はじめに
本記事はQmonus Value Streamの投稿キャンペーン記事です。
目次はこちら
この記事では、普段扱っている指標を理論的に捉えなおし、その性質を探ります。理論の話が多いですが、適宜自分の開発環境で使われている指標と比べながら、実感を持って読み進めていただければと思います。
いいね、ストックをよろしくお願いします!
指標の目的
まずは、ソフトウェア工学上の重要な概念を見てみましょう。
- 障害:ソフトウェアが正常に機能を提供できなくなること
- 欠陥:障害を引き起こす原因となるような何らかの問題点です
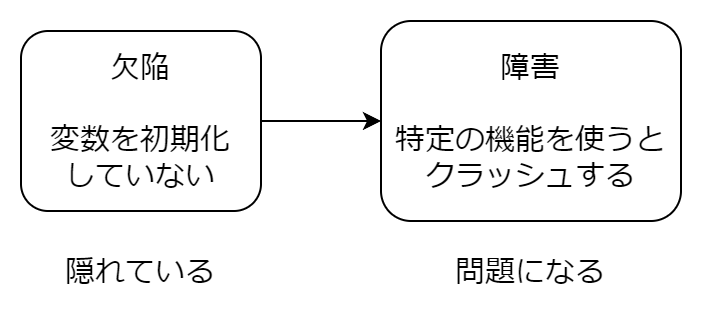
障害が発生する前に、欠陥を発見・修正することで、ソフトウェアの品質が向上します。
具体的に考えます。メモリの使用量が特定の値よりも大きい値になったらアラートが鳴り響きます。
これは、メモリの使用量が大きいことが何らかの欠陥があることを暗示しているからです。
開発者からすれば、メモリが90%使用されていても、最大値が90%ならば特に問題ないのです。
アラートが鳴り響くのは、指標が目的なのではなく、メモリリークのような何らかの欠陥があることや、アクセス数の見積もりが誤っていてスペックが不足していることなどの、何らかの欠陥を見つけるためのきっかけにしたいからです。
指標を使ったモダンな開発を始めるための第一歩は、指標の目的を理解することです。
指標の目的
指標は指標自体の数値や判定結果が目的ではなく、その背後に存在する欠陥を発見することが目的である。
まずは、指標に関する重要な言葉を二つ定義します。
- 成功:指標が、ソフトウェア品質が高いと判定すること
- 失敗:指標が、ソフトウェア品質が低いと判断すること
それに対して、指標が示したいソフトウェア品質にも二通りの性質があります。
- 欠陥なし:ソフトウェア品質が実際に高いこと
- 欠陥あり:ソフトウェア品質が実際に低いこと
開発者は、不完全な指標を通じて欠陥の有無を推定しつつ、なるべく欠陥を減らそうとしているのです。
この関係は、以下のような表にまとめることができます。
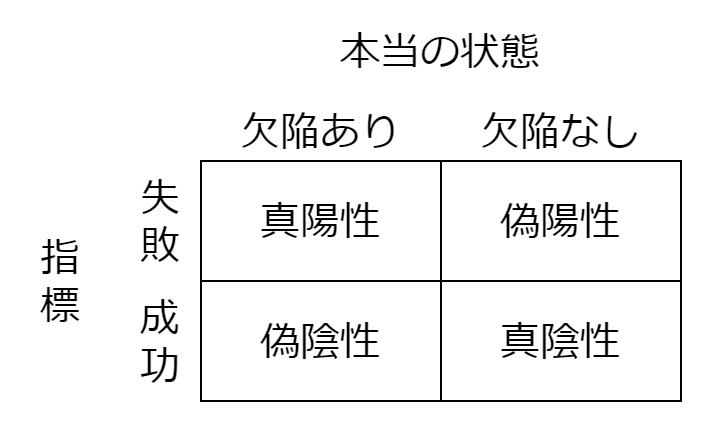
指標の誤り
偽陽性
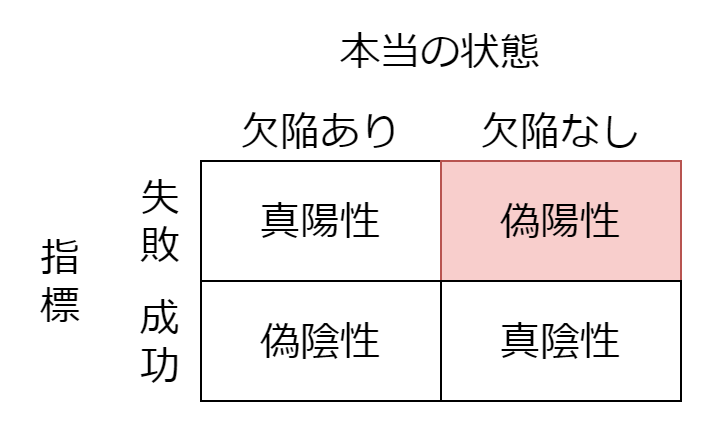
偽陽性とは、指標が失敗であるにもかかわらず、欠陥がないことです。具体的には、以下のような誤りが偽陽性です。
- レスポンスタイム指標:500ms以上で失敗。一時的なネットワーク遅延で510msを記録し失敗判定。実際はアプリケーションに問題なし。
- コード複雑度指標:循環的複雑度15超で失敗。ある関数が16を示し失敗判定。詳細確認で適切に構造化され問題なしと判明。
単なる失敗よりも大きな問題を引き起こします。それは、指標に対する信頼性の低下です。偽陽性が発生した場合、「この指標のせいで無駄な時間を使わさせられた」という記憶が強烈に残ります。
偽陰性
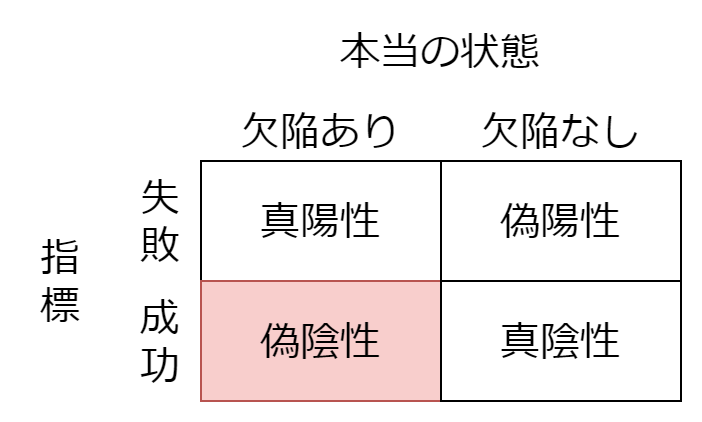
