はじめに
この記事では、前回解説した大切な概念である抽象度・文脈に着目して、モジュール分割、モジュールの命名、コメントを分類します。さらに、それぞれのパターンごとにどのようなベストプラクティスがあるか、アンチパターンは何か、アンチパターンをした場合はどのようなデメリットがあるのかについて詳しく見ていきます。この章の内容は普段の開発への応用が簡単で、なおかつ応用したときの設計の改善度が大きいです。ぜひ理解してください。
いいね・ストックが励みになります!
2種類の抽象化
文脈依存性がある抽象化
文脈依存性がある抽象化には次のような特性があります。
- 呼び出し元の処理を理解しやすくする
- 再利用はされない
文脈依存性がある抽象化は、処理の中の独立性の高い一部分を取り出して、その意味を説明します。下位モジュールが提供する抽象化内で具体的に何をしているかは書くべきではありません。
正しい名前の付け方
- 上位の処理の中で何を基準にまとめたのか、役割や目的を書くこと
- 抽象化したはずの内容を書かないこと
抽象化とは、具体的な処理の内容を処理全体が持つ意味で置き換えて隠すことです。したがって、上位モジュールは下位モジュールの名前を見て具体的な内容を想定できてはいけません。このことから、上位モジュールの知りうる知識の範囲で出来るだけ具体的に処理の意味を記述するべきだと言えます。具体例を通じて理解を深めましょう。
// セッションによってステートを管理するWebアプリケーション
// セッションを新しく開始する処理が書かれた上位モジュールの一部
ID id = CreateSessionID();
// この部分に名前を付けたい
XXX(id);
ここで呼び出しているXXX()関数は、内部的にidの内容をsessidという名前の付いたCookieに保存していました。このとき、XXX()の命名のパターンを考えてみましょう。
-
DoProgram():まとめ方が適当すぎる。もっと理解しやすい内容を基準にまとめたはずだ -
SaveData():本当にデータ一般を保存するためだけなのか。もっと詳しく役割を説明できるはずだ -
SaveSessionID():上位モジュールが知っているSessionIDという情報を盛り込んだ -
SaveSessionIDToCookie():上位モジュールはCookieに保存することを知らなくても正しく理解できるため、抽象化を破壊している
名前に必要な情報と不要な情報の区別は、どのような抽象化を提供するかに依存します。したがって、良い命名をするためにはドメイン知識が不可欠です。
モジュール分割の難易度
文脈を保つ抽象化では、モジュールの分割は処理の内容よりも、処理が上位モジュールにおいて持つ意味を基準に行います。そのため、この抽象化を行うモジュールに命名するには技術よりもドメインの理解が必要になります。命名が難しい代わりに、名前とモジュールとして取り出す範囲が決まれば、基本的には機械的にモジュールを分割出来ます。モダンなエディタを使っていれば、リファクタリング機能を活用してボタンひとつで分割可能なことも多いです。
役割
文脈依存性がある抽象化の役割は、上位モジュールの処理の流れに意味を見出して抽出することです。
上位のモジュールのモジュール名は、命名がモジュール全体なので、その処理手順を抽象的ないくつかのグループに分割することが出来たとしても、その方法について述べることが出来ません。そのため、文脈依存性がある抽象化が必要なのです。
文脈依存性が無い抽象化
文脈依存性が無い抽象化には次のような特性があります。
- 呼び出し元の処理はあまり理解しやすくならない
- 再利用性が高い
文脈依存性が無い抽象化は、再利用の単位です。
正しい名前の付け方
- 呼び出しうるすべての文脈について矛盾しない名前であること
- 出来るだけ役割や目的を分かりやすく説明する名前であること
- 抽象化したはずの内容を書かないこと
文脈依存性が無い抽象化の過程で、モジュールの内容からは文脈を消します。それでも消しきれなかった強い文脈の情報の範囲で命名してください。
例えば、設定ファイルのバリデーション処理を作成しているときに、複数の設定項目で「URLが正しいかを判定する」という処理が書かれていたとします。それらを共通化するため、当該処理を行っている部分を抽出します。(この例では、Go言語を使います)
u, err := url.Parse(OIDCIssuerURL)
isValidIssuerURL := err == nil && u.Scheme != "" && u.Host != ""
ここでは、なにやらOIDCのIdPについての設定をバリデーションしていることが変数名から分かってしまいます。しかし、URLの正しさの判定処理自体の文脈はURLを用いるアプリケーション全てなので、これは取り除くべき文脈であることが分かります。その結果、次のような文脈依存性が無い抽象化が完成します。
