DeepLearning Advent Calendar 2016 最終日の投稿をさせていただきます。
Qiitaでの初めての投稿なので少し自己紹介をした方が良いですね。
初めまして、ゴンザレズと申します。日本のSIerでほぼ8年間勤めています。最近機械学習を使ったサービスを開発し、一部にDeepLearning4Jを活用しています。
この投稿はDeepLearning4Jのプロジェクトの作り方とJava EEのアプリサーバーに展開する方法を紹介します。質問やコメントがありましたらDeepLearning4Jの日本語チャットルームに是非投稿してください。
DeepLearning4Jの特徴
DeepLearning4J(以下DL4J)はJavaの深層学習ライブラリです。Skymindというサンフランシスコのスタートアップが開発していますが、ライブラリ自体はTensorflowとMXNetと同じApache 2のライセンスを利用している、オープンソースのプロジェクトです。
DL4Jは計算速度向上の為、独自のC++行列計算バックエンド(ND4J)を利用しています。GPU対応とCPU対応のそれぞれのバーションがあり、実行時にクラスパスに含まれているものが利用されます。私はよく、GPUがないMacBook Airでまず開発し、サーバーにアップする前にGPU版をビルドし直し、アップする、というフローで作業しています。
自分がDL4Jを選んだ理由はApache Sparkとの統合性があったからです。他のフレームワークの中にも一部Sparkで利用することができるものもありますが、DL4Jは直接Sparkに対応しています。
最後にSIerとしての一番のメリットは、サポートする会社があることだと思います。特に金融関系のシステムだと、何か問題が起こったときに、直接連絡できる会社があると安心です。
DL4Jのプロジェクト作成
もしScalaを利用されるなら、私のg8テンプレートからプロジェクトを作成する事もできます。最近のScalaのビルドツール、SBT(スブタ)はg8テンプレートに対応していますので、下記のコマンドからプロジェクトを作成できます。
$ sbt new wmeddie/dl4j-scala.g8
このテンプレートにはサンプルのデータと、訓練するクラス(com.example.Train)が含まれているので、参考になるかと思います。
Javaを利用したい場合はmavenやgradleといったビルドツールを利用する事が必須です。
私もJavaのmavenテンプレートを開発中です。まだMaven Centralに公開していませんが、下記のコマンドでテンプレートを利用する事が出来ます。
まず、MavenのArchetypeのプロジェクトをインストールします。
$ git clone https://github.com/wmeddie/dl4j-trainer-archetype.git
$ cd dl4j-trainer-archetype
$ mvn install
すると、Archetypeを利用することができるようになります。
$ mvn archetype:generate -Dfilter=com.yumusoft:dl4j-trainer-archetype
すでにMavenを利用しているプロジェクトがありましたら、pom.xmlのファイルに下記の依存を<dependencies>に追加すればDL4Jが利用できます
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>nd4j-native-platform</artifactId>
</dependency>
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-core</artifactId>
<version>0.7.1</version>
</dependency>
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-ui_2.10</artifactId>
<version>0.7.1</version>
</dependency>
行列計算にCPUを利用する場合は上記のようにnd4j-native-platformを用います。GPUを利用する場合は、インストールされているCUDAのバーションによってnd4j-cuda-7.5-platformやnd4j-cuda-8.0-platformなどに書き換えてください。一般にGPUの方が行列計算能力は高いですが、モデルによってCPUの方が早い場合があります。両方試す事をお勧めします。
深層学習のモデルを訓練する
DL4Jの訓練方法は他のライブラリとほとんど変わりません。JavaはPythonと違って引数の名前をつける事ができないのでBuilderパターンを利用しています。
基本的なネットワークを構築するにはNeuralNetConfigurationを利用します。
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.seed(42)
.iterations(1)
.activation("relu")
.weightInit(WeightInit.XAVIER)
.learningRate(0.1)
.regularization(true).l2(1e-4)
