訓練プロセス、損失、モデル改良を提案して計算量をほとんど変えないまま物体検出の制度を向上させた論文。それら3つをまとめてLibraと呼んでいる。分かりづらい。正直やめてほしい
どれも、既存のモデルに追加して精度を向上させることができるアイデアである。
intro
これまで様々な物体検出モデルが検出されてきたが、訓練プロセスはあまり注目されてこなかった
物体検出の訓練を成功させるには
- 画像の選択された領域(いわゆるdefault bounding box)が代表値として適切か
- 抽出された特徴量が十分に使われているか
- 目的関数は適切か
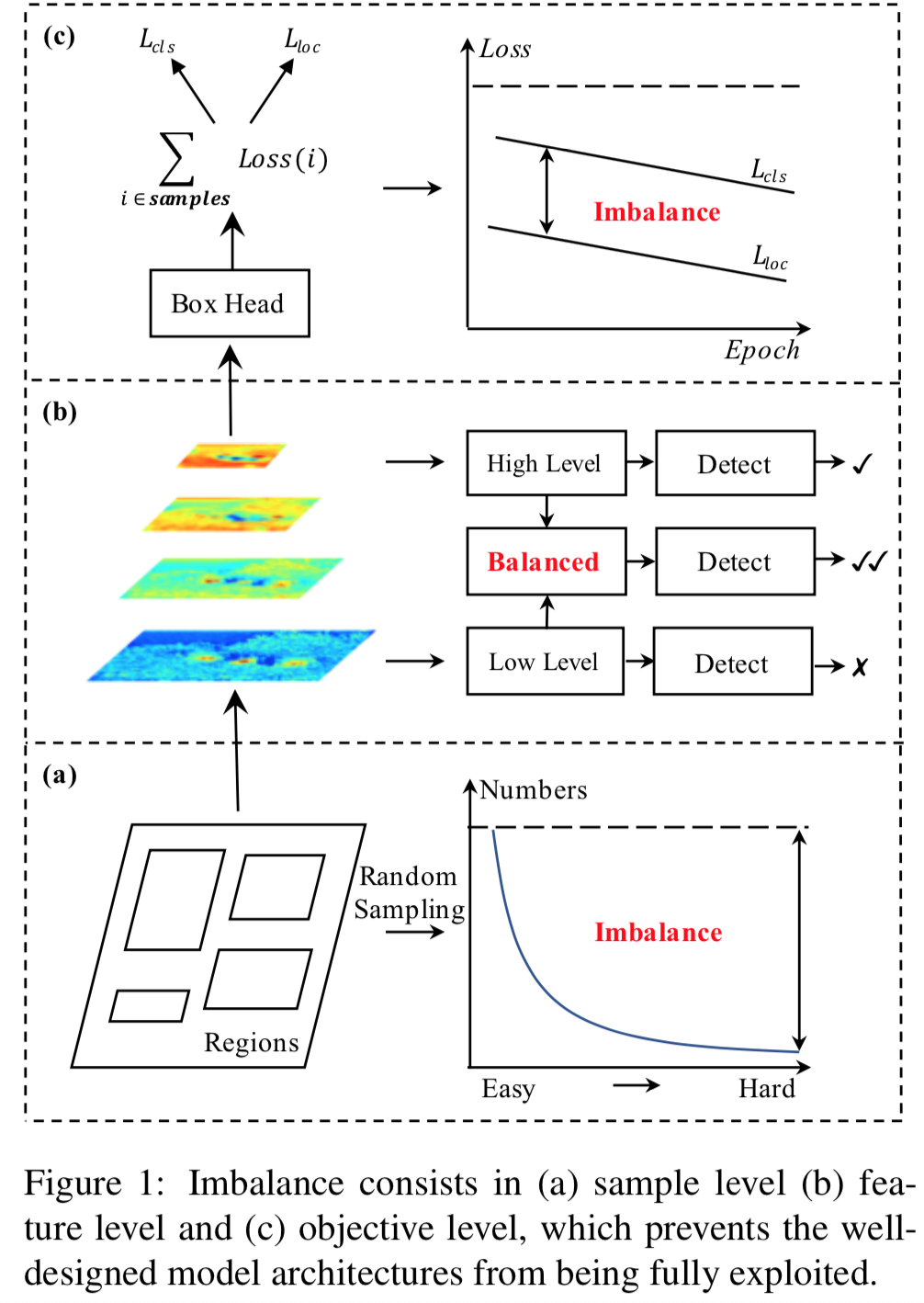
が必要だが、著者らによるとどれも適切に達成されていない。それぞれをSample/Feature/Objective level imbalanceとよんで、解決策を提案している
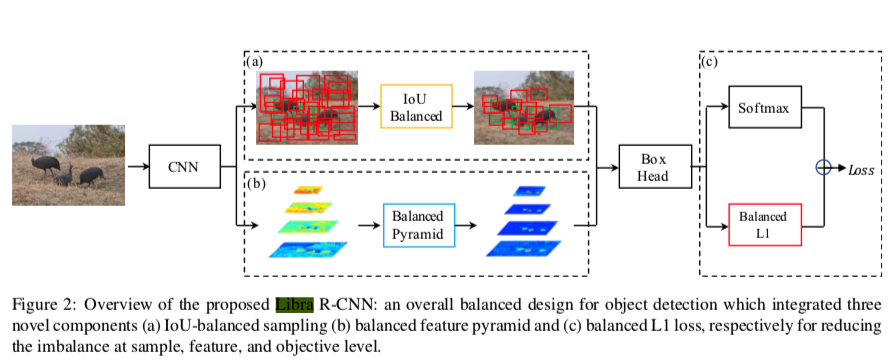
上の図で黄色、青、赤の箱がそれぞれの改善に対応している。
では、それぞれ見ていこう:
Sample level imbalance
物体検出機の学習にはhard sample(難易度の高いサンプル)をたくさん与えてやることが非常に重要だが、ランダムに選ぶとeasyが殆どになってしまう。
