概要
案件において、URLのパスを表す文字列のListの入力に対して、それぞれがそれぞれに重複したり前方一致するかを判定する実装をしていました。
当初は入力件数$n$が小さかったため$O(n^2)$のアルゴリズムで実装していましたが、その後要求される入力行数が大幅に増え、並列化等の工夫を行ったものの実行時間がキツくなったため、最終的にHashMapを用いた線形探索に落とし込むことで全体で$O(n)$になるアルゴリズムを考えて実装し、これにより実行時間を150倍以上高速化1しました。
判定したいことの例
以下のような入力に対して、重複と前方一致をそれぞれ判定し、結果をList<Pair<Boolean, String?>>に詰めます。
ここでは簡単のためパスは全て前後の/が取り除かれているものとします。
val input: List<String> = listOf(
"foo/bar",
"foo/bar/baz",
"foo/bar/baz",
"foo/bar/baz/qux"
)
// inputを重複の有無と自身に前方一致するもののPairに変換したもの
val result: List<Pair<Boolean, String?>> = TODO("判定処理")
// 結果の例
val expected: List<Pair<Boolean, String?>> = listOf(
// foo/barには重複も前方一致されるものも無い
false to null,
// foo/bar/bazには重複が有り、foo/barに前方一致される
true to "foo/bar",
true to "foo/bar",
// foo/bar/baz/quxには重複がなく、foo/barもしくはfoo/bar/bazに前方一致される(結果にはどちらが出ても可)
false to "foo/bar/baz"
)
注意点
今回紹介する内容は説明に関わらない業務ロジックなどを省いています。
また、業務ロジックに基づいて最適化できる内容に関しても、多少非効率でも分かりやすさのために行っていません。
当初の素朴な実装
重複だけであればHashSetを用いて効率的に判定することができますが、前方一致はそれぞれがそれぞれに対して条件を満たすか判定する必要が有るため、素朴に実装すると計算量が$O(n^2)$になります。
案件の当初は一度の入力行数が最大1000行となっており、実行時間も気になる程ではなかったため、これで良しとしていました。
fun simpleCheck(input: List<String>): List<Pair<Boolean, String?>> = input.mapIndexed { ix, it ->
var isDuplicated = false
var overWrappedBy: String? = null
input.forEachIndexed { iy, other ->
// 自分自身とは比較しない
if (ix == iy) return@forEachIndexed
if (other == it) {
isDuplicated = true
} else if (it.startsWith(other)) {
overWrappedBy = other
}
}
isDuplicated to overWrappedBy
}
一方、その後で「やっぱり最大5万行処理したい」という仕様変更が入り、この実装では実行時間がかかりすぎることが問題となりました。
この判定処理の並列化を含め処理全体の高速化を行った結果「本番環境にて4スレッド利用で判定を含む処理全体の実行時間が最大1分程度」という所までは高速化しましたが、この判定とそれに関わる処理だけで40秒程度かかるなど、依然ボトルネックにはなっていました。
fun simpleCheckParallel(input: List<String>): List<Pair<Boolean, String?>> = input
.mapIndexed { ix, it -> ix to it }
.stream().parallel()
.map{ (ix, it) ->
var isDuplicated = false
var overWrappedBy: String? = null
input.forEachIndexed { iy, other ->
// 自分自身とは比較しない
if (ix == iy) return@forEachIndexed
if (other == it) {
isDuplicated = true
} else if (it.startsWith(other)) {
overWrappedBy = other
}
}
isDuplicated to overWrappedBy
}.toList()
提案手法
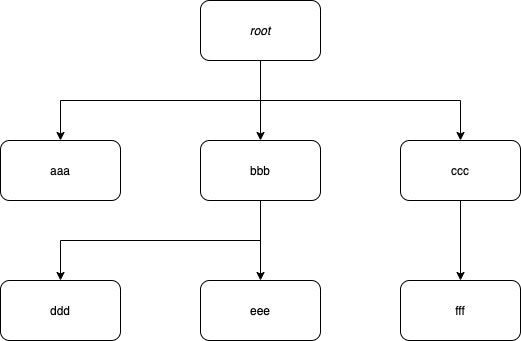
下図のように、パスを/で分解して各要素をHashMapによって木構造に変換し、そこに対して順次比較を行う方法であれば、構築・操作を線形探索に落とし込むことができ、効率よく比較ができると考えました。
計算量について