func isValidURL(toTest string) bool {
u, err := url.Parse(toTest)
return err == nil && u.Scheme != "" && u.Host != ""
}
モジュール分割の難易度
そのため、この抽象化を行うモジュールの命名にはドメインの知識よりも技術の知識が重要です。分割前のモジュールが持っている各変数や処理への意味を排除する必要があるため、サブモジュールを書くためにはどのようなインターフェースにすれば使いやすいか、汎用的かを見定める技術力が必要です。
役割
文脈を保持しない抽象化の役割は、複数の文脈で再利用できる具体的かつ汎用的な処理を抽出することです。この抽象化を行うことで、コードの重複を防ぎ、汎用的な処理を扱いやすい形で提供することが出来ます。
全体の仕組みを示す図
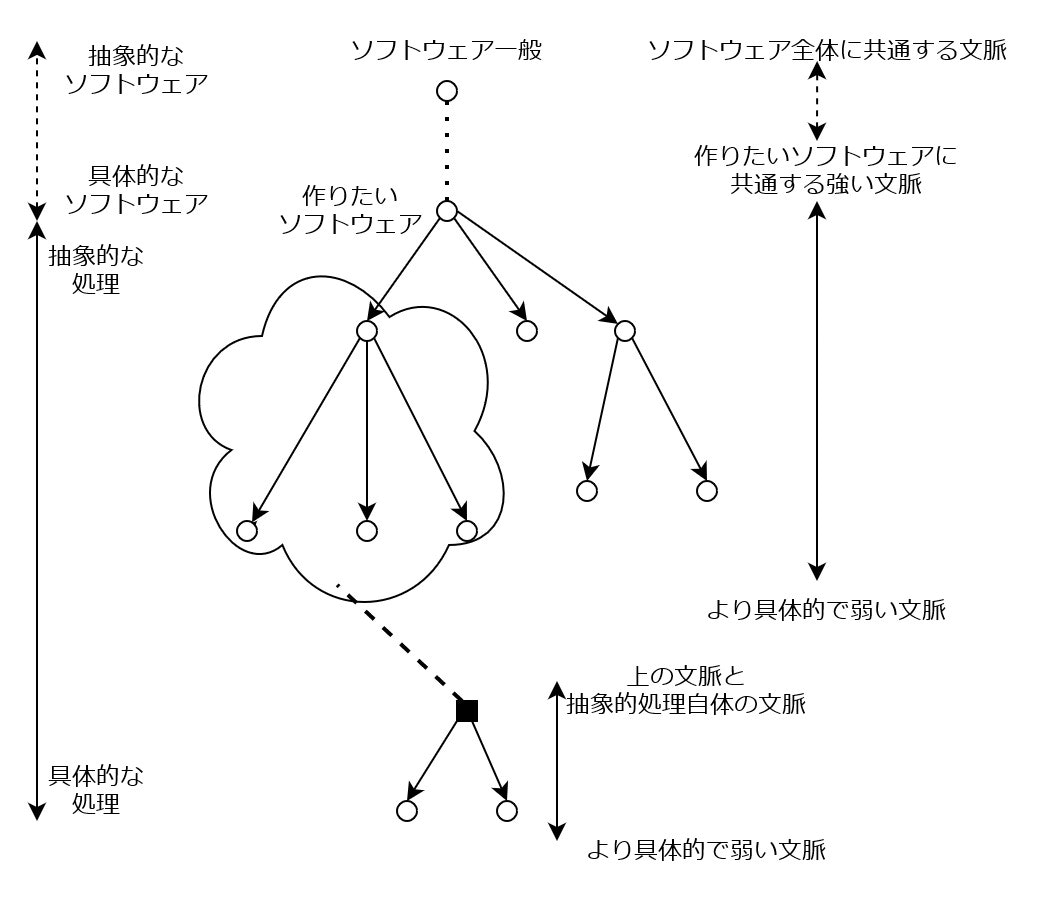
この図は、ソフトウェアにおける文脈依存性の無い抽象化と文脈依存性のある抽象化がどのように協力しているか、それぞれの抽象度・文脈はどのようになっているかを示しています。
文脈を依存性がある抽象化において、上位モジュールは役割を示す名前で下位モジュールを呼び出しています。文脈依存性がある抽象化によって下位モジュールの具体的な実装を理解しなくてもよくなります。そのため、考えることが減って、処理の理解の難易度が下がります。
このことをグラフ上で考えると、丸いノードの処理内容を理解するには、自分自身の処理に加えて、その直下の丸いノードのモジュール名およびシグネチャを理解すればよい、というように言い換えられます。
このように少しずつ抽象化を繰り返してそれぞれのモジュールの複雑性を下げることで、人間が把握しきれるレベルまで認知負荷を下げています。
文脈依存性が無い抽象化において、下位モジュールは呼び出し元の文脈のうち、一定以下の強さのものをすべて忘れます。これを示しているのが、図の黒い四角形です。この四角形は、雲で囲われた範囲の根ノードまでの強さの文脈を持ちます。これにより、雲に覆われた範囲で表されているような文脈の範囲に限り再利用することが可能になります。
具体例
ここではoauth2proxyというアプリケーションを題材にします。このアプリケーションは、簡単に言えば外部からのリクエストを参照して、知らないセッションならばOIDC認証を要求し、知っているセッションならば通過を許すリバースプロキシです。サンプルコードを筆者のGitHubで公開しています。
このアプリケーションでは、セッション単位の情報を保持する必要があります。そのため、複数のゴルーチンの間で共有できるデータ領域が必要です。この処理を行うライブラリとしてgo-cacheを使っています。これを使ったセッション単位の情報の保持の抽象化の階層は次のようになります。
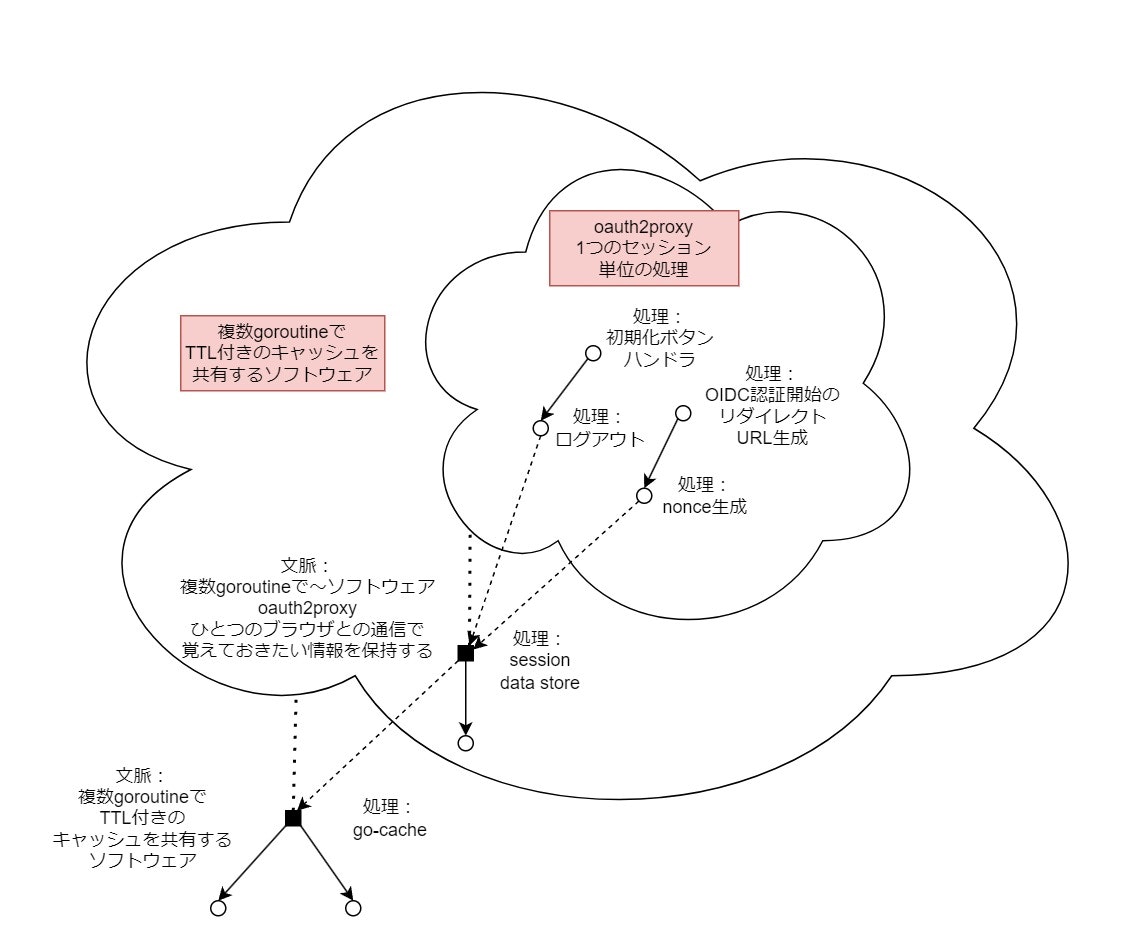
より文脈が少ないモジュールから順に解説していきます。まずは、go-cacheの使用方法を見てみましょう。
// 文脈:複数goroutineでTTL付きのキャッシュを共有するソフトウェア
// 一部を抜粋しています
// キーとそれに対応する値を設定する
func (c *cache) Add(k string, x interface{}, d time.Duration) error {
// 省略
}
// キーに対応する値を置き換える
func (c *cache) Replace(k string, x interface{}, d time.Duration) error {
// 省略
}
// キーに対応する値を取得する
func (c *cache) Get(k string) (interface{}, bool) {
// 省略
}
どのようなキーが使われるのか、どのような値が使われるのかについては全く知りません。例えば、戻り値の型はinterface{}であり、これはC#におけるobject型のようなもので、汎用的なものです。したがって、文脈が少なく、だからこそ一般公開されてたくさんの人に再利用されるOSSとなったわけです。
次に、go-cacheを利用したoauth2proxy特有のセッション情報保持用のモジュールを見てみます。
// 文脈:oauth2proxyにおいて、セッション単位で情報を保存する
// 一部を抜粋しています
func SetNonce(id sessionid.ID, nonce string) error {
key := getNonceKey(id)