既存手法としてOHEM, Focal Lossがあるが、
- OHEM
- ノイズラベルに弱い
- 計算量、メモリが重い
- Focal Loss
- 2-stage methodだとeasy negativeが1つめで除かれてるので(2nd stageの訓練に)意味ない
のような欠点を持つ。
というわけで、IoU-balanced Samplingという方法を考えた
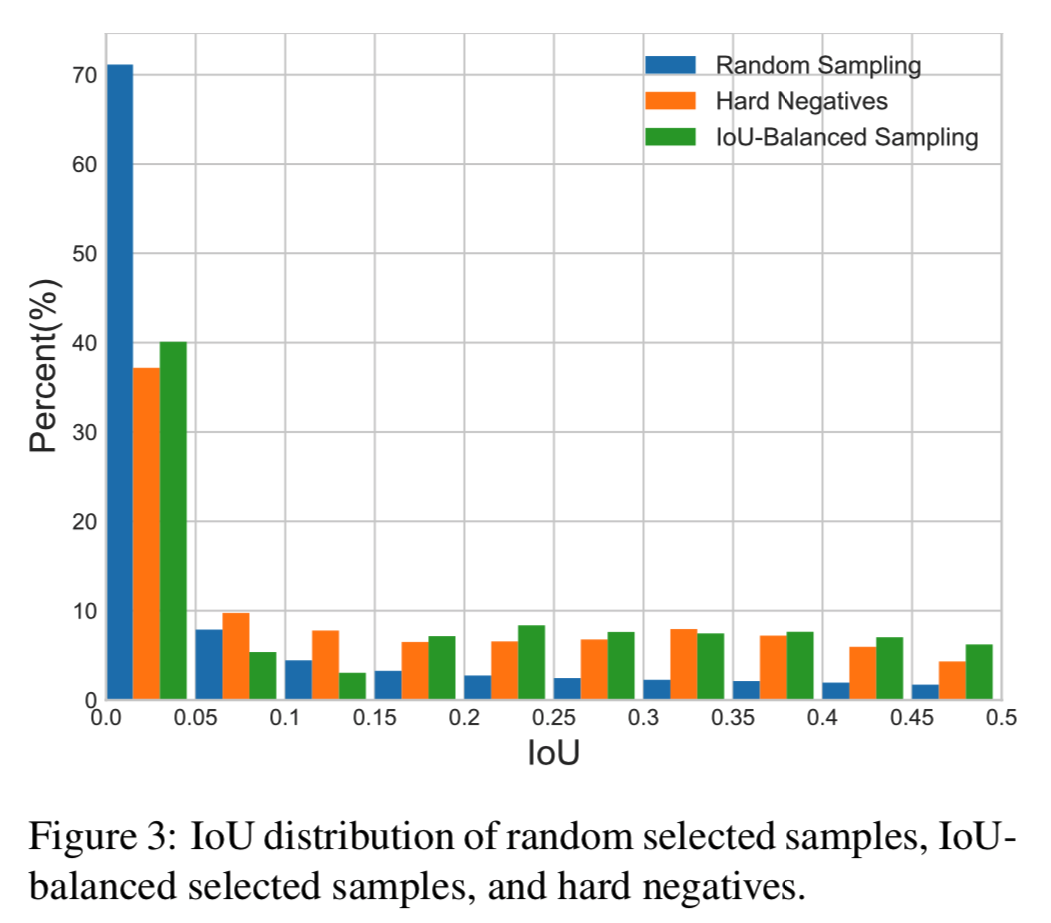
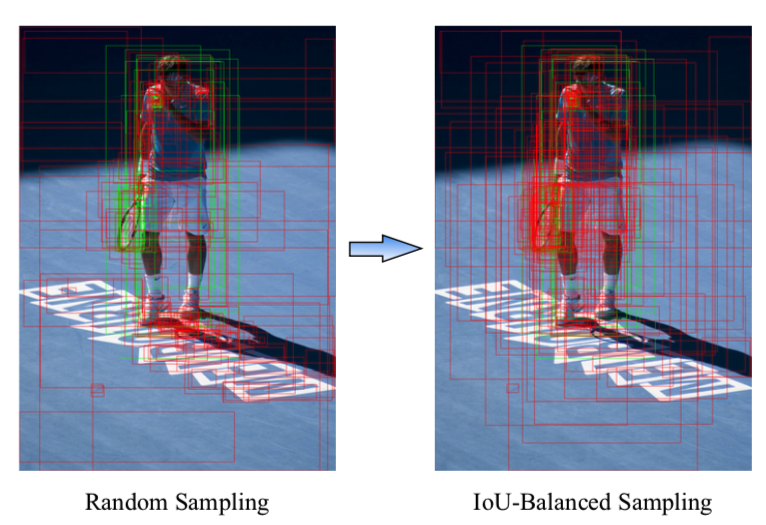
上の図で見るように、Hard negativesは6割以上がground truthと0.05以上のIoUを持つが、ランダムに選んだサンプルでそうなのは3割程度で全然違う。しかし、IoU-balanced Samplingは割と一致している
手法としては単純で、
- 既存手法ではM個の候補からN個のサンプルを取り出している
- $p=\frac{N}{M}$
- IoU順にK個に候補を分割し、それぞれから同じ数だけサンプルを取り出すように変更する