偽陰性とは、指標が成功であるにも関わらず、欠陥があることです。具体的には、以下のような誤りが偽陰性です。
- メモリ使用率指標:90%超で失敗。常に85%前後で成功判定。実際はメモリリークが発生しており、長期的に不安定。
- テストカバレッジ指標:80%以上で成功。あるモジュールで85%達成し成功判定。未テスト15%に重大バグが潜在し、本番でエラー発生。
偽陰性が失敗しても、指標の信頼はあまり損なわれません。なぜなら、成功したら指標のおかげですが、失敗してもそれが指標のせいだとは限らないからです。偽陽性と違って、間違ったときの責任はレビュー不足やテスト不足などその他の指標にも分散するのです。
偽陽性と偽陰性の性質から、不断の努力を続けなければ、常に指標は無視される方向に動くことが分かります。
極論、まったく指標を使わなければなんの指標の失敗もなく、全ての欠陥は偽陰性となります。
指標は常に軽視され煙たがられるような性質を持っているため、長期的に適切な運用が必要である。
指標の分類
正確な指標
正確な指標とは、偽陽性も偽陰性も少ない指標のことです。以下のような性質があります。
- 正確な指標で成功していれば、欠陥がない
- 正確な指標で失敗すれば、欠陥がある
下の図の赤い部分が多く、青い部分が少ないです。
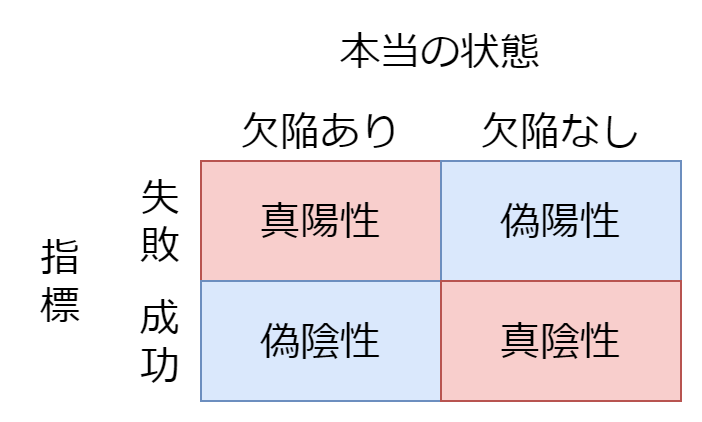
具体的には、十分に訓練された人間による時間をかけたレビューが正確な指標としての性質を強く持ちます。
偽陽性も偽陰性も少ない貴重な指標であるため、品質が重要なソフトウェアでは正確な指標をたくさん利用する必要があります。
レビューは人力の指標であり、コストと時間がかかり細かいミスも多いですが、全体として優れた指標です。
そのほかの指標は機械的な指標であり、形式的な知識を使うものです。そのため、何らかの誤差を受け入れることになります。
過剰な指標
過剰な指標とは、偽陽性が多い指標のことです。以下のような性質があります。
- 過剰な指標で成功していれば、欠陥がない
- 過剰な指標で失敗しているからと言って、欠陥があるとは限らない
下の図の赤い部分が多く、青い部分が少ないです。
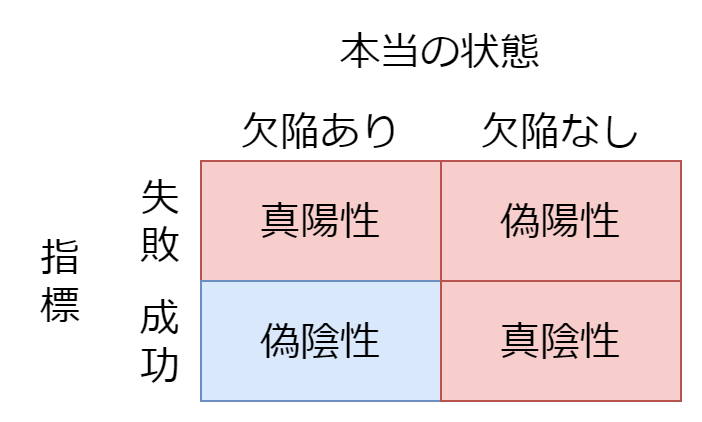
具体的には、以下のような指標は過剰な指標としての性質が強いです。
- ソフトウェア運用環境のWarnアラート
- MCCテストカバレッジ
機械的な指標で何らかの安心を保証できるという便利な性質があります。しかし機械的に判定する都合上、どうしても安全マージンを取って怪しいものすべてを問題であると判定するため、偽陽性が多くなってしまいます。
自明な指標
自明な指標とは、偽陰性が多い指標のことです。以下のような性質があります。
- 自明な指標で成功していても、欠陥はある
- 自明な指標で失敗している場合、必ず欠陥がある
下の図の赤い部分が多く、青い部分が少ないです。
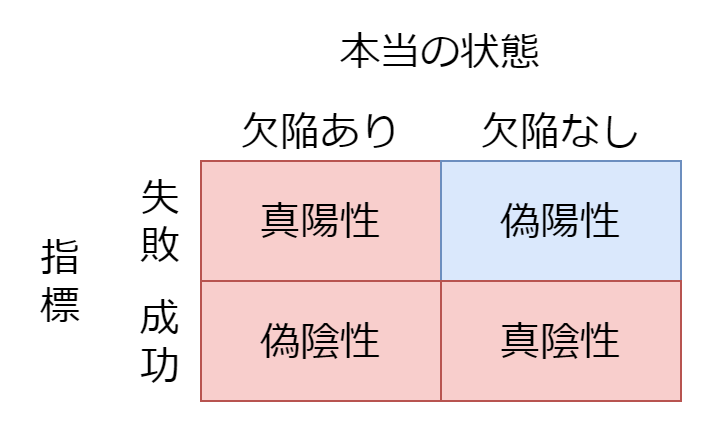