return dataStore.Add(key, nonce, temporaryExpireTime)
}
func SetState(id sessionid.ID, state string) error {
key := getStateKey(id)
return dataStore.Add(key, state, temporaryExpireTime)
}
func SetRedirectURL(id sessionid.ID, redirectURL string) error {
key := getRedirectURLKey(id)
return dataStore.Add(key, redirectURL, temporaryExpireTime)
}
func DeleteIDToken(id sessionid.ID) {
key := getIDTokenKey(id)
dataStore.Delete(key)
}
func DeleteUserInfo(id sessionid.ID) {
key := getUserInfoKey(id)
dataStore.Delete(key)
}
これはより多くの文脈を持った抽象化です。そのため、再利用できる範囲はoauth2proxyの内部にとどまります。oauth2proxyのセッション情報の保持のためにcacheを利用するという抽象化を行っています。このような文脈の追加によって、次の情報が使えるようになります。
- 保存するデータは
nonce,state,redirect URL,ID Token,UserInfoの5種類である - 情報の保持をするキーはセッションIDである
しかし、oauth2proxyを構成する種々の処理のどこで呼び出されるかについては文脈に持っていません。
最後に、session管理モジュールの使用例をひとつ見てみましょう。
// 文脈:OIDCの認証処理で、不正なログインが試行されたとき
func logout(id sessionid.ID) {
session.DeleteIDToken(id)
session.DeleteUserInfo(id)
}
この関数は文脈依存性のある抽象化です。呼び出し元の関数が固定されているため、多くの文脈を持っています。ここまで文脈を持っていれば、ID TokenとUserInfoの削除がログアウトのためであるという役割を示しています。
文脈を多く持つほど役割を説明しやすいことと文脈が少ないほど再利用がしやすいことの2点がよくわかると思います。
コラム:モジュール名のメトリクス
モジュールの名前にも抽象度と文脈を定義することが出来ます。
文脈
モジュール名の文脈
モジュールの名前だけから、上位モジュールの処理内容がどれだけ分かるか
この定義から考えると、次のことが言えます。
- 文脈を多く含む名前:特定のプログラムから呼ばれることが分かる名前
- 文脈を含まない名前:どのようなプログラムから呼ばれてもおかしくない名前
モジュールの文脈とモジュール名の文脈の間には、次のような関係があります。
モジュール名の文脈の原則
モジュール名の文脈は、モジュールの文脈の範囲から逸脱してはならない
不当に文脈が多い命名の場合、コードの再利用性が下がります。例えば、レシート発行プログラムにおいて、「レシート用紙に1行の文字列を書き込む」というモジュールがあったとき、もともとその処理が「レシート用紙に商品名と価格を印刷する」という処理から印刷部分だけを抽出してきたという歴史的事情によってPrintItemAndPrice()という命名をされた場合、合計金額や店名を印刷する処理など、本来再利用できるはずだった上位モジュールが再利用できなくなってしまいます。
不当に文脈が少ない命名の場合、命名に情報量が不足している場合があります。本来使われるべきでないところから使われてしまう危険性があります。ただし、モジュール名にモジュールの文脈を全て記述する必要はありません。モジュールの可視性・ディレクトリ上の配置によってモジュールの文脈を表現することが可能であるためです。モジュール名は文脈よりも、その文脈の中での役割や目的を表現することに専念したほうが良いです。
例えば同じSerializeモジュールでも、標準ライブラリのシリアライズは多数のモジュールから呼び出されるため、その内容はより汎用的なものになります。逆にあなたのアプリケーションのゲームのキャラクターの情報を管理するモジュールでのシリアライズは何をシリアライズするか明確です。いちいちXXGameCharacterSerialize()という無駄な接頭辞をつける必要はありません。
あくまでも原則は嘘を言わないまでしか保証しません。
抽象度
モジュール名の抽象度
モジュールの名前だけから、このモジュール配下の処理内容がどれだけ分かるか
