
概要
非常に小さい顔を検出できる新しいモデルを提案した論文。
また、どうしてそのモデルに至ったのかをImageNetの特性や画像のスケール、物体の周辺領域の情報(コンテクスト)という観点から考察している
Intro
画像に含まれている物体のサイズは、同じ物体クラスだとしても遠近などにより非常にばらつきがある(数百〜数pixel)。しかし、物体検出器一つでそれらすべてを検出できるようにしたいものだ。
そのため、下の図のように、パターンマッチングの時代から歴史的に様々な方法で物体サイズのばらつきに取り組んできた。

様々な研究の結果、scale-invariance(画像のサイズをいじることで、大きさの違う物体に対してもパターンがマッチするようにすること)は現在の画像認識システムの基本的特徴となっている。
しかし、実用的にはセンサーの解像度が有限である以上それは必ずしも成り立たない。実際、300pxの顔を認識する手がかりは3pxの顔とは違う。具体的にどういう違いがあるのか見ていこう:
背景
コンテクスト
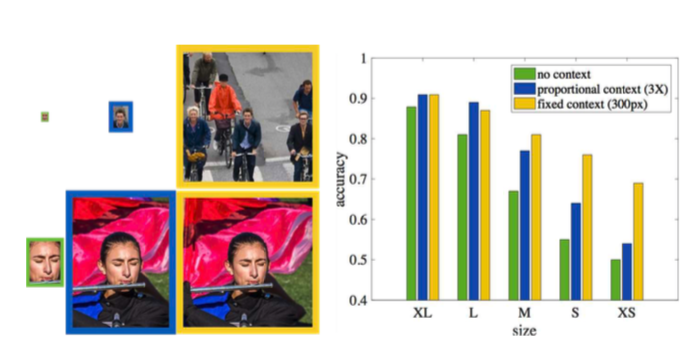
上図左上の緑の箱には非常に小さい物体が写っているが、もはや情報が少なすぎてこれだけで検出するのはほぼ不可能である。が、周りの状況が映されている右の箱を見れば顔とわかる。このように、非常に小さい物体を認識するには、その対象にパターンマッチするだけでなくまわりの状況(コンテクスト)の情報も必要である。
コンテクストを使うのは直感的に有効なことはわかるし使われてきたが、数値的にその効果を示すのは難しかった。この論文では深層学習モデルの最終的な精度を用いることで、そこに対する数値的な考察も行っている。下の図を見てほしい:

上段は小さい画像、下段は小さい画像に対するResNetを用いた検出結果である。右に行くにつれ、より深いResBlockの出力も同時に用いて顔を検出している。より深いResBlockのほうが一つのニューロンの受け取る画像の大きさ1が広いので、それが点線で示されている。
どちらにおいても、実線で示された緑の範囲より広い受容野を持つ出力を用いたほうが性能が良くなっており、(特に対象が小さい時)コンテクスト情報が重要であることが実験的に示されている
(なお、上段一番右で精度が下がっているのは、過学習によるものらしい)
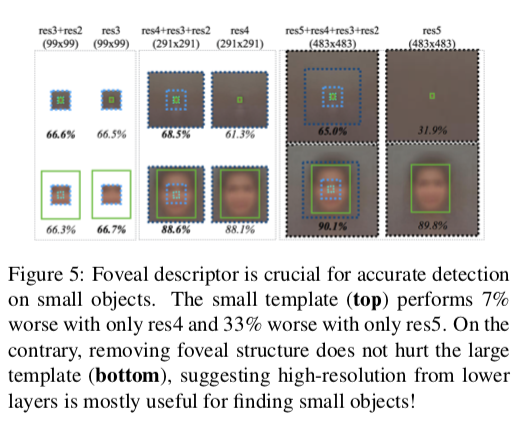
また、逆に深い層の出力だけで予測をするようにした場合、対象の物体が小さいと精度が大幅に低下する(上段:7%や33%に対し、下段はほとんど下がっていない)。
小さい物体を見つけるには、低い層からの高い解像度の出力が重要であることがわかる。
画像の解像度
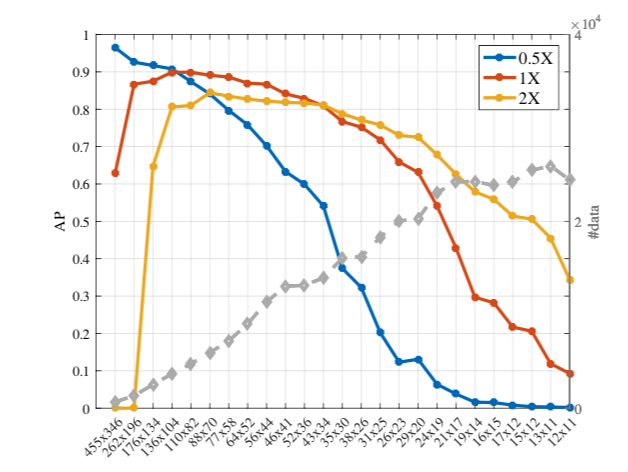
画像の解像度は高いほうが性能が上がるように思える。実際、小さい画像を「小さいサイズのテンプレート2」で検出させるより、単純に引き伸ばして「中くらいのサイズのテンプレート」に検出させたところ、大きく性能が上がった(69→75%、下図左)!

