この記事はKotlinのカレンダー | Advent Calendar 2022 - Qiitaの2日目の記事です。
Kotlinリポジトリに対して出した下記のPRについて解説していきます。
内容はkotlin-reflect内の重要な関数であるKFunction.callByを高速化するというものです。
Kotlin 1.8.20でリリース予定です。
このPRの意義
KFunction.callByは、Kotlinのリフレクションで、デフォルト引数を有効にして関数呼び出しを行うための関数です1。
正攻法でKotlin用にリフレクションでの関数呼び出しを実装したい場合、KFunction.callByの呼び出しは避けられません。
実際、簡単に検索してみるだけで、以下のような有名フレームワークでの利用例が見つかります。
つまり、この関数を高速化出来れば、Kotlinを利用する多くのシステムで処理コストを下げることが出来ます。
どれ位高速化するか
以下のコメント時点での簡単なJMHベンチマークによる性能比較を紹介します。
正確に言うとこのベンチマーク時点から変更されている部分も有りますが、大幅にスコアがブレるような変更は無く、これから入る予定も有りません。
ベンチマーク全体は以下にアップロードしています。
ベンチマーク内容
以下のような、全引数にデフォルト引数が設定されたトップレベル関数から取得したKFunctionについて、一定時間内にどれだけcallByできるか(秒間何回のペースで呼び出せたか)を比較しています。
fun __five(a0: Int = 0, a1: Int = 1, a2: Int = 2, a3: Int = 3, a4: Int = 4) {}
引数としては、空Map(= 全引数でデフォルト引数利用)の場合と、全ての引数を与えた場合を比較しています。
ベンチマーク結果
5引数の場合の結果は以下の通りです。
Scoreは高いほど良いです。
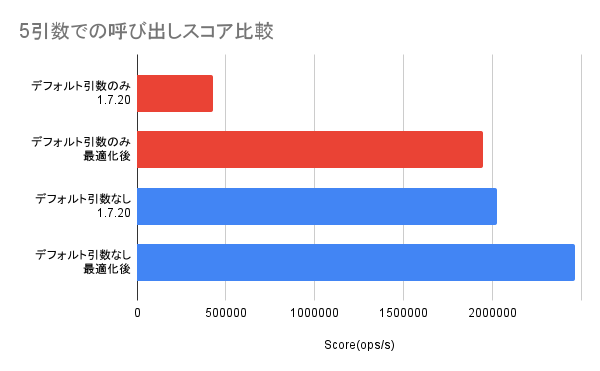
特に全引数でデフォルト引数を利用した場合に大きくスコアが伸びている(約4.6倍)ことが分かります。
また、デフォルト引数を利用しない場合にも、スコアが伸びています(約1.2倍)。
勿論この検証は限定的な内容であり、全ての場合での高速化を保証するものではありませんが、いくつかの計測結果を見る限り少なくとも引数が1つ以上の場合は高速化していそうでした。
この部分の生データは以下の通りです。
# 1.7.20
Benchmark Mode Cnt Score Error Units
Measurement.fiveWithDefault thrpt 4 427439.340 ± 18559.512 ops/s
Measurement.fiveWithoutDefault thrpt 4 2025561.126 ± 78028.024 ops/s
# 最適化後
Benchmark Mode Cnt Score Error Units
Measurement.fiveWithDefault thrpt 4 1948375.781 ± 199051.047 ops/s
Measurement.fiveWithoutDefault thrpt 4 2461809.238 ± 123859.545 ops/s
どのような最適化を行ったか
ここから先は完全にKotlin内部の実装の話になります。
内容は、以下の記事にあるような、Kotlinのデフォルト引数の仕組みを理解している前提となっています(この部分を分かりやすく解説できればと思いましたが書き切れませんでした、、、)。
最適化前(1.7.21時点)の当該関数は以下です。
用語解説
この先で用いる用語に関する解説です。
一部この記事独自の表現が含まれます。
- マスク
- デフォルト引数の利用の有無を管理するビットマスク
- マーカー
- デフォルト引数に関連する関数であることを示すため、
JVM上の引数末尾に加えられる引数 - 実行時には
nullを渡す
- デフォルト引数に関連する関数であることを示すため、
- ダミー引数
- デフォルト引数を利用する際に仮で渡す(最終的にデフォルト引数で置き換えられる)引数
- オブジェクト型の場合は
null、プリミティブ型なら0(非nullの値)を渡す-
varargの場合、対応する空配列を渡す
-
最適化内容
主に以下2点の高速化を行いました。
また、この他にも細かな修正を行なっています。
引数管理を配列化
最適化前までは引数をArrayListで管理していましたが、最終的に要求される配列のサイズは一定であるため、最初から配列で管理するようにしました。
これによってArrayList関連の計算コストと消費メモリ量が多少削減されました。
事前計算可能な処理のキャッシュ
最適化前までは、プリミティブ型及びvarargに対応するダミー引数の取得は呼び出し毎に行われていましたが、これらのダミー引数は引数毎に一定であるため、事前に計算・キャッシュして使い回す形に修正を行いました。
この処理はかなり高コストだったため、今回行った最適化の中では最大の効果が有りました。
また、最適化前はマスクやマーカーの追加処理を最後に行っていましたが、これらも最初からキャッシュに含めることで、呼び出しの度に必要な処理の量を減らしました。
後書き
この記事では自分の取り組んできたKFunction.callByの高速化についてまとめました。
冒頭で解説した通り、KFunction.callByは様々なフレームワーク・ライブラリで利用されている重要な関数です。
一方、この関数の呼び出しが非常に重たいことは前々から気になっていたので、自分が最適化に携われたことが嬉しいです。
一ユーザーとしてもこの最適化が方々に取り込まれるのを心待ちにしています。
今年はこの他にもkotlin-reflectのvalue class関連の修正にも携わることができ、Kontlibuteという意味では充実した1年でした。
この他にもkotlin-reflect絡みの最適化案は有るので、来年もいい感じにKontlibuteしていけたらと思います。
-
実行にはkotlin-reflectが必要です。 ↩