概要
お手元のパソコンにAWS CLIとslackのwebhookがあれば、
3分程度でmp3の文字起こし環境が用意できるのでご紹介。
作った物
好きなmp3を用意して、S3にupload、
するとAmazon Transcribeで文字に起こした物がslackに飛んでくる。というもの。

背景
私は絶望的に滑舌が悪く、最近社長に「聞き取りずらい」とよく言われます。
SoundOnlyで会話する機会が増えた昨今、致命的です。
なのでここ一ヶ月間「あ・え・い・う・え・お・あ・お」と、
鏡の前で発声練習を朝晩2回、歯磨きしながらやってます。
いつナレーションのオファーが来てもおかしくない状態に鍛え上げられ、
鏡がベチャベチャになった私は、社長から先日驚きのコメントをもらいました。
「聞き取りずらい」
そんなはずない、と判定を機械に委ねる事となったのです。
ということで、かなり前に日本語に対応したAmazon Transcribeを触ってみたました。
「私の滑舌は悪くない」そう誰かに言ってもらいたかったのです。
調べる
知見がない為、まずはAIサービスに詳しそうなりんなちゃんにきいてみます。
会話になりませんでした。
チュートリアルを見ると実にシンプルで、S3バケットにファイルを配置し、Transcription jobs (文字起こしジョブ) を作成すればいいだけのようです。
1ヶ月あたり60分の利用は無料なので、これで収まる範囲で触ってみたいと思います。
S3のcreateObjectをトリガーにしたLambda経由でjobを生成、結果を取得・整形してslackに飛ばす事にします。
という事で利用するリソース、用意するものは以下です
- S3バケット(input用と結果配置用の2つ)
- Lambda(Transcription jobsの作成と結果を生成してslack通知する)
- slackのwebhook
準備
CLIで完結でき、かつ終わったら一括でリソースが消せるのでCloudFormationのテンプレートを用意します。
用意したのは以下。
AWSTemplateFormatVersion: 2010-09-09
Description: Transcribe Test
Parameters:
SlackWebHookUrl:
Type: String
OutputBucketName:
Type: String
InputBucketName:
Type: String
Resources:
CreateTranscribeLambdaRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Principal:
Service:
- lambda.amazonaws.com
Action:
- sts:AssumeRole
ManagedPolicyArns:
- arn:aws:iam::aws:policy/AmazonS3FullAccess
- arn:aws:iam::aws:policy/CloudWatchLogsFullAccess
- arn:aws:iam::aws:policy/AmazonTranscribeFullAccess
RoleName: create-transcribe-job-role
CreateTranscribeLambdaPermission:
Type: AWS::Lambda::Permission
Properties:
Action: lambda:InvokeFunction
FunctionName: !GetAtt CreateTranscribeLambda.Arn
Principal: s3.amazonaws.com
SourceArn: !Sub "arn:aws:s3:::${InputBucketName}"
CreateTranscribeLambda:
Type: AWS::Lambda::Function
Properties:
