Oct 2016, by Francois Chollet (Kerasの作者)
arxiv: https://arxiv.org/abs/1610.02357
何がすごい?
・新たなモデル、Xceptionを提案
・Inception V3にImageNetというデータセットで辛勝
・JFTというデータセットで圧勝
・モデルサイズは殆ど変わらず
Inception概説
Inceptionをつかったモデルの一つであるGoogLeNetはInception Moduleを積み重ねてできている。
- GoogLeNet(とそれに使われたInception Module)は、モデルアーキテクチャを手動で探索せずとも、いろんな深さの層を並列に組んでやって学習すれば自動で探索してくれるのでは?というアイデアに基づいている。
- しかし、これをチャンネル同士の関係性 (channel correlation) の分離という別の視点から考察することにより、Xceptionモデルが生まれた。以下に詳説する:
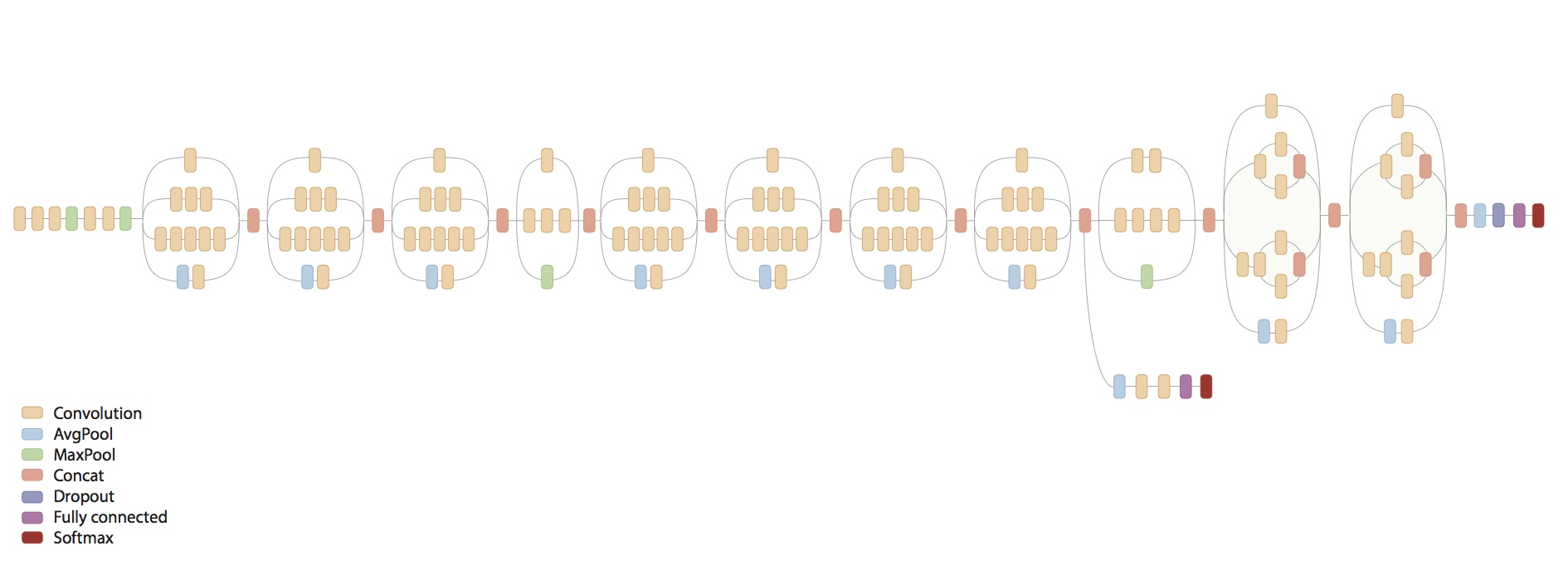
Inception Moduleでは先に1x1 convでチャンネル数を減らし、その後で3x3 convなどをする(図1)。
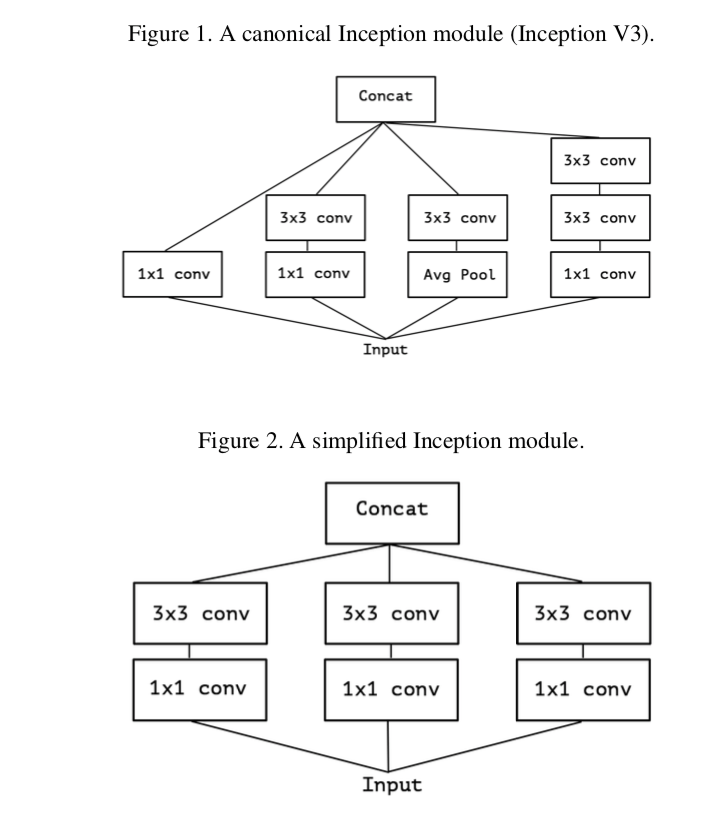
シンプルにしたのが図2。
これは、1x1 convの出力チャンネルが3倍あって、それを3x3 convが分担して受け取っているとも考えられる。
すなわち
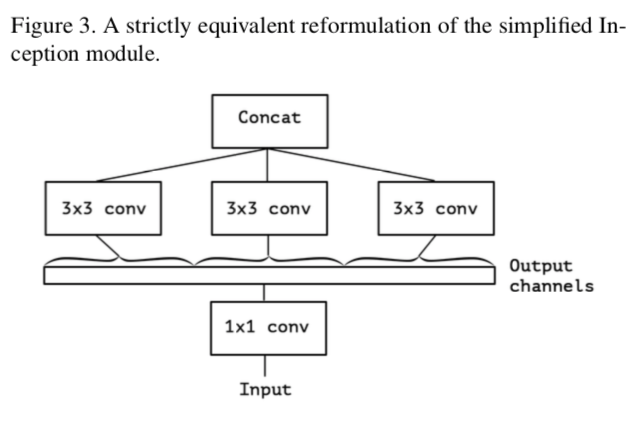
更に、これを極端(eXtreme)にするならば
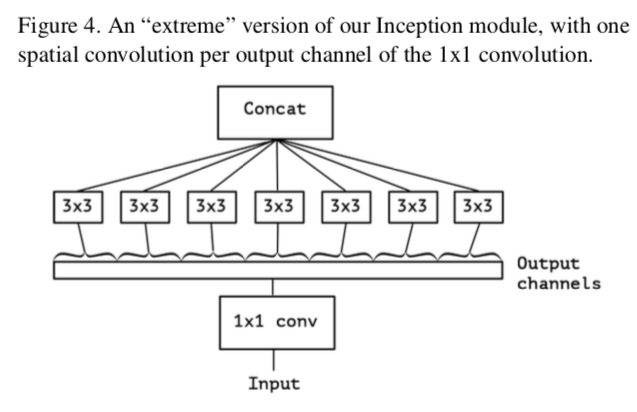
こうなる。
3x3 convの数自体は増えるが、それぞれのconvに対するinput channelを少なくしている(というか1)ので計算量が激減する。
この時、もはや3x3 convは1チャンネルしか入力されていないので、チャンネル同士の関係性を見ることはない。
これをXception Moduleと呼ぶ。
Inception仮説, Xception仮説
Inception Moduleが正しく動くには、channel correlationと空間同士の関係性 (spatial correlation) の計算が(ある程度)分離可能という仮説が必要。
Xception Moduleが正しく動くには、channel correlationとspacial correlationが完全に分離可能という仮説が必要1。
以下豆知識
- Xception はeXtreme inCEPTIONから来ている
