正しい論文タイトルは"Single-Shot Refinement Neural Network for Object Detection"。
arxiv
Object Detectionには2-stageと1-stage(Single Shotとも)の2つのアプローチがあり、一般に2-stageは精度が高いが遅く、1-stageは速いが精度が微妙。なので2つのメリットを組み合わせたモデルを提案した
既存研究の状況
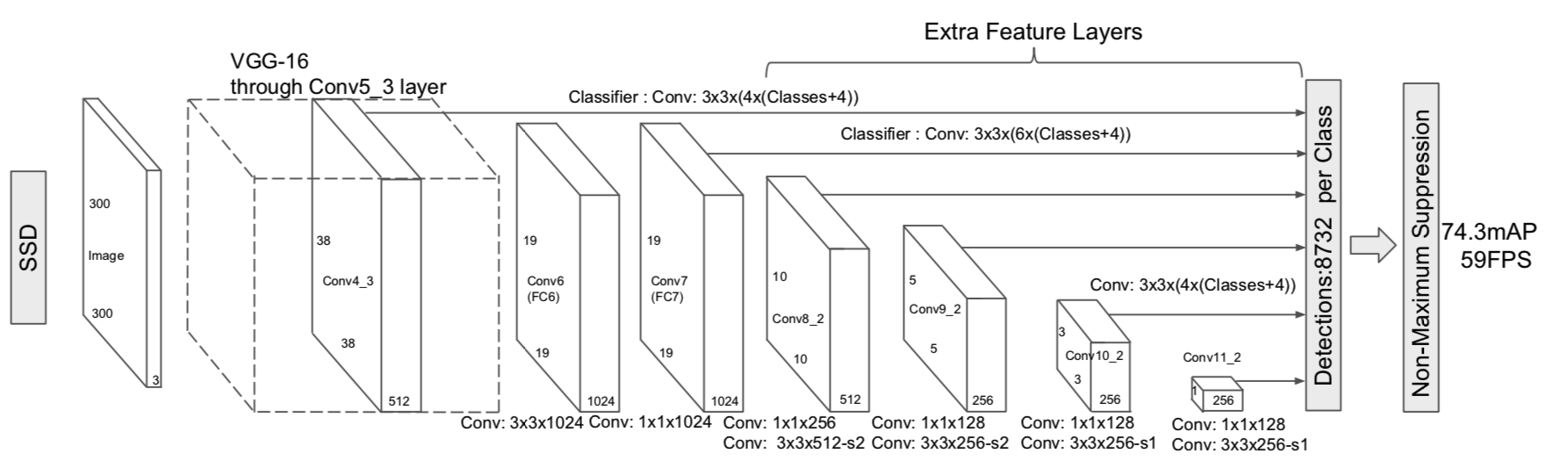
(1-stage methodであるSSDのアーキテクチャ)
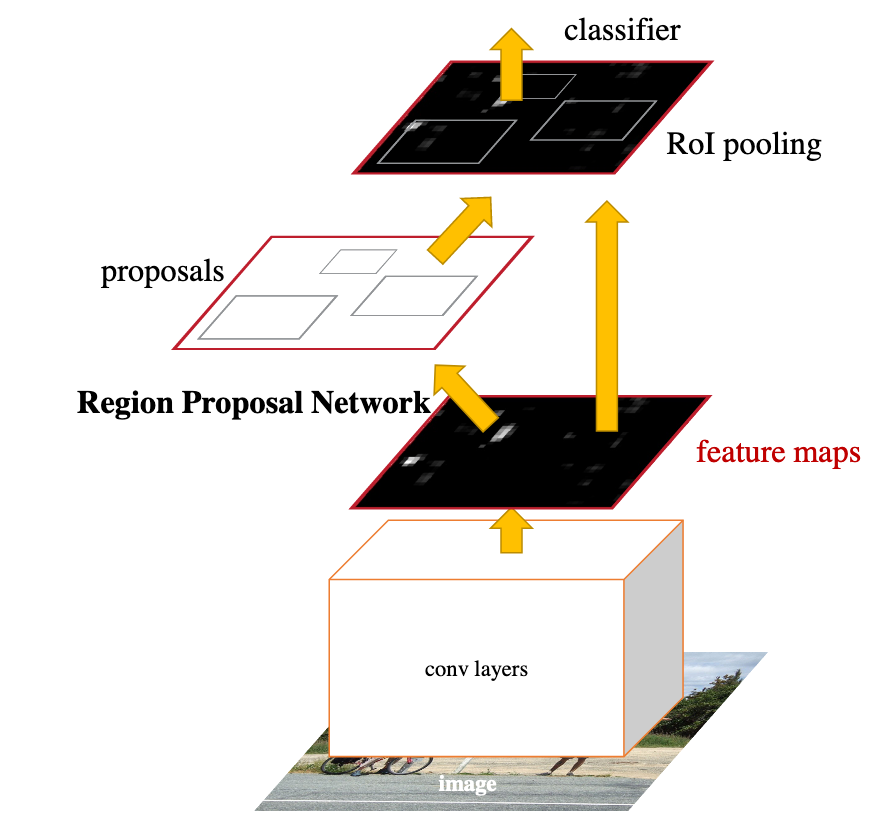
(2-stage methodであるFaster R-CNNのアーキテクチャ)
2-stage methodsは次のようなメリットがある:
- class imbalanceを是正するサンプリングができる(ため、classifierの訓練がよりうまくできる)
- ボックスのパラメータを2段階に渡って調整できる
- 2段階に渡る特徴量でボックスを記述できる
- 上図のFaster R-CNNでは、最初のRegion Proposal NetworkがProposal, すなわちAnchor1か否かを出力し、second stageでclassificationをする。この発想がこの論文にも用いられている
この論文のcontribution