FunctionName: create-transcribe-job
Runtime: python3.7
Handler: index.lambda_handler
Role: !GetAtt CreateTranscribeLambdaRole.Arn
MemorySize: 128
Timeout: 600
Environment:
Variables:
SLACK_WEB_HOOK_URL:
Ref: SlackWebHookUrl
OUT_PUT_BUCKET_NAME:
Ref: OutputBucketName
Code:
ZipFile: |
import os
import json
import boto3
import datetime
import json
import urllib
s3 = boto3.client('s3')
transcribe = boto3.client('transcribe')
output_bucket_name = os.environ['OUT_PUT_BUCKET_NAME']
web_hook_url = os.environ['SLACK_WEB_HOOK_URL']
def lambda_handler(event, context):
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
try:
print('=== FunctionStart ' + 'bucket: ' + bucket + ' key:' + key)
jobName = datetime.datetime.now().strftime('%Y%m%d%H%M%S') + '_testJob'
fileUrl = 'https://s3.ap-northeast-1.amazonaws.com/' + bucket + '/' + key
transcribe.start_transcription_job(
TranscriptionJobName = jobName,
LanguageCode='ja-JP',
Media={
'MediaFileUri': fileUrl
},
OutputBucketName=output_bucket_name
)
print('=== StartTranscriptionJob ===')
while True:
result = transcribe.get_transcription_job(TranscriptionJobName=jobName)
status = result['TranscriptionJob']['TranscriptionJobStatus']
if status == 'COMPLETED':
break
print('=== TranscriptionJob COMPLETED ===')
output_file_name = result['TranscriptionJob']['TranscriptionJobName'] + '.json'
response = s3.get_object(Bucket=output_bucket_name, Key=output_file_name)
body = response['Body'].read()
transcripts = json.loads(body.decode('utf-8'))
transtext = ''
for transcript in transcripts['results']['transcripts']:
transtext += transcript['transcript']
post_data = {
"text": "【文字起こし】" + "\n"+ transtext,
}
request = urllib.request.Request(
web_hook_url,