この定義から、次のようなことが言えます。
- 具体的な名前:処理の内容・実装が分かる名前
- 抽象的な名前:処理の意味・目的・役割が分かる名前
モジュール名の抽象度の原則
モジュール名は、できるだけ抽象的な名前にするべきである
モジュール名の抽象度が誤っていることは、プログラマにモジュール内部を読ませることに直結します。したがって命名の誤りは抽象化の破壊に相当します。
例えば、「ファイルのコピー処理に必要な時間を概算する」という処理に1%のデータ量をコピーする時間を測定して、それを100倍した値を返す()という命名をした場合、本来知らなくてもよかった情報を上位モジュールが知ってしまいます。また、モジュールの内部動作が変更されたとき、例えば、10MBのコピー時間をもとに概算する形式に仕様変更されたとき、モジュール名を変更する必要があります。
アンチパターン:情報の無い命名
情報量の無い命名
命名しようとしているモジュール以外でも通用するような汎用的な命名はしてはならない
情報量の無い命名とは、次のようなものです。
ExecProgram()DoSomething()
これらは、全ての処理に共通する内容を説明しています。「抽象」という言葉の辞書的な意味から、これが抽象的な命名だと勘違いされがちです。しかし、これは抽象的な名前とは呼びません。この名前からは、具体的な処理内容についても、処理の意味についても情報が得られないからです。
これは、実質的に何も言っていないのと同じ名前です。XXX()と書かれているのと同じです。
抽象的な処理vs抽象的な名前
名前が似ているせいで非常に混乱を招く概念として、抽象的な処理と抽象的な名前の区別を説明します。
処理の具体抽象というのは、抽象化によって隠蔽される側と隠蔽された意味だけを使う側のどちらに属するか、という区分を意味しています。本質的に複数のモジュールでの階層関係を意味しており、より多くの隠ぺいを経由している処理ほど抽象的である、ということです。
名前の具体抽象というのは、モジュールが内部的に行っている処理について、どれだけコードからは自明でない意味や役割を表すことが出来ているか、という区分であり、本質的にモジュールとその呼び出し元だけについての問題です。
- 具体的な処理で名前が抽象的な例
加算を実現する回路にはたくさんのパターンがある。これらは極めて具体的で、ゼロイチの信号のレベルまで深く潜ったコンピュータの低レイヤーの処理だが、抽象的に「足し算」という名前が付けられる。
抽象度と文脈の関係性
抽象度と文脈の関係
- 文脈を減らすと、抽象度の上限が下がる
特定のモジュールをなぜ呼び出すのかは、上位モジュールによって定められます。したがって、文脈を減らすと上位モジュールの情報を減らすため、どうして自分が呼び出されていたのかについて忘れてしまいます。例えば、「Redisの特定のキーの削除」を行うモジュールは「削除するキーは必ずセッションIDだし、削除する値はユーザーの情報」という上位モジュールの情報の仮定(文脈の仮定)によって初めて、より抽象度の高いLogout()という命名が出来るようになります。
この性質のせいで名前の抽象度と文脈は一定の関連を持っています。そのため、この2つの概念の区別が出来なくなっている人が多いです。
文脈によって規定されるのは、あくまで名前の抽象度の上限です。したがって、文脈をそのままに、名前の抽象度はどこまでも下げられます。先ほどの例では、DeleteRedisSessionIDKeyedValue()などと命名すれば抽象度が下がります。また、DeleteKVPair()とすれば情報量の無い名前に近づきます。
再利用されうるすべての文脈の中で最も抽象度の高い名前を選ぶべきです。
命名のパターン4種類
文脈依存性がある抽象化の命名+抽象度が高い
-
Option LoadOption():戻り値の型Optionのメンバが上位モジュールの文脈を表している。ファイルの形式がJSONであるとか、読み込み先が別サーバーのDBであるとかを漏らした場合、抽象度が下がる。戻り値の型をより汎用的なDictionary<string, object>にして、ParseJsonという名前にすれば、文脈依存度が下がり、抽象度も下がる -
DrawHPBar():ゲームのUI表示を担当するモジュールの名前である。HPBarという名前が画面に表示する画像の役割を表している。DrawProgressBar()だと抽象度と文脈依存度が両方下がる。DrawRectWithHPLength()だとHPという上位モジュールの文脈を保持したうえで、内部実装が矩形を表示するということがバレるため、文脈依存度はそのままで抽象度が下がる
文脈依存性がある抽象化の命名+抽象度が低い
処理方法について呼び出し元のドメイン知識を使って言及する名前
-