具体的には、以下のような指標は自明な指標としての性質が強いです。
- 型検査
- Lint
- C0テストカバレッジ
自明な指標は必ず欠陥がある場所を機械的に見つけ出そうとするため、機械的に判定できるような自明なことしか検出できません。したがって、指標で成功したうえで欠陥のあるプログラムを作成することができます。
しかし、自明な指標は有用です。なぜなら、ソフトウェア開発者の多くに経験があるように、人間は自明なミスを繰り返し続けるからです。
補助的な指標
補助的な指標とは、偽陽性も偽陰性も多い指標のことです。以下のような性質があります。
- 補助的な指標で成功していても、欠陥はある
- 補助的な指標で失敗していても、欠陥があるとは限らない
下の図の赤い部分が多く、青い部分が少ないです。
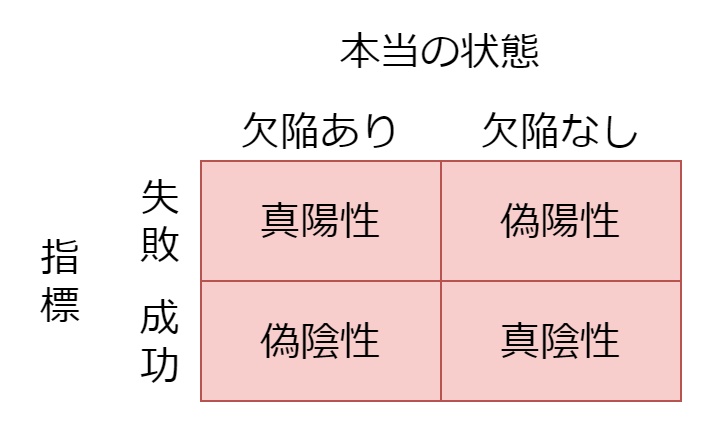
具体的には、以下のような指標は補助的な指標としての性質が強いです。
- コード行数(LOC)
- サイクロマティック複雑度
- PRがマージされるまでの平均リードタイム
- モジュール凝集度・結合度
補助的な指標は、これまでに説明してきた指標とは違い、なにも理論的な保証を提供してくれません。ソフトウェア品質とゆるく相関があるだけです。
例えば、モジュール結合度では、モジュールの意味については特に言及せず、単にパラメータの引き渡し方法だけを調べる指標であるため、モジュールが意味論として全く抽象化出来ていなかったとしても、単に引数がひとつならばそれだけで結合度は低いことになってしまいます。
指標の扱い方
指標をどのように扱うかは開発チームにゆだねられています。そのため、まずは開発チームにどのような手札があるのかを知ることが大切です。
強制する
指標が失敗だと判定すれば、コードの変更を拒否するように強制することができます。具体的には、次のような手段で強制できます。
- 指標が失敗を検出したときに、コードのプッシュやマージを拒否する
- 開発者のルールとして特定のプロセスを経るようにする
- 査定で使う
GitHubでCIが失敗したときの様子です。失敗したテストがあるため、マージができなくなっています。
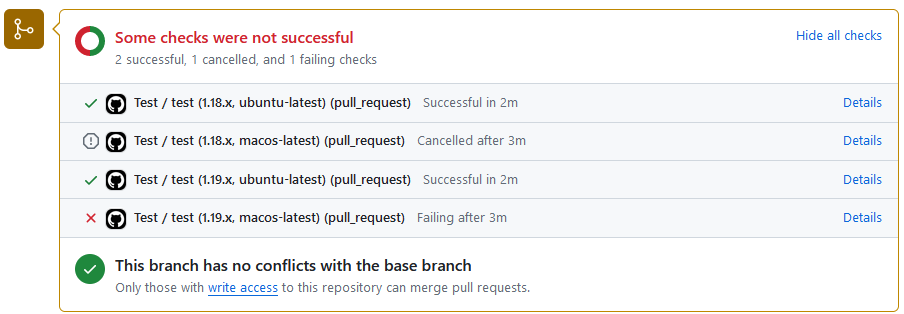
指標を強制すると、必ずコードの内容が成功と判定されることが保証できます。
指標を強制されると、開発現場はその指標を達成することが目的になります。例えば、次のような現象が発生します。
- 静的型付け言語では変数の型が違うと代入できないため、これまで横着して同じ名前の変数を別の型の値を保存するのに使いわましていた開発者が、目的ごとに変数を宣言するようになった
- LOCが大きいほど生産性が高いという指標を導入し、賃金に反映させたところ、無意味で冗長なコードが大量に作成された
- マージまでのリードタイムが短いほどよいという指標を導入すると、開発者同士でPR前に根回し的にレビューが行われるようになり、知識が共有されづらくなった
強制は最も強い手段