この論文のアーキテクチャはSSDの発展版と言える部分がとても多いので、かぶっている部分についてはかなり省略している。SSDを知らない人は以下を読む前に予習しておいたほうが良いだろう2。
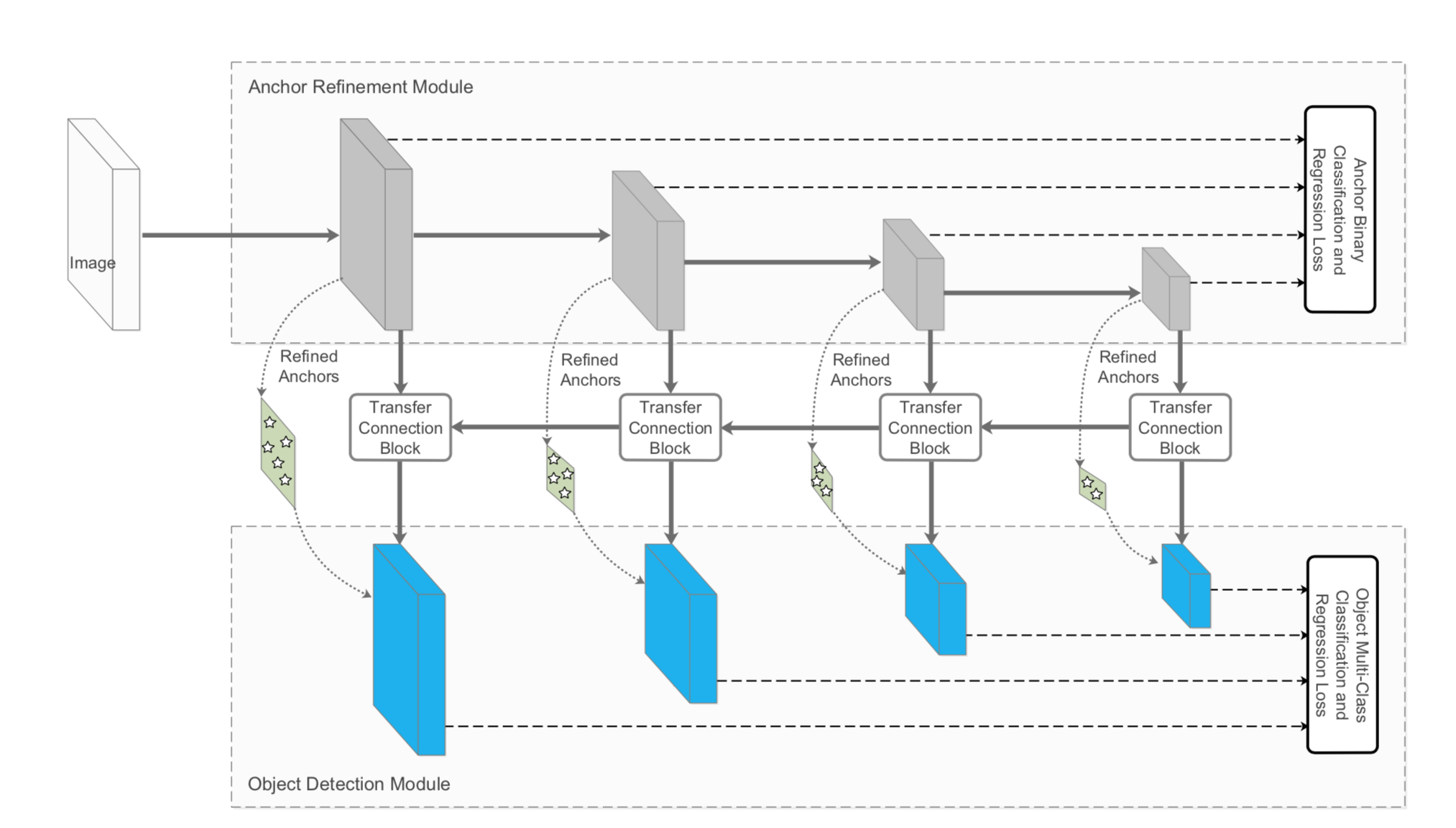
- ARMとODMという2つのモジュールからなる新モデルの提案
- すべてConv/Deconv/Addなどでひとつなぎに構成されている1-stage method
- 1-stageの効率と2-stageの性能を併せ持つ
- TCBを使ってそれらの間をつなぎ、ARMの特徴量をODMに渡す
- 正確な物体の位置&大きさ、クラスをODMに求めさせる
- Pascal VOC 2007/2012, MS COCOでSOTA
それぞれのモジュールの解説
ARM
SSDと結構似ているので省略する
細かい違いとしては、
- SSDの入力画像サイズは300/512だが、RefineDetでは320/512
- こちらのほうがstrideでサイズが半々になった時に扱いやすいし、賢い変更だと思う
- BackboneにResNet-101を使ったりもしている
- 推論速度を上げるため、逆にSSDの下位互換になっているところもある
- SSDでは6サイズのAnchorが出力されるが、RefineDetでは4サイズ
- SSDではAnchorのアスペクト比は{1, 2, 3, 1/2, 1/3}+(サイズ違いの正方形)に対し{1, 2, 1/2}+(サイズ違いの正方形)で4つ
- 2回サイズ調整を入れられるしサイズ変更が柔軟に行けると判断したようだ
TCB
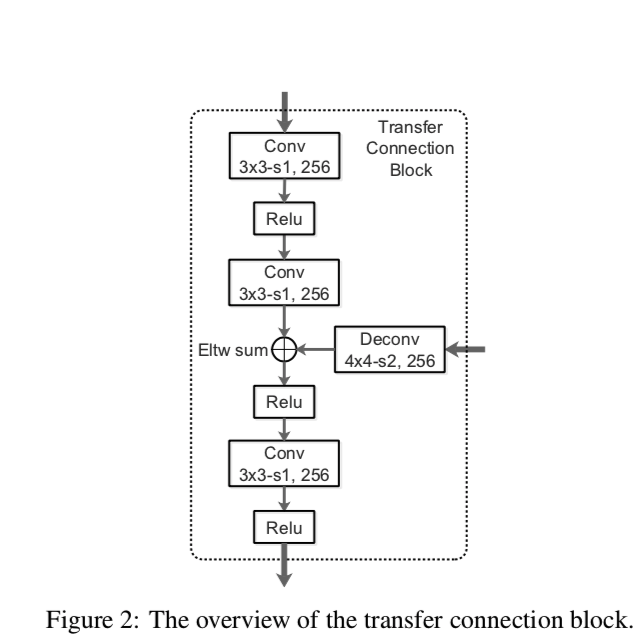