SubAttackFromDefense():上位モジュールの言葉で何をするかを指定している名前。攻撃力と防御力からダメージを計算するというより抽象的な役割が与えられているため、CalcDamage()というより抽象度の高い名前が存在する
文脈依存性が無い抽象化の命名+抽象度が高い
処理方法について低レイヤーの言葉で言及しないで、低レイヤーの処理の意味
PriorityQueue.Add()とかAES.Encrypt()とか内部実装が分からない
文脈依存性が無い抽象化の命名+抽象度が低い
処理方法について低レイヤーの言葉で言及する名前。SetBase64EncodedCredentialToHeader():SetBasicAuth()という意味を表す名前がある。
モジュールのグループへの命名
モジュールのグループ化の原則
- 文脈依存性の有無が異なるモジュールをグループ化してはならない
- 文脈が異なるモジュールをグループ化してはならない
- モジュールの処理の意味に共通性がないものをグループ化してはならない
- モジュールの処理の内容に共通性があるものはグループ化しなければならない
最初の3つの原則については、ある程度当然のものだと理解してもらえるはずです。
最後の原則における、処理の内容のというのは、正確に言えば扱うデータの共通性です。グループ化されるのは、部分的に共通のデータを扱うようなモジュールであるはずだ、ということですね。データではない命令の共通性については、文脈依存性のないモジュールを取り出して再利用するべきですので、グループ化で解決するべきものではありません。
最後の原則は「しなければならない」であることに注意してください。これは、抽象化を守るための原則です。処理の内容は本来モジュールの外部からは抽象化によって隠蔽されているはずです。しかし、関連する処理ではどうしても他の処理内容を知らないといけない場合があります。例えば、decodeモジュールはどうあがいてもencodeモジュールの動作内容を知らなければ実装できませんし、decode単体で変更を行うことは出来ません。つまり、原理的に抽象化が失敗します。したがって、同一グループに含めることによって、抽象化せずに両方の内部実装を読むべきだ、というメッセージを伝える必要があります。
グループ化したモジュールへの命名の原則
- グループの名前は、所属するモジュールが持つ意味の共通部分を述べるべきである
- グループに所属するモジュールは、所属するグループで与えられる情報は省略し、そのモジュールだけが特別に持つ意味を述べるべきである
良いグループ化
-
文脈を持たないモジュールのグループ化の例
-
authenticationグループ:loginとlogoutという意味的に対になっているモジュールをまとめた、これらはログイン中かを記憶する領域を共有する可能性が高いため、処理の共通性もある。似たような例として、chiperグループにおけるencriptとdecriptという対のモジュールについても同様の仕組みが成り立ちます -
listグループ:特定のデータ構造を実現するためのモジュール群。このグループに含まれるモジュールは、AddとRemoveとInsertなどが考えられます。データ構造のためのグループですので、当然データを共通するため処理に共通性があります
-
-
文脈をより多く持つモジュールのグループ化の例
- とあるアプリのボタンUIを制御するモジュール。共通の「サイズ」「座標」というデータを扱うことで「PC」「モバイル」のデザインを書き換える。また、レイアウト遷移時のアニメーションを行う
ここまで読んでピンと来た人もいるかもしれませんが、良いグループ化とは、オブジェクト指向における「正しくprivateフィールドの抽象化を行っているクラス」に相当します。オブジェクト指向プログラミングの定義は、抽象度と文脈の観点で次のように説明できます。
クラス
共通のデータに関連するモジュールをまとめるための機構
オブジェクト指向プログラミング
- モジュール分割が5章で説明する単一責任原則および4章で説明する依存性逆転の原則を正しく守っている
- モジュールのグループ化の原則を満たすようなグループ化のためにクラスを用いる
良く使われる 「オブジェクト指向とは現実世界の存在にクラスを対応させるのだ」 という設計指針は、基準に分割するべきなのか分かりません。ここで与えた説明は圧倒的に解像度が高く、客観的にオブジェクト指向プログラミングが出来ているかを検証しやすいと思います。
2段階グループ化
意味と内容の両方が共通であるものだけをグループ化できるならば、常にそうするべきです。しかし、現実にはそうはいかない場合もあります。それは、処理の意味に一定の共通性を持った、処理の内容の異なるモジュールが複数存在する場合です。