p_{k}=\frac{N}{K} * \frac{1}{M_{k}}, \quad k \in[0, K)
Kが大きいほうがいい気がするが、IoUの高いサンプルがある程度含まれるようになればよいので、Kがいくつかはあまり関係なく精度は向上する。論文ではK=3だった。
positive samplesのimbalance1に対処するのにも使えるようにおもえるが、そもそも数が少ないので難しい。
これに対しては、ground truthあたりのpositive samplesの数を等しくすることで代用している
Feature level imbalance
追加パラメータの不要なintegrateと呼ばれる作業を特徴マップに対して行う。その後にパラメータを使ったrefineという作業を行い、更に精度を向上させることもできる。
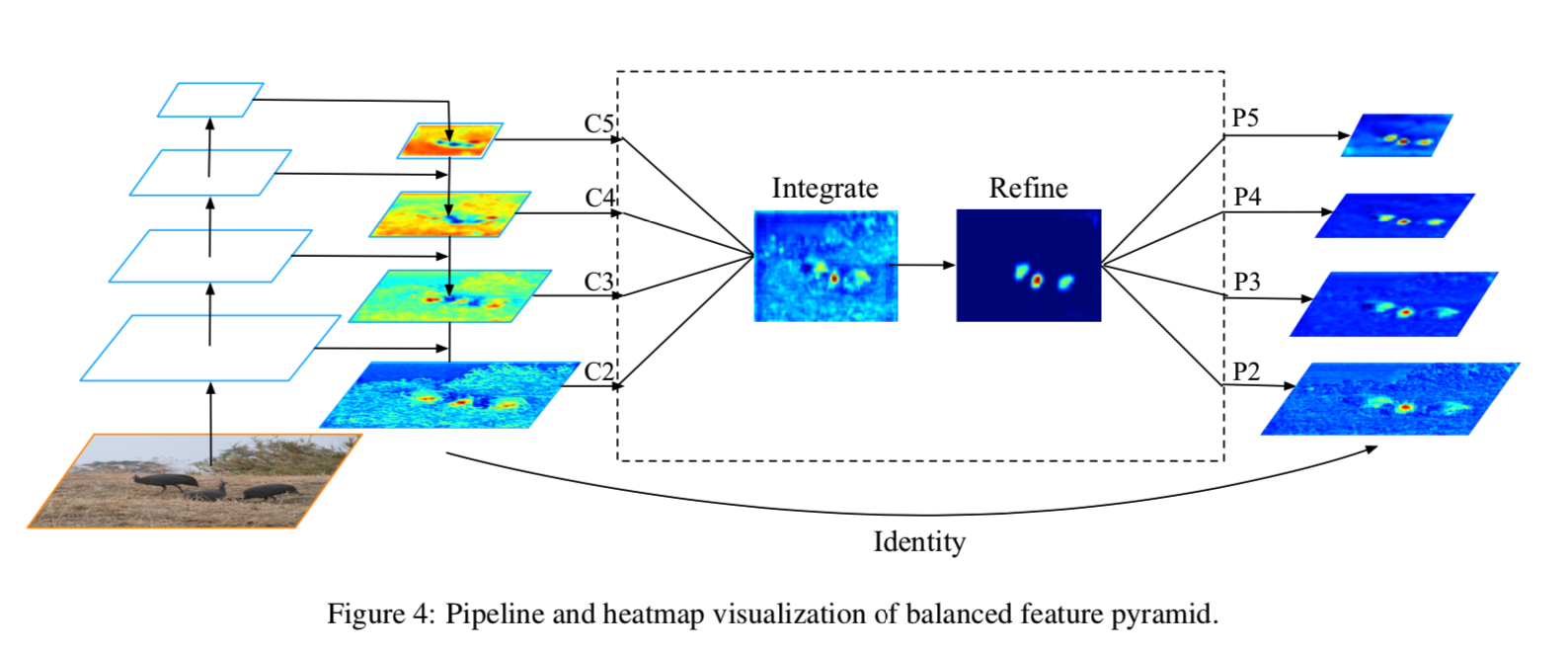
integrateの仕組みは単純で、
- $L=l_{max}-l_{min}$個の特徴量マップをリサイズし大きさを合わせる
- 足しあわせる
C=\frac{1}{L} \sum_{l=l_{m i n}}^{l_{\max }} C_{l}
- もとの特徴量に「足し戻す」(residual connection)ことで、もとの特徴量を強化する