まず木構造の構築の計算量は、入力行数を$n$、HashMapに対する操作の計算量を$O(1)$として、$O(n)$となります2。
次に、取得処理の計算量は木構造の構築と殆ど同じになることから、$O(n)$となります。
よって、全体の計算量は$O(n)$となります。
実装
これをKotlinで実装したものが以下です。
登場するidentityという値は、自分自身は比較対象に含めたくないという場合に利用するもので、基本的にinputのindexを用います。
edgeとleafを区別しているのは、aaa/bbbにaaa/bが前方一致するため、末尾まで全て木構造にすることはできなかったためです。
class TreeChecker private constructor() {
private val edges = HashMap<String, TreeChecker>()
private val leafs = HashSet<Pair<Int, String>>()
private fun add(identity: Int, values: List<String>, index: Int) {
val next = index + 1
if (next == values.size) {
leafs.add(identity to values.last())
return
}
val key = values[index]
if (edges.containsKey(key)) {
edges.getValue(key).add(identity, values, next)
} else {
edges[key] = TreeChecker().apply { add(identity, values, next) }
}
}
/**
* 入力が重複しているかと、入力をオーバーラップするidentity(= 自分より短い方)を返す関数
*
* 【末尾まで検索した場合】
* ・重複チェック
* - IDが異なり、値が一致する場合重複
*
* ・前方一致チェック
* - これまでで前方一致したものが有ればそれを、無ければ葉に前方一致するものを返す
*
* 【検索中の場合】
* - ノード中に現在のノードと一致するものが有ればそれを前方一致とする(foo/barに対してfooが前方一致する的な話)
*/
private fun getIsDuplicateAndOverWrappedBy(
identity: Int, values: List<String>, index: Int, overWrappedBy: String?
): Pair<Boolean, String?> {
val next = index + 1
return if (next == values.size) { // 末尾まで来た場合
val leaf = values.last()
// 重複チェック
val duplicatedIdentities = leafs.filter { (otherIdentity, otherLeaf) ->
otherIdentity != identity && otherLeaf == leaf
}.map { it.first }
// 最後の前方一致チェック、aaa/bbbとaaa/bのような前方一致をカバーしている
val tempOverWrappedBy = overWrappedBy ?: leafs.find { (otherIdentity, otherLeaf) ->
otherIdentity != identity && !duplicatedIdentities.contains(otherIdentity) && leaf.startsWith(otherLeaf)
}?.let { (_, otherLeaf) -> values.subList(0, index).joinToString(separator = "/") + "/${otherLeaf}" }
duplicatedIdentities.isNotEmpty() to tempOverWrappedBy
} else {
// 前方一致チェック、辿る途中の葉と一致しているなら前方一致
val tempOverWrappedBy = overWrappedBy ?: leafs.find { (_, otherLeaf) -> otherLeaf == values[index] }?.let {
// 一致が有れば文字列を復元したものを保持する
values.subList(0, next).joinToString(separator = "/")
}
// 探索続行
edges.getValue(values[index]).getIsDuplicateAndOverWrappedBy(identity, values, next, tempOverWrappedBy)
}
}
fun getIsDuplicateAndOverWrappedBy(identity: Int, path: String): Pair<Boolean, String?> {
return getIsDuplicateAndOverWrappedBy(
identity,
path.split("/"),