一方で、非常に大きい画像を半分に縮小して同じように検出させたところ、やはり性能が上がった(上図右)!
縮小したほうが情報量は下がるのに性能が上がるとは不思議だが、著者らはこれに対して以下のように説明を試みている:
- WIDER FACEやCOCOといった「自然界の」データセットは、小さい物体のほうが画面に大量に映り込みがち
- したがって小さい物体のほうがより多くラベリングされる
- 下グラフにグレイで示されるように、WIDERには小さい物体が多い
だが、これは「大きい画像を縮小して中くらいのサイズのテンプレートで見つけたほうが性能がいい」ことは説明できても、「小さい画像を拡大して中くらいのサイズのテンプレートで見つけたほうが性能がいい」ことの説明になっていない。
著者は、こちらはPretrainでつかったImageNetに原因があると推測している。ImageNetで認識される物体は、40-140pixelのものが非常に多いのである。
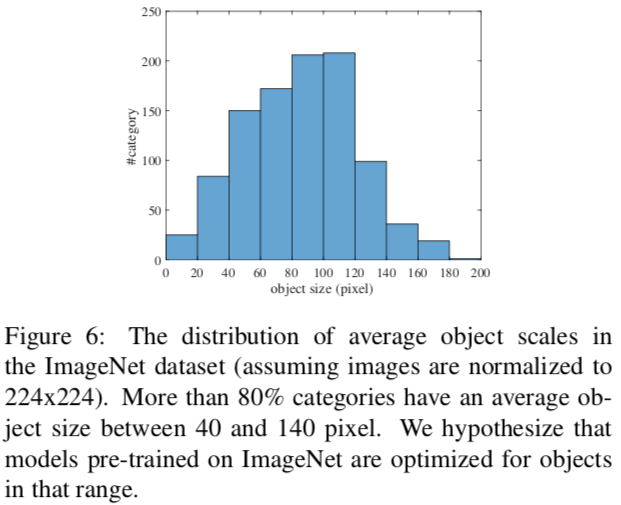
これにより、同じように検出器が転移学習の前の段階でバイアスを受けていたのではないかという仮説が立つ。
実際、画像をそのまま与えたモデル、2倍にしたモデル、半分にしたモデルの物体の大きさに対する成績は以下のグラフ(グレイ以外)のようになる。
これらの最も得意なところはこれらの包絡線になるので:
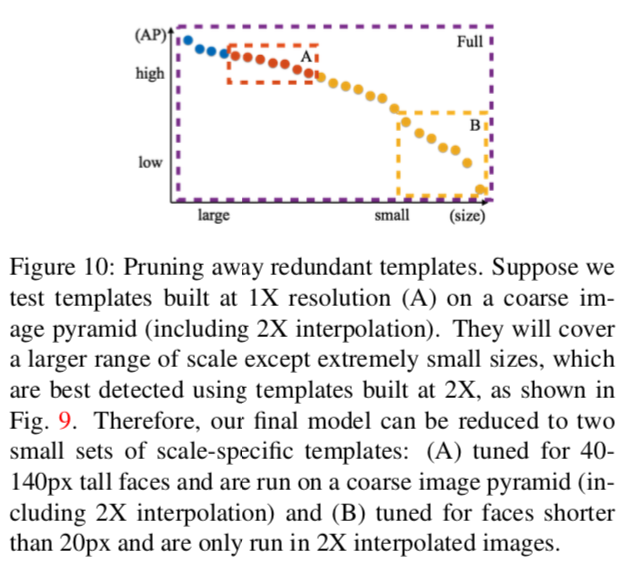
こんな感じになる。
モデル
上図の、点線で囲われた部分AとBのテンプレートを組み合わせて使う。
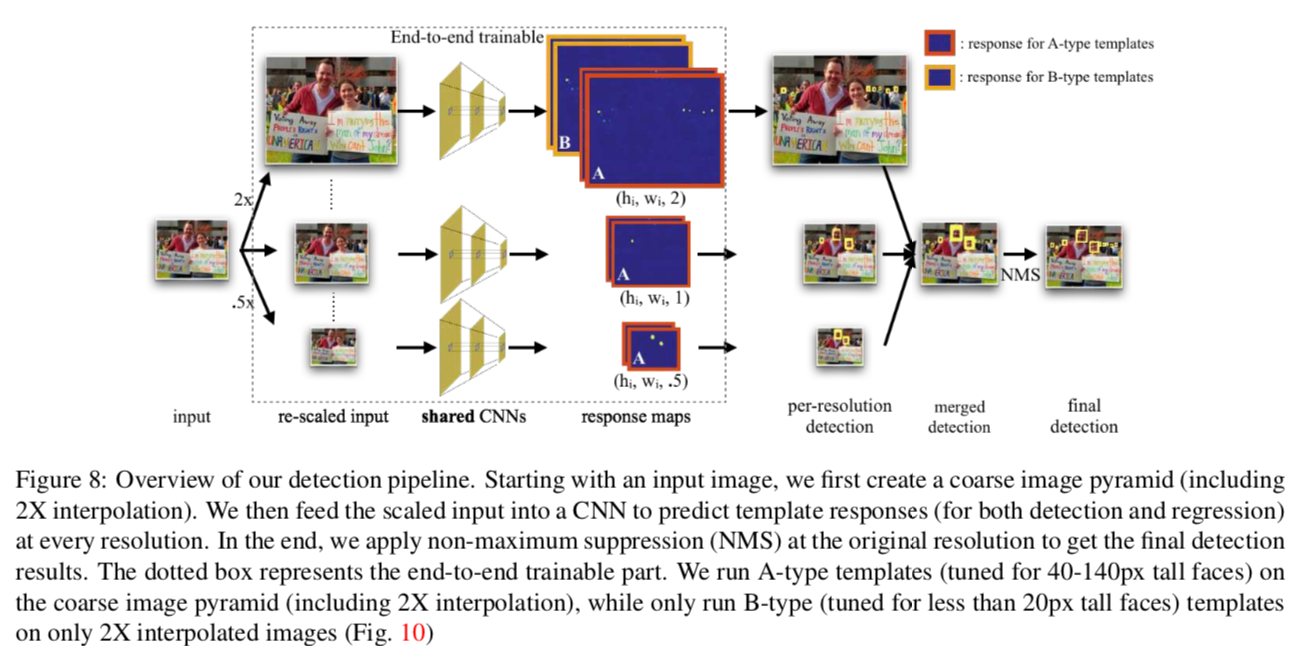
Aは40-140pxのサイズを担当している標準的なもの。これに2倍に引き伸ばした画像と半分に縮小した画像を両方食わせ、より広い範囲を担当させる。
極めて小さい物体に対してはBが担当する。これは2倍に引き伸ばした画像のみを受け取るので、より小さい物体に特化した性能になることが期待される。
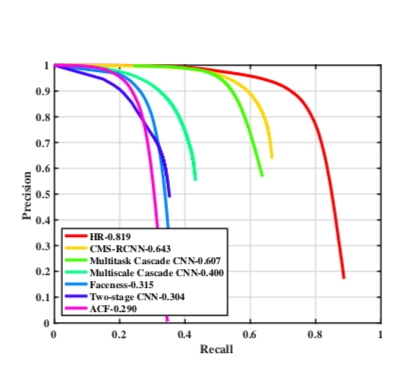
性能
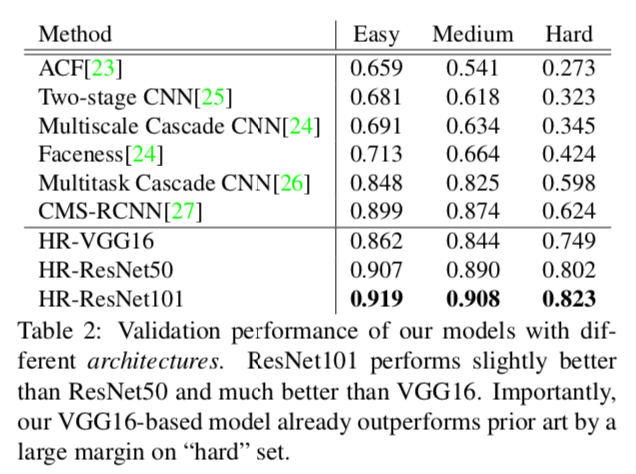
ResNet101: 1.4FPS on 1080p, 3.1 FPS on 720p
感想
機械学習の論文って、モデルの説明が割と多くを占めているものが多いんですけど、今回の論文はデータセットのインバランスやコンテクストの説明にも多くの分量が割かれている印象でしたね。
Foveal descriptorやtemplateといったCV系の用語がたくさん出てきて、読むのがちょっと難しかったです。
この記事はMETRICAの社内勉強会用の資料を改稿したものです