data=json.dumps(post_data).encode('utf-8'),
method="POST"
)
with urllib.request.urlopen(request) as response:
response_body = response.read().decode('utf-8')
print('=== PostedToSlack ===')
print(response_body)
except Exception as e:
print(e)
raise e
InputS3Bucket:
Type: AWS::S3::Bucket
DependsOn: CreateTranscribeLambdaPermission
DeletionPolicy: Delete
Properties:
BucketName:
Ref: InputBucketName
NotificationConfiguration:
LambdaConfigurations:
- Event: s3:ObjectCreated:*
Filter:
S3Key:
Rules:
- Name: suffix
Value: mp3
Function: !GetAtt CreateTranscribeLambda.Arn
OutputS3Bucket:
Type: AWS::S3::Bucket
DeletionPolicy: Delete
Properties:
BucketName:
Ref: OutputBucketName
デザイナーでみるとこんな感じ
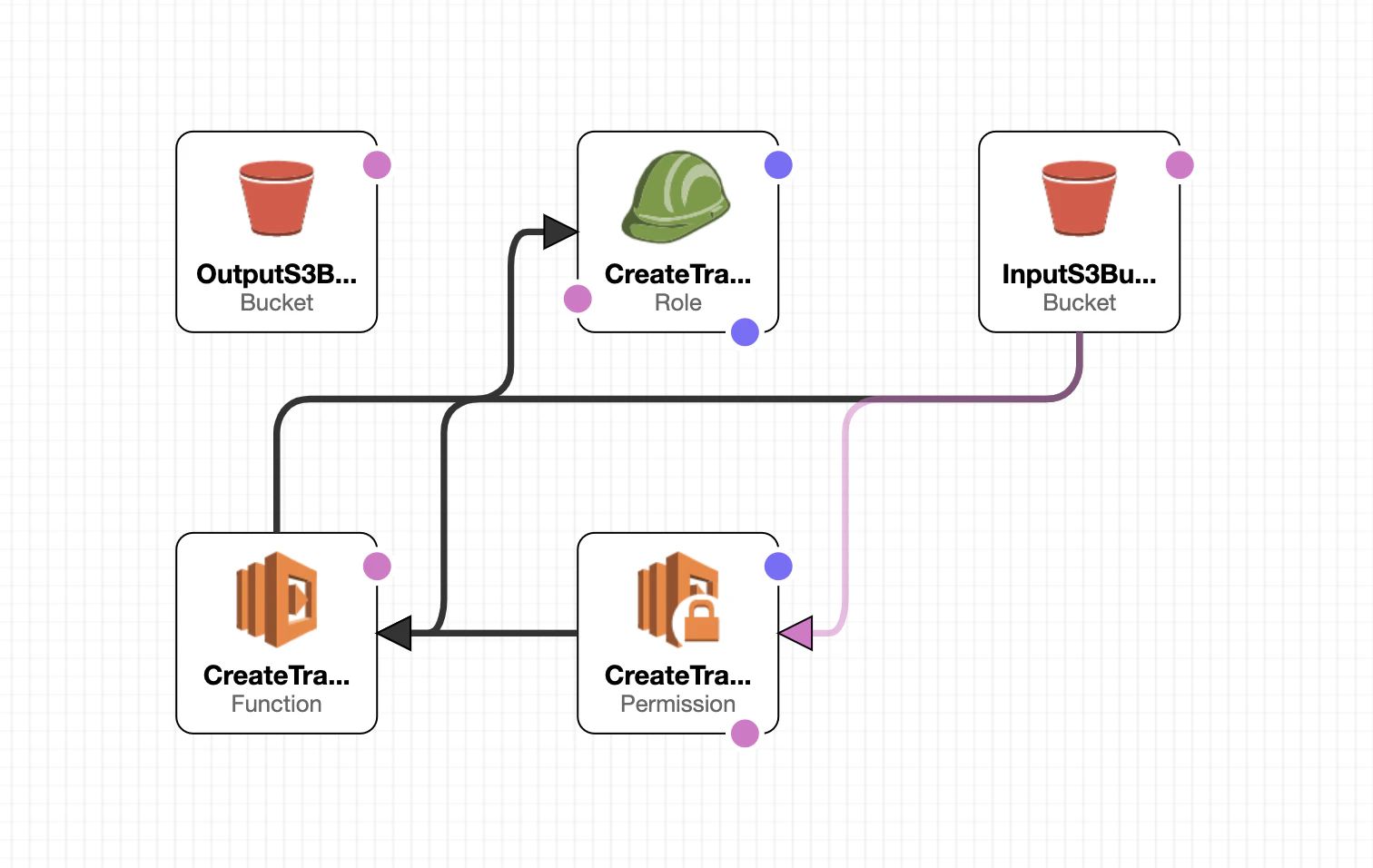
次に、テンプレートと同階層にパラメータファイルを用意します。
[
{
"ParameterKey": "SlackWebHookUrl",
"ParameterValue": "{$slack webhook url}"
},
{
"ParameterKey": "OutputBucketName",
"ParameterValue": "{$お好きなinput用バケット名}"
},
{
"ParameterKey": "InputBucketName",
"ParameterValue": "{$お好きなoutput用バケット名}"
}
]
2つのファイルを作り終わったら、以下のような形になってると思います。
作業ディレクトリ
├─ template.yaml
└─ parameter.json
リソース解説
-
AWS::IAM::Role- Lambda用のロールです。S3とログ用のCloudwatch、TranscribeのFullAccessを付与してます
-
AWS::Lambda::Permission- Lambda用のリソースベースポリシーです。画面から設計図を元にLambdaを作る時は意識しないのでテンプレートに起こす時忘れがちです。トリガーとなるinput用のS3バケットを指定します。ここ、GetAttでinput用バケットを指すと相互依存でエラーになるので、リソースネームはパラメータからバケット名をとってきて文字列生成
-
AWS::Lambda::Function- Lambda本体です。Codeは直書きしたかったのでZipFileを指定してます。テンプレートごとgit管理できるのはいいですが見にくいですね。機密情報を外に出すのも少し手間です。今回はCFパラメータ→Lambda環境変数の経路で値を渡す事で、テンプレートの外に情報を出してます
- やってる事は以下
- eventからputしたobjectを取得
- ↑を元にtranscription_job生成
- jobが終わるのを待つ
- 終わったら成果物を取得
- 文字列生成
- webhookへPOST
-
AWS::S3::Bucket- inputとoutputの2つ。 input用バケットのObjectCreatedでLambdaが発火しますが、形式はmp3に限定してます(特に縛る必要はないのですが)