0,
null
)
}
companion object {
/**
* 構築方法について
* 1. パスは/で分割する
* 2. 1をadd関数を用いて木構造に変換する
* 3. 変換時、葉をnodeとして、節点をchildrenとして保持する(前方一致はノード中でも見る必要があるため)
*/
fun newInstance(
inputs: List<String>
): TreeChecker {
return TreeChecker().apply {
inputs.forEachIndexed { identity, path ->
add(identity, path.split("/"), 0)
}
}
}
}
}
// 使い方
fun main() {
val input: List<String> = listOf(
"foo/bar",
"foo/bar/baz",
"foo/bar/baz",
"foo/bar/baz/qux",
"hoge/fuga",
"hoge/fu"
)
val checker = TreeChecker.newInstance(input)
val result = input.mapIndexed { identity, path ->
checker.getIsDuplicateAndOverWrappedBy(identity, path)
}
// -> [(false, null), (true, foo/bar), (true, foo/bar), (false, foo/bar), (false, hoge/fu), (false, null)]
println(result)
}
応用の話
今回のやり方は、当たり前ですが順序だてて木構造に分解できるものなら何にでも応用できます。
また、後方一致判定に関してもデータ構造をそのままに簡単に実装することができます3。
動作速度の比較
続いて簡単な動作速度の比較についてです。
テストデータと実行結果に関してはこちらにアップロードしてあります。
検証環境/検証内容
検証は以下のプログラムによって生成した1万、2万、...、5万行のデータを入力として実行時間[ms]を計測する形で行います。
このデータは同じデータ2つをマージして生成しているため、少なくとも半分は重複します。
テストデータ生成プログラム
val characterset: List<Char> = ('a'..'z') + ('A'..'Z') + ('0'..'9')
const val maxNodeLen = 7 // 1要素が最大どれだけの長さになるか
const val maxSumOfLen = 10 // 要素数が最大どれだけの長さになるか
const val separator = "/" // 区切り文字
fun generateStrings(generateSize: Int) = (1..(generateSize / 2)).map {
// 目標サイズの半分で生成
(1..Random.nextInt(2, maxSumOfLen)).joinToString(separator = separator) {
(1..Random.nextInt(1, maxNodeLen)).map {
characterset[Random.nextInt(characterset.size)]
}.joinToString(separator = "")
}
}.let {
it + it // 足して重複を再現
}
fun main() {
listOf(10_000, 20_000, 30_000, 40_000, 50_000).forEach {
File("./build/generated/${it}.txt")
.writeText(generateStrings(it).joinToString("\n"))
}
}
検証にはRyzen7 3700X(OC無し)搭載の環境を用いました4。
検証用プログラム
ここまでの実装に加え、検証用に幾つか実装を追加したものが以下です。
ラベルと内容の対応は以下の通りです。
-
simple1T: 本文中のsimpleCheck -
simple4T: 本文中のsimpleCheckParallelの実行スレッド数を4に制限したもの -
simple16T: 本文中のsimpleCheckParallel、今回の検証に用いた環境では16Tが用いられる -
treeCheck: 本文中のTreeCheckerを利用する実装
import java.io.File
import java.util.concurrent.ForkJoinPool
import kotlin.system.measureTimeMillis
fun simpleCheckParallel4Thread(input: List<String>): List<Pair<Boolean, String?>> {
var result: List<Pair<Boolean, String?>> = emptyList()
ForkJoinPool(4).submit { result = simpleCheckParallel(input) }.get()