.list(
new DenseLayer.Builder().nIn(10).nOut(10).build(),
new DenseLayer.Builder().nIn(10).nOut(5).build(),
new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD)
.activation("softmax")
.nIn(5)
.nOut(2)
.build()
)
.build();
MultiLayerNetwork model = new MultiLayerNetwork(conf);
model.init();
上記のBuilderパターンではactivationやweightInitはレイヤーの設定です。listを呼ぶ前に設定すると、全てのレイヤーに対してその値が利用されます。最後のレイヤーで行っているように、レイヤーに直接設定する事もできます。
上記の設定より複雑なニューラルネットワークが必要の場合はNeuralNetConfigurationの代わりにComputationGraphを使います。例として、下記のネットワークは二つの数字を足し算する仕組みのものです:
ComputationGraphConfiguration configuration = new NeuralNetConfiguration.Builder()
.weightInit(WeightInit.XAVIER)
.learningRate(0.5)
.updater(Updater.RMSPROP)
.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT).iterations(nIterations)
.seed(seed)
.graphBuilder()
.addInputs("additionIn", "sumOut")
.setInputTypes(InputType.recurrent(FEATURE_VEC_SIZE), InputType.recurrent(FEATURE_VEC_SIZE))
.addLayer("encoder", new GravesLSTM.Builder().nIn(FEATURE_VEC_SIZE).nOut(numHiddenNodes).activation("softsign").build(),"additionIn")
.addVertex("lastTimeStep", new LastTimeStepVertex("additionIn"), "encoder")
.addVertex("duplicateTimeStep", new DuplicateToTimeSeriesVertex("sumOut"), "lastTimeStep")
.addLayer("decoder", new GravesLSTM.Builder().nIn(FEATURE_VEC_SIZE+numHiddenNodes).nOut(numHiddenNodes).activation("softsign").build(), "sumOut","duplicateTimeStep")
.addLayer("output", new RnnOutputLayer.Builder().nIn(numHiddenNodes).nOut(FEATURE_VEC_SIZE).activation("softmax").lossFunction(LossFunctions.LossFunction.MCXENT).build(), "decoder")
.setOutputs("output")
.pretrain(false).backprop(true)
.build();
ComputationGraph model = new ComputationGraph(configuration);
model();
上記のコードはDL4J-Examplesから引用しました。DL4Jを利用するときにDL4J-Examplesはとても参考なります。
モデルが準備できたらtrainというメソッドで訓練することができます。シンプルなデータの場合は直接行列(INDArray)をtrainに渡す事ができますが、元データがCSVファイルや画像のファイルである場合、DL4Jのベクトル変換フレームワークを用いると便利です。
下記のコードはirisデータセットのCSVを読み込む場合の基本的な使い方です。
CSVRecordReader recordReader = new CSVRecordReader(0, ",");
recordReader.initialize(new FileSplit(new File(name)));
int labelIndex = 4; // 5カラム目はラベルを表します。
int numClasses = 3; // ラベルは3種類あります。
int batchSize = 50; // 一回に読み込む件数。GPU/CPUによってこのパラメターを変更する場合もあります。
RecordReaderDataSetIterator iterator = new RecordReaderDataSetIterator(
recordReader,
batchSize,
labelIndex,
numClasses