強制は非常に強く指標をコードに反映させます。逆に言えば、指標の誤りを強制的にコードベースに組み込むことにもなります。
また、一般に人間はよく分からない機械的な指標に仕事を指図されると不快になります。
あまり実績がない「かっこいい指標」を現場に導入するときに、強制してしまうとうまくいかないことが多いです。
通知する
通知の強さ
単に通知と言っても、その手段は様々です。ここでは、通知の種類をどれだけ開発者に認知されやすいかで分類し、指標の強さとして定義します。
メンション
メンションとは、特定の人間や人間の集団に対して指標が失敗するタイミングでプッシュ型の通知を行うことです。
開発作業に割り込んでメンションされるため、強い通知です。
具体的には、次のようなメンション手段があります。
- 電話を掛ける:オンコールと呼ばれる仕組みです。夜間や休日にも通知を送ることができますが、開発者に負担がかかります
- メール送信:強い通知の中では比較的弱めです
- チャットツールでのメンション:モダンな開発現場では標準的なメンション方法です
メンションの利点は以下のようなものです。
- 責任が明確化する:漠然と指標が失敗したという場合よりも、誰のせいで指標が失敗したので誰が対応すべきなのかが明確になります
- 対処の優先順位が上がる:割り込んで通知を送信するため、対処が素早くなされます
メンションの欠点は以下のようなものです。
- 生産性が下がる:開発作業に割り込まれると生産性が下がります
- ミュートされうる:強制よりも弱い手段のため、開発者は無視しようと思えば無視できます
atchannel通知は非常に強い手段
atchannel通知は責任を明確化しないまま全員に対して高い優先順位を与えることになります。
開発者全員のワークフローが混乱し、誰が何をするか分からなくなります。
自動表示
自動通知とは、開発者が普段使っている画面に対して情報を付与することで通知を行うことです。
自然と開発者の目に入りますが、作業を割り込むことはないため、中程度の強さの通知です。
具体的には、次のような自動表示手段があります。
- Lintが失敗している部分がエディタ上で黄色く表示される
- C0テストカバレッジが足りていないコード行が赤くハイライトされる
- GitHub上でPRに対して自動的にメッセージを投稿する
下の図は、カバレッジが高いと品質が高い?Javascript / TypeScript のカバレッジを可視化して網羅する単体テストコード入門の記事で解説されている、テストカバレッジをVSCodeに表示する例です。
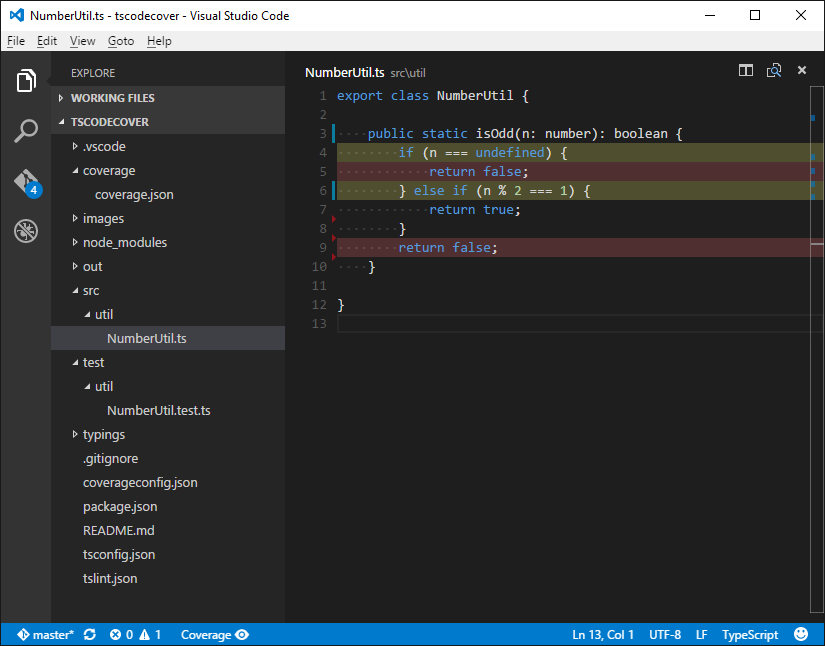
自動表示の利点は以下のようなものです。
- 必要な場面にピンポイントで表示できる:例えば、Lintの失敗部分をハイライトし、マウスカーソルを近づけることでエラー内容を表示すると、開発者体験が向上します
- スマートかつ認識されやすい:開発者が普段使う画面に表示するため、開発者体験を損ねることなく、しかも高確率で認識されます
自動表示の欠点は以下のようなものです。
