTS_DETAIL"}, {"owner": "IM_TEST", "name": "SITE"}, {"owner": "IM_TEST", "name": "STOCK"}],
"model": "cohere.command-r-16K",
"oci_apiformat" : "COHERE",
"comments": true,
"temperature": 0
}');
END;
/
この状態でSELECT AIを実行しても、ベクトル検索は使用してくれません。これはLLM側でAI Vector Searchのベクトル検索の構文を学習していないためです。正しく生成させるためには、プロンプト内で構文の使い方を教える必要があります。
そこで今回は以下のようにテンプレートとして、生成するべきSQL構文と、どのような質問に対して使用するかをLLM側にインプットします。ここはいわゆるプロンプトエンジニアリングの1つ、Few-shotと呼ばれるいくつかサンプルを提示することで、LLMに生成させるテクニックを使用しました。
以下がテンプレートです。使用するLLMがLlama3のため、英語で記述しています。
Please generate an SQL query to answer product description and feature-related questions. This query aims to search a vector database and extract the most relevant information.
The possible prompts fall into three main categories.
1. Question [Tell me about the functionality of product xxxx yyyy.]
For a prompt similar to this question, generate SQL as follows.
"SELECT DESC_CHUNK, DESC_CHUNK_ID, PRODUCT_ID
FROM PRODUCTS_DETAIL
WHERE PRODUCT_NAME = 'xxxx'
ORDER BY VECTOR_DISTANCE(DESC_VEC, query_vector)
FETCH FIRST 10 ROWS ONLY"
2. Question [Give me N(number) products like zzzz(home appliances) with category_name that have more than y(number) in stock at xxxx(city name in Japan) site.]
In addition to the PRODUCTS_DETAIL table, there are the STOCK table and the SITE table.
The STOCK table has columns SITE_ID, PRODUCT_ID, STOCK, RESERVED_QUANTITY, and AVAILABLE_QUANTITY.
The SITE table contains SITE_ID and SITE_NAME columns.
When information on stock is queried, the STOCK and PRODUCTS_DETAIL tables are joined on PRODUCT_ID.
When information on sites is queried, the STOCK and SITE tables are joined on SITE_ID.
The ROWS ONLY clause indicates how many rows to fetch. Fix this at 5 ROWS ONLY.
Be sure to use multi-vector similarity search in this case as well.
In this case, please generate SQL as follows.
"SELECT PD.PRODUCT_NAME, PD.PRODUCT_ID
FROM PRODUCTS_DETAIL PD
JOIN STOCK ST ON PD.PRODUCT_ID = ST.PRODUCT_ID
JOIN SITE SI ON ST.SITE_ID = SI.SITE_ID
WHERE ST.STOCK >= y
AND SI.SITE_NAME = 'xxxx'
AND PD.CATEGORY_NAME = 'zzzz'
ORDER BY VECTOR_DISTANCE(PD.DESC_VEC, query_vector)
FETCH FIRST N PARTITIONS BY PD.PRODUCT_ID, 5 ROWS ONLY"
このテンプレートを与えたうえで、再度同じ質問をしてみます。
質問: 製品MRO-S7B_Mで肉や魚を上手に解凍するコツを教えてください
AI Generated SQL:
SELECT DESC_CHUNK, DESC_CHUNK_ID, PRODUCT_ID
FROM PRODUCTS_DETAIL
WHERE PRODUCT_NAME = 'MRO-S7B_M'