ARMの特徴量を取ってきて、より深いレイヤのものと足し合わせる
- TCBに渡すのは「ARMの出力した結果」=「箱のサイズ・クラスに関する予測」ではなく、ARMへの入力である。
- すなわち、概観図における箱はコンボリューションではなく中間特徴量を表している。
- サイズが合わないのでDeconvで倍にする
- 大きいスケールのコンテクストを統合する効果があると考えられる
ODM
これこそSSDとまったく同じなので省略
予測の出し方
ARMは、それぞれのanchorに対して
- その箱の中に物体はあるか否か(dim=1)
- Anchorと比べた位置・大きさの修正(dim=4)
を出力し、ODMは
- 物体のクラス(dim=class)
- ARMの予測と比べた位置・大きさの修正(dim=4)
を出力する
訓練
クラス間inbalanceの是正
- ARMのconfidence出力があまりに低い($\leq 0.01$など)ものは、ODMに渡さない
- あまりに明白すぎるbackgroundは渡さないということ
- Hard negative samples3のみを渡す、という言い方をする
- これは推論時も同じ
- あまりに明白すぎるbackgroundは渡さないということ
- 更に、それでもnegative sampleは非常に多いので、訓練時はそのうちからランダムに選び、$\mathrm{neg:pos} = 3:1$になるようにする
- SSDと同じ
Anchor Boxのマッチング