- 即時性がない:あくまでもその画面を見るタイミングは開発者にゆだねられているので、即時性はありません
- 指標によっては自動表示が不可能:例えば、稼働しているプログラムのメモリ使用量などは関連する開発画面が存在しないため、自動表示ができません
- 無視が簡単:メンションと違って開発者は具体的な設定を行うことなく、単に自動表示を風景とみなすだけで通知を無視することができます
手動表示
手動通知とは、指標の通知を積極的に行わず、開発者が能動的に通知をプルする必要がある表示方法です。
自然に開発者に認識されることはないため、弱い通知です。
具体的には、次のような手動表示の手段があります。
- モニタリングのダッシュボード
- エラーログが転送されるようになっているSlackチャンネル
- 指標を計算するためのコマンドをmakeで呼び出せるようにする
下の図は、Qmonus Value Streamの機能を使ってエラーをSlackに通知している様子です
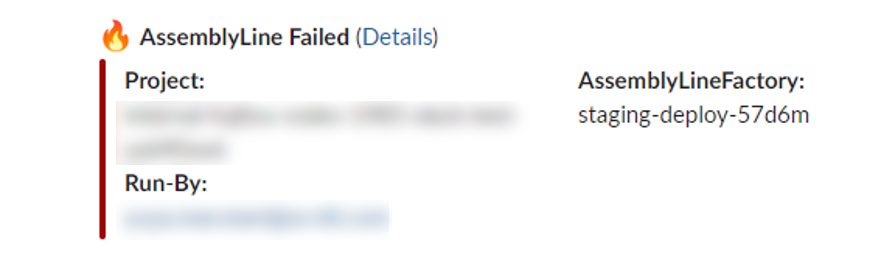
手動表示の利点は以下のようなものです。
- 表示内容をリッチにすることができる:手動通知はその指標専用の画面を作成することができるため、リッチなダッシュボードなどを通じて分かりやすく表示することが可能です
- 開発者体験を損なわない:開発者が必要になるまで指標が表示されることはありません
手動表示の欠点は以下のようなものです。
- 自力で指標を見に行く必要がある:人間は定期的に単純な作業を思い出して行うことが苦手です
- 指標の存在を忘れられる:特に新たにチームに参加した開発者にとって、自発的に指標を見に行く機会がないため、忘れられやすいです
成功と失敗のどちらを通知するか
強制と違い、通知では成功だけ・失敗だけを通知することが可能です。具体例を見てみましょう。
成功通知
- システムの稼働状態をダッシュボードで表示する
- 単体テストの実行結果をCIで表示する
通常であれば、品質が高い場合には特段の対応をする必要がないため、成功通知は失敗通知と併用されることが多いです。
失敗通知
- コンパイルエラーがエディタに表示される
- 毎晩実行されるe2eテストの失敗の通知がSlackに流れる
成功通知が増えるとノイズになるため、型検査などのたくさんの通知が必要なものは失敗だけを通知することが多いです。
分類ごとの扱い方
正確な指標
正確な指標について最も重要なことは、そんなものが存在しないことです。
したがって、現実的にはある程度の誤差を受け入れて諦めるしかありません。
現状、正確な指標の代替となるのは、十分に訓練された有能な人間が時間をかけてレビューすることです。
AI技術などによって自動的にレビューを行おうという試みがありますが、今のところ設計上の本質的な問題を明確に指摘して、一貫性を持って解決することはできていません。
正確な指標は、ソフトウェアの品質を保証するにあたって最も重要です。以下のような性質を持っています。
- 指標の正確性が高い