ORDER BY VECTOR_DISTANCE(DESC_VEC, query_vector)
FETCH FIRST 10 ROWS ONLY
final_answer:
肉や魚を解凍するときは、ラップなどの包装を外し、発泡スチロール製のトレーにのせます。トレーがない場合は、クッキングシートやキッチンペーパーを敷き、その上にのせます。食品の分量は100~1000gを目安に、2個以上を同時に解凍するときは、同じ種類・大きさ・重さにそろえます。食品はテーブルプレートの中央に置きます。
質問: 東京拠点の引当可能な在庫数が100個以下の冷蔵庫の製品の製品名と在庫数、脱臭機能があればその機能を説明して。
AI Generated SQL:
SELECT PD.PRODUCT_NAME, PD.DESC_CHUNK, ST.AVAILABLE_QUANTITY
FROM PRODUCTS_DETAIL PD
JOIN STOCK ST ON PD.PRODUCT_ID = ST.PRODUCT_ID
JOIN SITE SI ON ST.SITE_ID = SI.SITE_ID
WHERE ST.AVAILABLE_QUANTITY <= 100
AND SI.SITE_NAME = '東京'
AND PD.CATEGORY_NAME = '冷蔵庫'
ORDER BY VECTOR_DISTANCE(PD.DESC_VEC, query_vector)
FETCH FIRST 5 PARTITIONS BY PD.PRODUCT_ID, 3 ROWS ONLY
final_answer:
製品名はR-27TVとR-WXC74Vです。在庫数はそれぞれ69個と46個です。脱臭機能はどちらの製品にも搭載されており、4種類の脱臭素材の組み合わせによって、硫黄系・窒素系・アルデヒド系・酸系の4大臭気を含む庫内の様々な匂いを脱臭します。
このように非構造化データである製品マニュアルの情報をクエリする質問に対しても回答を生成できました。
今回の検証では、全てのSQLをSELECT AIでLLMに生成させるというチャレンジをしましたが、完全ではないものの、ある程度の精度までは制御可能ということが分かりました。
もちろんアプリ側の実装でそれぞれのパターンごとに実行するSQLを定義しておけば精度は100%にできますが、実装のためのハードルを考えるとLLMをフルに活用する今回の実装方法も有用かと思います。
おわりに
本ユースケースを、Oracle Database、OCI、Agentアーキテクチャで実現し、複雑な質問を含めた回答精度として、最終的に以下のような結果が得られました。
| 結果 | 質問数 | 正 | 誤 | 正答率 |
|---|---|---|---|---|
| Agentによる検索方法(ツール)選択の正誤 | 33 | 33 | 0 | 100% |
| Select AIによるSQLクエリ生成の正誤 | 23 | 22 | 1 | 96% |
| AIVectorSearchによるSQLクエリ生成の正誤 | 10 | 5 | 5 | 50% |
| 最終的に得られた回答の正誤 | 33 | 27 | 6 | 82% |
本ユースケースにより、従来のベクトル検索のみのRAGアーキテクチャでは実現できない問合せが可能になりました。
例えば、「東京拠点の冷蔵庫の引当可能な在庫の合計を教えてください。」といった質問に対しても、ハルシネーションを起こすことなく「東京拠点の冷蔵庫の引当可能な在庫の合計は456個です。」といったような回答を得ることができます。
逆に「一人暮らしに向いている家電を教えてください」のような曖昧な質問には、適切に回答できませんでした。
また、「全拠点の在庫リストを出してください」という質問に対しては、SQLで取得した在庫リストを基に、生成AIが回答を作成します。
しかし、生成AIが出力できる情報量(トークン数)に上限があるため、その上限を超えると、在庫リストが要約されて返されてしまいます。
正確な在庫リストが回答されていなかったので、「誤」と判定しました。
この問題については、今後の課題として引き続き対応していきたいと思います。
感想
今回、オラクルと日立の協業プロジェクトに参加し、短期間で実装まで完了することができました。
このプロジェクトの技術的な革新性として、以下の3つが挙げられます。
- Agentアーキテクチャ実装により、構造化データ検索も非構造データ検索も選択可能になった
-
Select AIで自然言語からのSQL生成に成功した -
AI Vector Searchで、ベクトル型のデータ検索機能を実装できた
正直なところ、プロジェクト開始時は成果が出せるのか不安でした。
しかし、両社の強みが見事に噛み合うことで、迅速に実装が進みました。
例えば、1. については、日立のLLMに関する知識とプロジェクト経験が活きたと考えています。2.と3. については、オラクルのDatabase技術とその専門性が活きたと考えています。
このプロジェクトを通じて、企業間協業の真の価値を実感しました:
- 知識の相互補完: 両社の異なる専門分野が補完し合い、総合的な解決策を生み出せました。
- 若手同士のイノベーションの加速: 異なる視点と技術が交わることで、新しいアイデアが次々と生まれました。
このような素晴らしい機会を提供してくださった オラクルおよび日立の関係者の皆様に 心から感謝申し上げます。