最もjaccard overlapの良いboxとマッチし、そのあとoverlapが0.5を超えているもの全てとマッチする。SSDと同じ
損失関数
損失は
\mathcal{L}\left(\left\{p_{i}\right\},\left\{x_{i}\right\},\left\{c_{i}\right\},\left\{t_{i}\right\}\right)\\
=\frac{1}{N_{\mathrm{arm}}}\left(\sum_{i} \mathcal{L}_{\mathrm{b}}\left(p_{i},\left[i_{i}^{l} \geq 1\right]\right)
+\sum_{i}\left[l_{i}^{*} \geq 1\right] \mathcal{L}_{\mathrm{r}}\left(x_{i}, g_{i}^{*}\right) \right)\\
+\frac{1}{N_{\mathrm{odm}}}\left(\sum_{i} \mathcal{L}_{\mathrm{m}}\left(c_{i}, l_{i}^{*}\right)
+\sum_{i}\left[l_{i}^{*} \geq 1\right] \mathcal{L}_{\mathrm{r}}\left(t_{i}, g_{i}^{*}\right) \right)
それぞれの項は
- $g_i^*$: Anchorの位置・大きさの正解
- $l_i^*$: Anchorの正解クラス(クラスがbackground、すなわち何でもないなら0、それ以外なら1, 2, ...)