1段階目で意味を基準にまとめ、2段階目で処理を基準にまとめるようなグループ化の手法です。(論理的に考えれば逆の順序の分割は不可能です)
典型的な2段階グループ化は、インターフェースの実装を1つのディレクトリにまとめることです。
- dataProvider:意味の共通性はありそうだが、内容の共通性はなさそう
- solver:意味の共通性はありそうだが、内容の共通性はなさそう
アンチパターン:技術的パターンでのグループ化
技術的パターンだけが共通しており、意味も処理も共通していないようなグループ化をしてはならない
技術的パターンでのグループ化とは、次のようなものです。
middlewareplugin
middlewareやpluginとはただの処理のパターンです。このようなグループ化がされている場合、ある決まったインターフェースを満たすのかもしれませんが、これらは、たかだか「Webアプリケーション」や「外部から拡張可能なソフトウェア」程度の文脈しか持たない、文脈依存性のないパターンです。つまり、グループ化しても意味の共通性も処理の共通性も見出せません。
アンチパターン:文脈依存性が無いことだけを示すグループ化
文脈依存性が無い、という共通点だけで同一のグループにまとめてはならない
文脈依存性が無いことだけでグループ化する、という文字だけを見ると難しそうですが、具体例を見ればすぐにわかります。以下のようなファイルに共通モジュールが全てごっちゃに書かれているパターンです。
common.javautil.goshared.tslibrary.cs
このようなファイルが矛盾の塊になってしまいがちなのは経験的に知られてきました。これは、意味にも処理にも共通性がないモジュールが同一のファイルにまとめられることで、どこまでが隠蔽したい内容でどこまでが外部に対して約束する役割なのかが分かりにくくなってしまうことが原因です。
ただし、2段階グループ化と同様の考え方で、文脈依存性が無いモジュールの中でさらに細分化して、common/意味名/処理名.jsなどと分類している場合、問題ありません。
命名の限界
- どれだけいい命名をしようが、命名によってモジュールの分割の不備をごまかすことは出来ません
- どれだけ適切にモジュールを分割しようとも、命名によって設計意図を台無しにすることが出来ます
コメント
コメントに関して、最も有名な設計指針は次のようなものでしょう。
Howはコードから分かるのでコメントにはWhyを書こう
あるいはより詳しくこのような格言もあります。
HowよりもWhatを書こう
WhatよりもWhyを書こう
WhyよりもWhy Notを書こう
これらのコメントに関する原則は、文脈依存性のない抽象化が理解の役に立たないことに対応しています。
モジュール名はコメントと同じ意味を持つことが分かりやすいのは次のような2つのコード例です。
// 足し算を行う
1 + 2
AddValue(1, 2)
static int AddValue(int a, int b)関数は呼び出した上位モジュールについて、足し算が必要な処理をすることしか分からないため、これは典型的な文脈依存性のない抽象化です。2つのコードを見比べれば、読者の得られる情報が等しいと分かります。つまり、モジュール分割の持つ「処理に名前を付けることで処理の流れを分かりやすくする機能」が文脈依存性のない抽象化の場合は全く存在していないのです。
Whatは文脈に依存する内容です。その処理が結局何をしたいがための処理なのかは、上位モジュールの内容、つまり文脈によります。したがって、文脈を保持する抽象化に適切に名前を付けると自然とWhatになります。
Whyも同様に文脈に依存する内容です。加えて、プログラム内部では表現しにくい情報です。例えば、ダメージ計算プログラムで「攻撃力計算」「防御力計算」「合算」という3つの文脈依存性のある抽象化が出来たとしても、結局なんでダメージ計算が必要なのか、どうして3ステップなのかについては分かりません。コードでは説明できないことなので、コメントで説明する価値があります。
【動画付き・初心者向け】コメントにはWHYを書こう 〜不要なコメントと必要なコメントの違いについて〜
文脈依存度の観点から解釈するコメントの種類
- How:文脈が少ないコメント(別のモジュールでもまったく同じコメントが書かれていそう)
- What:文脈が多いコメント(特定のモジュールの特定の場所でしか役に立たないことが書いてある)
- Why:文脈が多い上にコードでは説明しきれない事項を説明するコメント。Whatとの区別は状況による
- Why Not:Whyの一種。コードには「やらないこと」を書かないため、原理的にWhyの特徴を満たす
悪いコメントのパターン
この節では、コメントのアンチパターンについて、その対処方法と合わせて網羅的に説明します。
不当に文脈の少ない抽象化+Howのコメント