- ここまでの作業にはパラメータが必要ないことに注目
以上。より深い層の特徴量がミックスされて与えられるので、精度が向上するらしい。
さらに追加で、$C$を洗練(refine)することもできる
コンボリューションもありだが、non-local moduleがよりうまく行った
- 論文ではembedded Gaussian non-local attentionを使用
f\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right)=e^{\theta\left(\mathbf{x}_{i}\right)^{T} \phi\left(\mathbf{x}_{j}\right)}
- $\theta , \phi$はそれぞれ行列積
- ちなみに、これは
\operatorname{softmax}\left(\mathbf{x}_i^{T} \mathbf{W}_{\theta}^{T} \mathbf{W}_{\phi} \mathbf{x}_j\right)
……と書くこともできるので、特徴マップのattentionとみなすこともできる
Objective level imbalance
よく見るロス2
L_{p, u, t^{u}, v}=L_{c l s}(p, u)+\lambda[u \geq 1] L_{l o c}\left(t^{u}, v\right)
の$L_{loc}$に関して考える。
著者らの実験によると、誤差が1より大きいものが勾配の70%位を決めている。つまり、大幅にハズしてしまった予測に基づいて学習してしまっているということになるなので、バランスの取れたロス$L_b$を考える。
\frac{\partial L_{b}}{\partial x}=\left\{\begin{array}{ll}{\alpha \ln (b|x|+1)} & {\text { if }|x|<1} \\ {\gamma} & {\text { otherwise }}\end{array}\right.
ただし、$b$はこれが$x=1$で連続になるように調整する。
こうすることで、誤差が1より小さくても、0に近くない限り傾きが大きくなる。下図を参照。
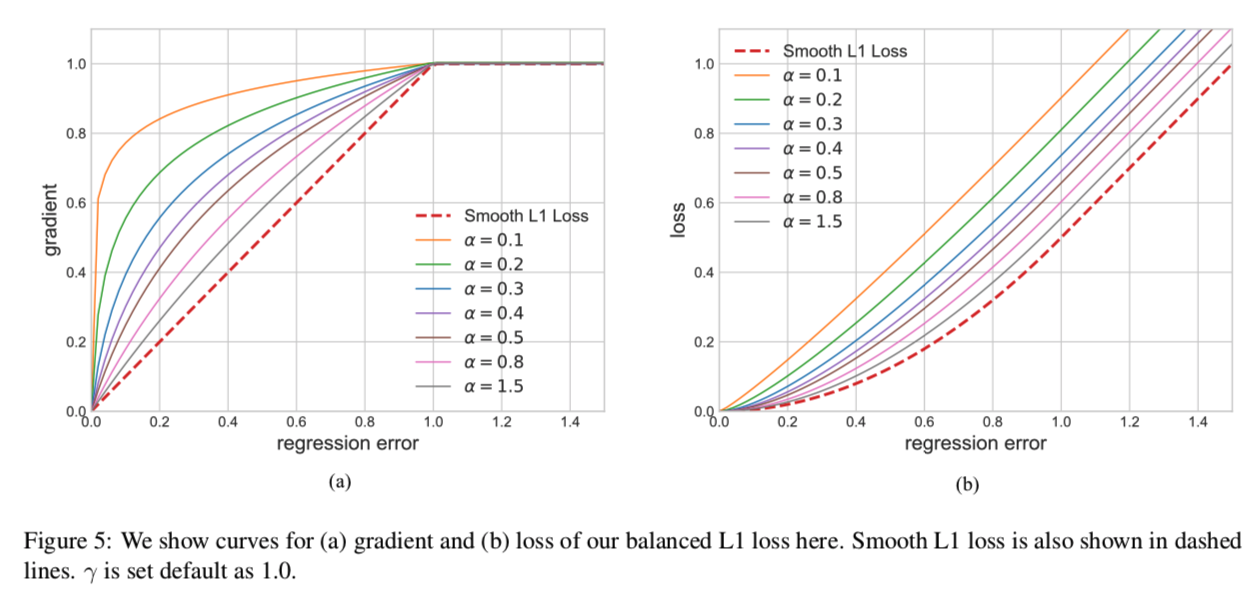
なお、$\alpha$が小さいときはL1 Lossに近似していることもわかる。Smoothed L1とL1の間をパラメータで決められるようになったLossと考えられる。
結果