- $p_i$: ARMの予測したあるか否かのbinary confidence
- $x_i$: ARMの予測した位置・大きさ
- $c_i$: ODMの予測したクラス
- $t_i$: ODMの予測した位置・大きさ
- $[cond]$: $cond$が満たされるなら1, そうでないなら0
ロス関数は
- $\mathcal{L}_b$: クロスエントロピー
- $\mathcal{L}_m$: (クラス間)ソフトマックス
- $\mathcal{L}_r$: L1損失
したがって、それぞれの損失は
- ARMが予測したbinary confidenceが合っているか
- (実際にそこにanchorがあったとき)ARMの予測した位置は正しいか
- ODMの予測したclassが合っているか
- ODMの(ARMの予測を修正することによって)予測した位置は正しいか
を見ていることになる
推論
上に述べたように、推論時はARMでしきい値に満たなかったものを取り除き、ODMがそこからconfidentなAnchor TOP400を取り出す。
最後にNMS(SSDと同じなので省略)をjaccard overlapしきい値0.45でかけ、トップ200を取り出して最終的な推論結果とする(ここはSSDもおなじ)
結果比較
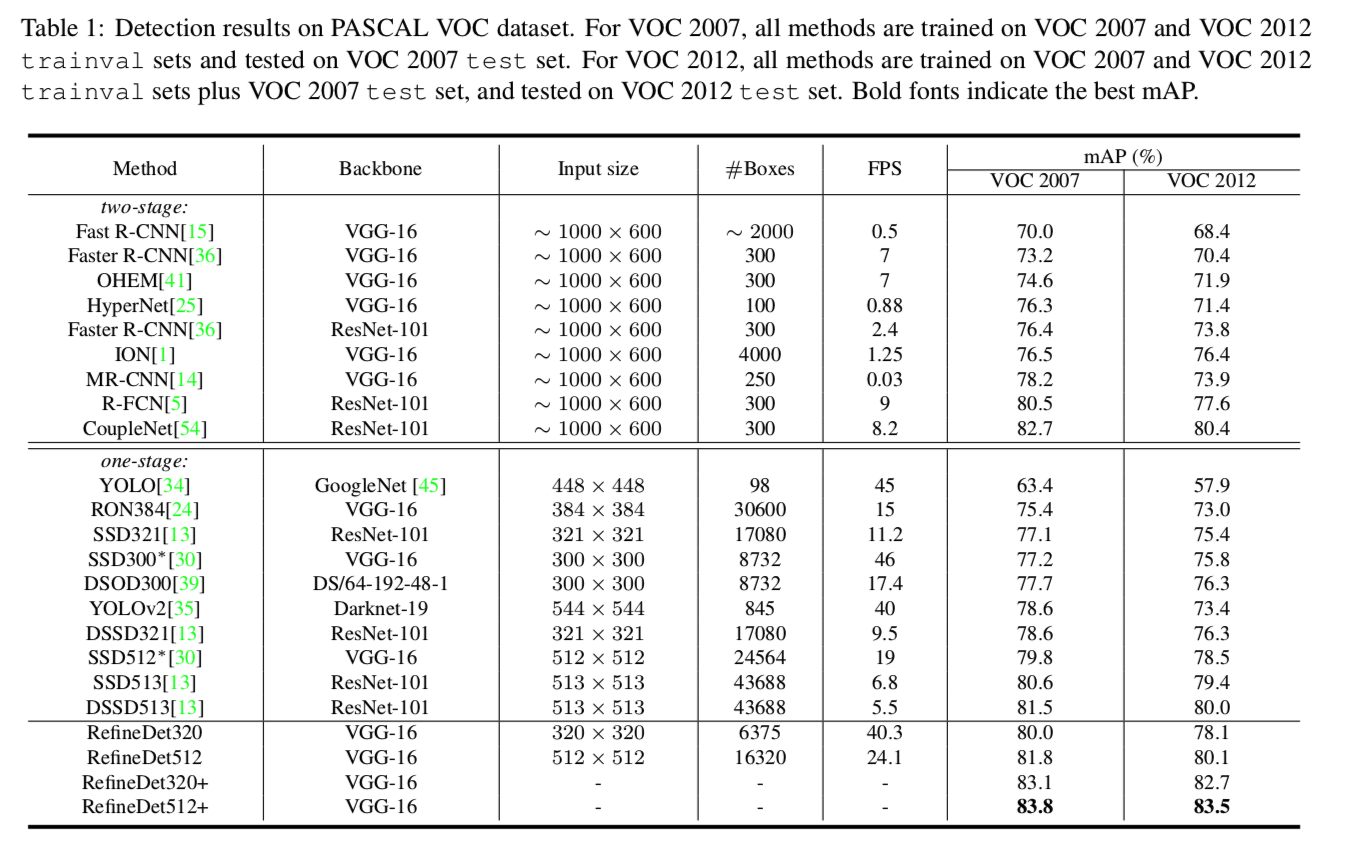
- Real Time Inferenceなのにabove 80% mAP!世界初!どや
- SSD300, YOLOはわずかにRefineDet320より速いが、性能でかなり勝ってる
- 個人的には$AP_S$の性能がいいのが注目ポイント
Ablation Study
次の3つの変更を順に行ってみて、性能がどう変わったかを調べた
Negative Anchor Filtering
- 訓練・推論時ともにしきい値を1に→どんな負例もすべてODMに送られる