- 目的を限定せずに汎用的に判定することができる
- ドメイン知識を用いて効果的な品質判定ができる
- 新たな解決策を見つけ出すことができる
出来る限りこの指標を用いてソフトウェアの品質を判定するべきです。
この指標は強制されるべきです。なぜなら、誤検知が少ないため、指摘された項目を修正することはノイズにならないためです。
誤検知が多い手法を強制されると、人はいずれ指標を無視するようになりますが、正しい結果が得られることを信頼できるならば、指標を重視します。
正確な指標は、強制的に利用されるべきである
しかし、正確な指標は高コストです。そのため、そのような指標を使わずともどうにかなるような些細な問題については、なるべく使わないで済ませたいです。
つまり、指標とは人間の知性を補助するためのものであり、最も効果的なレビューによる品質判定を行うためのものであるべきです。
正確な指標は、コードのマージ前などの重要な場面で優先的に利用されるべきである
ソフトウェアの品質だけでなく、指標自体の品質の判定としても、レビューは常に利用されるべきです。
なぜなら、機械的な指標は意図的にハックできるからです。
例えば、コードカバレッジを測定し、一定以上の値を強制した場合、開発者はそれに嫌気がさし、カバレッジを無理やり上げる手法を見つけ出します。
以下は、テストカバレッジが低いコードと、テストの例です。
public class Calculator
{
public static int Divide(int a, int b)
{
if (b == 0)
{
throw new DivideByZeroException("Cannot divide by zero");
}
return a / b;
}
}
public class CalculatorTests
{
[Fact]
public void Divide_ValidInput_ReturnsCorrectResult()
{
int result = Calculator.Divide(10, 2);
Assert.Equal(5, result);
}
}
以下は、上記のコードとまったく同じロジックにも関わらず、意図的に1行に命令を詰め込むことでカバレッジを無理やり上げた例です。
public class Calculator
{
public static int Divide(int a, int b) => b == 0 ? throw new DivideByZeroException("Cannot divide by zero") : a / b;
}
そもそも、カバレッジを上げたいだけならば、実行だけしてチェックをしないテストケースを大量に追加すればいいのです。その指標の向上が、単に指標を上げるように無理やり介入したものなのか、ソフトウェア品質を上げた結果のものなのかは、機械的に判定することは不可能です。
品質が上がるから指標が良くなるのであって、逆ではない
完全自動の品質チェックは不可能
レビュー以外の指標による判定結果は機械的であるため、無視したりハックする方法がどうしても存在します。