- グローバルでユニークというバケット名争奪戦を勝ち抜く必要があるのでパラメータに出してます
いざ、スタック作成
テンプレートとパラメータを配置したディレクトリに移動し、createStackします。
aws cloudformation create-stack --stack-name {$お好きなスタック名} --template-body file://template.yaml --parameters file://parameter.json --capabilities CAPABILITY_NAMED_IAM
1,2分で出来上がると思います。
aws cloudformation describe-stacks --stack-name {$お好きなスタック名} | jq .Stacks[].StackStatus
> CREATE_COMPLETE
Transcribeの実力はいかに
さぁ準備は終わりました。
まずはTranscribeが信頼に足る人物であるかを評価する必要があります。
サンプル音声で動作を試してみましょう。
こちらのサイトのC-29を採用します。
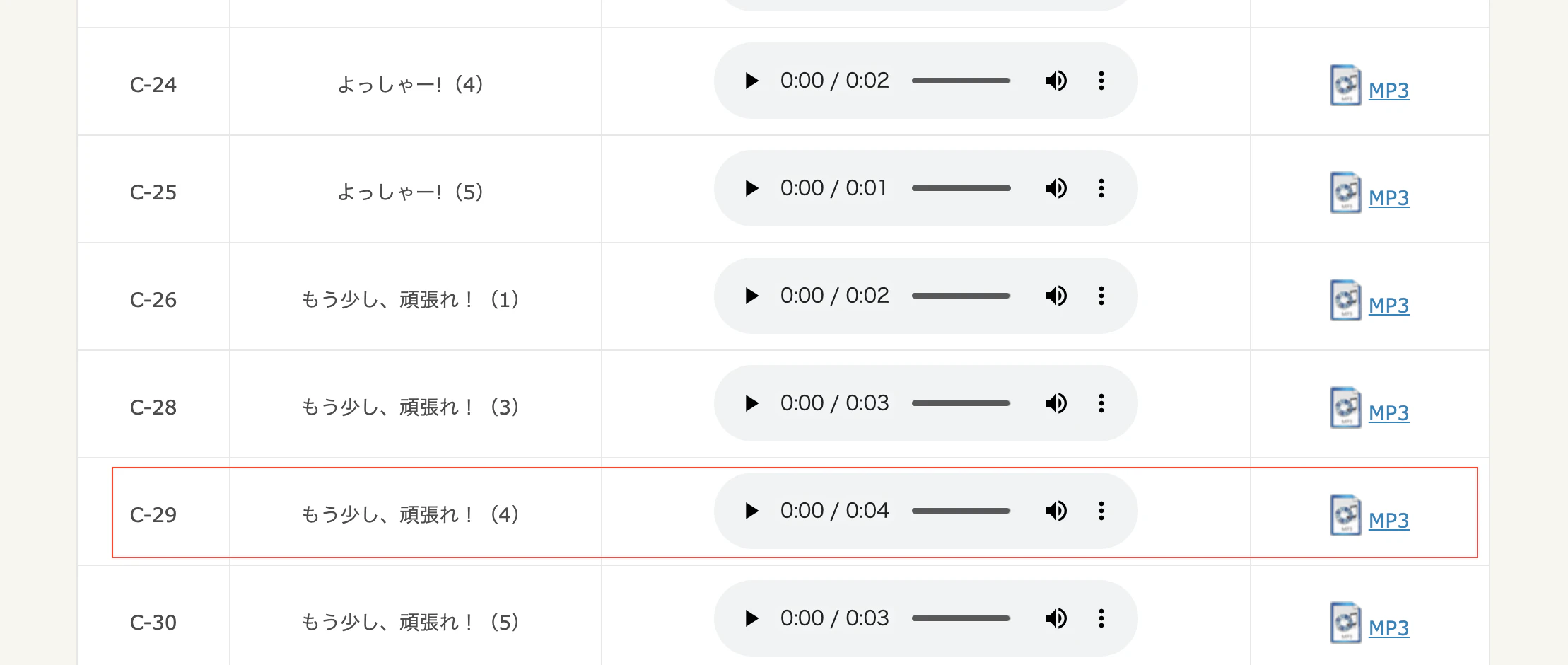
なんともクリーンな、お手本の用な「もう少し、頑張れ」です。
これを文字化できないようであればTranscribeに価値はないでしょう。
s3cpでinput用バケットに配置します。
aws s3 cp /path/to/もう少し頑張れ s3://{$input用バケット名}
たったこれだけ。簡単でしょ。
mp3は激軽ですが、30秒くらいかかるようです。
メッセージが届きました。
怒られてる気になった所で、もう少し長いファイルにしてみます。
今度はこちらのサイトの音声を投げてみます。
結果がコレ

パーフェクトです。素晴らしい。
さぁ、すべての準備は整いました。
Let's 自分の声を文字起こし
こっそり隠し撮りしたオフィスでの雑談mp3を通してみます。
結果がこちら

まともにしゃべれてるのか不安になりました。
「雑談してもらってもいいですか?」だけは聞きとってもらえたようです。
恥ずかしいので元データは載せません。
後片付け
気分が落ち込んだ所で後片付けします。
deleteStackすればいいだけですが、バケットはファイルが存在すると消えてくれないので中身を消します。
s3 rm にはご注意を。
aws s3 rm s3://{$input用バケット} --recursive
aws s3 rm s3://{$output用バケット} --recursive
aws cloudformation delete-stack --stack-name {$作ったスタック名}
要改善点
- 私の滑舌
- Lamdaのコード
-
start_transcription_jobした後get_transcription_jobで結果を取得し続けてます。大容量のファイルを配置するとjobが終わるまで結構かかる為、Lambdaのタイムアウトを大きくしなくてはなりません。ここはstart_transcription_jobする用のFunctionと、outputバケットをトリガーとした結果の取得用Functionに分けるべきだったなと思います。
-
最後に
自分の声の文字起こしに使った音声はmacのQuicktimePlayerでPCから割と離れた所から撮った音声で、入力として全然適切でないデータです。いくつか音声試しましたがちゃんとした物ならTranscribeはちゃんと返してくれますので、決して制度悪く有りません、ご承知おきください。
Webミーティングで音声取得する機会多いと思いますので、こんなのあったら割と便利ですよね。
終わりになりますが、弊社は今共に働くエンジニアを募集してます。
私の滑舌を聞いてみたい方は是非ご連絡ください。
参考文献