Two-Step Cascaded Regression
- ARMからの修正ではなく、ODMのみで場所を調整させる
Transfer Connection Block
- TCB以降を削除して、SSDと同じ構造にして推論させる
- これは流石にきついのでは?もはやSSD(の下位互換)になっている
結果
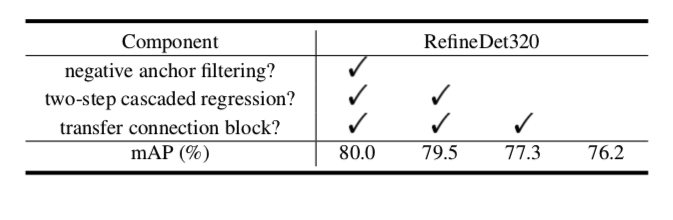
- Negative Anchor Filteringはちょっと効いてる
- ARMで不要なものを取り除くのはとくに訓練時に効果がありそう
- Two-step cascaded位置調整が実は一番効いてて面白い
- No Transfer Connection BlcokなしモデルはSSD300のmAP=77.2にすら負けてる
- SSDの下位互換なので残当
- TCB同士のconncetionを切断するだけとかのほうが比較実験として絶対いいと思う
MS COCOを使った事前訓練
- Pascal VOCの物体クラスはMS COCOに含まれているので、パラメータを一部取り除くだけで直接fine tuningできる!うれしいね
- 性能は更に上がる⤴
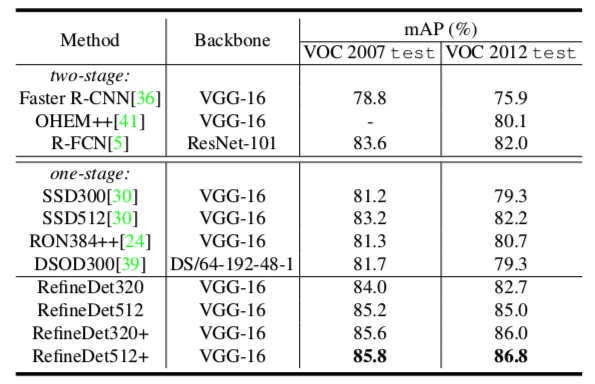
- RefineDet512+の記録はVOC2012 LBで5位
- One-stage methodとしては1位
- ほかのtwo-stage methodもResNet-101やResNeXt-101のようなもっと深いネットやアンサンブルをしている
- どやその2
この記事はMETRICAの内部勉強会用の資料を改稿して作りました
-
SSD論文においてはdefault bounding boxとよばれている。目的の物体を囲っている箱のこと ↩
-
同僚のYuki03759の記事が補完的な内容になっているので、これを読むのもありである ↩
-
「判定の難しい負サンプル」の意 ↩