呼び出し元における役割をサブモジュール名で説明することなく、しかもコメントでも見ればわかるようなことだけを説明しています。
// aとbの合計を計算する
Sum(a, b);
対処法は次の2点です。
- コメントの削除
- 変数・モジュールの命名をより抽象的に変更
適切な抽象化+Howのコメント
コメントによって抽象化が破壊されています。モジュールの内部の処理だけ書き換えた場合、コメントが嘘をつきはじめます。Whatのコメントは、モジュールの役割自体が変わらない限りは嘘をつきません。
// magazineテーブルとuserテーブルの連関エンティティであるMagazineSubscriptionに新しいレコードを追加する
db.SubscribeMagazine(userId)
対処法は次の1点です。
- コメントの削除
不当に文脈の少ない抽象化+Whatのコメント
このパターンは、モジュールの命名の失敗をコメントで無理やり誤魔化しています。コメントで頑張っている場合ではありません。このままでは、モジュールの呼び出しのすべての箇所で同じコメントをしなければなりません。設計論の書籍でコメントが不吉な匂いとして紹介されるのはこのパターンのコメントを想定しています。
// もっとも勝率の高いメンバーを選出する
FindMaximumValue(memberList)
対処法は次の2点です。
- コメントの削除
- 変数・モジュールの命名をより抽象的に変更
適切な抽象化+Whatのコメント
同じことを2重に書き込んでいます。このとき、コメントは新しい情報を提供しません。
// 指定したユーザーを購読者としてDBに登録する
db.SubscribeMagazine(userId)
対処法は次の1点です。
- コメントの削除
コメントの原則
ここまでで、「Whyを書け」という格言の合理性について検証してきました。以下は、「Whyを書け」が何を意味しているのかについてより厳密な形で表した原則です。
コメントの原則
- 文脈依存性がある抽象化で代替できる内容を書いてはならない
- 特定のモジュールの役割や意味について、どうしても名前で表しきれない情報について記述しなければならない
より進んだ学習
本連載はコメントに関するものではないため、これ以上深入りはしません。より詳しい内容は、リーダブルコードの第5章「コメントすべきことを知る」や第6章「コメントは正確で簡潔に」にもより分かりやすく実践的な形で書かれています。
不十分なモジュール分割の分類
モジュールの分割が足りない場合に発生する問題を説明します。
文脈を保持する抽象化が出来ていないパターン
必要な抽象化を行わずに直接文脈依存度が低いモジュールを呼び出しているために、何をやっているかが分かりにくいです。
競技プログラミングのコードが読みにくいと言われるのはこれが原因です。直接標準ライブラリや汎用的な処理を呼び出していたり、変数名が全部1文字だったり、Main()以外に関数が存在しなかったりするようなコードは文脈依存性のある抽象化が不足しています。以下のコードは筆者がAtCoderに提出したものを一部修正したものです。
public static void Main()
{
long Q = long.Parse(Console.ReadLine());
List<long> A = new List<long>();
List<long> B = new List<long>();
for(int i = 0;i < Q; i++)
{
var q = Console.ReadLine().Split(' ');
long x = long.Parse(q[1]);
switch(q[0])
{
case "1":
A.Add(x);
break;
case "2":
B.Add(A[(int)(A.Count - x)]);
break;
}
}
for(int i = 0; i < B.Count; i++)
{
Console.WriteLine(B[i]);
}
}
文脈を保持しない抽象化が出来ていないパターン
文脈の多いモジュール内部に文脈の少ない処理が書かれている
文脈の少ない処理は、定義上汎用的な処理であるため、コードの複数の箇所で現れます。しかし、文脈が多いモジュールの内部に閉じ込められている場合、それを呼び出すことは出来ません。
ホテルの検索アプリのモジュールに、指定された範囲の金額のプランを取り出すモジュールがあり、内部で二分探索をしていたとします。このとき、別の家電販売のWebアプリのバックエンド処理の内部で、指定されたサイズの範囲のTVを見つけてくる処理で二分探索を使いたくなったとしても、GetHotelPlan()を呼び出して、二分探索を再利用することは出来ません。