- Xceptionは、いわゆるdepthwise separable convolutionにほぼ同じ
- チャンネルごとに独立した空間方向convolutionとPointwise (1x1) convolutionのセット
- つまり、Depthwise separable conv = spacial conv + pointwise conv
- これとは順番が違う(Xception = pointwise + spacial)のと、間に非線形関数(ReLUとかELU)が挟まれないという違いがある。
- 1つ目の違いはどうでもいい。どうせたくさん積み重ねて使うので
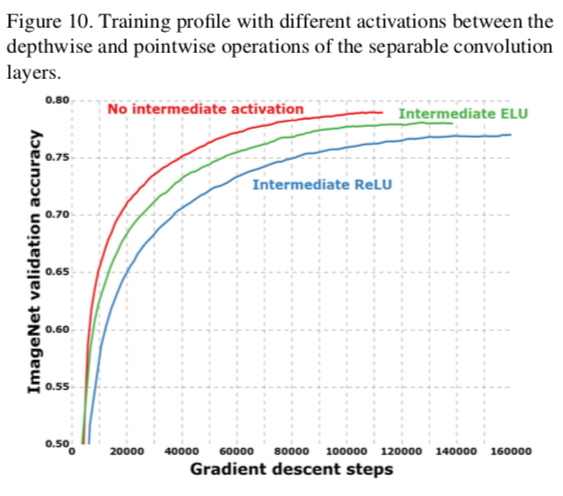
- 2つめは効果ありかも。図10を参照
空間方向のコンボリューションをする前、チャンネルがいくつの独立した部分segmentに分かれているかで分類すると……
- 通常のコンボリューションはすべてのチャンネルが一つになっている
- Inception Moduleは3-4つに分かれている
- Xception Moduleはすべてのチャンネルが独立している
という考察も可能
一番過激なXception仮説に基づいてXception ModelをGoogLeNetと同じくらいのパラメータ数で構築したら圧勝したよ
……というのが今回の理論的バックグラウンド
備考
空間的に分離したコンボリューション (Spacial separable conv) というのもある (1x7conv → 7x1convみたいなの)
- 歴史は長いらしい(2012年の深層学習の勃興以前から計算量の少ない画像処理手法として使われていた。Separable filterなどで調べよ)
- でもCNN的には性能があまり良くないので最近はあまり使われていないとか
Depthwise separable convを使うアイデア自体はMobileNetで提案されていたとか
- なので、今回の論文の新規性は
-
間に非線形関数を挟まないようにしたこと
- MobileNetでは挟んでいる2

-
ResNetライクなSkip connectionを追加して超深層にしたこと
-
- あたりか
アーキテクチャ

- GoogLeNetとかと違って繰り返しが多いのでプログラムするのも簡単
結果
-
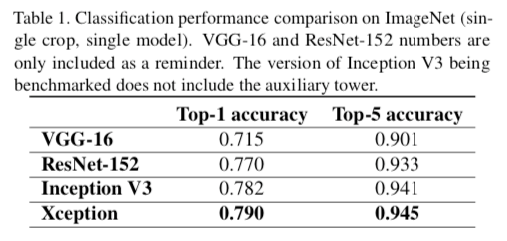
ImageNetで辛勝
-
JFT Datasetで圧勝

-
Inception V3はImageNetに強いのかも?
-
対ImageNetで作られたInception V3はアーキテクチャ自体がImageNetにOverfitしている?