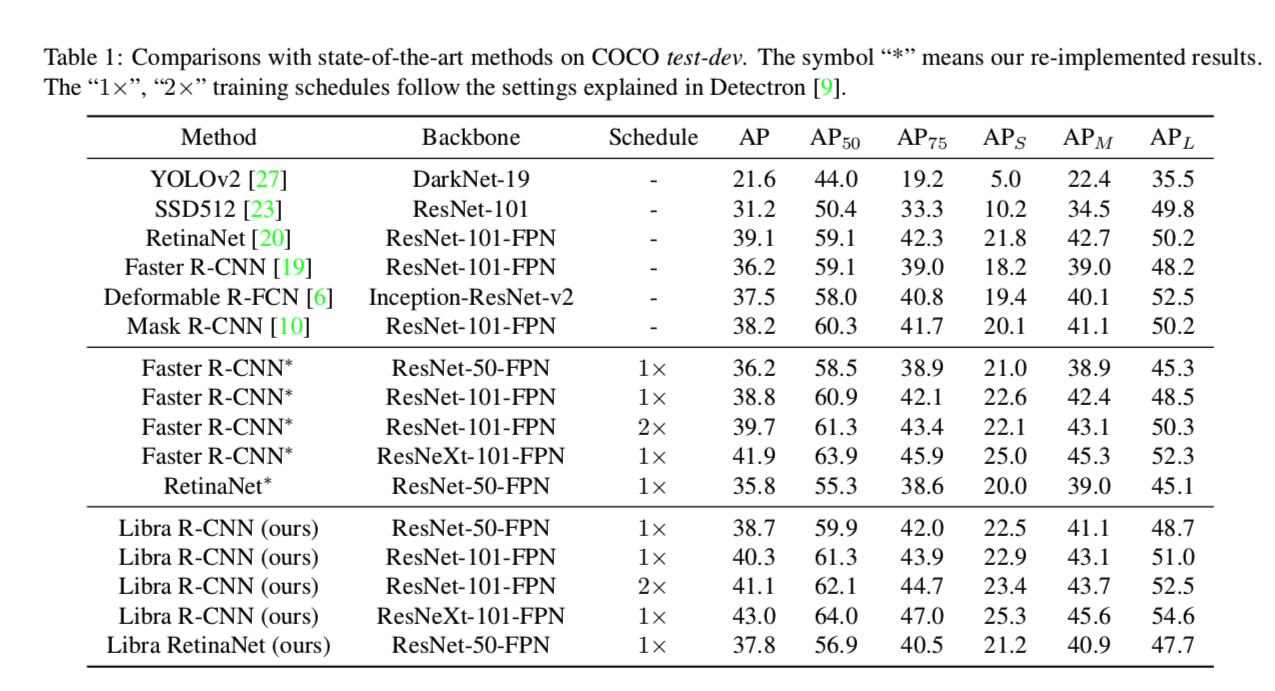
Libraを導入することで性能が向上しているのが見て取れる。なお、右にアスタリスクのついているものは著者らによる再現実験。
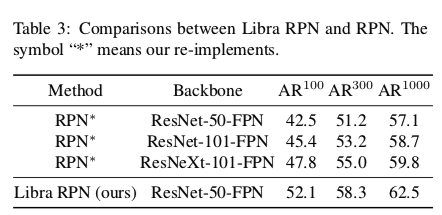
Libraによりbackboneがしょぼくてもaverage recallも向上している
このような向上が見られたのは、RPNの潜在能力をバランスの取れた訓練により発揮させられたからと著者は考えている
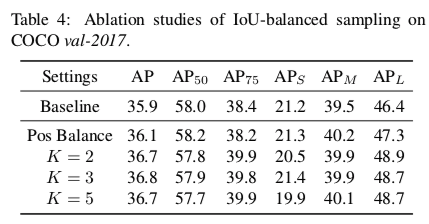
PositiveをBalanceしてもそこまで性能は向上せず。
- そもそも数が少ないので、学習にあまり影響しなかったものと思われる
しかし、K=2にするとすごく向上した
- K=3, 5にしてもあんまり向上せず。hard negativeがある程度選ばれることが重要だったことがわかる
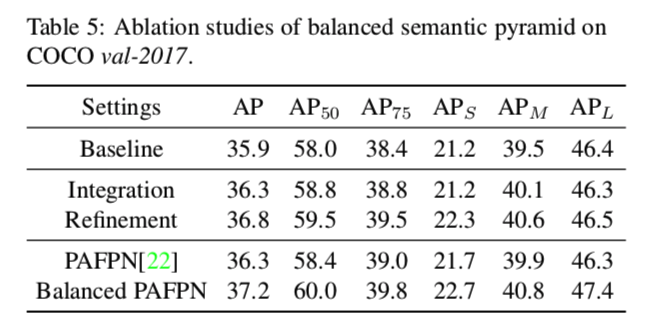
PAFPNと比べてみた。特徴マップをintegrateしただけ(パラメータ数増えてない)でベースラインモデルでも性能が同等に。