その結果、文脈を保持しない部分のコードのコピペが横行します。
本来文脈依存度が低い処理だが、名前の付け方に文脈が残っている
このパターンでは、モジュール分割自体は成功しています。したがって、厳密にはここに書くべきではないですが、モジュール名以外の命名にも関係するので一応触れておきます。
以下の部分に不要な文脈が含まれないようにしてください。
- モジュール名
- ローカル変数名
- コメント
先ほどの例でいえば、ホテルのプランを二分探索している処理から汎用的な検索処理を取り出すときに、変数名にhotelXXXが混ざっていると混乱を招きます。
不適切なモジュール分割の分類
モジュールの分割をしすぎている場合に発生する問題を説明します。
抽象化に失敗しているパターン
モジュール内部の処理を上位モジュールもしくは別の下位モジュールが把握している
外部への入出力は全て引数と戻り値で行うべきであって、勝手に書き換えてはならない。
もちろん、名前で内部実装をばらすのはNGです。
コラム:驚き最小の原則
抽象化された内容は上位モジュールが知らなくていい内容のはずです。つまり、抽象化に失敗したモジュールを使う場合、知らなくていいと言われているはずのことを知っていないといけないわけなので、コードを読む人間は「え、内部でこんなことをしていたの!?」という驚きます。このような悪い驚きはソフトウェアの理解を困難にします。
このような問題を減らすための設計原則が驚き最小の原則です。結城浩さんのプログラマの心の健康によれば、これは次のような意味です。
「どうしようかな?」と思ったときには、 相手の「驚き」を最小にするような選択をすべきなのです。
この連載では、ソフトウェアモジュールについて特化しているため、次のように言い換えます。
モジュールのあらゆる動作について、プログラマには必要最低限の知識だけを求めるべきだ
驚きを減らす設計についてより具体的な知見が@tatesukeさんのあっと驚かせるJavaプログラミング(をやめよう)に書かれています。
この原則をさらに推し進めると関数型プログラミングにおける純粋関数の概念にたどり着きます。
- 冪等性:引数以外から情報を読み取らないため、同じ引数に対して同じ結果を得る
- 副作用がない:戻り値以外にデータを出力しないため、実行するだけではソフトウェアの状態は書き換えられない
純粋関数にすれば、少なくともサブモジュールが何処にデータを読み書きするのかを探すためにコードの中身を読む必要はありません。また、処理の内部ではプログラムの状態を変更しないため、知らない間に変数が書き変わっていることはありません。そのため、驚きが小さくなります。
純粋関数で構成されるサブモジュールは抽象化に成功しやすいですが、抽象化に成功していてかつ純粋でないサブモジュールを作ることも可能です。純粋関数でも抽象化に失敗する条件はなにかなどを詳しく解説すると関数型プログラミングの解説になってしまうため、ここでは深入りしません。
文脈を保持しない抽象化の内容が少ない
文脈を保持しない抽象化は、一定以上の複雑さを持った処理を行う必要があります。
逆に、文脈を保持する抽象化は、1行どころかただの足し算だけでも存在価値があります。
int Subtract(int a, int b)は意味ないですが、int GetGrossProfit(int salesRevenue, int cost)には意味があります。
※粗利益=売上-原価という関係式から、2つ目の関数の内容はただの引き算であることが予想できます。しかし、この関係式を知らなくてもいいことこそがこの関数の提供する抽象化です。
文脈を保持しない抽象化が抽象化するのは、上位モジュール上での処理のまとまりの意味ではなく、再利用可能な処理です。したがって、処理に中身が必要です。上位モジュールの気持ちになれば、Subtractを呼ぶぐらいならばマイナス演算子を使って書きたいことは容易に想像できるでしょう。
文脈を保持する抽象化が処理を分割していない
前節で、文脈を保持する抽象化は内容が1行でも意味があると解説しました。しかし、意味があるのは、呼び出しているモジュールに文脈依存性がないときだけです。
文脈依存性のある処理が、1行だけであり、かつ文脈依存性のある処理を呼び出しているとき、何も抽象化していない可能性があります。
- 例:
Discount()の中身が、CalcDiscount()
この場合は、単にモジュール分割をやりすぎであり、抽象化に失敗しており、コードを読むコストが増加します。
おわりに
この記事では、抽象度と文脈の概念が実際のモジュールの分割や命名、コメントにおいてどのように応用できるのかについて学びました。理論上の誤りのパターンを理解しておけば、理論的に設計に失敗しているコードを正しく発見して指摘できます。かなり長い記事でしたが、ぜひ読み返してみてください。