パフォーマンス
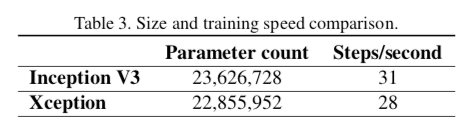
パラメータ数的には互角だが、速さ的には負けた……
負けてしまった理由は、depthwise convolutionの計算の効率が通常のconvに比べて悪いからと思われる。CUDNNとかが最適化されれば同等〜より高速になれるかも3
Residual connectionの効果
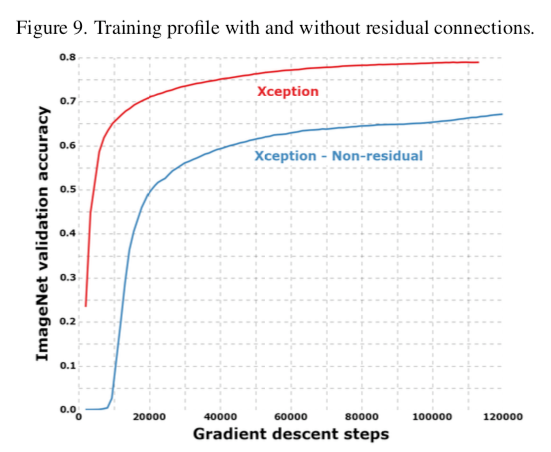
- ありそう
- 最終的な結果ももちろん違うが、それに加えて、収束もより早くなっている。
- 論文では述べられていないが、**Non-residualだと最初のあたりでろくに予測できていない。**これは逆伝播を効率的に飛ばすresidual connectionの効果の一つ。
- ただし、OptimizerなどのハイパラをNon-residualに対しては調整してないのでちょっとハンデになってはいる。
- 別にdepthwise convを使ったモデルにresidualが必須というわけではもちろんない
- convをdepthwiseで置き換えたVGGライクなモデルでも、JFTデータセットに対してはInception V3に勝利
非線形関数を挟むか
GoogLeNetだと挟んだほうが性能が上がったらしい……
が、今回は挟むと下がった
- 中間出力のチャンネル深さによるのかもしれないと考察している
- GoogLeNetだと16~チャンネルあった

- Xceptionは1チャンネル
- Xception仮説に基づいているので
- そのため非線形関数を用いることがチャンネル間の情報を「うまく混ぜる」ことよりむしろ情報を落としてしまうことに繋がり有害なのではないか(今回はそもそも1チャンネルなので混ぜない)
展望
- Xception仮説が完全に正しいかはわからない
- InceptionとXceptionの間にもっといいモデルがあるかもしれない
結論
Inception Moduleは、アーキテクチャ探索を簡単にするために導入されたモデルだったが、それを**「チャンネル方向と空間方向のコンボリューションの分離」**という解釈のもと考察した。
その考察をもとに、もっと過激に『完全分離可能』を仮定したモデルを作ってXceptionと名付けた。
depthwise convolutionはInception Moduleと同じような性質(depth/space separation)を持つしプログラムしやすいからこれからますます使われそう(実際よく使われている)
この記事はMETRICAの内部勉強会用の資料を改稿して作りました