Feature balancingはPAFPNのような既存のモデルに「中処理」として追加できる。PAFPNをbalanceさせることで性能が更に上がった
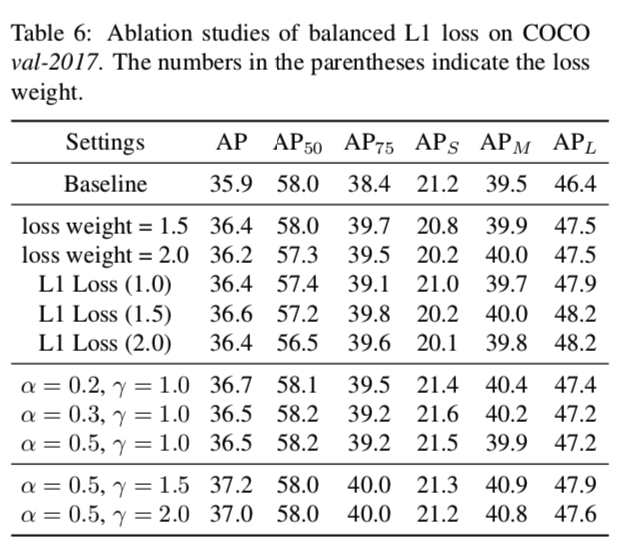
loss weight($\lambda$)と$\gamma$が同じ役割を果たすのに加え、L1とSmoothed L1の間を$\alpha$を用いてフレキシブルに調整できるのが強み。すなわち、$\alpha$が小さいときL1に、$\alpha$が大きいときSmoothed L1に近い。
$\lambda = \gamma$が大きすぎても小さすぎてもAPは下がってしまっている。また、$\alpha=0.5$で一番APが高いことは、L1とSmoothed L1の間によりよいロス関数が存在していたことの証左になるだろう。
感想
3つどれをとってみても、改変自体は小さいながらも納得の行く改良であり、実際にある程度の効果が上がっているのですごいね。とくに、Sample Level Imbalanceへの対処は意外と単純な仕組みで面白かった。
ただ、Feature Level Imbalanceを"Imbalance"と呼ぶのは流石にこじつけに思えるぞ……
この記事はMETRICAの社内勉強会用の資料を改稿したものです