return result
}
fun treeCheck(input: List<String>): List<Pair<Boolean, String?>> {
val checker = TreeChecker.newInstance(input)
return input.mapIndexed { identity, path ->
checker.getIsDuplicateAndOverWrappedBy(identity, path)
}
}
fun main() {
val funcs = listOf<Pair<String, (List<String>) -> List<Pair<Boolean, String?>>>>(
"simple1T" to ::simpleCheck,
"simple4T" to ::simpleCheckParallel4Thread,
"simple16T" to ::simpleCheckParallel,
"treeCheck" to ::treeCheck
)
listOf(10_000, 20_000, 30_000, 40_000, 50_000).forEach { size ->
// ファイルからデータを読み込み
val inputs = File("./build/generated/${size}.txt").readText().split("\n")
var result: List<Pair<Boolean, String?>>
funcs.forEach { (name, func) ->
// ウォームアップ
result = func(inputs)
result.random()
println("size: ${size}, name: ${name},\ttime[ms]: ${measureTimeMillis { result = func(inputs) }}")
result.random()
}
}
}
実行結果
全体
全体の実行結果は以下の通りです。
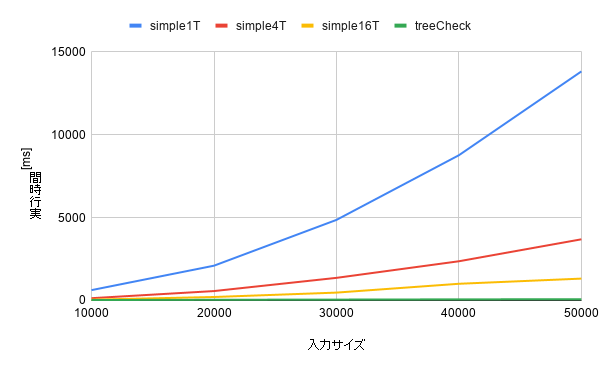
素朴な実装では入力行数に対して実行時間がどんどん増えているのに対し、提案手法の実行時間は増え方がとても穏やかになっています。
入力行数が5万件の場合、simple1Tの実行時間が13827msに対し提案手法は79msと、約175倍程度の高速化ができていました。
生データは以下の通りです。
生データ
size: 10000, name: simple1T, time[ms]: 627
size: 10000, name: simple4T, time[ms]: 140
size: 10000, name: simple16T, time[ms]: 52
size: 10000, name: treeCheck, time[ms]: 28
size: 20000, name: simple1T, time[ms]: 2101
size: 20000, name: simple4T, time[ms]: 570
size: 20000, name: simple16T, time[ms]: 212
size: 20000, name: treeCheck, time[ms]: 45
size: 30000, name: simple1T, time[ms]: 4865
size: 30000, name: simple4T, time[ms]: 1367
size: 30000, name: simple16T, time[ms]: 477
size: 30000, name: treeCheck, time[ms]: 56
size: 40000, name: simple1T, time[ms]: 8769
size: 40000, name: simple4T, time[ms]: 2369
size: 40000, name: simple16T, time[ms]: 1010
size: 40000, name: treeCheck, time[ms]: 69
size: 50000, name: simple1T, time[ms]: 13827
size: 50000, name: simple4T, time[ms]: 3694
size: 50000, name: simple16T, time[ms]: 1322
size: 50000, name: treeCheck, time[ms]: 79
提案手法単体
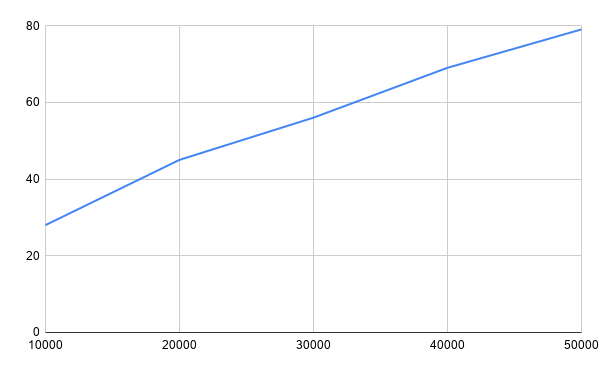
提案手法単体で見た場合の結果は以下の通りです。
件数の増加に対して処理時間の増加は穏やかなことが分かります。
まとめ
今回はパスを木構造に整形してから比較することでパスの重複・前方一致判定を150倍以上高速化した話について書きました。
競技プログラミングなどをやっている人はこういうのをサッと解いてしまうものなのでしょうか?
自分はこの実装を思いつくまでにかなり時間をかけてしまい、素養の無さを痛感しました。
もっと高速な方法も有るかもしれませんが、とりあえずの課題に関しては解決することができたので、今回はここまでとします。