スペクトラルクラスタリング
いい機会だし先日投稿したスペクトラルクラスタリングとやらを実際にやってみたいと思います。ソースコードは再生産しても仕方がないのですぐる様のブログからパクってお借りします。
すぐる様のブログにあったコードはそのままではうまく動作しなかったのと、Jupyter notebook のお作法に従って少しコードを手直ししています。(そのまま実行するとGraph is not fully connected, spectral embedding may not work as expected.というwarningが表示されました。このwarningに関してもGitHubのissueに素晴らしい回答があるのですが読むのが面倒臭かったので@taki__taki__様のブログよりスペクトラルクラスタリングの実行部分のコードを1行だけお借りしました。また、%matplotlib inlineはimport matplotlib.pyplot as pltより手前に書く必要があります)。
# 1:ライブラリのインポート--------------------------------
%matplotlib inline
import numpy as np #numpyという行列などを扱うライブラリを利用
import pandas as pd #pandasというデータ分析ライブラリを利用
import matplotlib.pyplot as plt #プロット用のライブラリを利用
from sklearn import cluster, preprocessing #機械学習用のライブラリを利用
from sklearn import datasets #使用するデータ
# 2:moon型のデータを読み込む--------------------------------
X,z = datasets.make_moons(n_samples=200, noise=0.05, random_state=0)
# 3:データの整形-------------------------------------------------------
sc=preprocessing.StandardScaler()
sc.fit(X)
X_norm=sc.transform(X)
# 4:プロットしてみる------------------------------------------
x=X_norm[:,0]
y=X_norm[:,1]
plt.figure(figsize=(10,10))
plt.subplot(3, 1, 1)
plt.scatter(x,y, c=z)
# 4:KMeansを実施---------------------------------
km=cluster.KMeans(n_clusters=2)
z_km=km.fit(X_norm)
# 5: 結果をプロット-----------------------------------------------
plt.subplot(3, 1, 2)
plt.scatter(x,y, c=z_km.labels_)
plt.scatter(z_km.cluster_centers_[:,0],z_km.cluster_centers_[:,1],s=250, marker='*',c='red')
# 解説6:SpectralClusteringを実施---------------------------------
km=cluster.SpectralClustering(n_clusters=2, eigen_solver='arpack', affinity='rbf', gamma=10.0)
# こちらはwarningが出る
# km=cluster.SpectralClustering(n_clusters=2, affinity="nearest_neighbors")
z_km=km.fit(X_norm)
# 7: 結果をプロット-----------------------------------------------
plt.subplot(3, 1, 3)
plt.scatter(x,y, c=z_km.labels_)
plt.show()
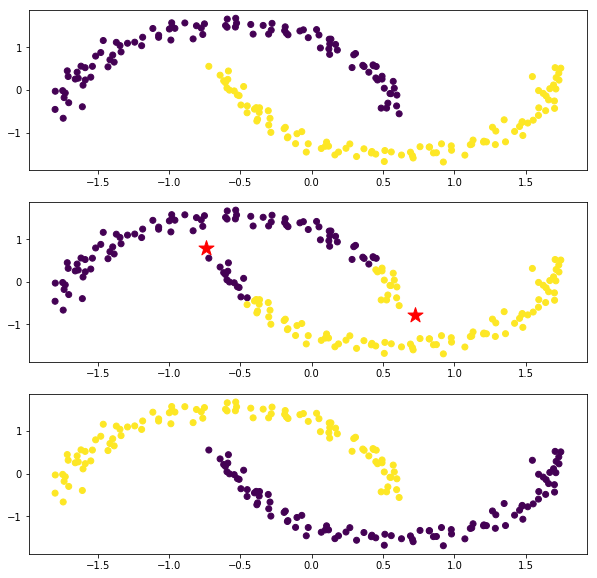
スゲェ。うまくいった(他人事)。k-meansは素直に実行すると各グループがユークリッド空間上でガウス分布している場合しかうまくいきません。今回の弧状の分布はどう見てもガウス分布じゃないのでk-meansはうまくいっていないようです。
一方でスペクトラルクラスタリングは以前に解説したように類似度行列を用いてグラフカット最小化を行うので、なるべくひとつながりになっているデータを同じグループとみなそうとします。今回のようなケースではうまくいく一方で、類似度行列で表現される空間における疑似的なつながりを拾ってしまうことがあります。
自前で実装しようとすると毎回地獄を見るんですがどんな地獄を見るかみなさまにもご覧に入れましょう。以前に解説した式を素直にそのまま実装してみましょうか。
from itertools import combinations_with_replacement
# ハイパーパラメータ。今回は上のコードと同じ10.0に設定
beta = 10.0
# グラム行列を計算
n_samples, n_features = X_norm.shape
K = np.zeros((n_samples, n_samples))
for i, j in combinations_with_replacement(range(n_samples), 2):
K[i][j] = np.exp(- beta * np.sum((X_norm[j] - X_norm[i])**2))
K[j][i] = K[i][j]
# グラフラプラシアンを計算
D = np.diag(np.sum(K, axis=1))
L = D - K
A = np.linalg.inv(D).dot(L)
eigvals, eigvecs = np.linalg.eig(A)
# とりあえず閾値を0に設定して分類
# eigvecs[0]は固有値0の意味のないベクトル
p = []
threshold = 0
for i in eigvecs[1]:
if i >= threshold:
p.append(0)
else:
p.append(1)
# 閾値以上と以下のどっちが0,1に対応するか不明なので両方のパターンを考える
p = np.array(p)
q = 1 - p
# 両方のパターンで confusion matrix を計算し、うまく分類できているか確かめる
from sklearn.metrics import confusion_matrix
print(confusion_matrix(z, p))
print(confusion_matrix(z, q))
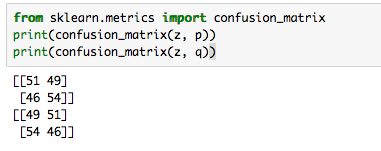
正答率50%くらい。2値分類問題なので適当に0か1って言っておけばそれくらいの正答率になりますよね。つまり全然うまくいってねぇ!クソッタレ!!

ああもうこうなってしまうとなんでうまくいかないのか原因究明のために2,3日は軽く吹き飛びます。で、原因究明してる暇ないです。ごめんなさい。sklearn様様です。
いつにも増してゴミ記事ですけどマジで実験レポート死にかかってて進級かかってるので勘弁してください。