そのため、人手で各種指標が正しく使われているかを常に確認し続ける必要があります。
指標の良さの指標
人手によるレビューでは、指標自体の使われ方についてもレビューするべきです。
指標を意図的にハックしても、レビューでそれがバレてしまうと理解されれば、本質的なソフトウェア品質の改善によって結果として指標を改善するような修正が行われるようになります。
過剰な指標
過剰な指標は、どれだけ正しいコードを書いていても失敗だと判定されることが避けられません。そのため、過剰な指標をパスすることを強制すると、開発者は指標が馬鹿らしくなっていきます。具体的には、次のような仕組みを実装してしまうと、指標への信頼度が急速に下がります。
- 本番環境のWarnログすべてに対してatchannelを使ったメンションを行う
- ベンチマークテストなど、結果が不安定で偽陽性が多いテストの失敗に通知を出す
過剰な指標の失敗を強く通知してはならない
過剰な指標を強く通知されると、開発者は指標そのものを無視します。
過剰な指標が理論的な保証を持つのは、成功のときだけです。そのため、成功している部分を通知することで、開発者に特定の部分の思考リソースが必要ないことを伝えることができます。つまり、レビューのコストを下げられます。したがって、成功を通知しましょう。
過剰な指標は成功を通知するべき
成功は失敗に比べてみていて気分がいいので無視されにくいという性質があります。そのため、弱めの通知でも問題ありません。可能であれば自動表示による通知が望ましいでしょう。自動表示が不可能な場合、対象者が明らかな場合はメンション、対象者がチーム全体の場合は手動通知で通知するのがよいでしょう。
具体的には、以下のような例は過剰な指標を正しく使いこなしています。
- 本番環境のWarnログ, Errorログを必要に応じて解析する環境が整っている(手動通知)
- テスト駆動開発をしているときに、テストファーストで書いたテストケースがC0カバレッジ基準でカバーしていない部分のコード行がエディタに表示される(自動表示)
ちなみに、Criticalログは明らかに何らかのシステム側の問題があるため、自明な指標の性質が強くなります。同じログでも性質が異なるのは面白いですね。
自明な指標
自明な指標を活用することで、人間がよくやってしまう簡単なミスを検出できます。
自明な指標で最も重要な点は、常に収集を続けて高速にミスを検出することです。
自明な指標のフィードバックは速いほうがいい
細かいミスでも積み重なると修正が面倒になっていきます。ミスした直後なら意図を覚えているのでどうしたかったのかが分かりやすいですが、時間がたってしまうとそのときには簡単に思えたケアレスミスも、修正に時間がかかるようになってしまいます。
具体的には、以下のようなプラクティスを実践しましょう。
- エディタのコンパイルエラーの表示を有効にする
- リンターも自動的に実行する
- オートフォーマッターを使う
次に重要な点は、自明な指標は強制されるべきであることです。