);
RecordReaderDataSetIteratorを用いれば、それを丸ごとにモデルのtrainメソッドに渡すことができます。
for (int epoch = 0; epoch < 10; epoch++) {
model.train(iterator);
iterator.reset();
}
訓練の監視
trainのメソッドは時間かかるのでモデルの訓練がうまくいっているかを見る事が大事です。DL4Jではモデルの監視はIterationListenerで行います。trainを呼ぶ前にsetListenersでいくつかのIterationListenerを設定することができます。
一番簡単なIterationListenerはScoreIterationListenerです。ScoreIterationListenerは基本的にエラーの値を出力します。出力される数字が大きく変化したり増加している場合は訓練がうまくいってない証拠です。GPUとCPUの速さを比較するにはPerformanceListenerが便利です。
最後に、少し使い方が難しいですが、GUIを用いた監視機能も用意されています。使い方は以下の通りです。
UIServer uiServer = UIServer.getInstance();
StatsStorage statsStorage = new InMemoryStatsStorage();
uiServer.attach(statsStorage);
model.setListeners(Arrays.asList(new ScoreIterationListener(1), new StatsListener(statsStorage)));
trainを呼び始めたらブラウザーでhttp://localhost:9000にアクセスすると以下のような画面が表示されます。
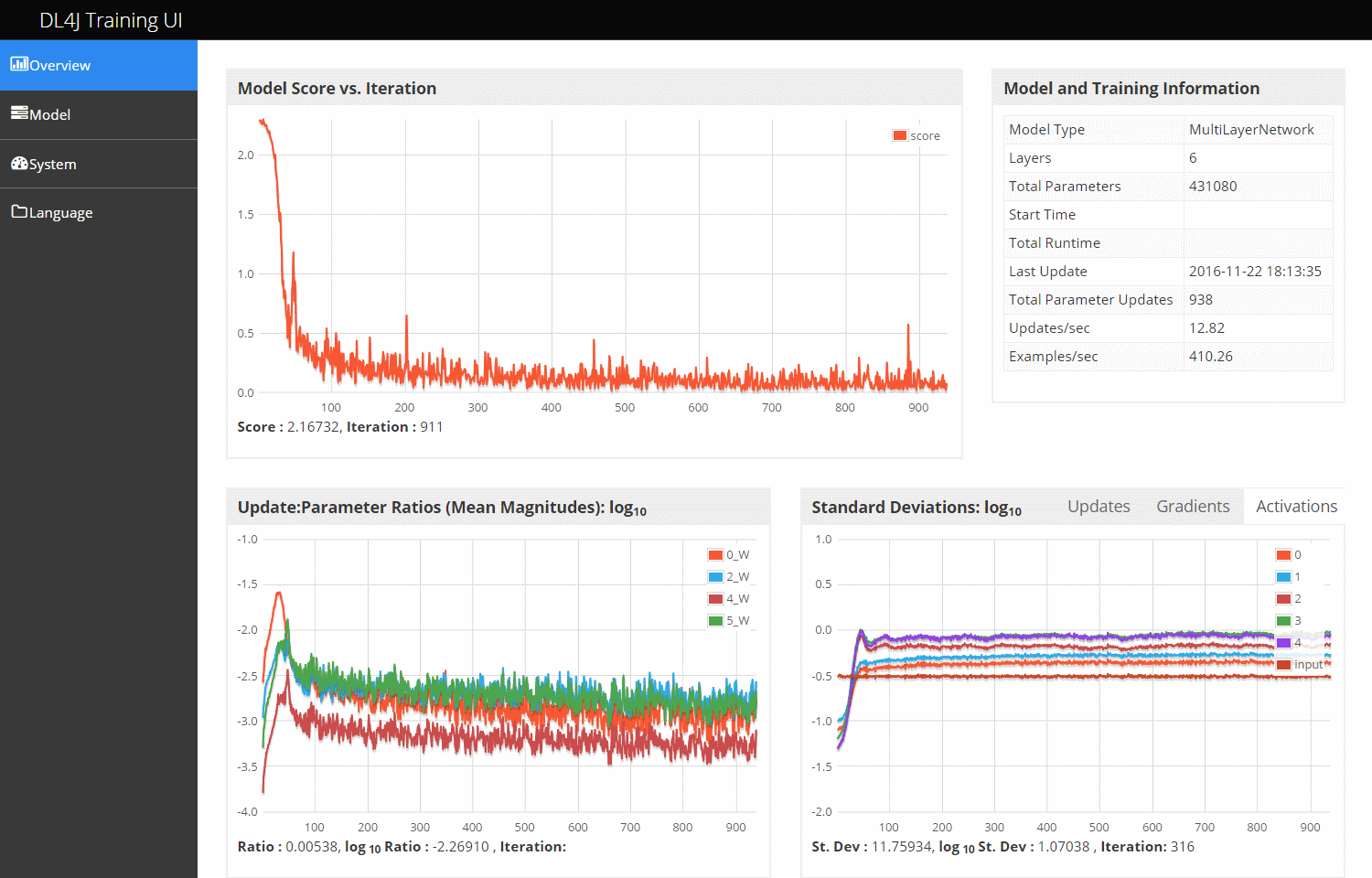
レイヤーごとのパラメターの動きまでビジュアルで見れるのでとても便利です。
モデルの評価のためにDL4JはEvaluationというクラスを用意しています。基本的にevalのメソッドとstatsのメソッドを呼びながら評価の結果を確認できます。
Evaluation eval = new Evaluation(3);
while (testData.hasNext()) {
DataSet ds = testData.next();
INDArray output = model.output(ds.getFeatureMatrix());
eval.eval(ds.getLabels(), output);
}
log.info(eval.stats());
最後に訓練したモデルを保存します。DL4Jの場合はModelSerializerが一番簡単です。使い方は以下のようになります。
ModelSerializer.writeModel(model, "model1.net", true);
最後の引数がtrueの場合はモデルの再トレーニングができます。
訓練したモデルを本番にデプロイ
モデルを利用するのはバッチ処理が一番簡単ですが、ウェブサービスとして利用する事も可能です。問題はモデルのoutputメソッドはatomicではありませんので、複数スレッドで利用すると変な値が予測されてしまう可能性があることです。Java EEのEJB仕様では一つのスレッドで同時に実行されないので、それを活用すれば正しく利用できます。
@Startup
@Stateless
public class Inferencer {
private MultiLayerNetwork model;
@PostConstruct
public void init() {
try {
InputStream modelStream = ClassLoader.getSystemResourceAsStream("model1.net");
model = ModelSerializer.restoreMultiLayerNetwork(modelStream);
} catch (Exception e) {
throw new RuntimeError(e.toString());
}
}
public int predict(float a, float b, float c) {
INDArray input = Nd4j.create(new float[] { a, b, c });
return Nd4j.argMax(model.output(input)).getInt(0);
}
}
モデルが大きい場合はコンテナーでEJBのプールサイズを調整する必要がありますが、この仕組みでもある程度利用できます。EJBが利用できない場合は、パフォーマンスが下がりますがmodel.clone()してからoutputを呼ぶという対処法があります。
GPUを利用する場合は、パフォーマンスのために予測をバッチにして返す事が必要になりますが、それをよしなにしてくれるクラスを現在開発中です。
まとめ
DL4Jを利用すると、一つの言語でモデルの開発、評価、本番環境へのデプロイをする事ができます。一つの言語を利用していますので生のデータをベクトル化する部分も共通化できるのでとても便利です。まだ利用したことがない方は是非試してみてください。