自明な指標は、強制されるべきである
自明な指標を満たさないコードには明らかに欠陥があるため、マージしてはいけません。
具体的には、以下のようなプラクティスを実践しましょう。
- 単体テストが通るまでCIでマージをブロックする
- なるべく静的型付け言語を採用する
自明な指標の成功は特に欠陥がないことを意味しません。そのため、次の原則は重要です。
自明な指標の成功はいかなる形でも通知してはならない
自明な指標は成功していて当然の指標です。つまり、成功をいちいち報告されても意味がありません。開発者の生産性を下げます。そもそも強制されているので失敗という状況があり得ないのです。
補助的な指標
補助的な指標を扱うときに最も重要なことは、偽陽性・偽陰性のどちらも多いため、その成功・失敗をもってして、品質について正確な判断をすることができないことです。
したがって、補助的な指標は名前の通り、人間がレビューをするときの補助的な役割として使うことが適当です。
このような性質から、補助的な指標は仕組み化・自動化との相性が悪いです。コンパイルエラーが発生したときに自動的にコードのマージを拒否してよいのは、それが100%間違っているからです。形式検証で保証された性質に対してテストを書かなくていいのは、それが100%正しいからです。つまり、自動化は「なんらかの定まった性質があるので、人間の判断を用いずに機械的に処理できる」という前提があるのです。
補助的な指標は、自動化と組み合わせてはならない
補助的な指標は自動化できないので、旨味が少なく、収集するのが少しでも面倒だと、使われなくなります。さらに、仕組みに組み込んではならないので、通常のワークフローではそもそも存在が認知されません。そのため、補助的な指標を開発現場に組み込むには、他の指標よりも多くの制約があります。以下で、補助的な指標を扱う上でのベストプラクティスをいくつか説明します。
補助的な指標のコストパフォーマンス
補助的な指標は、人間のレビューの手間を多少軽くする可能性がある、という程度の利益であるため、長期的に収集コストが高い場合には測定を取りやめることも選択肢である。
補助的な指標は成功も失敗も弱く通知する必要がある
開発者にとっても補助的な指標を収集するのは面倒なものです。損益分岐点よりも収集コストが小さくなるように、分かりやすい画面で表示できるようにしましょう。補助的な指標は成功・失敗のどちらにも意味があるため、どちらも表示しましょう。
補助的な指標は使える場面を明確化し、伝える必要がある
自動化によって浸透させることができないため、普及させるにはドキュメントやチャットでの説明などのコミュニケーションをとる必要があります。開発者が補助的な指標を便利だと理解して、自発的に使うようにならないと、現場に補助的な指標は根付きません。具体的な役立つユースケースを見つけ、地道に便利さを伝えていくしかないです。
おわりに
長い記事を最後まで読んでくださってありがとうございます。
この記事を通じて、ソフトウェア品質の保証のための指標に親しんでもらえると嬉しいです。